Muchos ya saben que en el lanzamiento de la plataforma 8.3.14.1565, el navegador Internet Explorer fue reemplazado por el Web-Kit, esto es en realidad un gran paso adelante, pero estoy seguro de que, como yo, aún no está claro qué es qué. Hubo una experiencia de usar web-kit en 1C, llamando a JS desde 1C y llamando a 1C desde JS. Tratemos de entender juntos cómo se diferencia uno del otro y, al mismo tiempo, hagamos algo útil. Sí, y seguramente muchos tendrán que reescribir sus manualidades similares después de actualizar a una nueva plataforma, por lo que espero que mi experiencia sea útil.
Todo comenzó con el hecho de que surgió la tarea: "Queremos, en UT, ingresar una descripción formateada del producto para que luego vuele a la tienda en línea", porque la descripción estándar del producto llega en una línea continua sin guiones y no se ve muy bien. Inmediatamente hubo un deseo de usar un documento formateado, hay un editor simple y puedes subirlo a HTML. Pero tan pronto como mostré el HTML generado por el documento formateado a los desarrolladores web, inmediatamente agitaron sus manos y dijeron que esto no funcionaría. El sitio ya tiene sus propios estilos para mostrar los elementos de bloque necesarios y el comportamiento de este tipo de texto puede volverse impredecible.
La función Obtener HTML de un documento formateado devuelve una página HTML completamente formada, con toda la estructura de las etiquetas, y lo que es más desagradable, con estilos en línea. Se ve así.
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <meta http-equiv="X-UA-Compatible" content="IE=Edge" /> <meta name="format-detection" content="telephone=no" /> <style type="text/css"> body{margin:0;padding:8px;} p{line-height:1.15;margin:0;white-space:pre-wrap;} ol,ul{margin-top:0;margin-bottom:0;} img{border:none;} li>p{display:inline;} </style> </head> <body> <p><span style="text-decoration: underline;"></span></p> <p><span style="font-weight: bold;"> </span></p> <p><span style="color: #ff0000;font-weight: normal;"> </span></p> <p><br></p> </body> </html>
Y si obtener el contenido de la etiqueta del cuerpo es una tarea simple, entonces no quería analizar y recortar los atributos de estilo de las etiquetas.
TinyMCE trae de vuelta un diseño agradable. Permitirse estilos en línea solo en el caso del color, que ya es mucho mejor.
<p></p> <p><strong></strong></p> <p><span style="color: #ff0000;"></span></p>
Se decidió integrar TinyMCE, un editor de texto de terceros. Además, la experiencia de su integración con la comunidad 1C ya es bastante grande.
Tal vez fue un error entonces, y solo tenía que analizar el texto generado por un documento formateado, pero tenemos lo que tenemos.
1. Características de la solución.
Dado que 1C no permite cargar archivos locales desde el sistema de archivos a la página en el campo HTML, para esto definitivamente necesita un servidor web o al menos la dirección de este archivo en almacenamiento temporal, coloque la biblioteca Tiny js al lado de 1C y cárguela en los encabezados del documento HTML no puede: también tendrá que crear un archivo con un diseño HTML que internamente forme una ventana de editor preparada y que ya esté conectada al documento HTML.
En general, de hecho, puede cargar una biblioteca si obtiene una dirección para ella en el repositorio si se compiló en un archivo, y Tiny, además de la biblioteca principal, también contiene archivos js, un administrador de estilos y estilos, archivos crack ellos mismos , íconos, etc., y como lo entiendes, esto complica enormemente la tarea. Hubo un tiempo en que incluso surgió la idea de compilar todo esto en un solo archivo y no conocer los problemas, pero llevó mucho tiempo comprender las herramientas. Luego se encontró TinyMCE Builder en el sitio web oficial, que compila todos los js en un solo archivo y sería una pequeña victoria si hiciera lo mismo con css, pero no, css aún se encuentra junto a varias carpetas.
TinyMCE crea un iframe para la ventana de edición, que en sí mismo es un documento HTML incrustado en la página, por lo que los eventos que ocurren en este iframe 1C no pueden rastrearse, más sobre eso a continuación.
La configuración de UT 11.4 en el momento del desarrollo tenía un modo de compatibilidad de 8.3.12, de modo que ahora usaba IE como navegador incorporado, pero una actualización adicional implicaba una transición a nuevas versiones que ya usan el kit web.
2. Primeros pasos
Las principales diferencias en el trabajo con el kit web:
El objeto principal de los campos HTML ahora tiene una estructura diferente y para trabajar con el contenido de la página debe usar la propiedad
defaultView .HTML.Document.DefaultView
utilizamos previamente la propiedad
parentWindow para esto
.HTML.Document.parentWindow
La prohibición de usar eval, que solía usarse universalmente para invocar código JS. Algo como esto
Elements.FieldHTML.Document.parentWindow.eval ("alert ('Código de llamada de 1C')")
Pero puede acceder a los métodos directamente desde 1C.
Elements.Description HTML.Document.DefaultView.NameMethodJS ();
Y rápidamente construí funciones de ajuste para todos los métodos de Tiny que necesito.
function GetText(){ return tinyMCE.activeEditor.getContent({format: "text"}); } function SetText(text){ return tinyMCE.activeEditor.setContent(text); } function GetHTML(){ return tinyMCE.activeEditor.getContent(); }
Que además se dirigió desde 1C
HTML = .HTML.Document.DefaultView; HTML = HTML.GetHTML(); = HTML.GetText();
Aunque se podría pasar con llamadas directas al objeto editor, por ejemplo,
.HTML..defaultView.tinyMCE.activeEditor.getContent()
El procesamiento de la publicación se descargó de inmediato (un respeto separado al autor), lo que me mostró muchas cosas interesantes. Funcionó más o menos en IE, pero copiar y pegar no funcionó en webkit, al principio causó un estupor, pero luego quedó claro que era por el iframe que el campo HTML no estaba activado al hacer clic dentro de él, ya que el clic realmente ocurrió en el documento adjunto HTML cuyos eventos se atascaron en algún lugar en el camino a 1C. Y, por lo tanto, si presiona Ctrl + C en un lugar del formulario e intenta pegarlo dentro del campo del editor, el texto se insertará en ese campo desde donde se copió porque el campo HTML del documento no está activado. Lo mismo sucede en el caso contrario, los atajos de teclado para copiar y pegar no funcionan.
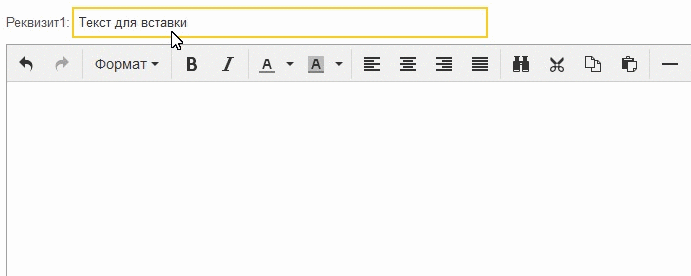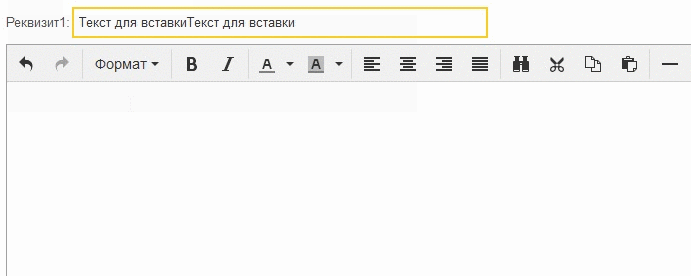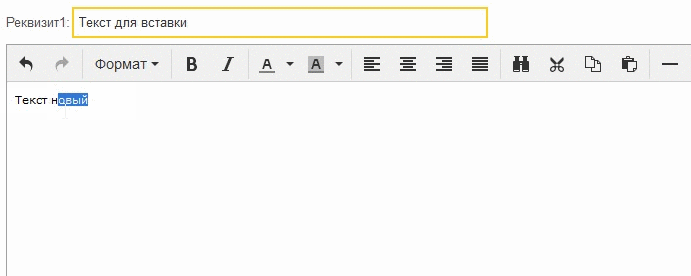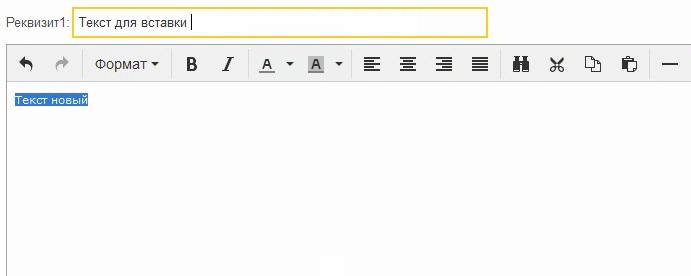
Al principio, surgió la idea de que era una jamba Tiny, y bloquea la pasta directa del búfer, como CKEditor, que ofrece una ventana separada para pegar desde el búfer. Pero para comprobar que fue bastante fácil, creé un documento vacío con un campo de entrada e intenté copiar y pegar

Como puedes ver, todo funciona. Entonces, el problema está en algún lugar de Tiny o en interacción con 1C.
3. Decisión
Para resolver el problema con la interacción del navegador y 1C, se aplicó el truco habitual, creé un botón invisible en la página HTML y planeé hacer clic en él desde JS cuando ocurrieron los eventos necesarios dentro de la página que 1C interceptaría en el evento HTML Press. ¿Pero en qué evento llevar a cabo un programa de prensa?
El diseño se ve así:
<body> <textarea id="editor"></textarea> <button id="button1c" style="display: none"></button> </body>
Y una función para activar un evento de clic de botón
function clickButton() { button1c.click(); }
Anteriormente, era posible transferir un objeto de forma 1C en el campo HTML como un objeto, y debido al hecho de que IE se conectaba a 1C a través de COM, el formulario en sí mismo se convertía de alguna manera en un objeto que IE entendía y era posible llamar a las funciones de exportación de la forma 1C directamente desde el código JS . Ahora es imposible.
Estudiamos la documentación de Tiny API y encontramos una construcción para interceptar controladores de eventos y una combinación adecuada de eventos que deberían activar el campo HTML del documento
tinymce.activeEditor.on('click', function(e){clickButton(e)}); tinymce.activeEditor.on('KeyDown', function(e){clickButton(e)});
Debe poner este código en el lugar donde Tiny ya se inicializó. Hice esto en el controlador de carga del objeto de
ventana . Pero puede hacerlo más bellamente y colocar el código al inicializar Tiny en el parámetro:
init_instance_callback
Ahora todo debería estar en orden. Y la forma debería funcionar como debería ...
Se hizo mucho mejor, el campo HTML realmente comenzó a activarse, pero no siempre, por alguna razón, algunos clics no hicieron que el foco se moviera al campo:
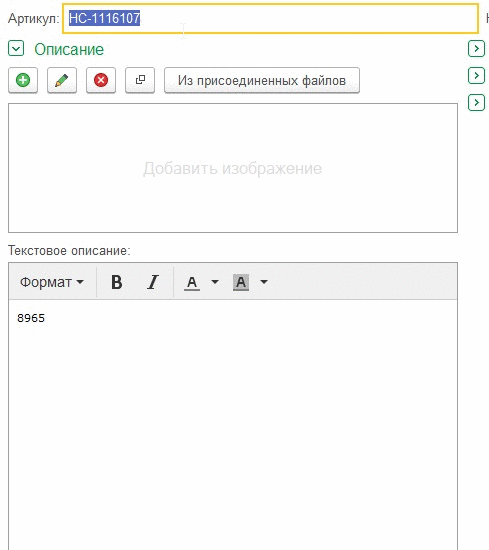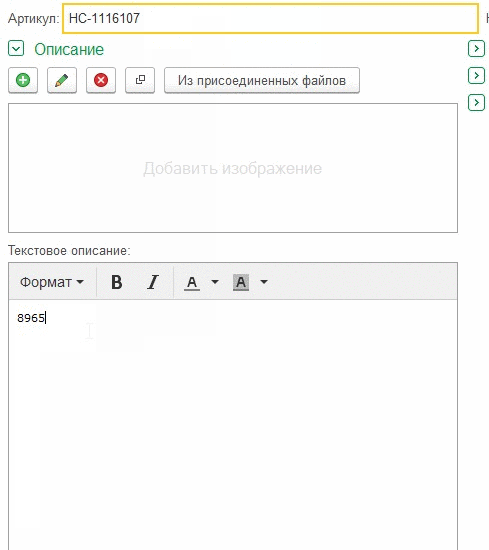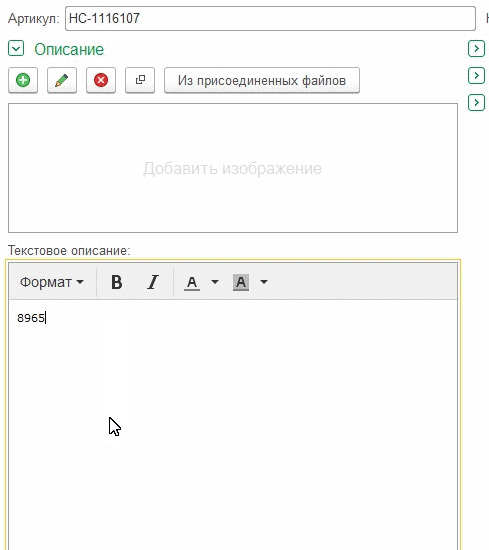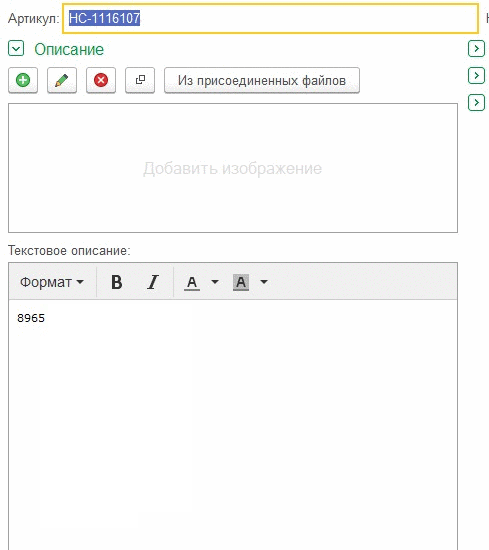
Este registro muestra que si hace clic en la línea donde parpadea el cursor, el foco del campo funciona como debería, pero si hace clic a continuación, el campo no se activa.
Era un artefacto molesto, y los intentos de comprender lo que estaba sucediendo no dieron ninguna solución. Envié alertas al controlador y se mostraron alertas, pero 1C no respondió al evento

De repente, se me ocurrió la idea: qué pasa si 1C no logra procesar el evento que ocurre en el campo, qué pasa si ralentizas un poco la ejecución del script JS y ves lo que sucede. La función de pausa en JS se implementó rápidamente usando promesas y espera asíncrona. Como puede ver en JS, tampoco existe por defecto y nada, la gente vive).
function sleep(ms){ return new Promise(resolve => setTimeout(resolve, ms)); } async function clickButton(e){ await sleep(1); button1c.click(); }
Aquí configuro el retraso en un milisegundo, antes de hacer clic en el botón. Y voila, funcionó. 1C comenzó a procesar el clic de un botón a tiempo.
4. Terminamos el intercambio.
Dado que para almacenar la nueva descripción en formato HTML, se agregó un nuevo atributo al directorio, debemos reemplazar el valor del campo típico durante la descarga. Para hacer esto, en el módulo ExchangeSiteRemoveable, agregue la función GetTexts de RequestsCatalog a la extensión y escriba allí:
. = (., ".", ".HTML_HTML");
Eso es todo. Comenzamos el intercambio y todo funciona, solo queda hacer cambios en el sitio, si es necesario, para que la descripción del producto se perciba como diseño y no como una cadena.
Resumen
En este ejemplo, probé la interacción de JS WebKit y 1C, recogí el rastrillo y encontré una solución.
Quizás para resolver este problema fue más fácil analizar y borrar el texto HTML de un documento formateado, pero no sería tan interesante y podría tener algunos problemas con algunas opciones de formato complejas.
Gracias por leer