Python entiende todos los formatos de archivo populares. Además, cada biblioteca tiene su propio formato de "tubo caliente". La sintaxis, por supuesto, en cada formato es puramente individual. Reuní todas las funciones para trabajar con archivos de diferentes formatos en una hoja A4, con la aplicación como ejemplo de uso en el cuaderno jupyter.
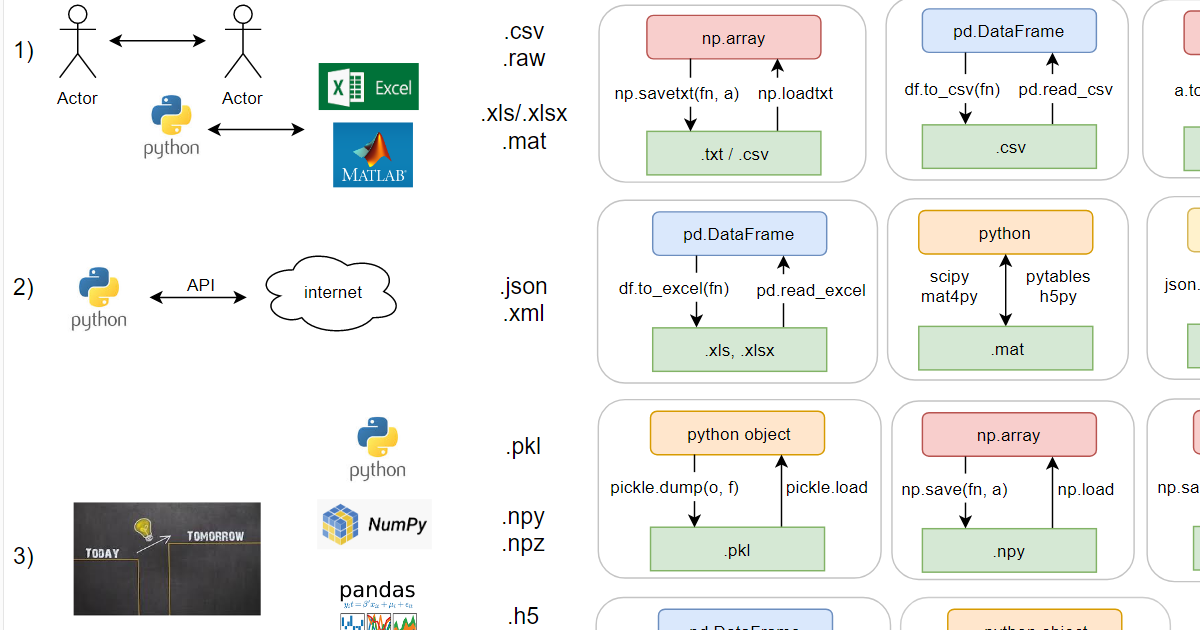
Dividí condicionalmente los formatos en tres bloques según el método de uso. Como usted sabe, se necesitan archivos para intercambiar información: entre personas, entre programas (primer bloque), entre una computadora y una red (segundo) y "guardar juego", entre el mismo programa en diferentes momentos (tercer bloque).
Brevemente sobre cada bloque:
1) Formatos universales:
- .csv - texto, valores separados en principio por comas, pero por ejemplo, el exel ruso prefiere separarlo con punto y coma, ya que la coma ya se usa en el idioma ruso como separador decimal;
- .raw es un formato binario para quienes no les gustan los formatos de archivo. El tipo de datos y, si los datos son multidimensionales, los tamaños correspondientes deben transferirse por separado, solo los datos en sí mismos en el archivo;
- .xls / .xlsx: el antiguo binario (limitación de 65k líneas) y los nuevos formatos xml exel;
- En realidad, .mat también tiene dos formatos (ambos binarios): el antiguo propietario y el nuevo basado en hdf5. Python puede funcionar con ambos (a través de bibliotecas).
2) Formatos de "red":
- .json - textual, parece un diccionario en python, pero las comillas solo se pueden usar dobles;
- .xml: textual, similar a html.
3) Formatos nativos de python:
- .pkl es un formato binario, todos los objetos de Python integrados pueden guardarlo. Las clases personalizadas también pueden hacerlo, y si la pitón guarda algo mal, puede ayudarlo a través de métodos mágicos. Admite agregar al final de un archivo existente.
- .npy y .npz: en numpy hay hasta dos de sus formatos (ambos binarios). Aparecieron como reacción a la pérdida de compatibilidad con versiones anteriores en pkl en el momento de la transición python v2-> v3. La sobrecarga es mínima (~ 100 bytes más que el raw correspondiente; pkl, sin embargo, es ligeramente mayor: ~ 150 bytes más que el raw). En .npy puede guardar solo una matriz, y en npz, varias a la vez, y posteriormente puede sacarlas de allí por su nombre.
- .h5: formato binario hdf5. Es de destacar que en él puede almacenar una estructura de datos jerárquica completa, es casi un sistema de archivos en un archivo. Además, se puede abrir en matlab sin conversión. Contras:
a) los archivos pequeños ocupan un espacio excesivamente grande (por ejemplo, 300 bytes pkl frente a 3.1 Mb para h5),
b) muchos errores ,
c) se está agregando a un archivo existente, pero si ocurre un error (como sucede), obtener datos de él será problemático.
Aquí hay un análisis detallado de los pros y los contras de hdf5, en resumen, un buen formato para el intercambio de datos, malo, para usar como un sistema de archivos (por ejemplo, no puede borrar una matriz, solo copie el archivo sin ella). - .parquet es un formato binario para big data. Apache Parquet no es un formato nativo de Python, pero está bien integrado en los pandas. Puede comprimir / expandir sobre la marcha (rle, gzip, codificación de diccionario); se comprime un poco mejor que Apache Avro. A diferencia de avro, donde los datos se almacenan línea por línea (como el orden C), en el parquet los datos se almacenan columna por columna (como el orden fortran). Gracias a esto, puede trabajar eficazmente con tablas con una gran cantidad de columnas.
- jupyter decidió no reinventar la rueda:% store la guarda en formato .pkl, pero por alguna razón sin extensión.
Hoja de revestimiento en sí:
- en formato
pdf- en formato png:

Un ejemplo del uso de todas las funciones de un diagrama:
html con tabla de contenido y fuente de ipynb