Tarde o temprano, cualquier servicio en crecimiento tiene que evaluar sus capacidades técnicas. ¿A cuántos visitantes podemos servir? ¿Cuál es la capacidad del sistema? ¿Hemos alcanzado el límite y no caeremos si atraemos a varios miles de usuarios más? ¿Cuántos recursos informáticos adicionales se presupuestan para el próximo año para cumplir con los planes de crecimiento?
Las respuestas se pueden obtener analíticamente dirigiendo preguntas a un desarrollador experimentado / DevOps / SRE / admin. La confiabilidad de la evaluación depende de una gran cantidad de factores: comenzando por el ritmo de llenado del sistema con funcionalidad y el gráfico de las relaciones entre los componentes y terminando con el tiempo que el experto pasó la mañana en el tráfico. Cuanto más complejo es el sistema, más dudas hay en la idoneidad de la evaluación analítica.
Mi nombre es Maxim Kupriyanov, hace cinco años que trabajo en Yandex.Market. Hoy les contaré a los lectores de Habr cómo aprendimos a evaluar la capacidad de nuestros servicios y lo que surgió de ellos.
Vamos al puesto
La estructura de los componentes del mercado es bastante complicada, por lo que decidimos evaluar la capacidad de los servicios más grandes y caros en escala. Además, el número diario de solicitudes para ellas debe depender claramente del tamaño de la audiencia diaria del mercado (usuarios activos diarios, DAU). ¿Por qué exactamente de DAU? Porque los analistas, que hacen pronósticos para los próximos meses y años, siempre calculan el tamaño futuro de la audiencia, y aprovecharemos esta agradable circunstancia.
Ahora hablemos sin lo cual es imposible construir evaluaciones objetivas: sobre las métricas del servicio. Si el número de solicitudes de servicio depende de la DAU, entonces definitivamente necesitamos la métrica "solicitudes por segundo" (solicitudes por segundo, RPS). Además, para evaluar la calidad del servicio, debe conocer el porcentaje de errores y los tiempos de respuesta (tiempos de solicitud). El error se considerará una respuesta con un código HTTP de 500 o superior. Los errores del rango 4xx son del lado del cliente y, en un sistema que normalmente funciona, generalmente no dicen nada acerca de los problemas de servicio. En cuanto a los tiempos, aquí se acostumbra contar y almacenar los percentiles 80, 95, 99 y 99,9 de los tiempos de respuesta, pero un conjunto específico puede diferir ligeramente de un servicio a otro.
Entonces, tenemos métricas de frecuencia de solicitud, porcentaje de errores y un conjunto de percentiles de tiempo de respuesta. Y también conocemos el servicio DAU para todos los días y para períodos futuros (en forma de pronóstico). Dado que los patrones promediados del comportamiento del usuario no cambian demasiado de un día a otro, digamos lo siguiente: conociendo RPS en el período más activo del día laboral (RPS pico), podemos predecir RPS pico para períodos futuros, siempre que tengamos un pronóstico DAU. Y viceversa: si sabemos cuántas solicitudes por segundo puede soportar el sistema sin violar el acuerdo sobre el tiempo de respuesta y el porcentaje de errores, entonces podemos estimar cuánta audiencia podemos atender, es decir, sabemos la capacidad del sistema.
Bueno, decidimos la tarea: corregir los tiempos de respuesta y el porcentaje de errores en forma de acuerdos y encontrar el RPS máximo que el sistema puede soportar en estas condiciones. ¿Cómo vamos a decidir?
Disparamos al objetivo
Aquí hay un enfoque clásico para resolver el problema: recopilamos un sitio de prueba, tomamos registros del sistema de acceso del entorno de producción, hacemos cartuchos de ellos y disparamos el sistema, aumentando la frecuencia de las solicitudes, hasta que el sitio muestre una degradación significativa en los tiempos de respuesta y / o errores. En este punto, detenemos y arreglamos la frecuencia de las solicitudes (el mismo RPS). Victoria No importa como. Y aquí está el por qué:
- el sitio de prueba, por regla general, no es idéntico a la plataforma bajo el servicio en el entorno de producción;
- el código de servicio cambia todos los días, o incluso más a menudo;
- los experimentos pueden influir en la carga;
- la gravedad de las solicitudes de los usuarios depende de la hora del día y otras condiciones;
- los servicios modernos rara vez funcionan de forma aislada, con mayor frecuencia realizan subconsultas a otros servicios, y esto deberá tenerse en cuenta de alguna manera.
Mejora: activaremos el servicio automáticamente todos los días, recogiendo cartuchos de revistas en las horas pico. Y para no desperdiciar recursos en un sitio de prueba, comenzaremos a bombardear componentes que nos interesan en el mismo puesto. Suena complicado y no resuelve todos los problemas. ¿Pero qué otras opciones hay?
Simula la realidad
La idea general es esta: copiamos parte del tráfico de los equilibradores al sitio, donde recopilamos el análogo completo del entorno de producción en miniatura y, ajustando el volumen del tráfico copiado, buscamos el punto de degradación. La idea es hermosa, y nosotros en el mercado hacemos esto para probar nuevas funciones y comparar el comportamiento de las nuevas versiones con las antiguas. Mi colega Eugene
habló sobre esto en detalle: consulte la sección sobre el clúster de sombra. Pero también hay dificultades obvias:
- el problema de interactuar con componentes externos no está resuelto, ya que es muy costoso hacer una copia de todo el entorno de producción;
- los registros de solicitud del sistema espejo pueden mezclarse accidentalmente con los registros del entorno de producción, lo que significa que es necesario construir un sistema con señalización del tráfico espejo para poder encontrarlo y limpiarlo;
- Por lo general, las solicitudes se reflejan en su totalidad o como un porcentaje del total, y esa precisión no nos conviene (pero esto se puede resolver, estamos trabajando en esta dirección).
En general, la imitación de producción es un enfoque muy bueno y prometedor, pero muy costoso y con limitaciones significativas.
Probar directamente en producción
Y luego finalmente llegamos a lo delicioso. Para cada componente probado, planteamos una instancia separada en producción, cuya frecuencia de solicitudes se regula desde el equilibrador con alta precisión. La última vez, los
lectores nos preguntaron : “¿HAProxy es suficiente para ti? ¿Había necesidad de escribir algo propio? Entonces, este es el caso muy raro cuando no fue suficiente y tuve que escribir.
Al mismo tiempo, hay un servicio separado que monitorea de cerca las métricas de la instancia cargada y, cuando los indicadores se acercan a los valores críticos, cierra la válvula en el equilibrador, reduciendo la frecuencia de las solicitudes. Si el servicio funciona dentro de límites aceptables, la válvula, por el contrario, se abre. Por supuesto, los umbrales para los tiempos y los errores al cargar un servicio en vivo son notablemente más conservadores (generalmente entre un 5 y un 10%) que en el campo de entrenamiento, porque no queremos empeorar la interacción con los usuarios. Por lo tanto, la instancia cargada siempre funciona hasta el límite. Arreglamos estos indicadores. Y luego tenemos la aritmética: sabemos la cantidad de núcleos de servicio bajo carga en todo momento, sabemos la DAU ayer. A partir de esto, consideramos el reciclaje, las reservas de capacidad y las opciones de comportamiento del sistema al deshabilitar una u otra ubicación. Todo esto se establece en la base desde donde se construyen hermosos gráficos. Según estos datos, cuando la capacidad cae por debajo del umbral, se activan alertas.
Veamos los gráficos.
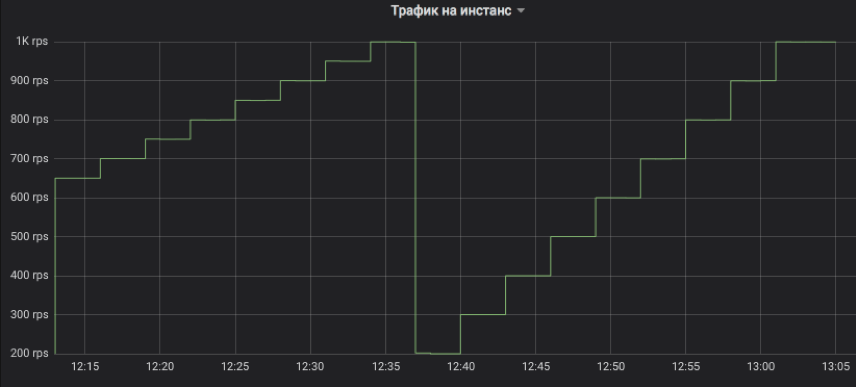
Así es como controlamos el flujo de tráfico a la instancia probada. El paso puede ser cualquier múltiplo de 1 RPS. En el gráfico, a modo de ilustración, modelamos una escalada con un intervalo de tres minutos: primero, de 650 a 1K RPS en incrementos de 50, y luego de 200 a 1K RPS en incrementos de 100. Permítanme recordarles que este es el tráfico real de usuarios al que los clientes recibieron respuestas.
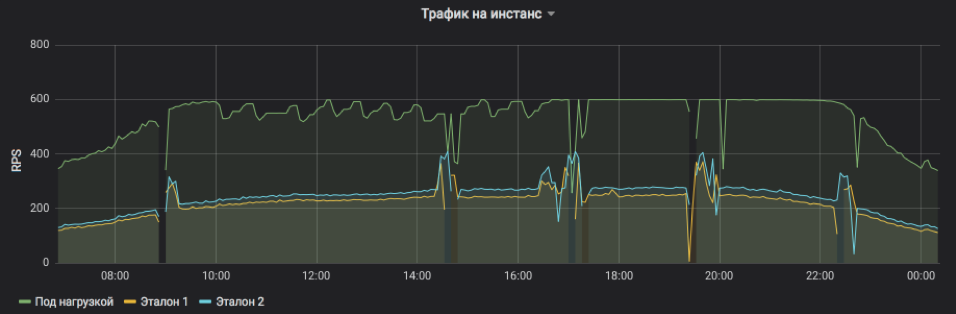
Esto muestra RPS para tres instancias: una bajo carga y dos de control. El sujeto se estableció artificialmente un límite superior de 600 RPS. El servicio puede ser más, pero se vuelve demasiado inestable y depende de influencias externas. Se ve claramente que en la primera mitad del día las solicitudes de servicio son, en promedio, más pesadas y la instancia no puede alcanzar su capacidad máxima en condiciones aceptables, pero hacia la noche, todo vuelve a la normalidad. Las ráfagas y las omisiones en el gráfico son reinicios de instancias para distribuir lanzamientos y otras actualizaciones (todos están en equilibrio, nadie resultó herido). Y los ajustes RPS paso a paso en el sujeto de prueba son solo el trabajo de un algoritmo que busca el límite de posibilidades.

La frecuencia de las solicitudes de servicio y la carga que una instancia puede soportar son claramente visibles.
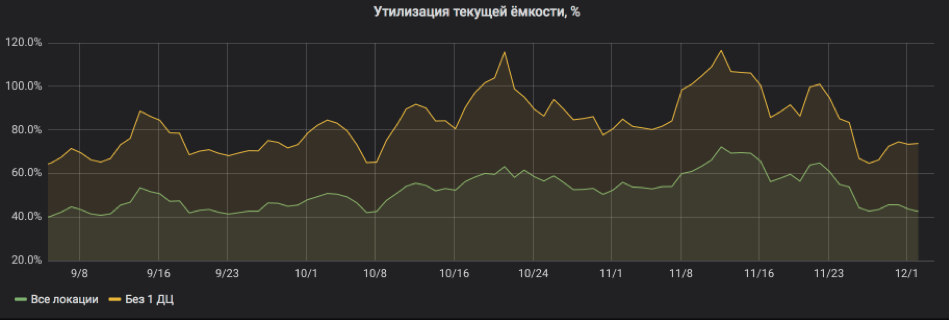
Y aquí recalculamos todo en porcentaje de utilización. El gráfico muestra que el servicio estaba bastante cargado y cuando una de las ubicaciones estaba apagada, había riesgos de irse a SLA. Pero ahora todo está bien: se han agregado recursos al servicio, el reciclaje ha vuelto a límites aceptables.
Por lo tanto, las pruebas de carga en producción le permiten evaluar rápidamente la capacidad del sistema y predecir el consumo de recursos para períodos futuros. Al mismo tiempo, el sistema en realidad no agrega gastos apreciables y puede trabajar de manera segura con servicios con estado, ya que no generamos tráfico nuevo, sino que solo redistribuimos con precisión el que es. Y finalmente: para trabajar, por regla general, no es necesario cambiar el código del sistema experimental en sí, lo que permite probar incluso las aplicaciones heredadas.
Reflexionar
Esta metodología no ha estado funcionando en el mercado por más de un año, y podemos compartir observaciones y recomendaciones:
- Junto a la instancia cargada, debe haber un control ordinario, y preferiblemente vapor, ya que la degradación a menudo ocurre no porque la instancia esté sobrecargada, sino por problemas generales con el servicio en su conjunto.
- La técnica funciona bien solo con aquellos componentes cuya carga es superior a cientos de solicitudes por segundo para una ubicación. La razón es bastante simple: necesitamos cargar tanto la instancia probada como una o dos de control. Si no hay suficiente tráfico, no alcanzaremos la saturación o no podremos comparar honestamente. Y si el límite de RPS por instancia es muy pequeño, entonces el paso mínimo de cambiar la frecuencia de solicitud a 1 RPS puede ser demasiado aproximado.
- Es mejor probar frentes y backends en diferentes ubicaciones, de modo que los artefactos de backends de prueba de carga no afecten la estimación de la capacidad frontal.
- Cuando analizamos los tiempos de respuesta y buscamos signos de degradación, generalmente tomamos agregados de cinco minutos y contamos la mediana para no reaccionar a explosiones aleatorias.
- La razón principal por la que la instancia cargada del servicio se bloquea es el espacio en disco para los archivos de registro (registros). Siempre se olvidan de él.
- El inicio de sesión en un disco de servidores web cargado con E / S es una razón muy común para empeorar los tiempos, incluso en SSD. Siempre active el almacenamiento en búfer, la grabación asincrónica y cualquier otra cosa, solo para no esperar hasta que termine la grabación.
- La carga nocturna no es indicativa, ya que las solicitudes son en promedio más pesadas debido a la mayor proporción de robots. Por lo tanto, para estimar la capacidad, es mejor fijar el rango del horario de luz convencional del día y de noche solo para reducir el flujo de solicitudes si aparecen signos de degradación.
- El percentil 99.9 de los tiempos de respuesta es inútil para la estimación de capacidad, ya que las garantías de disponibilidad de la red rara vez superan el 99%.
- Comience una línea de tiempo y registre lanzamientos de servicios y otros eventos importantes. Ayuda a encontrar lo que condujo a una disminución de la capacidad.
- En un análisis detallado de las causas de la degradación, el rastreo también es útil: se agrega un encabezado de marcador a cada solicitud de servicio, que va desde el frente hasta el último backend e ingresa todos los registros. De esta manera, puede rastrear la ruta de solicitud completa y comprender qué causa los retrasos.