
Nos convertimos en lo que vemos. Primero damos forma a las herramientas, luego las herramientas nos dan forma.
—Marshal McLuhan
Quisiera agradecer sinceramente y expresar mi gratitud a mi buen amigo Ricardo Sueiras por su revisión, contribución y por no dejarme dejar este artículo sin terminar. Ricardo, eres solo una leyenda!
Es importante recordar que la ingeniería del caos no es cuando liberas monos y entras indiscriminadamente en fallas. La ingeniería del caos es una técnica de experimentación formal bien definida.
"La ingeniería del caos implica una observación cuidadosa, un escepticismo severo con respecto al objeto de observación, porque los supuestos cognitivos distorsionan la interpretación de los resultados. Esta técnica implica la formulación de hipótesis a través de la inducción basada en observaciones similares; pruebas experimentales y basadas en mediciones de conclusiones hechas a partir de hipótesis similares; ajuste o rechazo de hipótesis basadas en resultados experimentales "
—Wikipedia
La ingeniería del caos comienza entendiendo el estado estable del sistema con el que está tratando, luego formula una hipótesis y finalmente un experimento que lo confirma, lo que ayuda a aumentar el margen de seguridad del sistema.
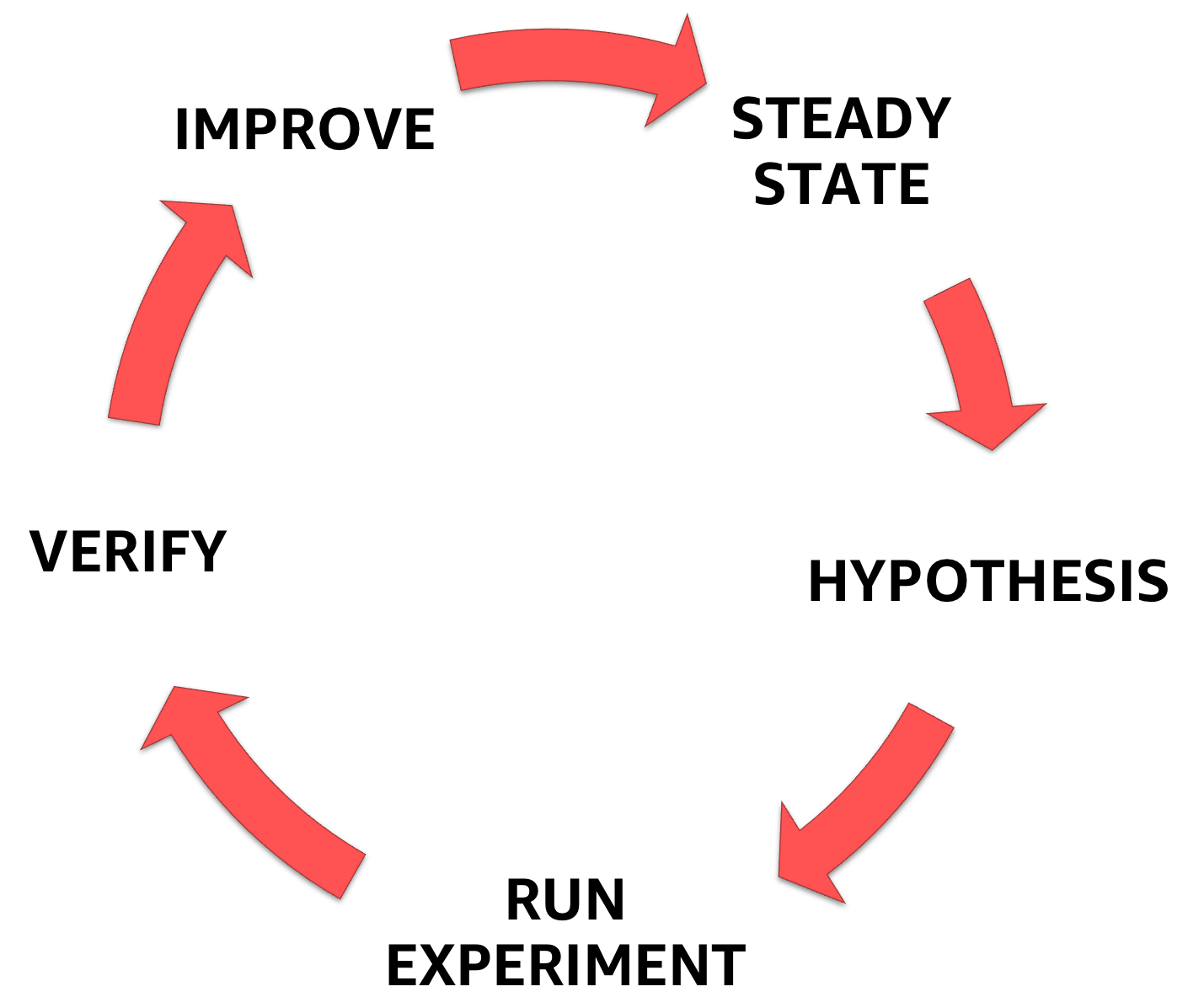
Fases de ingeniería del caos
En la primera parte de una serie de artículos, presenté la ingeniería del caos y discutí cada paso de la metodología descrita anteriormente.
En la segunda parte , analicé las áreas en las que necesita invertir al diseñar experimentos sobre ingeniería del caos y cómo elegir las hipótesis correctas.
En esta tercera parte, me enfocaré en el experimento en sí y presentaré una selección de herramientas y métodos que cubren una amplia gama de fallas.
La lista no es exhaustiva, pero para empezar, y para reflexionar, debería ser suficiente.
Introducción del fracaso: ¿qué es y para qué sirve?
La falla se utiliza para verificar que la respuesta del sistema cumple con las especificaciones en condiciones de carga normales. Por primera vez, esta técnica se utilizó cuando se introdujeron fallas en el nivel de "hierro" , en el nivel de los contactos, al cambiar las señales eléctricas en los dispositivos.
En la programación, la introducción de fallas ayuda a mejorar la estabilidad del sistema de software y le permite corregir las debilidades en la resistencia a fallas potenciales en el sistema. Esto se llama solución de problemas. También ayuda a evaluar el daño de la falla, es decir radio de daño, incluso antes de que ocurra una falla en el entorno de producción. Esto se llama predicción de fallas.
La introducción de fallas tiene varios beneficios clave, que ayudan a:
- Comprender y practicar las respuestas a accidentes e incidentes.
- Comprender los efectos de los fracasos reales.
- Comprender la efectividad y las limitaciones de los mecanismos de tolerancia a fallas.
- eliminar errores de diseño y detectar puntos comunes de falla.
- Comprender y mejorar la observabilidad del sistema.
- comprender el radio de falla de falla y reducirlo.
- Comprender la propagación del error entre los componentes del sistema.
Categorías de fallas
Hay 5 categorías de introducción de fallas: a nivel de (1) recurso; (2) red y dependencias; (3) aplicación, proceso y servicio; (4) infraestructura; y (5) el nivel humano **.
A continuación, examinaré cada una de las categorías y daré un ejemplo de introducción de fallas para cada una de ellas. También consideraré un ejemplo de introducción de fallas e instrumentos de orquestación todo en uno.
** ¡Importante! En esta publicación no me refiero a la introducción de fallas a nivel humano, pero lo consideraré a continuación.
1 - Introducción de fallas a nivel de recursos, también conocida como falta de recursos.
Sí, las tecnologías en la nube nos han enseñado que los recursos son casi ilimitados, pero me apresuro a decepcionarte: no son infinitos. Instancia, contenedor, función, etc. - independientemente de la abstracción, los recursos finalmente terminan. Ir más allá de lo permisible, el agotamiento máximo de los recursos se llama agotamiento.

La falta de recursos imita un ataque de denegación de servicio , pero no el habitual, para infiltrarse en el servidor previsto. Esta introducción de fallas es probablemente generalizada porque, probablemente, no es difícil de usar.
El agotamiento de la CPU, la memoria y los recursos de E / S
Una de mis herramientas favoritas es el estrés, la correspondencia de la herramienta de prueba de estrés original , creada por Amos Waterland .
Con stress-ng, se pueden ingresar fallas al cargar varios subsistemas físicos de la computadora, así como al controlar las interfaces del núcleo del sistema mediante pruebas de estrés. Están disponibles las siguientes pruebas de estrés: CPU, caché de CPU, dispositivo, E / S, interrupción, sistema de archivos, memoria, red, sistema operativo, canalización, programador y VM. Las páginas de manual incluyen una descripción completa de todas las pruebas de estrés disponibles, ¡y solo hay 220 de ellas!
A continuación se presentan algunos ejemplos prácticos de cómo usar stress-ng:
La carga en la CPU matrixprod proporciona la combinación correcta de operaciones con memoria, caché y coma flotante. Esto, tal vez. La mejor manera de calentar bien la CPU.
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60s
La iomix-bytes escribe N-bytes para cada iomix controlador de iomix ; El valor predeterminado es 1 GB y es ideal para realizar una prueba de esfuerzo de E / S. En este ejemplo, estableceré el 80% del espacio libre en el sistema de archivos.
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60s
vm-bytes ideal para pruebas de estrés de memoria. En este ejemplo, stress-ng ejecuta 9 pruebas de estrés de memoria virtual, que juntas consumen el 90% de la memoria disponible por hora. Por lo tanto, cada prueba de esfuerzo consume el 10% de la memoria disponible.
❯ stress-ng --vm 9 --vm-bytes 90% -t 60s
Sin espacio en disco en los discos duros
dd es una utilidad de línea de comandos compilada para convertir y copiar archivos. Sin embargo, dd puede leer y / o escribir desde archivos de dispositivos especiales como /dev/zero y /dev/random para tareas como hacer una copia de seguridad del sector de arranque de un disco duro y obtener una cantidad fija de datos aleatorios. Por lo tanto, se puede usar para introducir fallas en el servidor y simular el desbordamiento del disco. ¿Sus archivos de registro desbordaron el servidor y dejaron caer la aplicación? Entonces, dd ayudará, ¡y dolerá!
Use dd mucho cuidado. Ingrese el comando incorrecto, ¡y los datos del disco duro se borrarán, destruirán o sobrescribirán!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &
Aplicación API Slowdown
El rendimiento, la resistencia y la escalabilidad de la API son importantes. Las API son vitales para crear aplicaciones y hacer crecer su negocio.
La prueba de carga es una excelente manera de probar su aplicación antes de que entre en producción. Este también es un método genial para cargar el estrés, porque a menudo revela excepciones y limitaciones que, en otras circunstancias, habrían permanecido invisibles antes de encontrarse con tráfico real.
wrk es una herramienta de evaluación comparativa HTTP que ejerce una gran presión sobre los sistemas. Especialmente me gusta probar las comprobaciones de accesibilidad de la API, especialmente cuando se trata de comprobaciones de rendimiento , porque revelan muchas cosas con respecto a las decisiones de diseño a nivel de código de desarrollador: ¿cómo se configura la caché? ¿Cómo se implementa el límite de velocidad? ¿El sistema prioriza las comprobaciones de estado de los equilibradores de carga?
Aquí es donde comenzar:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
Este comando inicia 12 subprocesos y mantiene abiertas 400 conexiones HTTP durante 20 segundos.
2 - Introducción de fallas y dependencias a nivel de red
El libro de Peter Deutsch , Las ocho falacias de la computación distribuida, es una colección de supuestos que los desarrolladores hacen al diseñar sistemas distribuidos. Y luego la respuesta vuela en forma de inaccesibilidad, y tienes que rehacer todo. Estas suposiciones erróneas son:
- La red es confiable.
- El retraso es 0.
- El ancho de banda es infinito.
- La red es segura.
- La topología no cambia.
- Solo hay un administrador.
- Costo de transferencia 0.
- La red es homogénea.
Esta lista es un buen punto de partida para elegir la conmutación por error si está probando para ver si su sistema distribuido puede manejar fallas de red.
Introducción de latencia de red, pérdida e interrupción
Introducir latencia de red, pérdida o interrupción
tc ( control de tráfico ) es una herramienta de línea de comandos de Linux que se usa para configurar el programador por lotes del kernel de Linux. Define cómo se ponen en cola los paquetes para su transmisión y recepción en la interfaz de red. Las operaciones incluyen colas, definición de políticas, clasificación, planificación, conformación y pérdida.
tc se puede usar para simular la demora y la pérdida de paquetes para aplicaciones UDP o TCP o para limitar el uso del ancho de banda de un servicio en particular, para simular las condiciones del tráfico de Internet.
- introducción de un retraso de 100 ms
#Start ❯ tc qdisc add dev etho root netem delay 100ms #Stop ❯ tc qdisc del dev etho root netem delay 100ms
- introducción de un retraso de 100 ms con un delta de 50 ms
#Start ❯ tc qdisc add dev eth0 root netem delay 100ms 50ms #Stop ❯ tc qdisc del dev eth0 root netem delay 100ms 50ms
- daño al 5% de los paquetes de red
#Start ❯ tc qdisc add dev eth0 root netem corrupt 5% #Stop ❯ tc qdisc del dev eth0 root netem corrupt 5%
- 7% de pérdida de paquetes con una correlación del 25 por ciento
#Start ❯ tc qdisc add dev eth0 root netem loss 7% 25% #Stop ❯ tc qdisc del dev eth0 root netem loss 7% 25%
Importante! El 7% es suficiente para que la aplicación TCP no se caiga.
Jugar con "/ etc / hosts" - una tabla de búsqueda estática para nombres de host
/etc/hosts es un archivo de texto simple que asocia direcciones IP con nombres de host, una línea a la vez. Cada nodo requiere una línea que contenga la siguiente información:
IP_address canonical_hostname [aliases...]
El archivo de hosts es uno de varios sistemas que acceden a los nodos de red en una red informática y traducen los nombres de host que las personas entienden en direcciones IP. Y sí, lo has adivinado: gracias a él, es conveniente engañar a las computadoras. Aquí hay algunos ejemplos:
- Bloquee el acceso a la API DynamoDB para la instancia EC2
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
- Bloquee el acceso a la API EC2 desde una instancia EC2
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
Mire en vivo: primero, la API EC2 está disponible y ec2 describe-instances devuelve con éxito.
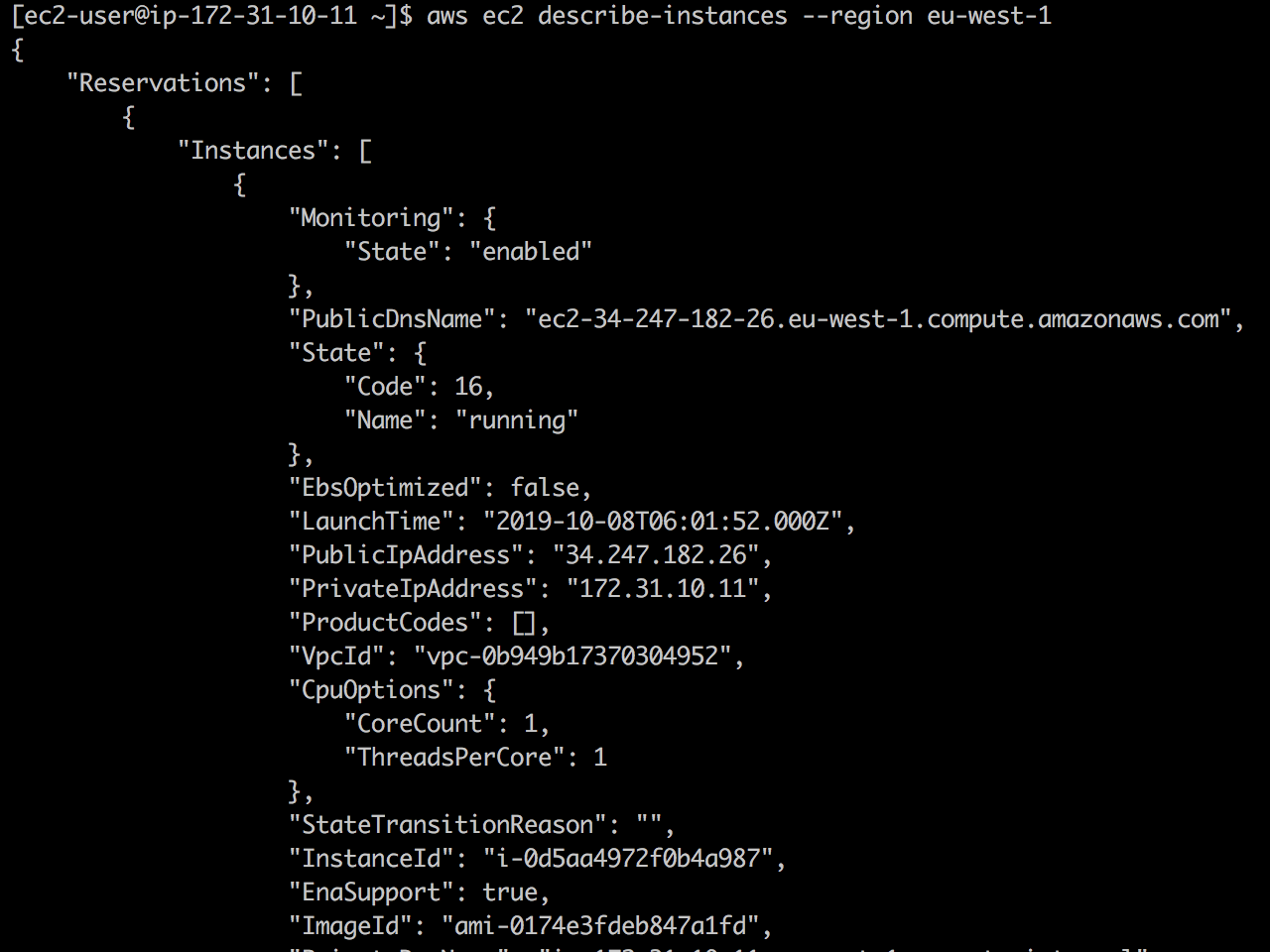
Una vez que agregué 127.0.01 ec2.eu-west-1.amazonaws.com a /etc/hosts , y la llamada a la API EC2 cae.

Por supuesto, esto funciona para todas las API de AWS.
Te diría una broma sobre DNS ...

... pero me temo que solo te llegará el segundo día. Quiero decir, después de 24 horas.
El 21 de octubre de 2016, debido al ataque DDoS Dyn, un número decente de plataformas y servicios en Europa y América del Norte no estaban disponibles. Según el informe de ThousandEyes sobre el rendimiento de DNS en todo el mundo en 2018 , el 60% de las empresas y los proveedores de SaaS aún dependen de un proveedor de DNS de origen único y, por lo tanto, se vuelven vulnerables a fallas de DNS. Y dado que no habrá Internet sin DNS, será genial simular una falla de DNS para evaluar su resistencia a la próxima falla de DNS.
Blackholing es un método por el cual tradicionalmente reducen el daño de un ataque DDoS . El mal tráfico de la red se enruta al agujero negro y se descarga al vacío. La versión de /dev/null para trabajar en la red :-) Puede usarla para simular la pérdida de tráfico de red o el protocolo del mismo DNS , por ejemplo.
Para esta tarea, necesita la herramienta iptables , que se utiliza para configurar, mantener y verificar el paquete IP en el kernel de Linux.
Para obtener tráfico DNS a través del agujero negro, intente esto:
#Start ❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP #Stop ❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROP
Introducción de fallas utilizando Toxiproxy.
Las herramientas de Linux como tc e iptables un problema grave, pero no el único. Requieren permiso de root para ejecutarse, y esto crea problemas para algunas organizaciones y entornos. Por favor amor y favor - ¡ Toxiproxy !
Toxiproxy es un proxy TCP de código abierto desarrollado por el equipo de ingenieros de Shopify . Ayuda a simular la red caótica y las condiciones del sistema o sistemas reales. Colóquelo entre los diversos componentes de la arquitectura como se muestra a continuación.
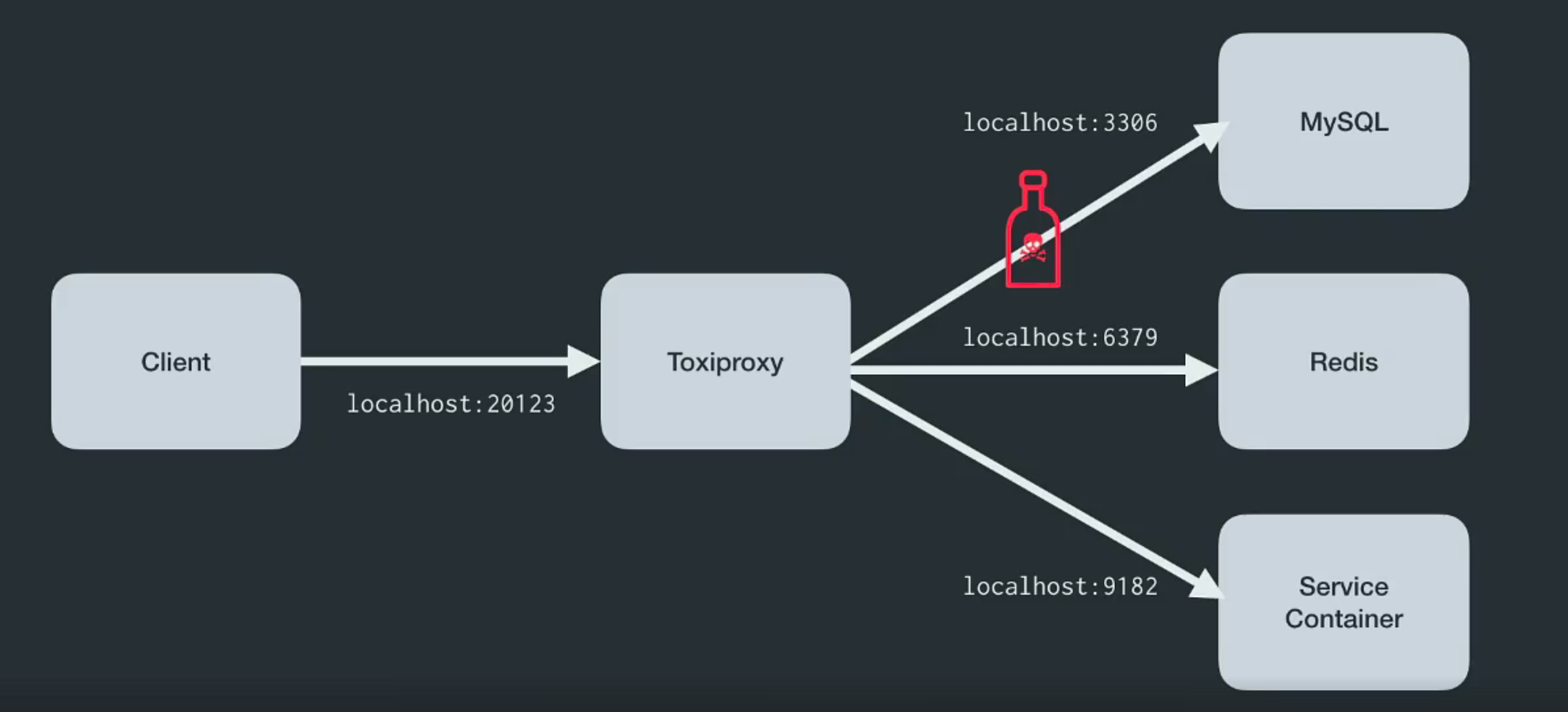
Fue creado específicamente para entornos de prueba, CI y desarrollo, e introduce una confusión predefinida o aleatoria que se controla a través de la configuración. Toxiproxy utiliza sustancias tóxicas para manipular la relación entre el cliente y el código del desarrollador, y se puede configurar a través de la API HTTP . Y para él en el kit hay suficientes tóxicos para comenzar.
El siguiente ejemplo muestra cómo Toxiproxy funciona con el código del cliente de tóxicos al introducir un retraso de 1000 ms en la conexión entre mi cliente Redis, redis-cli y el propio Redis.
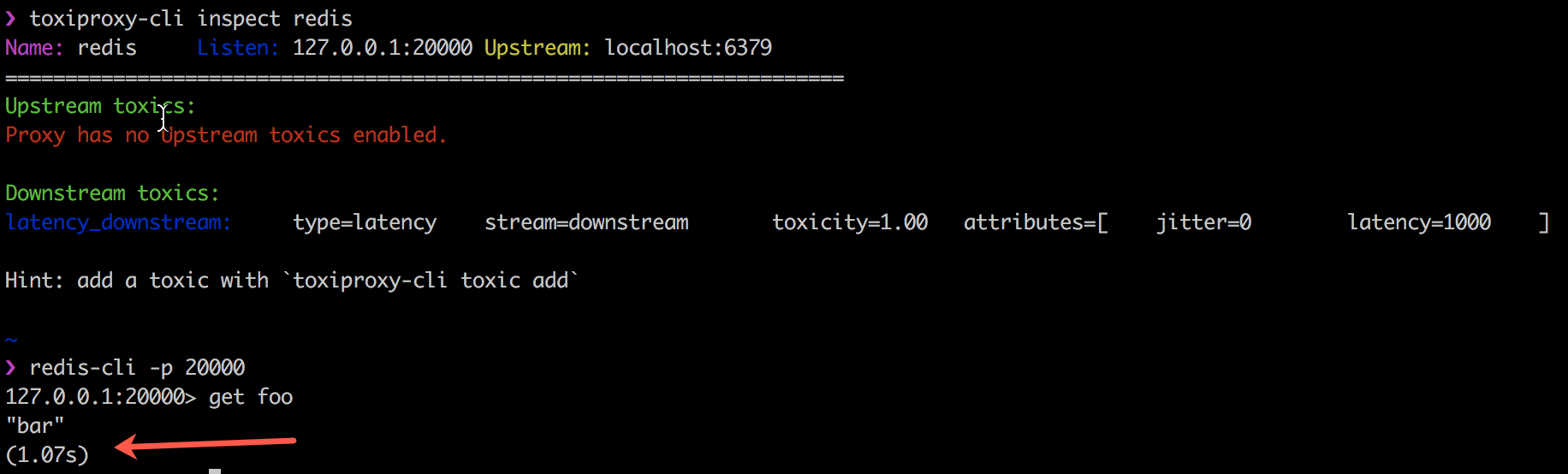
Shopx ha utilizado con éxito Toxiproxy en todos los entornos de producción y desarrollo desde octubre de 2014. Más información está en su blog .
3 - Introducción de fallas a nivel de aplicación, proceso y servicio
El software está cayendo. Esto es un hecho Y que haces ¿Debo iniciar sesión a través de SSH en el servidor y reiniciar el proceso fallido? Los sistemas de control de procesos proporcionan funciones de control de estado o cambio de estado del tipo iniciar, detener, reiniciar. Los sistemas de control se utilizan generalmente para garantizar un control estable del proceso. systemd es solo una herramienta de este tipo, que proporciona los ladrillos básicos de control de procesos para Linux. Supervisord ofrece control de varios procesos en sistemas operativos como UNIX.
Cuando implemente la aplicación, debe usar estas herramientas. Sin duda, es una buena práctica probar el daño de matar procesos críticos. Asegúrese de recibir alertas y de que el proceso se reinicie automáticamente.
- matar procesos Java
❯ pkill -KILL -f java #Alternative ❯ pkill -f 'java -jar'
- matar procesos de Python
❯ pkill -KILL -f python
Por supuesto, puede usar el comando pkill para eliminar muchos otros procesos que se ejecutan en el sistema.
Presentación de fallas en la base de datos
Si hay mensajes de falla que a los operadores no les gusta recibir, estos son los relacionados con fallas de la base de datos. Los datos valen su peso en oro y, por lo tanto, cada vez que una base de datos se bloquea, aumenta el riesgo de perder datos de clientes.

Será un mantenimiento sencillo. Y-y-y-y-y-así ... todo ha caído
A veces, la capacidad de recuperar datos y poner la base de datos en condiciones de trabajo lo más rápido posible decide el futuro de la empresa. Desafortunadamente, tampoco siempre es fácil prepararse para varios modos de falla de la base de datos, y muchos de ellos aparecerán solo en el entorno de producción.
Sin embargo, si está utilizando Amazon Aurora , puede probar la resistencia del clúster de la base de datos de Amazon Aurora ante fallas mediante solicitudes de conmutación por error .
Introducción a Amazon Aurora Crash
Las solicitudes de falla se emiten como comandos SQL a una instancia de Amazon Aurora y le permiten programar una simulación de uno de los siguientes eventos:
- Fallo de una instancia de DB de escritura.
- Fracaso de la réplica de Aurora.
- Falla de disco.
- Sobrecarga de disco.
Al enviar una solicitud de falla, también debe especificar la cantidad de tiempo durante el cual se simulará el evento de falla.
- Causa de la falla de la instancia de Amazon Aurora:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];
- simular el fallo de Aurora Replica:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE [ TO ALL | TO "replica name" ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- simular falla de disco para el clúster de base de datos Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- simular falla de disco para el clúster de base de datos Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION BETWEEN minimum AND maximum MILLISECONDS [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
Accidente en el mundo de las aplicaciones sin servidor
La falla puede ser un verdadero desafío si utiliza componentes sin servidor, ya que los servicios sin servidor como AWS Lambda no admiten de manera nativa la conmutación por error.
Presentación de fallas de Lambda
Para comprender este problema, escribí una pequeña biblioteca de Python y una capa lambda , para introducir fallas en AWS Lambda . Actualmente, ambos admiten demoras, errores, excepciones y la introducción de un código de error HTTP. La falla se logra configurando el almacén de parámetros de AWS SSM de la siguiente manera:
{ "isEnabled": true, "delay": 400, "error_code": 404, "exception_msg": "I really failed seriously", "rate": 1 }
Puede agregar un decorador de python a la función del controlador para introducir un error.
- lanzar una excepción:
@inject_exception def handler_with_exception(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_exception('foo', 'bar') Injecting exception_type <class "Exception"> with message I really failed seriously a rate of 1 corrupting now Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../chaos_lambda.py", line 316, in wrapper raise _exception_type(_exception_msg) Exception: I really failed seriously
- ingrese el código de error "HTTP no válido":
@inject_statuscode def handler_with_statuscode(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_statuscode('foo', 'bar') Injecting Error 404 at a rate of 1 corrupting now {'statusCode': 404, 'body': 'Hello from Lambda!'}
- ingrese un retraso:
@inject_delay def handler_with_delay(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_delay('foo', 'bar') Injecting 400 of delay with a rate of 1 Added 402.20ms to handler_with_delay {'statusCode': 200, 'body': 'Hello from Lambda!'}
Haga clic aquí para obtener más información sobre esta biblioteca de Python.
Introducción de la falla de Lambda a través de la limitación de concurrencia
Lambda por defecto, por razones de seguridad, ajusta la ejecución paralela de todas las funciones en una región específica por cuenta. Las ejecuciones paralelas se refieren a varias ejecuciones de un código de función que ocurre en cualquier momento en el tiempo. Se utilizan para escalar una llamada de función a una solicitud entrante. Pero también puede servir para el propósito opuesto: detener la ejecución de Lambda.
❯ aws lambda put-function-concurrency --function-name <value> --reserved-concurrent-executions 0
Este comando reducirá la concurrencia a cero, causando fallas en las consultas con un error como "frenado" - DTC 429 .
Thundra: rastreo de transmisión sin servidor
Thundra es una herramienta de monitoreo de aplicaciones sin servidor que tiene una capacidad incorporada para inyectar fallas en aplicaciones sin servidor. Realiza manejadores de envoltorios para introducir fallas como "manejador sin errores" para operaciones con DynamoDB, "sin neutralización de errores" para la fuente de datos o "sin tiempo de espera en las solicitudes HTTP salientes". No lo he intentado yo mismo, pero en esta publicación para la autoría de Yan Chui y en este magnífico video de Marsha Villalba, el proceso está bien descrito. Se ve prometedor.
Y en conclusión de la sección sobre aplicaciones sin servidor, diré que Yan Chui tiene un excelente artículo sobre las dificultades de la ingeniería del caos en relación con las aplicaciones sin servidor. Recomiendo a todos que lo lean.
4 - Introducción de fallas a nivel de infraestructura
Todo comenzó con la introducción de fallas a nivel de infraestructura, tanto para Amazon como para Netflix. La introducción de fallas a nivel de infraestructura, desde la desconexión de un centro de datos completo hasta la detención aleatoria de instancias, es probablemente la más fácil de implementar.
Y, por supuesto, el ejemplo del " mono del caos " viene a la mente primero.
Detener instancias de EC2 que se seleccionan aleatoriamente en una determinada zona de disponibilidad.
En su infancia, Netflix quería introducir reglas arquitectónicas difíciles. Implementó su "mono del caos" como una de las primeras aplicaciones de AWS en instalar microservicios sin estado de escala automática, en el sentido de que cualquier instancia puede ser destruida o reemplazada automáticamente sin causar ninguna pérdida de estado. The Chaos Monkey se aseguró de que nadie violara esta regla.
El siguiente escenario, similar al "mono del caos", es detener cualquier instancia al azar, en una zona de disponibilidad específica dentro de la misma región.
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")
import boto3 import random REGION = 'eu-west-1' def stop_random_instance(az, tag_name, tag_value, region=REGION): ''' >>> stop_random_instance(az="eu-west-1a", tag_name='chaos', tag_value="chaos-ready", region='eu-west-1') ['i-0ddce3c81bc836560'] ''' ec2 = boto3.client("ec2", region_name=region) paginator = ec2.get_paginator('describe_instances') pages = paginator.paginate( Filters=[ { "Name": "availability-zone", "Values": [ az ] }, { "Name": "tag:" + tag_name, "Values": [ tag_value ] } ] ) instance_list = [] for page in pages: for reservation in page['Reservations']: for instance in reservation['Instances']: instance_list.append(instance['InstanceId']) print("Going to stop any of these instances", instance_list) selected_instance = random.choice(instance_list) print("Randomly selected", selected_instance) response = ec2.stop_instances(InstanceIds=[selected_instance]) return response
¿ tag_value tag_name y tag_value ? Tales pequeñas cosas evitarán el fracaso de las instancias incorrectas. #lessonlearned

Y sí ... reinicie la base de datos - bien hecho [Uy, no esa instancia]
5 - Introducción de fallas y herramientas de orquestación todo en uno
Es probable que estés perdido en tantas herramientas. Afortunadamente, hay un par de presentaciones de rechazo y herramientas de orquestación que incluyen la mayoría de ellas y son fáciles de usar.
Una de mis herramientas favoritas es Chaos Toolkit , una plataforma de ingeniería de caos de código abierto respaldada comercialmente por el gran equipo de ChaosIQ . Estos son solo algunos de ellos: Russ Miles , Sylvain Helleguarch y Marc Parrien .
Chaos Toolkit define una API declarativa y extensible para realizar convenientemente un experimento de ingeniería de caos. Incluye controladores para AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humino, Prometheus y Gremlin.
Las extensiones son un conjunto de comprobaciones y acciones utilizadas para los experimentos de la siguiente manera: detenemos una instancia seleccionada aleatoriamente en una zona de disponibilidad específica si la tag-key contiene chaos-ready valor chaos-ready .
{ "version": "1.0.0", "title": "What is the impact of randomly terminating an instance in an AZ", "description": "terminating EC2 instance at random should not impact my app from running", "tags": ["ec2"], "configuration": { "aws_region": "eu-west-1" }, "steady-state-hypothesis": { "title": "more than 0 instance in region", "probes": [ { "provider": { "module": "chaosaws.ec2.probes", "type": "python", "func": "count_instances", "arguments": { "filters": [ { "Name": "availability-zone", "Values": ["eu-west-1c"] } ] } }, "type": "probe", "name": "count-instances", "tolerance": [0, 1] } ] }, "method": [ { "type": "action", "name": "stop-random-instance", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "stop_instance", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] }, "pauses": { "after": 60 } } ], "rollbacks": [ { "type": "action", "name": "start-all-instances", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "start_instances", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] } } ] }
Realizar el experimento anterior es simple:
❯ chaos run experiment_aws_random_instance.json
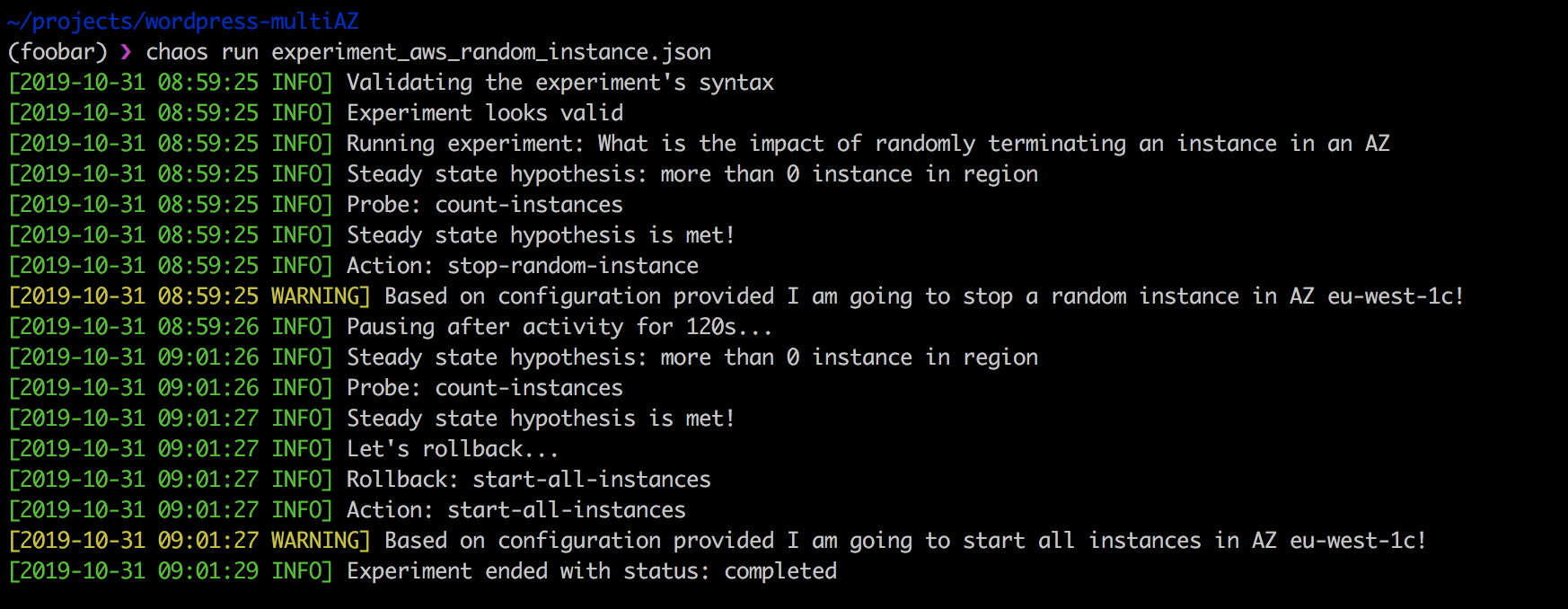
La fortaleza del Chaos Toolkit es que, en primer lugar, es de código abierto y se puede adaptar a sus necesidades. En segundo lugar, encaja perfectamente en la tubería de CI / CD y admite pruebas continuas de caos.
La desventaja de Chaos Toolkit es que lleva tiempo dominarlo. Además, no hay experimentos listos en él, por lo que debe escribirlos usted mismo. Sin embargo, estoy familiarizado con el equipo de ChaosIQ, que trabaja incansablemente, entendiendo esta tarea.
Gremlin
Otro de mis favoritos es Gremlin. Contiene un conjunto completo de modos para introducir fallas en una herramienta simple con una interfaz de usuario intuitiva. Tal caos como servicio.
Gremlin admite la introducción de fallas en los niveles de recursos, redes y consultas , lo que le permite experimentar rápidamente con todo el sistema, incluido con hardware, varios proveedores de nube, entornos en contenedores, incluidos Kubernetes, aplicaciones y, en cierta medida, aplicaciones sin servidor.
Además de una bonificación: ¡los muchachos de Gremlin son excelentes compañeros que escriben excelente contenido para el blog y siempre están listos para ayudar! Estos son algunos de ellos: Matthew , Colton , Tammy , Rich , Ana y HML .
Gremlin no tiene dónde usar:
Primero ingrese a la aplicación Gremlin y seleccione "Crear ataque".
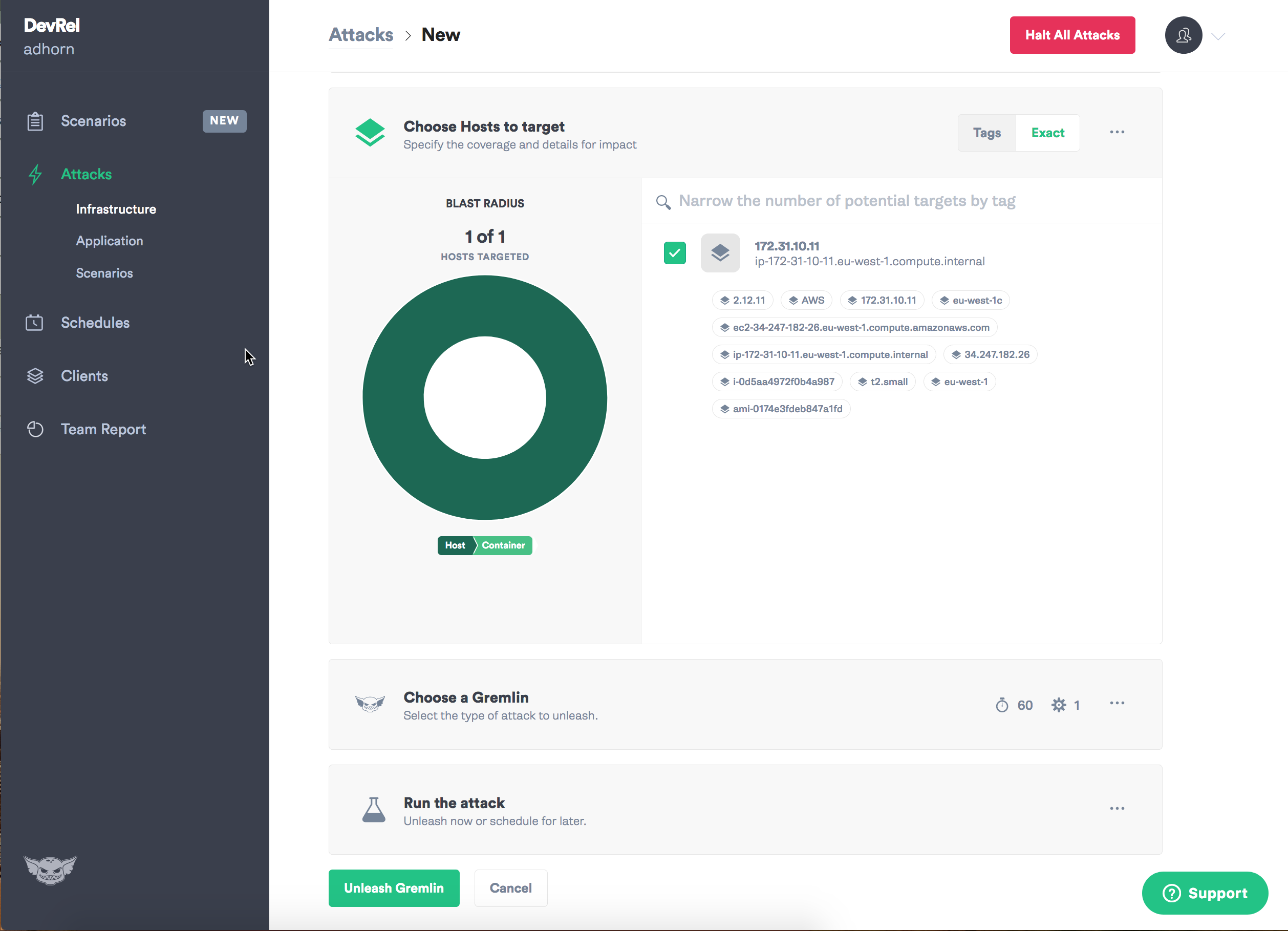
Asignar una meta - instancia.
Seleccione el tipo de falla que desea presentar, ¡y puede comenzar el caos!
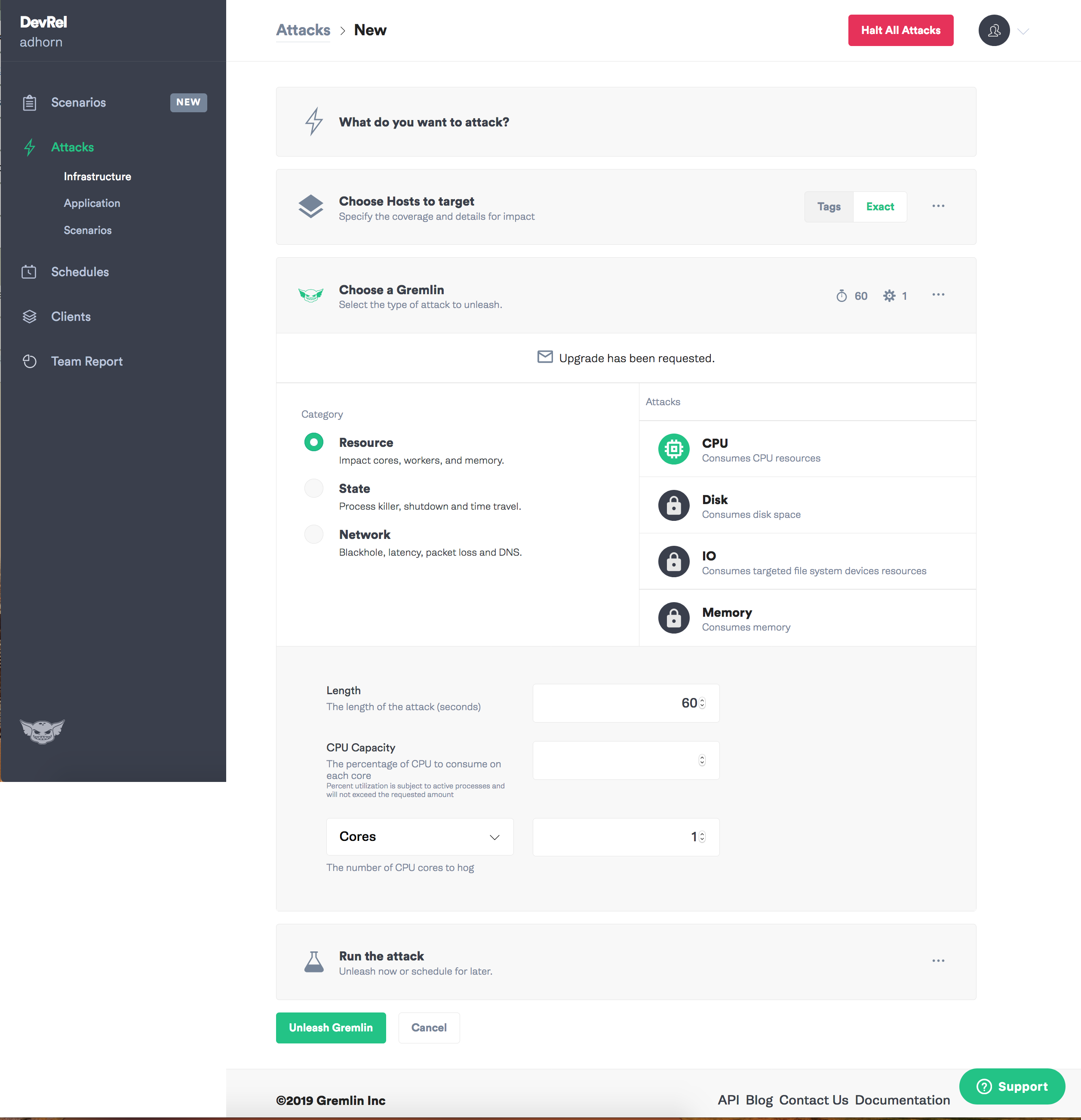
Debo admitir que siempre me gustó Gremlin: con él, los experimentos en ingeniería del caos son intuitivamente simples.
Menos en la política de precios : se requiere una licencia para el trabajo, que puede no ser adecuada para usuarios novatos o trabajos únicos. Sin embargo, recientemente agregó su versión gratuita. Además, el cliente Gremlin y el demonio deben instalarse en instancias que deben ser atacadas, pero esto no es del agrado de todos.
Ejecutar comando desde el Administrador del sistema de AWS
Run command EC2 , 2015 , . — 2, . , , Systems Manager.
Run Command DevOps ad-hoc , .
, Run Command , Windows, -.
AWS System Manager . — !
!
, .
1 — - — , - . . — , — , , . , ! :
" . ".
— , - Amazon Prime Video
2 — , , . , -.
3 — , , .
4 — , , , . , - — , .
, , , . , . , , :-)
—