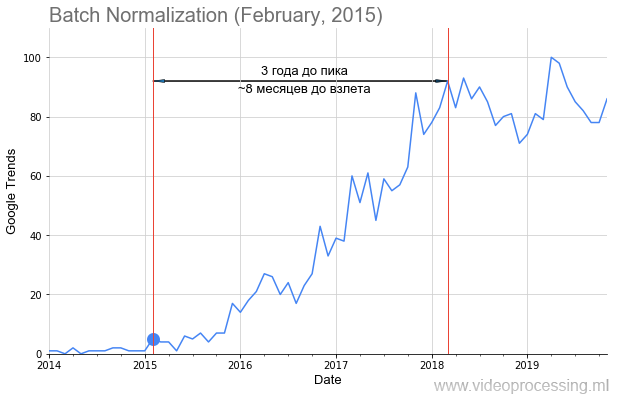
Se acerca el Año Nuevo, los años 2010 pronto terminarán, dando al mundo el renacimiento sensacional de las redes neuronales. Me preocupaba
y me privaba del sueño un simple pensamiento: "¿Cómo se puede estimar retrospectivamente la velocidad de desarrollo de las redes neuronales?" Para "El que conoce el pasado conoce el futuro". ¿Qué tan rápido despegaron los diferentes algoritmos? ¿Cómo se puede evaluar la velocidad del progreso en esta área y estimar la velocidad del progreso en la próxima década?

Está claro que puede calcular aproximadamente el número de artículos en diferentes áreas. El método no es ideal, debe tener en cuenta los subdominios, pero en general puede intentarlo. Les doy una idea, en
Google Scholar (BatchNorm) es bastante real. Puede considerar nuevos conjuntos de datos, puede nuevos cursos. Su humilde servidor, después de haber seleccionado varias opciones, se decidió por
Google Trends (BatchNorm) .
Mis colegas y yo recibimos solicitudes de las principales tecnologías de ML / DL, por ejemplo,
Normalización de lotes , como en la imagen de arriba, agregamos la fecha de publicación del artículo con un punto y obtuvimos una línea de tiempo para despegar la popularidad del tema. Pero no para todos, el
camino está lleno de rosas, el despegue es tan obvio y hermoso, como el batnorm. Algunos términos, como la regularización o la omisión de conexiones, no se pudieron crear debido al ruido de los datos. Pero en general, logramos recolectar tendencias.
¿A quién le importa lo que sucedió? ¡Bienvenido al corte!
En lugar de presentar o sobre el reconocimiento de imágenes
Entonces! Los datos iniciales eran bastante ruidosos, a veces había picos agudos.
 Fuente: Andrei Karpaty twitter: los estudiantes se paran en los pasillos de una gran audiencia para escuchar una conferencia sobre redes neuronales convolucionales
Fuente: Andrei Karpaty twitter: los estudiantes se paran en los pasillos de una gran audiencia para escuchar una conferencia sobre redes neuronales convolucionalesConvencionalmente, fue suficiente para
Andrey Karpaty dar una conferencia sobre el legendario
CS231n: Redes neuronales convolucionales para el reconocimiento visual para 750 personas con la popularización del concepto de cómo va un pico agudo. Por lo tanto, los datos se suavizaron con un
filtro de caja simple (todos los suavizados se marcan como suavizados en el eje). Como estábamos interesados en comparar la tasa de crecimiento de la popularidad, después de suavizar, todos los datos se normalizaron. Resultó bastante gracioso. Aquí hay un gráfico de las principales arquitecturas que compiten en ImageNet:
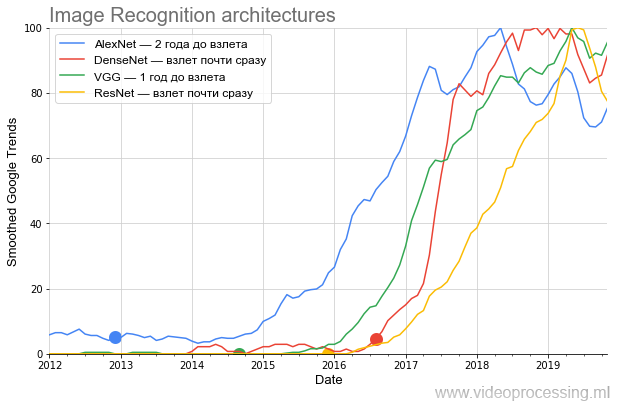 Fuente: en adelante, los cálculos del autor según Google Trends
Fuente: en adelante, los cálculos del autor según Google TrendsEl gráfico muestra muy claramente que después de la sensacional publicación de
AlexNet , que
generó la papilla de la actual exageración de las redes neuronales a fines de 2012, durante casi dos años fue hirviente,
contrariamente a las afirmaciones del montón, solo se
unió un círculo relativamente estrecho de especialistas. El tema fue al público en general solo en el invierno de 2014-2015. Preste atención a la periodicidad del calendario a partir de 2017: más picos cada primavera.
En psiquiatría, esto se llama exacerbación de primavera ... Esta es una señal segura de que ahora el término es utilizado principalmente por los estudiantes y, en promedio, el interés en AlexNet disminuye en comparación con el pico de popularidad.
Además, en la segunda mitad de 2014, apareció
VGG . Por cierto,
VGG fue coautor con la supervisora de
estudios de mi ex alumna
Karen Simonyan , que ahora trabaja en Google DeepMind (
AlphaGo ,
AlphaZero , etc.). Mientras estudiaba en la Universidad Estatal de Moscú en el tercer año, Karen implementó un buen
algoritmo de estimación de movimiento , que ha servido como referencia para estudiantes de 2 años durante 12 años. Además, las tareas allí son algo esquivamente similares. Compara:
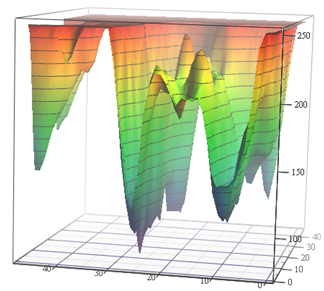
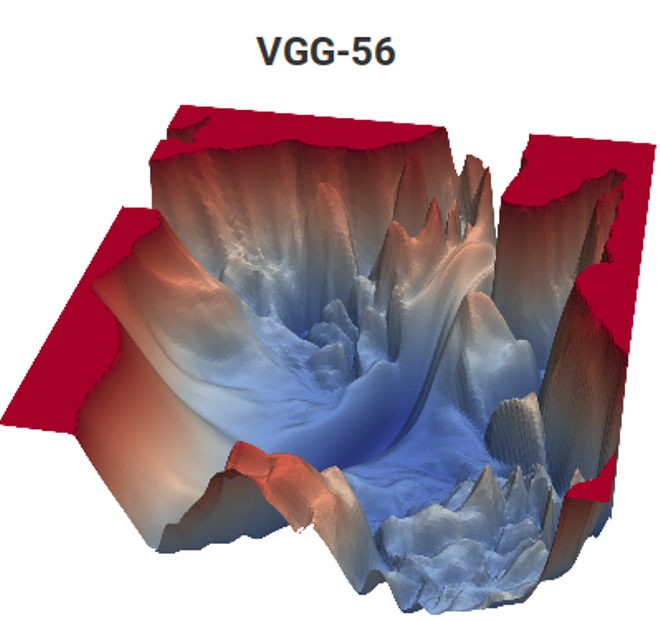 Fuente: Función de pérdida para tareas de Estimación de movimiento (materiales de autor) y VGG-56
Fuente: Función de pérdida para tareas de Estimación de movimiento (materiales de autor) y VGG-56A la izquierda necesita encontrar el punto más profundo en una superficie no trivial dependiendo de los datos de entrada para el número mínimo de mediciones (son posibles muchos mínimos locales), y a la derecha necesita encontrar un punto más bajo con cálculos mínimos (y también un montón de mínimos locales, y la superficie también depende de los datos) . A la izquierda, obtenemos el vector de movimiento predicho, y a la derecha, la red entrenada. Y la diferencia es que a la izquierda solo hay una medida implícita del espacio de color, y a la derecha hay un par de medidas de cientos de millones. Bueno, la complejidad computacional de la derecha es de aproximadamente 12 órdenes de magnitud (!) Mayor. Un poco así ... Pero el segundo año, incluso con una tarea simple, se balancea como ... [cortado por censura]. Y el nivel de programación de los escolares de ayer por razones desconocidas en los últimos 15 años ha disminuido notablemente. Tienen que decir: "¡Lo harás bien, te llevarán a DeepMind!" Se podría decir "inventar VGG", pero "llevarán a DeepMind" por alguna razón motiva mejor. Esto, obviamente, es un análogo avanzado moderno del clásico "¡Comerás sémola, te convertirás en astronauta!". Sin embargo, en nuestro caso, si contamos el número de niños en el país y el tamaño del cuerpo de cosmonautas, las posibilidades son millones de veces mayores, porque dos de nosotros ya trabajamos en DeepMind desde nuestro laboratorio.
El siguiente fue
ResNet , rompiendo el listón para el número de capas y comenzando a despegar después de seis meses. Y finalmente, DenseNet, que llegó al comienzo de la exageración
, despegó casi de inmediato, incluso más fresco que ResNet.
Si hablamos de popularidad, me gustaría agregar algunas palabras sobre las características de la red y el rendimiento, de las cuales también depende la popularidad. Si observa cómo se
predice la clase
ImageNet según el número de operaciones en la red, el diseño será así (más alto y a la izquierda, mejor):
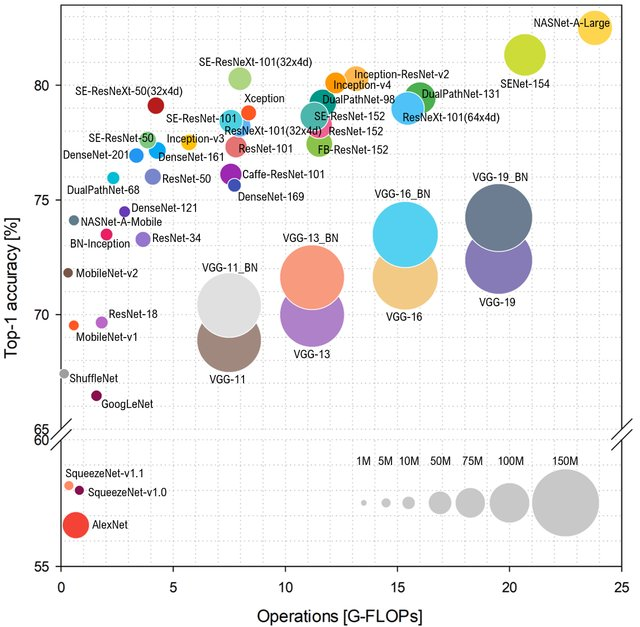 Fuente: Análisis comparativo de arquitecturas representativas de redes neuronales profundas
Fuente: Análisis comparativo de arquitecturas representativas de redes neuronales profundasEscriba AlexNet ya no es un pastel, y gobiernan las redes basadas en ResNet. Sin embargo, si observa la evaluación práctica de
FPS más cerca de mi corazón, puede ver claramente que VGG está más cerca del óptimo aquí y, en general, la alineación cambia notablemente. Incluyendo AlexNet inesperadamente en el sobre óptimo de Pareto (la escala horizontal es logarítmica, mejor arriba y a la derecha):
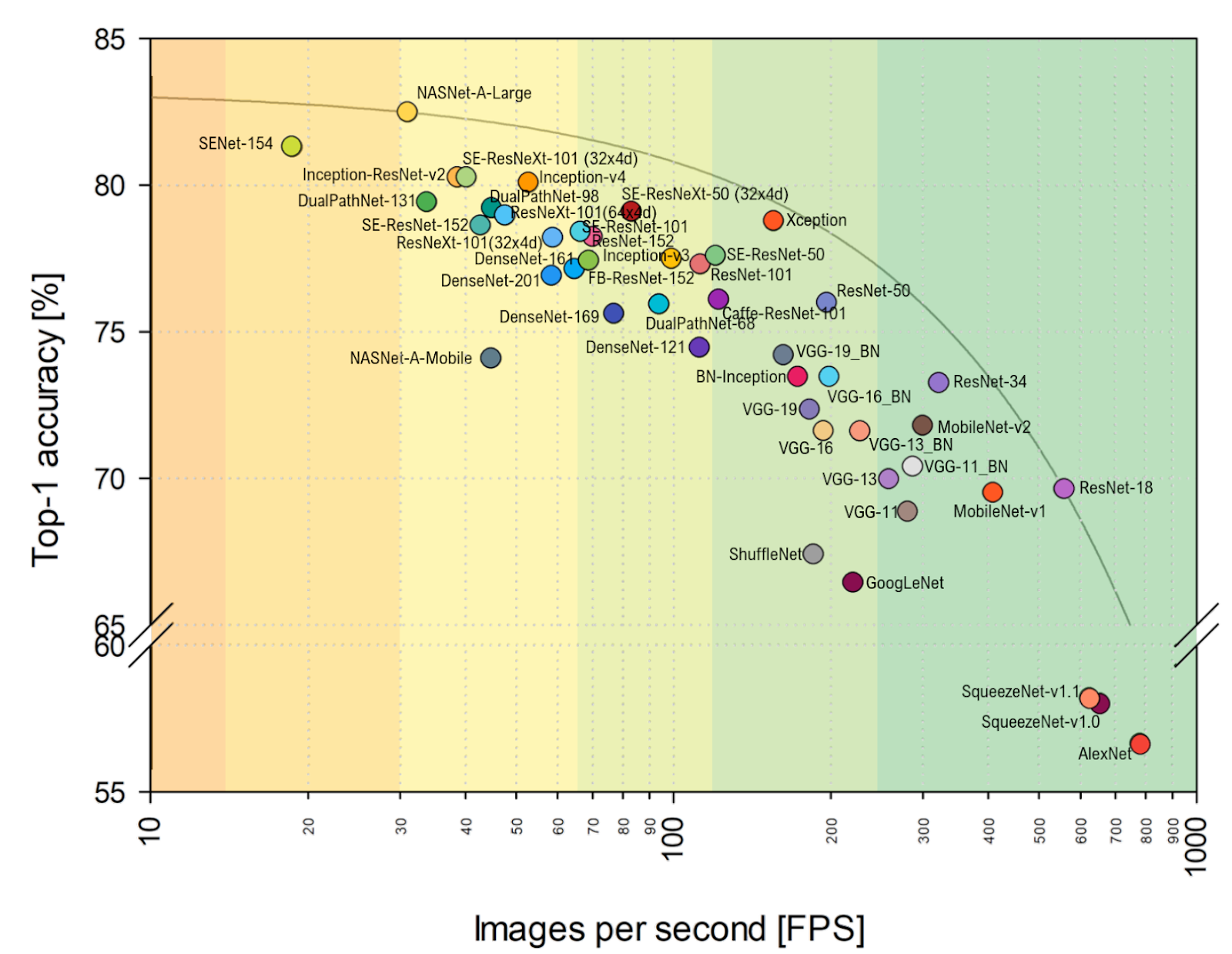 Fuente: Análisis comparativo de arquitecturas representativas de redes neuronales profundasTotal:
Fuente: Análisis comparativo de arquitecturas representativas de redes neuronales profundasTotal:
- En los próximos años, la alineación de las arquitecturas con una alta probabilidad cambiará significativamente debido al progreso de los aceleradores de redes neuronales , cuando algunas arquitecturas van a las cestas y otras despegan repentinamente, simplemente porque es mejor instalar un nuevo hardware. Por ejemplo, en el artículo mencionado , se realiza una comparación en el NVIDIA Titan X Pascal y el tablero NVIDIA Jetson TX1, y el diseño cambia notablemente. Al mismo tiempo, el progreso de TPU, NPU y otros acaba de comenzar.
- Como profesional, no puedo evitar notar que la comparación en ImageNet se realiza por defecto en ImageNet-1k, y no en ImageNet-22k, simplemente porque la mayoría entrena sus redes en ImageNet-1k, donde hay 22 veces menos clases (esto tanto más fácil como más rápido). Cambiar a ImageNet-22k, que es más relevante para muchas aplicaciones prácticas, también cambiará la alineación (para aquellos que están afilados por 1k - mucho).
Más profundo en tecnología y arquitectura
Sin embargo, volvamos a la tecnología. El término
Abandono como palabra de búsqueda es bastante ruidoso, pero un crecimiento de 5 veces está claramente asociado con las redes neuronales. Y la disminución en el interés en él es más probable con una
patente de Google y el advenimiento de nuevos métodos. Tenga en cuenta que ha pasado aproximadamente un año y medio desde la publicación del
artículo original hasta el aumento de interés en el método:
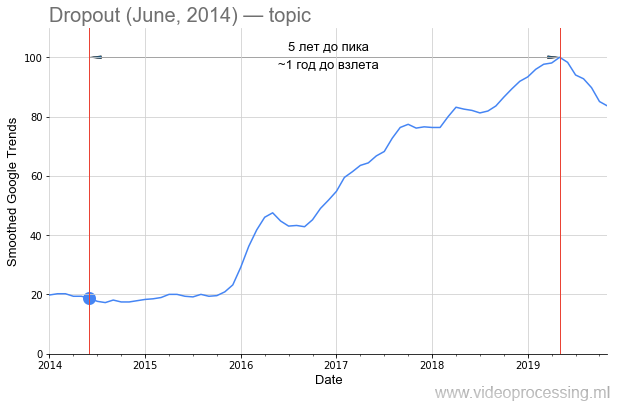
Sin embargo, si hablamos sobre el período anterior al aumento de la popularidad, entonces en DL uno de los primeros lugares está claramente ocupado por
las redes recurrentes y
LSTM :
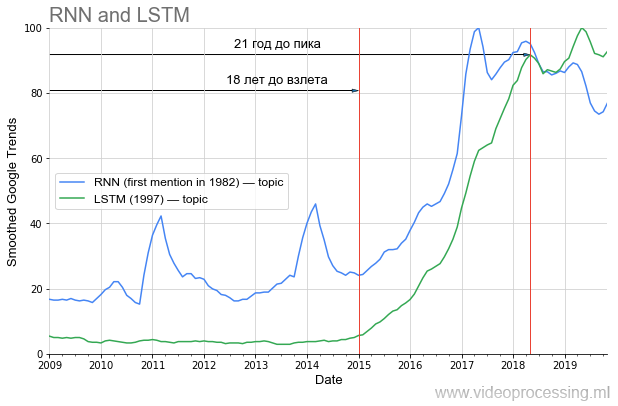
Mucho 20 años antes del pico de popularidad actual, y ahora, con su uso, la traducción automática y el análisis del genoma se han mejorado drásticamente, y en el futuro cercano (si tomas de mi área), YouTube, el tráfico de Netflix con la misma calidad visual caerá dos veces. Si aprende correctamente las lecciones de la historia, es obvio que parte de las ideas del eje actual de los artículos "despegarán" solo después de 20 años. ¡Lleva un estilo de vida saludable, cuídate y lo verás personalmente!
Ahora más cerca del bombo prometido.
Las GAN despegaron así:
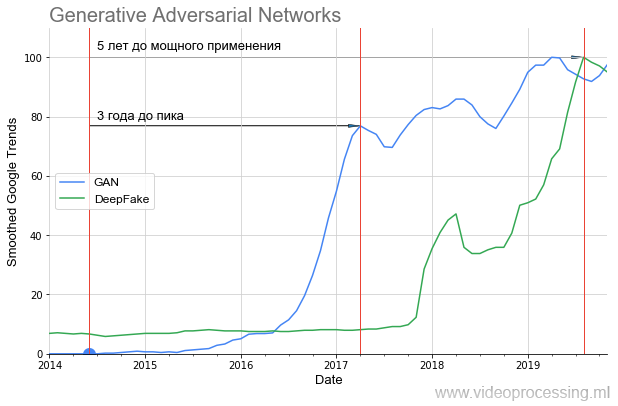
Se puede ver claramente que durante casi un año hubo silencio por completo y solo en 2016, después de 2 años, comenzó un fuerte aumento (los resultados mejoraron notablemente). Este despegue un año después dio el sensacional DeepFake, que, sin embargo, también despegó 1.5 años. Es decir, incluso las tecnologías muy prometedoras requieren una cantidad considerable de tiempo para pasar de una idea a aplicaciones que todos pueden usar.
Si observa qué imágenes generó la GAN en el
artículo original y qué se puede construir con
StyleGAN , resulta bastante obvio por qué hubo tal silencio. En 2014, solo los especialistas podían evaluar lo genial que era: crear, en esencia, otra red como función de pérdida y capacitarlos juntos. Y en 2019, todos los escolares podrían apreciar lo genial que es esto (sin comprender completamente cómo se hace):

Hoy en día, las redes neuronales resuelven con éxito
muchos problemas diferentes, puede tomar las mejores redes y crear gráficos de popularidad para cada dirección, lidiar con el ruido y los picos de las consultas de búsqueda, etc. Para no difundir mis pensamientos sobre el árbol, finalizaremos esta selección con el tema de los algoritmos de segmentación, donde las ideas de
convolución atroz / dilatada y
ASPP en el último año y medio se han disparado por completo
en el punto de referencia del algoritmo :
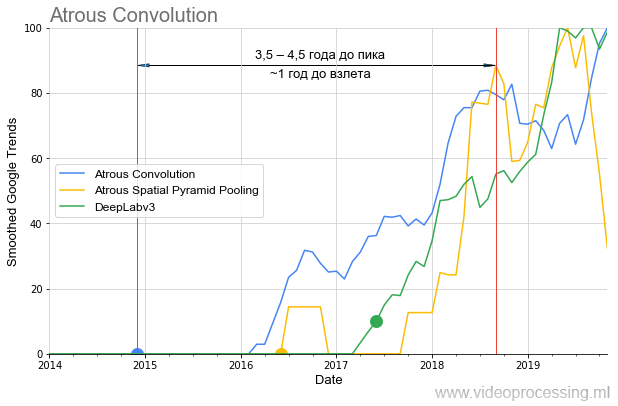
También debe tenerse en cuenta que si
DeepLabv1 más de un año "esperó" el aumento de la popularidad,
DeepLabv2 despegó en un año y
DeepLabv3 casi de inmediato. Es decir en general, podemos hablar sobre acelerar el crecimiento del interés con el tiempo (bueno, o acelerar el crecimiento del interés en tecnologías de autores de renombre).
Todo esto en conjunto condujo a la creación del siguiente problema global: un aumento explosivo en el número de publicaciones sobre el tema:
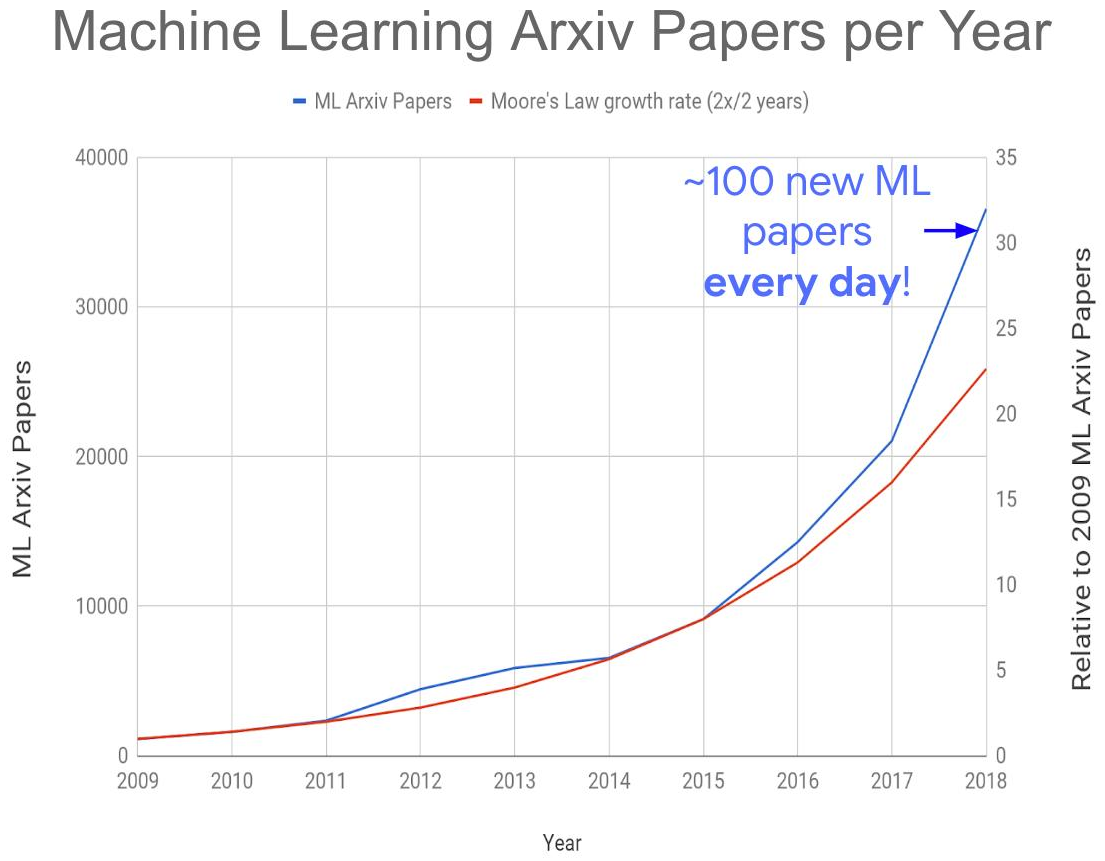 Fuente: ¿ Demasiados documentos de aprendizaje automático?
Fuente: ¿ Demasiados documentos de aprendizaje automático?Este año recibimos entre 150 y 200 artículos por día, dado que no todos se publican en arXiv-e. Leer artículos incluso en su propia subárea hoy es completamente imposible. Como resultado, muchas ideas interesantes serán enterradas bajo los escombros de nuevas publicaciones, lo que afectará el momento de su "despegue". Sin embargo, también el aumento
explosivo en el número de especialistas competentes empleados en la región da
pocas esperanzas de hacer frente al problema.
Total:
- Además de ImageNet y la historia detrás de escena de los éxitos de juego de DeepMind, las GAN han dado lugar a una nueva ola de popularización de las redes neuronales. Con ellos, era realmente posible "disparar" actores sin usar una cámara . ¡Y si habrá más! Bajo este ruido informativo, se financiarán tecnologías de procesamiento y reconocimiento menos sonoras, pero bastante funcionales.
- Como hay demasiadas publicaciones, esperamos la aparición de nuevos métodos de redes neuronales para el análisis rápido de los artículos, porque solo ellos nos salvarán (¡una broma con una fracción de broma!).
Robots de trabajo, hombre feliz
Durante 2 años, AutoML ha ganado popularidad
en las páginas de los periódicos . Todo comenzó tradicionalmente con ImageNet, en el que, en Top-1 Accuracy, comenzó a tomar firmemente los primeros lugares:
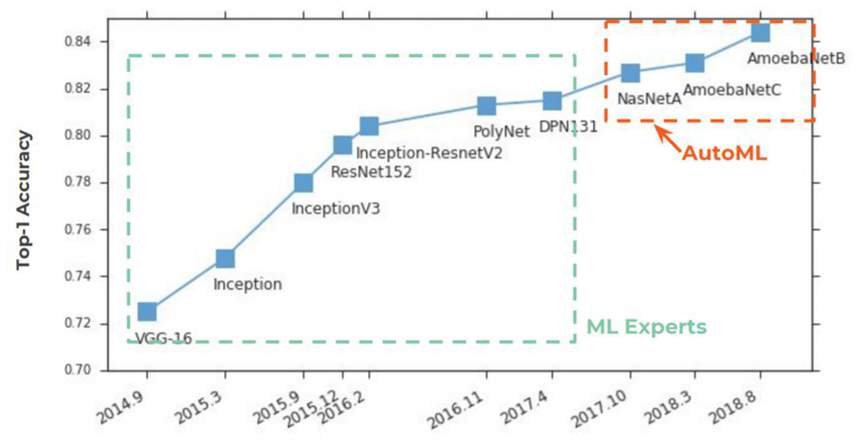
La esencia de AutoML es muy simple, un sueño centenario de científicos de datos se ha hecho realidad: una red neuronal para seleccionar hiperparámetros. La idea fue recibida con una explosión:
A continuación, en el gráfico, vemos una situación bastante rara cuando, después de la publicación de los artículos iniciales sobre
NASNet y
AmoebaNet , comienzan a ganar popularidad según los estándares de las ideas anteriores casi instantáneamente (se ve afectado un gran interés en el tema):
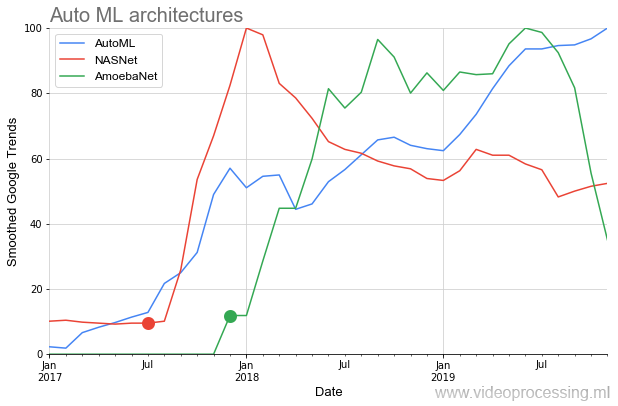
La imagen idílica está algo estropeada por dos puntos. En primer lugar, cualquier conversación sobre AutoML comienza con la frase: "Si tiene una GPU dofigalion ...". Y ese es el problema. Google, por supuesto, afirma que con su
Cloud AutoML esto se resuelve fácilmente, lo
principal es que tiene suficiente dinero , pero no todos están de acuerdo con este enfoque. En segundo lugar, funciona hasta ahora
imperfectamente . Por otro lado, recordando las GAN, cinco años aún no han pasado, y la idea en sí misma parece muy prometedora.
En cualquier caso, el despegue principal de AutoML comenzará con la próxima generación de aceleradores de hardware para redes neuronales y, de hecho, con algoritmos mejorados.
 Fuente: Imagen de Dmitry Konovalchuk, materiales del autor.Total: De hecho, los científicos de datos no tendrán unas vacaciones eternas, por supuesto, porque durante mucho tiempo seguirá habiendo un gran dolor de cabeza con los datos. Pero antes del Año Nuevo y el comienzo de la década de 2020, ¿por qué no soñar?
Fuente: Imagen de Dmitry Konovalchuk, materiales del autor.Total: De hecho, los científicos de datos no tendrán unas vacaciones eternas, por supuesto, porque durante mucho tiempo seguirá habiendo un gran dolor de cabeza con los datos. Pero antes del Año Nuevo y el comienzo de la década de 2020, ¿por qué no soñar?Algunas palabras sobre herramientas
La efectividad de la investigación depende mucho de las herramientas. Si para programar AlexNet, necesitaba una programación no trivial, hoy dicha red se puede recopilar en varias líneas en marcos nuevos.
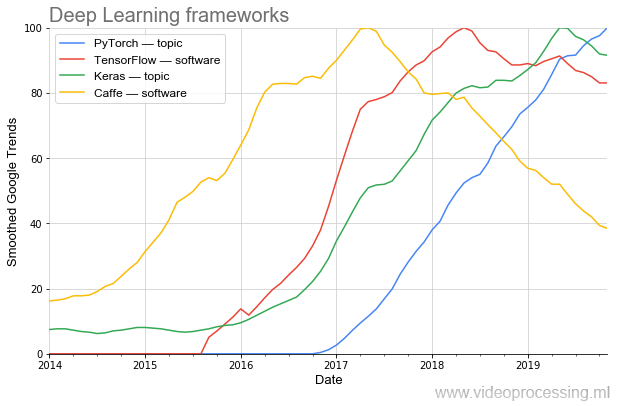
Se ve claramente cómo la popularidad está cambiando en oleadas. Hoy, el más popular (incluso
según PapersWithCode ) es
PyTorch . Y una vez que el popular
Caffe bellamente se va muy suavemente. (Nota: tema y software significa que se utilizó el filtrado de temas de Google al trazar).
Bueno, dado que tocamos las herramientas de desarrollo, vale la pena mencionar las bibliotecas para acelerar la ejecución de la red:
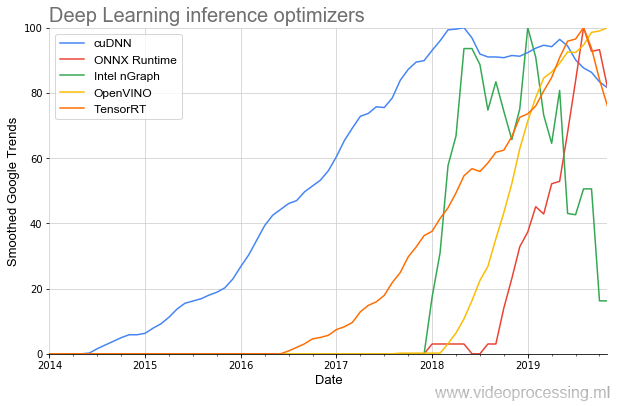
El más antiguo en el tema es (respete NVIDIA)
cuDNN , y, afortunadamente para los desarrolladores, en los últimos años el número de bibliotecas ha aumentado varias veces, y el comienzo de su popularidad se ha vuelto notablemente más pronunciado. Y parece que todo esto es solo el comienzo.
Total: incluso en los últimos 3 años, las herramientas han cambiado seriamente para mejor. Y hace 3 años, según los estándares actuales, no lo eran en absoluto. ¡El progreso es muy bueno!Perspectivas de la red neuronal prometidas
Pero la diversión comienza más tarde. Este verano, en un
artículo extenso, describí en detalle por qué la CPU e incluso la GPU no son lo suficientemente eficientes como para trabajar con redes neuronales, por qué miles de millones de dólares están fluyendo hacia el desarrollo de nuevos chips y cuáles son las perspectivas. No me repetiré A continuación se muestra una generalización y adición del texto anterior.
Para comenzar, debe comprender las diferencias entre los cálculos de la red neuronal y los cálculos en la arquitectura familiar de von Neumann (en la que, por supuesto, pueden calcularse, pero de manera menos eficiente):
 Fuente: Imagen de Dmitry Konovalchuk, materiales del autor.
Fuente: Imagen de Dmitry Konovalchuk, materiales del autor.La vez anterior, la discusión principal fue sobre FPGA / ASIC, y los cálculos inexactos pasaron casi desapercibidos, así que hablemos de ellos con más detalle. Las grandes posibilidades de reducir los chips de las próximas generaciones radican precisamente en la capacidad de leer de manera incorrecta (y almacenar datos de coeficientes localmente). El engrosamiento, de hecho, también se usa en aritmética exacta, cuando los pesos de la red se convierten a enteros y se cuantifican, pero a un nuevo nivel. Como ejemplo, considere un sumador de un solo bit (el ejemplo es bastante abstracto):
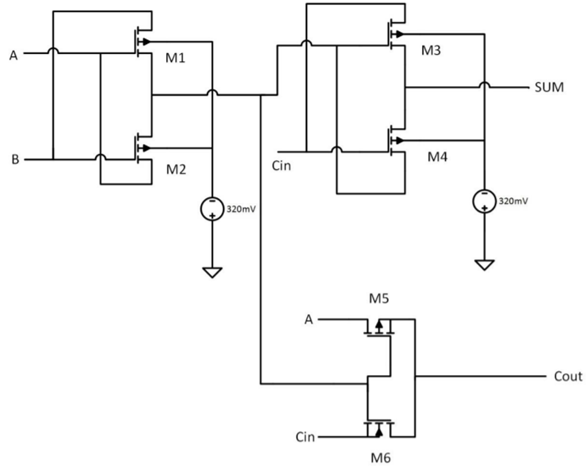 Fuente: Un diseño multiplicador de 8 bits x 8 bits de alta velocidad y baja potencia con puertas XOR de dos transistores de novela dos (2T)
Fuente: Un diseño multiplicador de 8 bits x 8 bits de alta velocidad y baja potencia con puertas XOR de dos transistores de novela dos (2T)Necesita 6 transistores (existen diferentes enfoques, la cantidad de transistores necesarios puede ser mayor o menor, pero en general, algo así). Para 8 bits,
se requieren aproximadamente
48 transistores . En este caso, el sumador analógico requiere solo 2 (¡dos!) Transistores, es decir 24 veces menos:
 Fuente: Multiplicadores analógicos (análisis y diseño de circuitos integrados analógicos)
Fuente: Multiplicadores analógicos (análisis y diseño de circuitos integrados analógicos)Si la precisión es mayor (por ejemplo, equivalente a 10 o 16 bits digitales), la diferencia será aún mayor. ¡Aún más interesante es la situación con la multiplicación! Si un multiplexor digital de 8 bits requiere aproximadamente
400 transistores , entonces un análogo 6, es decir 67 veces (!) Menos. Por supuesto, los transistores "analógicos" y "digitales" son significativamente diferentes desde el punto de vista de los circuitos, pero la idea es clara: si logramos aumentar la precisión de los cálculos analógicos, entonces llegamos fácilmente a la situación cuando necesitamos dos órdenes de magnitud menos transistores. Y el objetivo no es tanto reducir el tamaño (que es importante en relación con la "desaceleración de la ley de Moore"), sino reducir el consumo de electricidad, que es fundamental para las plataformas móviles. Y para los centros de datos no será superfluo.
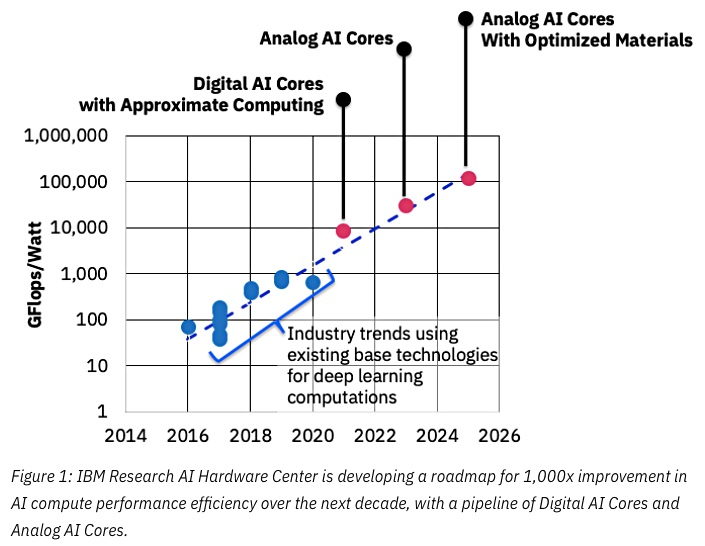 Fuente: IBM piensa que los chips analógicos aceleran el aprendizaje automático
Fuente: IBM piensa que los chips analógicos aceleran el aprendizaje automáticoLa clave del éxito aquí será una reducción en la precisión, y nuevamente aquí IBM está a la vanguardia:
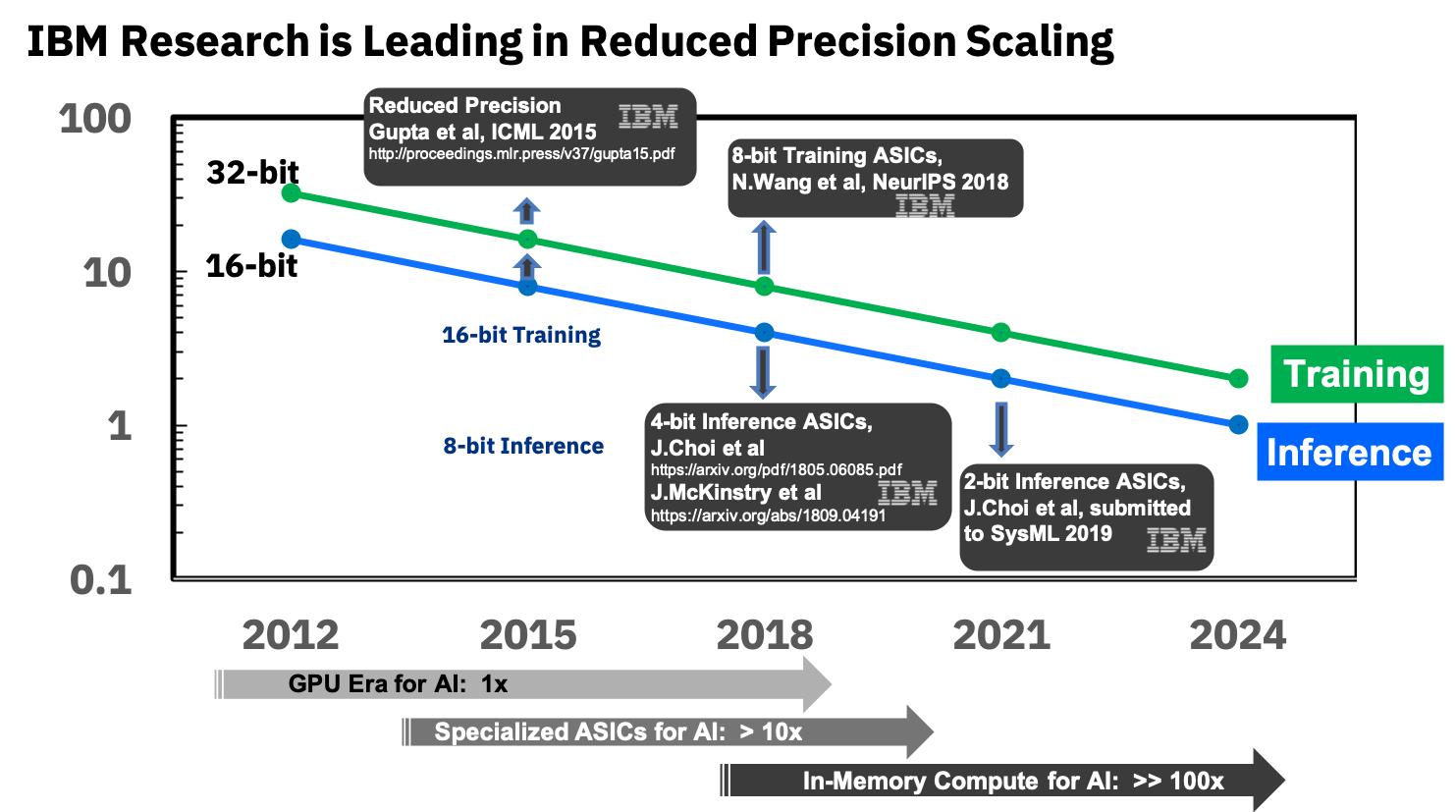 Fuente: Blog de investigación de IBM: Precisión de 8 bits para la formación de sistemas de aprendizaje profundo
Fuente: Blog de investigación de IBM: Precisión de 8 bits para la formación de sistemas de aprendizaje profundoYa están involucrados en ASIC especializados para redes neuronales, que muestran una superioridad de más de 10 veces sobre la GPU, y planean lograr una superioridad de 100 veces en los próximos años. Parece extremadamente alentador, realmente estamos deseando que llegue, porque, repito, este será un gran avance para los dispositivos móviles.
Mientras tanto, la situación no es tan mágica, aunque hay serios éxitos. Aquí hay una prueba interesante de los actuales aceleradores de hardware móvil de las redes neuronales (se puede hacer clic en la imagen, y eso nuevamente calienta el alma del autor, también en imágenes por segundo):
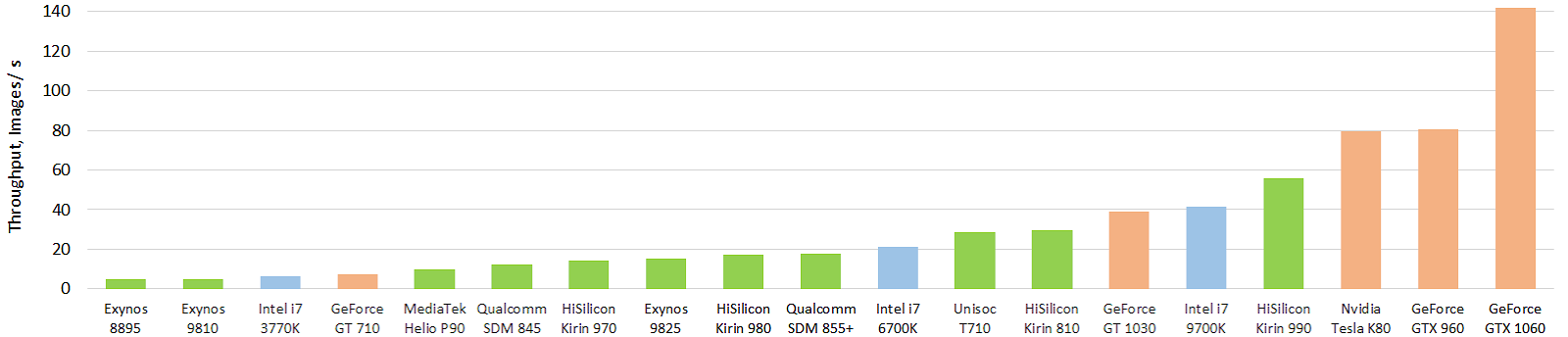 Fuente: Evolución del rendimiento de los aceleradores de IA móviles: rendimiento de imagen para el modelo flotante Inception-V3 (modelo FP16 con TensorFlow Lite y NNAPI)
Fuente: Evolución del rendimiento de los aceleradores de IA móviles: rendimiento de imagen para el modelo flotante Inception-V3 (modelo FP16 con TensorFlow Lite y NNAPI)Verde indica chips móviles, azul indica CPU, naranja indica GPU. Se ve claramente que los chips móviles actuales y, en primer lugar, el chip de gama alta de Huawei, ya están superando a las CPU decenas de veces más grandes en tamaño (y consumo de energía). ¡Y es fuerte! Con la GPU, hasta ahora no todo es tan mágico, pero habrá algo más. Puede ver los resultados con más detalle en un sitio web separado
http://ai-benchmark.com/ , preste atención a la sección de pruebas allí, eligieron un buen conjunto de algoritmos para comparar.
Total: El progreso de los aceleradores analógicos hoy es bastante difícil de evaluar. Hay una carrera Pero los productos aún no han salido, por lo que hay relativamente pocas publicaciones. Puede controlar las patentes que aparecen con un retraso (por ejemplo, flujo denso de IBM ) o buscar patentes raras de otros fabricantes. Parece que esta será una revolución muy seria, principalmente en teléfonos inteligentes y TPU de servidor.En lugar de una conclusión
ML / DL hoy se llama una nueva tecnología de programación, cuando no escribimos un programa, pero insertamos un bloque y lo entrenamos. Es decir Como al principio había un ensamblador, luego C, luego C ++, y ahora, después de 30 años de espera, el siguiente paso es ML / DL:
Eso tiene sentido. Recientemente, en empresas avanzadas, los lugares de toma de decisiones en los programas son reemplazados por redes neuronales. Es decir
si ayer hubo decisiones "sobre IFs" o sobre heurísticas que fueron amables con el corazón del programador o incluso con las ecuaciones de Lagrange (¡guau!) y otros logros más complejos de décadas de desarrollo de la teoría de control, hoy utilizaron una red neuronal simple con 3-5 capas con varias entradas y docenas de probabilidades. Aprende al instante, trabaja de manera significativamente más eficiente y el desarrollo de código se vuelve más rápido. Si antes era necesario sentarse, chamán , encender el cerebro , ahora lo pegué, alimente datos y funcionó, y usted está ocupado con cosas de alto nivel. ¡Solo un tipo de vacaciones!Naturalmente, la depuración ahora es diferente. Si antes, cuando algo no funcionaba, había una solicitud: "¡Envía un ejemplo en el que no funciona!" Y luego un barbudo serio y experimentado- El teléfono inteligente toma fotos del texto y lo reconoce: estas son redes neuronales,
- Un teléfono inteligente se traduce bien sobre la marcha de un idioma a otro y habla una traducción: redes neuronales y una vez más redes neuronales,
- El navegador y el altavoz inteligente reconocen bastante bien el habla, nuevamente redes neuronales,
- El televisor muestra una imagen de contraste brillante de 8K del video de entrada 2K, también una red neuronal,
- Los robots en producción se volvieron más precisos, comenzaron a ver y reconocer mejor las situaciones anormales, nuevamente redes neuronales,
- Un escolar en el grado 10 descarga escaneos de ensayos escolares de Internet, los marca en letras y escribe
sobre sus rodillas un programa de reconocimiento de escritura sorprendentemente bueno, una tarea imposible para los megaprofesionales de los 90, y aquí hay una red neuronal,
- En un servicio de automóviles, registran el sonido del motor e inmediatamente obtienen una lista de posibles problemas, y estas son redes neuronales,
- Y aun así, en lugar de una solución difícil y aún lenta de las ecuaciones diferenciales de cinemática inversa, el equipo enseña algo mágico y obtiene soluciones rápidas y bastante precisas , por supuesto, es una red neuronal,
- En general, ¡las redes neuronales ahora están absolutamente en todas partes! )

Solo han pasado 4 años desde que las personas aprendieron a entrenar redes neuronales realmente profundas en muchos aspectos gracias a BatchNorm (2015) y omitir conexiones (2015), y han pasado 3 años desde que "despegaron", y realmente estamos leyendo los resultados de su trabajo No lo vi. Y ahora llegarán a los productos. Algo nos dice que en los próximos años nos esperan muchas cosas interesantes. Especialmente cuando los aceleradores "despegan" ...

Érase una vez, si alguien lo recuerda, Prometeo robó el fuego del Olimpo y se lo entregó a la gente. Zeus enojado con otros dioses creó la primera belleza de una mujer llamada Pandora, que estaba dotada de muchas cualidades femeninas maravillosas
(de repente me di cuenta de que la narración políticamente correcta de algunos de los mitos de la antigua Grecia es extremadamente difícil) . Pandora fue enviada a la gente, pero Prometeo, que sospechaba que algo andaba mal, se resistió a su hechizo, y su hermano Epimeteo no. Como regalo para la boda, Zeus envió un hermoso cofre con Mercurio y Mercurio, un alma amable, cumplió la orden: le dio el cofre a Epimeteo, pero le advirtió que no lo abriera en ningún caso. La curiosa Pandora le robó el ataúd a su esposo, lo abrió, pero solo había pecados, enfermedades, guerras y otros problemas de la humanidad. Ella trató de cerrar el ataúd, pero ya era demasiado tarde:
 Fuente: Artista Frederick Stuart Church, Caja abierta de Pandora
Fuente: Artista Frederick Stuart Church, Caja abierta de PandoraDesde entonces, la frase "abre la caja de Pandora" se ha ido, es decir, para realizar
por curiosidad una acción irreversible, cuyas consecuencias pueden no ser tan hermosas como las decoraciones del ataúd en el exterior.
Sabes, cuanto más me sumerjo en las redes neuronales, más clara es la sensación de que esta es otra caja de Pandora. Sin embargo, ¡la humanidad tiene la experiencia más rica en abrir tales cajas! De lo reciente reciente: esto es energía nuclear e Internet. Entonces, creo que podemos hacer frente juntos. No es de extrañar que un grupo de hombres con
barba dura entre los primeros. Bueno, un ataúd es hermoso, ¡de acuerdo! Y no es cierto que solo haya problemas, ya se han conseguido un montón de cosas buenas. Por lo tanto, se unieron y ... ¡abrimos más!
Total:
- El artículo no incluyó muchos temas interesantes, por ejemplo, algoritmos clásicos de ML, aprendizaje de transferencia, aprendizaje de refuerzo, la popularidad de los conjuntos de datos, etc. (Caballeros, ¡pueden continuar con el tema!)
- A la pregunta sobre el ataúd: personalmente creo que los programadores de Google que hicieron posible que Google abandonara el contrato de $ 10 mil millones con el Pentágono son geniales y atractivos. Respetan y respetan. Sin embargo, tenga en cuenta que alguien ganó esta importante licitación.
Lee también:
- Aceleración de hardware de redes neuronales profundas: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP y otras cartas : el texto del autor sobre el estado actual y las perspectivas de aceleración de hardware de redes neuronales en comparación con los enfoques actuales.
- Deep Fake Science, la crisis de reproducibilidad y de dónde provienen los repositorios vacíos , sobre los problemas en la ciencia generados por ML / DL.
- Comparación de códec mágico callejero. Revelamos secretos , un ejemplo de una falsificación basada en redes neuronales.
¡Toda una gran cantidad de nuevos descubrimientos interesantes en la década de 2020 en general y en el Año Nuevo en particular!
Agradecimientos
Me gustaría agradecerle cordialmente:
- Laboratorio de Computación Gráfica y Multimedia VMK Universidad Estatal de Moscú M.V. Lomonosov por su contribución al desarrollo del aprendizaje profundo en Rusia y no solo
- personalmente Konstantin Kozhemyakov y Dmitry Konovalchuk, quienes hicieron mucho para hacer este artículo mejor y más visual,
- y finalmente, muchas gracias a Kirill Malyshev, Yegor Sklyarov, Nikolai Oplachko, Andrey Moskalenko, Ivan Molodetsky, Evgeny Lyapustin, Roman Kazantsev, Alexander Yakovenko y Dmitry Klepikov por sus muchos comentarios útiles y correcciones que hicieron que este texto fuera mucho mejor.