Hemos estado utilizando servicios en la nube durante mucho tiempo: correo, almacenamiento, redes sociales, mensajería instantánea. Todos funcionan de forma remota: enviamos mensajes y archivos, y se almacenan y procesan en servidores remotos. Los juegos en la nube también funcionan: el usuario se conecta al servicio, selecciona el juego y lo inicia. Esto es conveniente para el jugador, porque los juegos comienzan casi instantáneamente, no ocupan memoria y no necesitan una computadora de juego potente.

Para un servicio en la nube, todo es diferente: tiene problemas de almacenamiento de datos. Cada juego puede pesar decenas o cientos de gigabytes, por ejemplo, "The Witcher 3" toma 50 GB y "Call of Duty: Black Ops III" - 113. Al mismo tiempo, los jugadores no usarán el servicio con 2-3 juegos, se necesitan al menos varias docenas. . Además de almacenar cientos de juegos, el servicio debe decidir cuánto almacenamiento asignar por jugador y escalar cuando hay miles de ellos.
¿Debería almacenarse todo esto en sus servidores: cuántos necesitan, dónde ubicar los centros de datos, cómo "sincronizar" los datos entre varios centros de datos sobre la marcha? Comprar "nubes"? ¿Usar máquinas virtuales? ¿Es posible almacenar datos de usuario con compresión 5 veces y proporcionarlos en tiempo real? ¿Cómo excluir cualquier influencia de los usuarios entre sí durante el uso constante de la misma máquina virtual?
Todas estas tareas se resolvieron con éxito en Playkey.net, una plataforma de juegos basada en la nube.
Vladimir Ryabov (
Graymansama ), jefe del departamento de administración de sistemas, hablará en detalle sobre la tecnología ZFS para FreeBSD, que ayudó en esto, y su nueva bifurcación de ZOL (ZFS en Linux).
Mil servidores de la compañía están ubicados en centros de datos remotos en Moscú, Londres y Frankfurt. Hay más de 250 juegos en el servicio, que juegan 100 mil jugadores al mes.
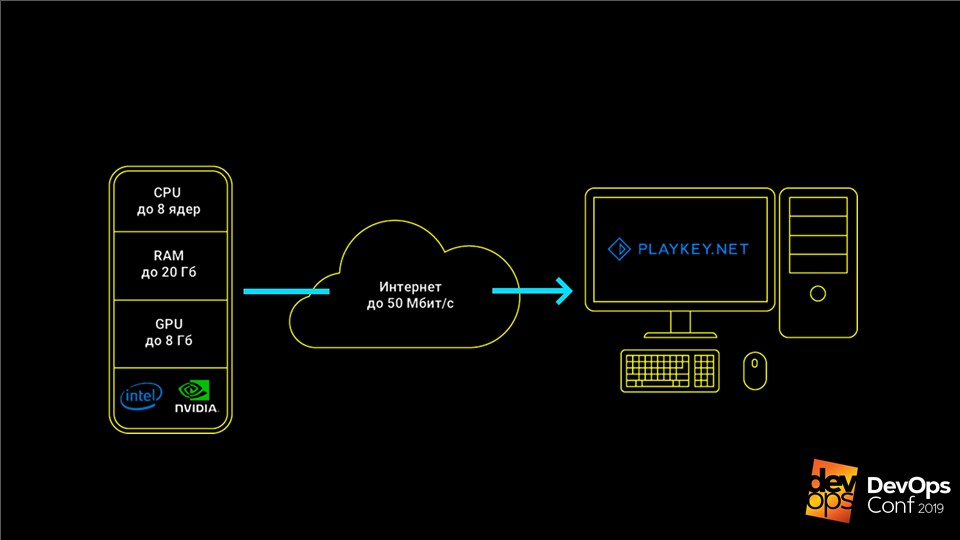
El servicio funciona así: el juego se ejecuta en los servidores de la compañía, el usuario recibe una secuencia de controles desde el teclado, el mouse o el gamepad, y se envía una secuencia de video en respuesta. Esto le permite jugar juegos modernos de alta gama en computadoras con hardware débil, computadoras portátiles con video integrado o en Mac para las que estos juegos no se lanzan en absoluto.
Los juegos deben ser almacenados y actualizados
Los datos principales para el servicio de juegos en la nube son las distribuciones de juegos, que pueden superar los cientos de GB, y el ahorro del usuario.
Cuando éramos pequeños, teníamos solo una docena de servidores y un modesto catálogo de 50 juegos. Almacenamos todos los datos localmente en los servidores, los actualizamos manualmente, todo estaba bien. Pero ha llegado el momento de crecer y partimos
hacia las nubes de AWS .
Con AWS, obtuvimos varios cientos de servidores, pero la arquitectura no ha cambiado. También eran servidores, pero ahora virtuales, con discos locales en los que se basaban las distribuciones de juegos. Sin embargo, la actualización manual en un centenar de servidores fallará.
Comenzamos a buscar una solución. Al principio intentamos actualizar a través de
rsync . Pero resultó que esto es extremadamente lento, y la carga en el nodo principal es demasiado. Pero esto ni siquiera es lo peor: cuando teníamos un nivel bajo en línea, apagamos algunas de las máquinas virtuales para no pagarlas, y al actualizar, los datos no se vierten en los servidores apagados. Todos quedaron sin actualizaciones.
La solución fue torrentes: el programa
BTSync . Le permite sincronizar una carpeta en una gran cantidad de nodos sin especificar explícitamente un nodo central.
Problemas de crecimiento
Por un tiempo, todo esto funcionó maravillosamente. Pero el servicio se estaba desarrollando, había más juegos y servidores. El número de almacenamientos locales también aumentó, tuvimos que pagar más y más. En las nubes es costoso, especialmente para los SSD. En un momento, incluso la indexación habitual de una carpeta para comenzar su sincronización comenzó a tomar más de una hora, y todos los servidores podían actualizarse durante varios días.
BTSync ha creado otro problema con tráfico de red excesivo. En ese momento, en Amazon se pagaba incluso entre virtuales internos. Si el clásico iniciador de juegos realiza pequeños cambios en archivos grandes, BTSync cree inmediatamente que todo el archivo ha cambiado y comienza a transferirlo completamente a todos los nodos. Como resultado, incluso una actualización de 15 MB podría generar decenas de GB de tráfico de sincronización.
La situación se volvió crítica cuando el almacenamiento aumentó a 1 TB. Acabo de lanzar un nuevo juego World of Warships. Su distribución tenía varios cientos de miles de archivos pequeños. BTSync no pudo digerirlo y distribuirlo a todos los demás servidores; esto ralentizó la distribución de otros juegos.
Todos estos factores crearon dos problemas:
- producir almacenamiento local es costoso, inconveniente y difícil de actualizar;
- Las nubes eran muy caras.
Decidimos volver al concepto de nuestros servidores físicos.
Sistema de almacenamiento propio
Antes de pasar a los servidores físicos, debemos deshacernos del almacenamiento local. Esto requiere su propio
sistema de almacenamiento: almacenamiento . Este es un sistema que almacena todas las distribuciones y las distribuye centralmente a todos los servidores.
Parece que la tarea es simple: ya se ha resuelto repetidamente. Pero con los juegos hay matices. Por ejemplo, la mayoría de los juegos simplemente se niegan a funcionar si se les da acceso de solo lectura. Incluso con el inicio habitual habitual, les gusta escribir algo en sus archivos, y sin eso se niegan a trabajar. Por el contrario, si un gran número de usuarios tiene acceso a un conjunto de distribuciones, comienzan a vencer a los archivos del otro con acceso competitivo.
Pensamos en el problema, verificamos varias soluciones posibles y llegamos a
ZFS - Zettabyte File System en FreeBSD .
ZFS en FreeBSD
Este no es un sistema de archivos ordinario. Los sistemas clásicos se instalan inicialmente en un dispositivo, y para trabajar con varios discos ya requieren un administrador de volúmenes.
ZFS se creó originalmente en grupos virtuales.
Se llaman
zpool y consisten en grupos de discos o matrices RAID. El volumen completo de estos discos está disponible para cualquier sistema de archivos dentro de zpool. Esto se debe a que ZFS se desarrolló originalmente como un sistema que funcionará con grandes cantidades de datos.
Cómo ZFS ayudó a resolver nuestros problemas
Este sistema tiene un
mecanismo maravilloso
para crear instantáneas y clones . Se crean al
instante y pesan solo unos pocos KB. Cuando realizamos cambios en uno de los clones, aumenta el volumen de estos cambios. Al mismo tiempo, los datos en los clones restantes no cambian y siguen siendo únicos. Esto le permite distribuir un disco de
10 TB con acceso exclusivo para el usuario final, gastando solo unos pocos KB.
Si los clones crecen en el proceso de realizar cambios en una sesión de juego, ¿no ocuparán tanto espacio como todos los juegos? No, descubrimos que incluso en sesiones de juego bastante largas, el conjunto de cambios rara vez supera los 100-200 MB, esto no es crítico. Por lo tanto, podemos dar acceso completo a un disco duro de alta capacidad completo a varios cientos de usuarios al mismo tiempo, gastando solo 10 TB con una cola.
Cómo funciona ZFS
La descripción parece complicada, pero ZFS funciona de manera bastante simple. Analicemos su trabajo con un ejemplo simple: cree
zpool data partir de los discos de
zpool create data /dev/da /dev/db /dev/dc disponibles
zpool create data /dev/da /dev/db /dev/dc .
Nota Esto no es necesario para la producción, porque si al menos un disco muere, todo el grupo quedará en el olvido con él. Mejor usar grupos RAID.Creamos el sistema de archivos
zfs create data/games , y en él un dispositivo de bloque con el nombre
data/games/disk de 10 TB. El dispositivo está disponible en
/dev/zvol/data/games/disk como un disco normal; puede realizar las mismas manipulaciones con él.
Entonces comienza la diversión. Entregamos este disco a través de
iSCSI a nuestro asistente de actualización, una máquina virtual normal que ejecuta Windows. Conectamos el disco y colocamos los juegos simplemente desde Steam, como en una computadora doméstica normal.
Llena el disco con juegos. Ahora queda por distribuir estos datos a
200 servidores para usuarios finales.
- Cree una instantánea de este disco y
zfs snapshot data/games/disk@ver1 la primera versión: zfs snapshot data/games/disk@ver1 . Cree su clon zfs clone data/games/disk@ver1 data/games/disk-vm1 , que irá a la primera máquina virtual. - Entregamos el clon a través de iSCSI y KVM lanza una máquina virtual con este disco . Se carga, entra en un grupo de servidores accesibles para los usuarios y espera un jugador.
- Cuando se completa la sesión del usuario, tomamos todos los archivos guardados de esta máquina virtual y los colocamos en un servidor separado .
zfs destroy data/games/disk-vm1 la máquina virtual y destruimos el clon : zfs destroy data/games/disk-vm1 . - Volvemos al primer paso, nuevamente creamos un clon e iniciamos la máquina virtual.
Esto nos permite proporcionar a cada próximo usuario una
máquina siempre limpia , en la que no hay cambios con respecto al jugador anterior. El disco después de cada sesión de usuario se elimina y se libera el espacio que ocupaba en el sistema de almacenamiento. También realizamos operaciones similares con el disco del sistema y con todas nuestras máquinas virtuales.
Recientemente, me encontré con un video en YouTube, donde un usuario satisfecho durante una sesión de juego formateó nuestros discos duros en los servidores, y estaba muy contento de haber roto todo. Sí, por favor, solo para pagar: puede jugar y disfrutar. En cualquier caso, el siguiente usuario siempre obtendrá una máquina virtual funcional y limpia, sin importar lo que haga la anterior.
Según este esquema, los juegos se distribuyen a solo 200 servidores. Calculamos el número 200 experimentalmente: este es el número de servidores en los que no se producen cargas críticas en las unidades de almacenamiento. Esto se debe a que los
juegos tienen un perfil de carga bastante específico : leen mucho en la etapa de lanzamiento o en la etapa de carga de nivel, y durante el juego, por el contrario, prácticamente no usan un disco. Si su perfil de carga es diferente, entonces la figura será diferente.
En el esquema anterior, para el servicio simultáneo de 200 usuarios, necesitaríamos 2,000 TB de almacenamiento local. Ahora podemos gastar un poco más de 10 TB para el conjunto de datos principal, y todavía hay 0,5 TB en stock para cambios de usuarios. Aunque ZFS ama cuando tiene al menos el 15% de espacio libre en su grupo, me parece que hemos ahorrado significativamente.
¿Qué pasa si tenemos varios centros de datos?
Este mecanismo funcionará solo dentro de un centro de datos, donde los servidores con un sistema de almacenamiento están conectados por al menos 10 interfaces de gigabit. ¿Qué hacer si hay varios DC? ¿Cómo actualizar el disco principal con juegos (conjunto de datos) entre ellos?
Para esto, ZFS tiene su propia solución:
el mecanismo de envío / recepción . El comando de ejecución es muy simple:
zfs send -v data/games/disk@ver1 | ssh myzfsuser@myserverip zfs receive data/games/disk
El mecanismo le permite transferir de un sistema de almacenamiento a otro una instantánea del sistema principal. Por primera vez, deberá enviar los 10 terabytes de datos escritos al nodo maestro a un sistema de almacenamiento vacío. Pero con las próximas actualizaciones, solo enviaremos cambios desde el momento en que creamos la instantánea anterior.
Como resultado, obtenemos:
- Todos los cambios se realizan centralmente en un sistema de almacenamiento . Luego se dispersan a todos los demás centros de datos en cualquier cantidad, y los datos en todos los nodos son siempre idénticos.
- El mecanismo de envío / recepción no teme una desconexión . Los datos no se aplican al conjunto de datos principal hasta que se transmiten completamente al nodo esclavo. Si se pierde la conexión, es imposible dañar los datos y simplemente repita el procedimiento de envío.
- Cualquier nodo puede convertirse fácilmente en un nodo maestro durante un accidente en solo unos minutos, ya que los datos en todos los nodos son siempre idénticos.
Deduplicación y copias de seguridad
ZFS tiene otra característica útil: la
deduplicación . Esta función ayuda a
no almacenar dos bloques de datos idénticos . En cambio, solo se almacena el primer bloque y, en lugar del segundo, se almacena un enlace al primero. Dos archivos idénticos ocuparán espacio como uno, y si coinciden en un 90%, llenarán el 110% del volumen original.
La función nos ayudó mucho en el almacenamiento de guardar el usuario. En un juego, diferentes usuarios tienen un guardado similar, muchos archivos son iguales. Mediante el uso de la deduplicación, podemos almacenar cinco veces más datos. Nuestro índice de deduplicación es 5.22. Físicamente, tenemos 4,43 terabytes, multiplicamos por un factor y obtenemos casi 23 terabytes de datos reales. Esto ahorra espacio al evitar el almacenamiento duplicado.
Las instantáneas son buenas para las copias de seguridad . Utilizamos esta tecnología en nuestros almacenes de archivos. Por ejemplo, si guarda una imagen todos los días durante un mes, puede implementar un clon en cualquier momento en cualquier día de ese mes y extraer archivos perdidos o dañados. Esto elimina la necesidad de revertir todo el almacenamiento o implementar una copia completa del mismo.
Usamos clones para ayudar a nuestros desarrolladores . Por ejemplo, quieren experimentar una migración potencialmente peligrosa en una base de combate. No es rápido implementar una copia de seguridad clásica de una base de datos que se acerca a 1 TB. Por lo tanto, simplemente eliminamos el clon del disco base y lo agregamos instantáneamente a la nueva instancia. Ahora los desarrolladores pueden probar todo de forma segura allí.
API ZFS
Por supuesto, todo esto debe ser automatizado. ¿Por qué subir a los servidores, trabajar con las manos, escribir scripts, si esto se puede dar a los programadores? Por lo tanto, escribimos nuestra
API web simple.
Envolvimos todas las funciones estándar de ZFS, cortamos el acceso a aquellas que son potencialmente peligrosas y podrían romper todo el sistema de almacenamiento, y dimos todo esto a los programadores. Ahora
todas las operaciones de disco están estrictamente centralizadas y realizadas por código, y
siempre conocemos el estado de cada disco . Todo funciona muy bien.
ZoL - ZFS en Linux
Centralizamos el sistema y pensamos, ¿es tan bueno? De hecho, ahora para cualquier extensión, inmediatamente necesitamos comprar varios racks de servidores: están vinculados a los sistemas de almacenamiento y es irracional dividir el sistema. ¿Qué hacer cuando decidimos implementar un pequeño stand de demostración para mostrar tecnología a socios en otros países?
Pensando, llegamos a la vieja idea:
usar unidades locales , pero solo con toda la experiencia y el conocimiento que recibimos. Si expande la idea de manera más global, ¿por qué no dar a nuestros usuarios la oportunidad no solo de usar nuestros servidores, sino también de alquilar sus computadoras?
La bifurcación relativamente reciente de
ZFS en Linux: ZoL nos ayudó mucho en esto.
Ahora cada servidor tiene su propio almacenamiento.
Solo que no almacena 10 terabytes de datos, como en el caso de una instalación centralizada, sino solo 1-2 distribuciones de los juegos que sirve. Un SSD es suficiente para esto. Todo esto funciona bien: cada próximo usuario siempre obtiene una máquina virtual limpia, así como en una instalación de combate.
Sin embargo, aquí encontramos dos problemas.
¿Cómo actualizar?
Actualice centralmente a través de SSH, como lo hacemos en los centros de datos no funcionará . Los usuarios pueden conectarse a la red local o simplemente apagarse, a diferencia de los sistemas de almacenamiento, y no desea generar tantas conexiones SSH.
Encontramos los mismos problemas que cuando usamos rsync. Sin embargo, ya no se pueden obtener torrentes sobre ZFS. Pensamos cuidadosamente cómo funciona el mecanismo de envío: envía todos los bloques de datos modificados al almacenamiento final, donde Recibir los aplica al conjunto de datos actual. ¿Por qué no escribir los datos en un archivo, en lugar de enviarlos al usuario final?
El resultado es lo que llamamos
diff . Este es un archivo en el que todos los bloques modificados entre las dos últimas instantáneas se escriben secuencialmente. Ponemos este diff en un CDN y lo enviamos a todos nuestros usuarios a través de HTTP: encendió la máquina, vio que había actualizaciones, desinfló y lo aplicó al conjunto de datos local usando Recibir.
¿Qué hacer con los conductores?
Los servidores centralizados tienen la misma configuración, y los
usuarios finales siempre tienen diferentes computadoras y tarjetas de video . Incluso si llenamos la distribución del sistema operativo con todos los controladores posibles tanto como sea posible, la primera vez que se inicie, aún querrá instalar estos controladores, luego se reiniciará y luego, posiblemente, nuevamente. Dado que cada vez que proporcionamos un clon limpio, todo este carrusel ocurrirá después de cada sesión de usuario, esto es malo.
Queríamos hacer una ejecución de inicialización: espere hasta que Windows se inicie, instale todos los controladores, haga todo lo que quiera y solo luego opere en esta unidad. Pero el problema es que si realiza cambios en el conjunto de datos principal, las actualizaciones se interrumpirán, porque los datos en la fuente y en el receptor serán diferentes, y diff simplemente no se aplicará.
Sin embargo, ZFS es un sistema flexible y nos permitió hacer una pequeña muleta.
- Como de costumbre, cree una instantánea:
zfs snapshot data/games/os@init . - Cree su clon (
zfs clone data/games/os@init data/games/os-init ) y ejecútelo en modo de inicialización. - Estamos esperando que todos los controladores se instalen y todo se reiniciará.
- Apague la máquina virtual y tome una instantánea nuevamente. Pero esta vez, no del conjunto de datos original, sino del clon de inicialización:
zfs snapshot data/games/os-init@ver1 . - Creamos un clon de la instantánea con todos los controladores instalados. Ya no se reiniciará:
zfs clone data/games/os-init@ver1 data/games/os-vm1 . - Luego trabajamos en el grupo clásico.
Ahora este sistema está en la etapa de prueba alfa. Lo probamos en usuarios reales sin conocimiento de Linux, pero logran implementarlo todo en casa. Nuestro objetivo final es que cualquier usuario simplemente conecte una unidad flash USB de arranque a su computadora, conecte una unidad SSD adicional y la alquile en nuestra plataforma en la nube.
Discutimos solo una pequeña parte de la funcionalidad de ZFS. Este sistema puede hacer cosas mucho más interesantes y diferentes, pero pocas personas saben acerca de ZFS; los usuarios no quieren hablar de ello. Espero que después de este artículo aparezcan nuevos usuarios en la comunidad ZFS.
Suscríbase a un canal de telegramas o boletín informativo para obtener información sobre nuevos artículos y videos de la conferencia DevOpsConf . Además del boletín, recopilamos noticias de las próximas conferencias y contamos, por ejemplo, qué será interesante para los fanáticos de DevOps en Saint HighLoad ++ .