
En una conferencia de desarrolladores de software de sistemas y herramientas, OS DAY 2016, que se celebró en Innopolis del 9 al 10 de junio de 2016 (Kazan) al analizar un informe sobre arquitectura multicelular, se expresó la idea de que sería más eficaz para resolver problemas de inteligencia artificial. Las condiciones para el desarrollo de un nuevo procesador de propósito general centrado en tareas de IA se han desarrollado este año.
El neuroprocesador S2 Multiclet, cuyo proyecto se presentó por primera vez en el Huawei Innovation Forum 2019, es un desarrollo adicional de la arquitectura multicelda. Se diferencia de las multiceldas creadas anteriormente con un sistema de comandos, a saber, la introducción de nuevos tipos de datos de pequeño tamaño (con punto fijo y flotante) y las operaciones con ellos. El número de células aumentó - 256 y la frecuencia - 2.5 GHz, lo que debería proporcionar un rendimiento máximo de 81.9 TFlops a 16F y, en consecuencia, hacerlo comparable, en términos de cálculos neuronales, con las capacidades de TPU ASIC especializados modernos (TPU-3: 90 TFlops a 16F).
Dado que la eficiencia del uso de procesadores depende en gran medida de la optimización del compilador, se ha desarrollado un esquema de optimización de código desarrollado.
Consideremos con más detalle.
El
artículo anterior mencionaba las optimizaciones del compilador que vale la pena implementar. Allí puede encontrar materiales sobre arquitectura multicelular si aún no está familiarizado con ella.
Generando comandos de dos argumentos con dos constantes
Se ha introducido un nuevo formato de instrucción con el procesador S1, que permite que ambos argumentos se especifiquen como un valor constante. Esto le permite reducir la cantidad de comandos en el código, eliminando comandos innecesarios como cargar para cargar constantes en el conmutador.
Por ejemplo:
load_l func wr_l @1, #SP
puede ser reemplazado por:
wr_l func, #SP
O incluso dos equipos a la vez:
load_l [foo] load_l [bar] add_l @1, @2
Hay dos direcciones constantes, y leerlas también puede sustituirse directamente en los argumentos del comando:
add_l [foo], [bar]
Esta optimización se implementó para todos los que admiten este formato. Desafortunadamente, resultó ser muy ineficaz, por dos razones:
- El número de situaciones en las que se puede llevar a cabo dicha optimización es muy pequeño. En el código de arbitraje, las situaciones rara vez surgen cuando necesita procesar de alguna manera dos valores que se conocen de antemano. Muy a menudo, tales cosas se deciden en la etapa de compilación, y solo queda un poco por hacer en tiempo de ejecución. Por lo general, estas son algunas operaciones en direcciones, nuevamente, constantes.
- Eliminar el comando de carga no libera al procesador del proceso de generación de la constante, sino solo de buscar un comando de carga por separado, que solo proporciona una aceleración débil, e incluso entonces no siempre.
Optimización de la transferencia de registros virtuales entre unidades base
En LLVM, los bloques básicos son secciones lineales en las que el código se ejecuta sin ramificación. Los párrafos en una arquitectura multicelular realizan exactamente la misma función, por lo tanto, la mayoría de las veces al generar un código, un párrafo refleja un bloque básico. En el procesador R1, cualquier transferencia de registros virtuales entre párrafos se realizó a través de la memoria escribiendo el valor del registro deseado en la pila y volviéndolo a leer en el párrafo que necesita este registro. Este mecanismo se divide en 2 partes: transferencia del registro virtual a otro párrafo para uso directo y transferencia del registro virtual como parámetro para el nodo phi.
Los nodos Phi son una consecuencia de la forma
SSA (asignación única estática) en la que se representa el lenguaje de presentación LLVM. De esta forma, una variable (o, como en el caso de LLVM IR - registros virtuales) solo se puede escribir una vez. Por ejemplo, este pseudocódigo:
a = 1; if (v < 10) a = 2; else a = 3; b = a;
no se presenta en forma SSA, porque el valor de la variable
a se puede sobrescribir. El código puede reescribirse en este formulario, si usa el nodo phi:
a1 = 1; if (v < 10) a2 = 2; else a3 = 3; b = phi(a2, a3);
El nodo phi selecciona a2 o a3, según el origen del flujo de control:
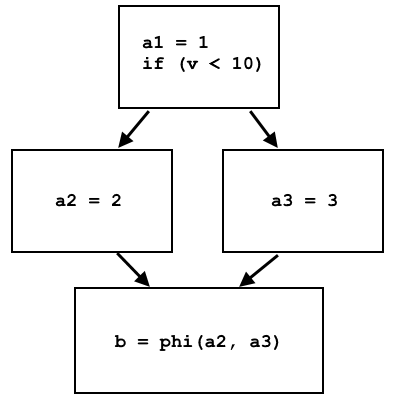
En LLVM IR phi, los nodos se implementan como una instrucción separada, que selecciona diferentes registros virtuales dependiendo de la unidad base de la que proviene el control. La implementación en el procesador de esta instrucción a través de la memoria es bastante simple: diferentes bloques base escriben datos diferentes en la misma celda de memoria, y en el nodo phi del sitio se lee esta celda de memoria, y los datos serán diferentes dependiendo del bloque base anterior.
El formulario SSA implica que cuando se inicializa el registro, el valor siempre será el mismo. Cuando se realiza la transferencia directa de registros virtuales, cuando el valor de cada registro virtual se escribe en su propia celda de memoria separada, la condición SSA se cumple sin problemas: los datos están en la memoria hasta que se sobrescriben. Sin embargo, si queremos transferir el registro a través del interruptor, debemos recordar: su tamaño es de solo 63 celdas, y cualquier valor desaparece cuando se ejecutan 63 comandos. Por lo tanto, si el registro virtual se escribe en algún primer párrafo y se usa después de que cientos de otros se hayan completado, entonces es imposible transferirlo a través del conmutador; solo queda memoria.
La implementación de esta optimización se inició precisamente con la optimización de los nodos phi, ya que, en contraste con la transferencia directa de registros virtuales, los valores de los parámetros para el nodo phi siempre se inicializan directamente en los párrafos anteriores (bloques base), lo que le permite no pensar mucho sobre si el interruptor es lo suficientemente grande. si queremos pasar estos parámetros a través de él.
El ensamblador multicelular le permite asignar nombres a los resultados de los comandos y usar sus resultados con este nombre. En lugar de que cada programador tenga que calcular cuántos comandos se obtuvo este resultado, el ensamblador calcula esto por su cuenta:
result := add_l [A], [B] ; ; ; wr_l @result, C
Este mecanismo funciona perfectamente dentro del párrafo actual, porque es una sección lineal y el orden de los comandos se conoce allí. Esto se usa activamente cuando el compilador genera código: todos los comandos tienen nombres asignados y el compilador no necesita preocuparse por numerar los comandos. Más precisamente, no era necesario, porque si queremos obtener el resultado de un comando ejecutado en otro párrafo, entonces el mecanismo no funciona: en la etapa de ensamblaje es imposible descubrir qué párrafo fue ejecutado realmente por el anterior si hay varias entradas en el actual. Por lo tanto, la única opción es acceder a los resultados de los equipos a través del número. Por esta razón, no puede simplemente arrojar registros / lecturas adicionales de la memoria en párrafos vecinos y reemplazar las referencias de registro del comando de lectura con el comando en el párrafo anterior.
Aquí vale la pena prestar atención a una consecuencia muy importante: si un párrafo tiene varias entradas, entonces
@ 1 en el primer comando de esta sección puede referirse a resultados completamente diferentes, dependiendo de qué párrafo fue el anterior. El nodo Phi es solo una situación así. Anteriormente, en todos los bloques básicos que inicializaban el nodo phi, los datos se escribían en la misma celda de memoria, y en lugar del nodo phi había una lectura de esta celda. Por lo tanto, no era absolutamente importante el lugar en el que había un registro en esta celda en los párrafos anteriores, al igual que el lugar en el que se leyó esta celda. Si se deshace del uso de la memoria, cambia.
Para permitir que los hosts phi usen un conmutador en lugar de memoria, se realizó lo siguiente:
- Todos los nodos phi en la unidad base actual se cuentan (y puede haber varios), se marcan con un número de serie y se ordenan en este orden
- Para cada nodo phi, se omiten los bloques iniciales que lo inicializan; se agregan comandos para cargar los valores en el conmutador ( loadu_q ), marcados con el número de serie del nodo phi correspondiente.
- La instrucción phi del nodo en sí también se reemplaza por loadu_q con su número de serie
- Todos los comandos agregados se reorganizan en el orden dado
El cuarto punto es necesario por la razón ya indicada: si queremos que el
comando loadu_q @ 3 acceda al resultado específicamente para su nodo phi, entonces todos los párrafos de inicialización del comando que carga los datos en el conmutador deben estar exactamente en el mismo orden. Pongamos un ejemplo del resultado real de compilar código en el que hay dos nodos phi en una unidad base.
Párrafos con inicializadores nodos phi:
LBB1_27: LBB1_30: SR4 := loadu_q @1 setjf_l @0, LBB1_31 setjf_l @0, LBB1_31 SR4 := loadu_q [#SP + 8] SR5 := loadu_q [#SP + 16] SR5 := loadu_q [#SP] SR6 := loadu_l 0x1 SR6 := add_l @SR4, 0xffffffff SR7 := add_l @SR6, [@SR4] loadu_q @SR5 wr_l @SR7, @SR4 loadu_q @SR6 loadu_q @SR6 complete loadu_q @SR5 complete
Un párrafo con dos nodos phi:
LBB1_31: SR4 := loadu_q @2 SR5 := loadu_q @2 SR6 := loadu_l [#SP + 124] SR7 := loadu_l [#SP + 120] setjf_l @0, @SR7 setrg_q #RETV, @SR4 wr_l @SR5, @SR6 setrg_q #SP, #SP + 120 complete
Anteriormente, en lugar de los comandos
loadu_q, habría escrituras en la memoria y lecturas de la misma.
En el proceso de implementación de esta optimización, también hubo algunos problemas que no se habían previsto de antemano:
- Algunas optimizaciones de código existentes reorganizan los comandos en lugares, por ejemplo, colocando la dirección del siguiente párrafo al comienzo del actual, o la ubicación de los comandos de lectura / escritura de memoria al principio / final del párrafo, respectivamente. Estas optimizaciones ocurren después de las operaciones con nodos phi (las llamadas instrucciones LLVM de reducción antes de las instrucciones del procesador), por lo que a menudo interrumpen el orden incorporado de los comandos loadu_q . Para no interrumpir el trabajo de estas optimizaciones, tuve que crear un pase LLVM separado, que organiza los comandos para los nodos phi en el orden correcto después de todas las otras manipulaciones con los comandos.
- Resultó que puede surgir una situación en la que una unidad base inicializa nodos phi para dos unidades base diferentes. Es decir, siguiendo el algoritmo indicado, estos bloques base se agregarán al comando de inicialización loadu_q para cada nodo phi. En este caso, incluso si tienen un solo nodo phi, en la sección de inicialización habrá 2 comandos loadu_q , que, lógicamente, ambos deberían estar en el último lugar, lo que, por supuesto, es imposible. Afortunadamente, tales situaciones son bastante raras, por lo que si hay una unidad base en la que los nodos phi se inicializan para más de otra unidad base, solo el primero usa el interruptor de acuerdo con el algoritmo, para el resto, como antes, a través de la memoria.
Toda esta optimización de los nodos phi se puede complementar un poco más. Por ejemplo, si mira el párrafo
LBB1_30 anterior, puede ver que
loadu_q ordena valores de carga que no se usan en ningún otro lugar. Es decir, si elimina
loadu_q y establece los comandos que crean estos valores en el mismo orden, los comandos
loadu_q @ 2 en la siguiente sección también cargarán los valores correctos.
Puntos de referencia
Los resultados de optimización actuales se probaron en los puntos de referencia de CoreMark y WhetStone, cuya descripción se puede encontrar en el
artículo anterior . Comencemos con los resultados de CoreMark en el núcleo S2 en comparación con los resultados anteriores (versión anterior del compilador en el núcleo S1).
Los valores relativos de CoreMark / MHz se muestran en el histograma:

Para obtener una estimación de la aceleración solo debido a la optimización de los nodos phi, puede volver a calcular el indicador CoreMark en un multicelda en núcleos S1 y S2 para una frecuencia de 1600 MHz: son 1147 y 1224, respectivamente, lo que significa un aumento del 6,7%.
Con WhetStone, la situación es algo diferente. Los cambios en el núcleo aquí influyeron en el resultado, además, este punto de referencia se ejecuta en un núcleo (multicelda) y se calcula en términos de megahercios, por lo que la frecuencia del procesador no juega ningún papel.
Tarjeta de puntuación de piedra de afilar:
Ahora está claro que incluso cuando se usa la versión anterior del compilador en el núcleo S1, el índice general es más alto, principalmente debido a las pruebas de punto flotante MFLOPS1-3. Este inconveniente se notó durante las pruebas y se debe al hecho de que el transportador interno del bloque de coma flotante en S2, en comparación con S1, es un paso más. Como resultado, las sucesivas cadenas de comandos relacionados con datos perdieron una medida en cada comando. La necesidad de este paso fue causada por una reducción en la duración del ciclo del reloj (un aumento en la frecuencia del procesador de 1.6 GHz a 2.5 GHz y un aumento en la nomenclatura de comandos, por ejemplo, la aparición del comando de multiplicación con la acumulación de MAC). Esta decisión es temporal. Se está trabajando para reducir la longitud de la tubería, y en el futuro esto se solucionará, pero se realizaron pruebas en la versión actual de S2.
Para evaluar la aceleración de la optimización del compilador, WhetStone también se compiló en una versión anterior y se lanzó en la versión actual de S2. El indicador total fue 0.3068 MWIPS / MHz versus 0.3267 MWIPS / MHz en el nuevo compilador, es decir. que muestra una aceleración del 6.5% debido a las optimizaciones anteriores.
El sistema de optimización desarrollado y probado le permite implementar en el futuro el siguiente esquema de optimización, a saber, la transferencia directa de registros virtuales a través del conmutador. Como ya se mencionó, no todas las copias del registro virtual se pueden hacer a través del conmutador. Debido al tamaño limitado del interruptor y la imposibilidad de acceder correctamente a los resultados de los párrafos anteriores si hay varios puntos de entrada al actual (esto se resuelve parcialmente mediante nodos phi), la única opción posible es copiar registros virtuales de un párrafo directamente al siguiente, pero solo hay uno anterior . Tales casos, de hecho, no son tan pocos, a menudo es necesario transferir datos de manera tan directa, aunque la aceleración del código que dará para decir por adelantado es, por supuesto, difícil.