
Era 2019, y todavía no tenemos una solución estándar para la agregación de registros en Kubernetes. En este artículo, nos gustaría, utilizando ejemplos de la práctica real, compartir nuestras búsquedas, los problemas encontrados y sus soluciones.
Sin embargo, para comenzar, haré una reserva para que diferentes clientes comprendan cosas muy diferentes al recopilar registros:
- alguien quiere ver registros de seguridad y auditoría;
- alguien: registro centralizado de toda la infraestructura;
- y para alguien es suficiente recopilar solo los registros de la aplicación, excluyendo, por ejemplo, los equilibradores.
Acerca de cómo implementamos varias "Lista de deseos" y qué dificultades encontramos, debajo del corte.
Teoría: acerca de las herramientas de registro
Antecedentes sobre los componentes del sistema de registro.
El registro ha recorrido un largo camino, como resultado de lo cual hemos desarrollado metodologías para recopilar y analizar registros, que utilizamos hoy. En la década de 1950, Fortran introdujo un análogo de flujos de E / S estándar que ayudó al programador a depurar su programa. Estos fueron los primeros registros de computadora que facilitaron la vida de los programadores de aquellos tiempos. Hoy vemos en ellos el primer componente del sistema de registro: la
fuente o "productor" de los registros .
La informática no se detuvo: aparecieron las redes informáticas, los primeros grupos ... Los sistemas complejos que constaban de varias computadoras comenzaron a funcionar. Ahora los administradores del sistema se vieron obligados a recopilar registros de varias máquinas y, en casos especiales, podían agregar mensajes del kernel del sistema operativo en caso de que necesitaran investigar una falla del sistema. Para describir los sistemas centralizados de recopilación de registros,
RFC 3164 salió a principios de la década de 2000, que estandarizó remote_syslog. Entonces apareció otro componente importante: el
recolector (recolector) de registros y su almacenamiento.
Con el aumento en el volumen de registros y la adopción generalizada de tecnologías web, surgió la pregunta de qué registros deberían mostrarse convenientemente a los usuarios. Las herramientas de consola simples (awk / sed / grep) fueron reemplazadas por
visores de registro más avanzados: el tercer componente.
En relación con el aumento en el volumen de registros, otra cosa quedó clara: se necesitan registros, pero no todos. Y diferentes registros requieren diferentes niveles de seguridad: algunos se pueden perder cada dos días, mientras que otros deben almacenarse durante 5 años. Por lo tanto, se agregó un componente de filtración y enrutamiento para flujos de datos al sistema de registro, llamémoslo
filtro .
Los repositorios también dieron un gran salto: cambiaron de archivos normales a bases de datos relacionales y luego a repositorios orientados a documentos (por ejemplo, Elasticsearch). Entonces el almacenamiento se separó del colector.
Al final, el concepto del registro en sí se ha expandido a un flujo abstracto de eventos que queremos mantener para la historia. Más precisamente, en el caso de que sea necesario realizar una investigación o elaborar un informe analítico ...
Como resultado, durante un período de tiempo relativamente corto, la recopilación de registros se ha convertido en un subsistema importante, que legítimamente se puede llamar una de las subsecciones en Big Data.
 Si alguna vez las impresiones normales podrían ser suficientes para un "sistema de registro", ahora la situación ha cambiado mucho.
Si alguna vez las impresiones normales podrían ser suficientes para un "sistema de registro", ahora la situación ha cambiado mucho.Kubernetes y Registros
Cuando Kubernetes entró en la infraestructura, el problema existente de recolectar registros no pasó por alto. En cierto sentido, se ha vuelto aún más doloroso: la administración de la plataforma de infraestructura no solo se simplificó, sino que también fue complicada. Muchos servicios antiguos comenzaron a migrar a pistas de microservicios. En el contexto de los registros, esto dio como resultado un número creciente de fuentes de registro, su ciclo de vida especial y la necesidad de rastrear a través de los registros las interconexiones de todos los componentes del sistema ...
Mirando hacia el futuro, puedo decir que ahora, desafortunadamente, no hay una opción de registro estandarizada para Kubernetes que sería favorablemente diferente de todos los demás. Los esquemas más populares en la comunidad son los siguientes:
- alguien está implementando una pila EFK (Elasticsearch, Fluentd, Kibana);
- alguien está probando el Loki recientemente lanzado o usando el operador Logging ;
- nosotros (¿y quizás no solo nosotros?) estamos en gran medida satisfechos con nuestro propio desarrollo: loghouse ...
Como regla, utilizamos tales paquetes en clústeres K8 (para soluciones autohospedadas):
Sin embargo, no me detendré en las instrucciones para su instalación y configuración. En cambio, me centraré en sus defectos y conclusiones más globales sobre la situación con los registros en general.
Practica con registros en K8s

"Registros diarios", ¿cuántos de ustedes? ..
La recolección centralizada de registros con una infraestructura suficientemente grande requiere recursos considerables que se gastarán en recolectar, almacenar y procesar registros. Durante la operación de varios proyectos, enfrentamos varios requisitos y los problemas operativos resultantes.
Probemos ClickHouse
Echemos un vistazo a un repositorio centralizado en un proyecto con una aplicación que genera muchos registros: más de 5000 líneas por segundo. Comencemos a trabajar con sus registros, agregándolos a ClickHouse.
Tan pronto como se requiera el tiempo real máximo, el servidor ClickHouse de 4 núcleos ya estará sobrecargado en el subsistema de disco:

Este tipo de descarga se debe al hecho de que estamos tratando de escribir en ClickHouse lo más rápido posible. Y la base de datos responde a esto con una mayor carga de disco, lo que puede causar los siguientes errores:
DB::Exception: Too many parts (300). Merges are processing significantly slower than insertsEl hecho es que
las tablas MergeTree en ClickHouse (contienen datos de registro) tienen sus propias dificultades durante las operaciones de escritura. Los datos insertados en ellos generan una partición temporal, que luego se fusiona con la tabla principal. Como resultado, la grabación es muy exigente en el disco y se aplica la restricción, cuya notificación recibimos anteriormente: no se pueden fusionar más de 300 subparticiones en 1 segundo (de hecho, esto es 300 insert'ov por segundo).
Para evitar este comportamiento,
debe escribir en ClickHouse con la mayor cantidad de fragmentos posible y no más de 1 vez en 2 segundos. Sin embargo, escribir en grandes lotes sugiere que deberíamos escribir con menos frecuencia en ClickHouse. Esto, a su vez, puede provocar desbordamientos del búfer y pérdida de registros. La solución es aumentar el búfer de Fluentd, pero luego aumentará el consumo de memoria.
Nota : Otro lado problemático de nuestra solución ClickHouse fue que la partición en nuestro caso (loghouse) se implementó a través de tablas externas vinculadas por una tabla Merge . Esto lleva al hecho de que al muestrear intervalos de tiempo grandes, se requiere RAM excesiva, ya que la metatabla pasa por todas las particiones, incluso aquellas que obviamente no contienen los datos necesarios. Sin embargo, ahora este enfoque se puede declarar obsoleto de forma segura para las versiones actuales de ClickHouse (desde 18.16 ).Como resultado, queda claro que ClickHouse no tiene suficientes recursos para cada proyecto para recopilar registros en tiempo real (más precisamente, su distribución no será conveniente). Además, deberá usar una
batería , a la que volveremos. El caso descrito anteriormente es real. Y en ese momento no podíamos ofrecer una solución confiable y estable que se adaptara al cliente y permitiera recopilar registros con un retraso mínimo ...
¿Qué hay de Elasticsearch?
Elasticsearch es conocido por manejar cargas pesadas. Probémoslo en el mismo proyecto. Ahora la carga es la siguiente:
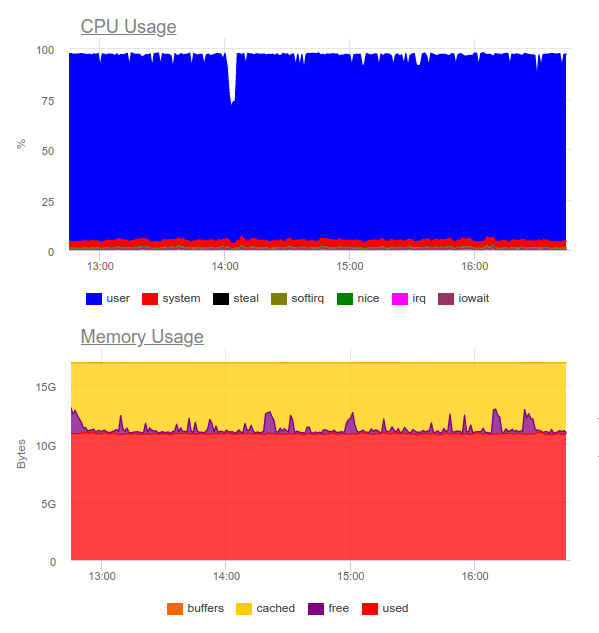
Elasticsearch fue capaz de digerir el flujo de datos, sin embargo, escribir tales volúmenes en él utiliza en gran medida la CPU. Esto lo decide la organización del clúster. Desde el punto de vista técnico, esto no es un problema, pero resulta que solo para el funcionamiento del sistema de recopilación de registros ya utilizamos alrededor de 8 núcleos y tenemos un componente adicional altamente cargado en el sistema ...
En pocas palabras: esta opción puede justificarse, pero solo si el proyecto es grande y su administración está lista para gastar recursos significativos en un sistema de registro centralizado.
Entonces surge una pregunta lógica:
¿Qué registros se necesitan realmente?

Intentemos cambiar el enfoque en sí: los registros deben ser informativos al mismo tiempo y no cubrir
todos los eventos del sistema.
Digamos que tenemos una tienda en línea próspera. ¿Qué registros son importantes? Recopilar tanta información como sea posible, por ejemplo, de una pasarela de pago es una gran idea. Pero del servicio de corte de imágenes en el catálogo de productos, no todos los registros son críticos para nosotros: solo los errores y la supervisión avanzada son suficientes (por ejemplo, el porcentaje de 500 errores que genera este componente).
Entonces llegamos a la
conclusión de que
el registro centralizado está lejos de estar siempre justificado . Muy a menudo, el cliente quiere recopilar todos los registros en un solo lugar, aunque de hecho solo el 5% de los mensajes que son críticos para el negocio se requieren de todo el registro:
- A veces es suficiente configurar, por ejemplo, solo el tamaño del registro del contenedor y el recopilador de errores (por ejemplo, Centinela).
- Para investigar incidentes, las alertas de error y un gran registro local a menudo pueden ser suficientes.
- Teníamos proyectos que costaban completamente solo pruebas funcionales y sistemas de recolección de errores. El desarrollador no necesitaba los registros como tales: vieron todo en las trazas de errores.
Ilustración de la vida
Un buen ejemplo es otra historia. Recibimos una solicitud del equipo de seguridad de uno de los clientes que ya tenía una solución comercial que se desarrolló mucho antes de la implementación de Kubernetes.
Se necesitó "hacer amigos" un sistema centralizado de recopilación de registros con un sensor corporativo para detectar problemas: QRadar. Este sistema puede recibir registros utilizando el protocolo syslog, para tomarlo desde FTP. Sin embargo, integrarlo con el complemento remote_syslog para fluentd no funcionó de inmediato
(como resultó, no somos los únicos ) . Los problemas con la configuración de QRadar estaban del lado del equipo de seguridad del cliente.
Como resultado, parte de los registros críticos para los negocios se cargaron a FTP QRadar, y la otra parte se redirigió a través de syslog remoto directamente desde los nodos. Para hacer esto, incluso escribimos un
gráfico simple : tal vez ayude a alguien a resolver un problema similar ... Gracias al esquema resultante, el cliente mismo recibió y analizó registros críticos (usando sus herramientas favoritas), y pudimos reducir el costo del sistema de registro, manteniendo solo el último mes
Otro ejemplo es bastante indicativo de cómo no hacerlo. Uno de nuestros clientes para manejar
cada evento proveniente del usuario, realizó una
salida de información no
estructurada multilínea al registro. Como puede suponer, tales registros eran extremadamente inconvenientes para leer y almacenar.
Criterios para los registros
Tales ejemplos llevan a la conclusión de que, además de elegir un sistema para recopilar registros, ¡también debe
diseñar los registros ellos mismos ! ¿Cuáles son los requisitos aquí?
- Los registros deben estar en un formato legible por máquina (por ejemplo, JSON).
- Los registros deben ser compactos y con la capacidad de cambiar el grado de registro para depurar posibles problemas. Al mismo tiempo, en entornos de producción, debe ejecutar sistemas con un nivel de registro como Advertencia o Error .
- Los registros deben estar normalizados, es decir, en el objeto de registro, todas las líneas deben tener el mismo tipo de campo.
Los registros no estructurados pueden provocar problemas al cargar registros en el repositorio y detener su procesamiento por completo. Para ilustrar, aquí hay un ejemplo con un error 400, que muchos seguramente encontraron en los registros fluidos:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"Un error significa que está enviando un campo cuyo tipo es inestable al índice con una asignación lista. El ejemplo más simple es un campo en el registro nginx con la variable
$upstream_status . Puede tener un número o una cadena. Por ejemplo:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}Los registros muestran que el servidor 10.100.0.10 respondió con el error 404 y la solicitud fue a otro almacén de contenido. Como resultado, en los registros, el significado se ha convertido así:
"upstream_response_time": "0.001, 0.007"Esta situación está tan extendida que incluso ganó una
mención por separado
en la documentación .
¿Y qué hay de la fiabilidad?
Hay momentos en que todos los registros son vitales sin excepción. Y con esto, los esquemas típicos de recopilación de registros para K8 propuestos / discutidos anteriormente tienen problemas.
Por ejemplo, fluentd no puede recolectar registros de contenedores de corta duración. En uno de nuestros proyectos, el contenedor con la migración de la base de datos duró menos de 4 segundos y luego se eliminó, de acuerdo con la anotación correspondiente:
"helm.sh/hook-delete-policy": hook-succeededDebido a esto, el registro de migración no entró en el repositorio. La política de
before-hook-creation puede ayudar en este caso.
Otro ejemplo es la rotación de los registros de Docker. Supongamos que hay una aplicación que escribe activamente en los registros. En condiciones normales, logramos procesar todos los registros, pero tan pronto como surge un problema, por ejemplo, como se describió anteriormente con el formato incorrecto, el procesamiento se detiene y Docker gira el archivo. En pocas palabras: los registros críticos para el negocio pueden perderse.
Por eso
es importante separar el flujo de registros , integrando el envío de los más valiosos directamente en la aplicación para garantizar su seguridad. Además, no será superfluo crear una especie de
"acumulador" de registros que pueda sobrevivir a la breve falta de disponibilidad del almacenamiento mientras se mantienen los mensajes críticos.
Finalmente, no olvide que
es importante monitorear cualquier subsistema de manera de calidad . De lo contrario, es fácil encontrar una situación en la que fluentd esté en el estado
CrashLoopBackOff y no envíe nada, lo que promete la pérdida de información importante.
Conclusiones
En este artículo, no consideramos soluciones SaaS como Datadog. Muchos de los problemas descritos aquí ya han sido resueltos de una forma u otra por empresas comerciales especializadas en recopilar registros, pero no todos pueden usar SaaS por varias razones
(las principales son el costo y el cumplimiento de 152-) .
La colección centralizada de registros al principio parece una tarea simple, pero no lo es en absoluto. Es importante recordar que:
- El registro detallado solo es un componente crítico y, para otros sistemas, puede configurar la supervisión y la recopilación de errores.
- Los registros en la producción deben minimizarse para no dar una carga adicional.
- Los registros deben ser legibles por máquina, normalizados, tener un formato estricto.
- Los registros realmente críticos deben enviarse en una secuencia separada, que debe separarse de las principales.
- Vale la pena considerar una batería de registro, que puede ahorrar de estallidos de alta carga y hacer que la carga en el almacenamiento sea más uniforme.

Estas reglas simples, si se aplican en todas partes, permitirían que los circuitos descritos anteriormente funcionen, a pesar de que carecen de componentes importantes (batería). Si no se adhiere a dichos principios, la tarea lo llevará fácilmente a usted y a la infraestructura a otro componente del sistema altamente cargado (y al mismo tiempo ineficaz).
PS
Lea también en nuestro blog: