En TI, un proyecto saludable es un sistema o servicio que, por un lado, es de alta calidad, es decir, cumple con los requisitos y a los usuarios les gusta. Por otro lado, genera ganancias, porque la empresa siempre quiere ganar dinero. Sin un paquete de calidad y negocios, nada bueno saldrá de ello.

Bajo el corte, Ruslan Ostropolsky le contará todo sobre las métricas que son indicadores de la salud de los sistemas de TI. Analizará qué son las métricas, cómo cambian a medida que se desarrolla el proyecto, cuáles se utilizan mejor en cada proyecto. Explica cómo la calidad y el negocio se ayudan mutuamente en términos de métricas y por qué se necesita esta colaboración.
Sobre el orador y la compañía: Ruslan Ostropolsky en TI desde 2010, el área principal de interés es el aseguramiento de la calidad. Durante los últimos 5 años ha estado trabajando en DocDoc, una compañía que desarrolla servicios médicos de Internet. El producto principal es una cita en línea con un médico, más de 2 millones de pacientes se han inscrito para un médico a través de DocDoc, también hay una línea de diagnóstico, telemedicina y seguro VHI.
Cuando la calidad y los negocios no son amigos
Sin garantía de calidad, será difícil para una empresa ganar dinero a largo plazo. Necesita un montón de calidad y negocios. Si no es así, entonces las siguientes situaciones son posibles.
En primer lugar, hay
calidad por el bien de la calidad : cuando todos los tipos conocidos de pruebas se utilizan en una pequeña startup. Puede pensar inmediatamente en la automatización y las pruebas bajo cargas, pero si se excede, es posible que el producto aún no llegue a producción. Por lo tanto, necesitas:
- Comprender el negocio: lo que es relevante en este momento: ganar dinero, ingresar al mercado o escalar rápidamente. La tarea del negocio es transferir estos objetivos al departamento técnico.
- Calidad en el lugar correcto y en la cantidad correcta. A veces, puede lanzar versiones con errores, pero comprenda los riesgos y, en consecuencia, tenga esto en cuenta.
En segundo lugar, hay otro caso: un
negocio sin calidad . Una empresa de TI puede incluso tener un departamento de pruebas, pero si el control de calidad es ligero o existe en forma de pruebas de mono, que simplemente borra la regresión y se detiene allí, entonces esto no mejorará mucho.
NB: El control de calidad no es realmente una prueba, sino un enfoque general a nivel de empresa sobre cómo hacer buenos productos.
¿Cómo entender si está desarrollando alta calidad o no?
Una evaluación objetiva requiere métricas que muestran:
- El hecho de los problemas. Que básicamente tiene problemas, y si no hay problemas, debe buscarlos con más cuidado. Lo más probable es que estén en algún lugar, solo que aún no los ve.
- El hecho de los resultados. Los proyectos se crean para ganar dinero, ingresar al mercado, aumentar la conversión. Estos resultados deben ser rastreados.
- Estado actual ¿Dónde se dirige hacia sus objetivos, cuántos errores tiene actualmente, logra correr, qué tan rápido se está moviendo?
Cómo elegir métricas
Puede elegir métricas de acuerdo con tres principios.
Donde duele Si ocurre un incidente, es necesario desmontarlo, ponderarlo con métricas y observar el dolor: cómo va el tratamiento, qué dinámica, si se corrigieron los errores.
Con un
enfoque dirigido, obviamente nos enfocamos en objetivos, por ejemplo, aceleración y automatización. Anteriormente, nuestras pruebas automatizadas duraban dos horas. Establecimos una meta en 10 minutos y observamos las métricas para ver si nos estábamos acercando a este valor.
Pero es imposible obtener un proyecto saludable si las métricas no tienen conexión con el negocio, solo son técnicas y el negocio no obtiene resultados. Por el contrario, si no hay errores y el negocio pierde dinero, está sucediendo algo extraño.
Es importante recordar que hay diferentes negocios y diferentes etapas de un proyecto. Una startup, una empresa en crecimiento o un proyecto de expansión necesita diferentes métricas. Es como una enfermedad: si solo tose, puede medir la temperatura, beber ácido ascórbico y todo pasará. Si sospecha que tiene neumonía, debe tomar fotografías, someterse a un examen y recibir un tratamiento diferente.
Métricas en diferentes etapas del proyecto.
Te diré qué métricas medimos cuando éramos una startup y luego comenzamos a crecer y expandirnos.
Inicio
En esta etapa, el producto solo está en su infancia, está probando una hipótesis e investigando si las personas la necesitan.
En la etapa de inicio de una empresa, es importante que las ideas se entreguen al usuario lo más rápido posible y que puedan verificarse. Es decir, debe medir el
tiempo de comercialización : la velocidad de entrega de ideas a los usuarios (es decir, a la producción, y no solo a la liberación) y la
cantidad de clientes .
En la parte de control de calidad, teníamos solo 3-5 métricas:
- número de errores de la batalla;
- la cantidad de errores que llegan al lanzamiento;
- criticidad de los errores.
La respuesta a la pregunta de cómo recopilar métricas es simple: hay manos y hay Excel. Aproximadamente una vez al mes, ponga sus manos en la tabla de datos, esto debería ser suficiente.
Estan creciendo
En la siguiente etapa, ya hemos aprendido a ponernos de pie, caminamos un poco.
Las necesidades comerciales están evolucionando, se vuelve importante medir:
- Tráfico Cuando quedó claro que los usuarios necesitan el producto, se genera la mayor cantidad de tráfico posible, por ejemplo, aparecen programas de afiliación.
- Escalado : tanto como sea posible para crecer tanto desde el lado del producto como desde el lado del desarrollo.
El control de calidad ya está creciendo: 10-15 métricas. Si en una startup creamos un producto de acuerdo con nuestros sentimientos, por ejemplo, el fundador dijo: "Quiero un botón azul", y todos lo hicieron, ahora hay la primera estadística. Puede omitir funciones a través de
pruebas A / B y recuerde medir los resultados.
Aparece la
automatización . Las pruebas de mono ya no son suficientes, y tiene sentido invertir en una extensión. En este punto, aparecen las pruebas automáticas, lo que debería ayudar a acelerar las pruebas de regresión. En consecuencia, se mide la
velocidad de las pruebas de lanzamiento: cuánta automatización se justifica. Es triste cuando la automatización tardó seis meses y, por alguna razón, los lanzamientos no se aceleraron.
El
volumen de lanzamiento también se mide para ver si, por ejemplo, en lugar de 5 desarrolladores, se ha convertido en 15, pero por alguna razón el volumen de lanzamiento no ha crecido.
Para recopilar métricas en la etapa de crecimiento, además de manos y Excel, aparecen sistemas especializados. Los sistemas son herramientas que ayudan a crear un producto. Si anteriormente se escribieron los mismos casos de prueba en Google docs, aparecen aquí:
- administrador del sistema, por ejemplo, TestRail;
- Google Analytics para recopilar datos de usuarios;
- Portal de informes, Allure para la automatización.
El sistema construye dentro de sí mismo métricas e informes adicionales.
Gordo
Crecemos aún más, “crecimos de grasa”: no ingresamos a las oficinas en las que estábamos sentados y comenzamos a movernos periódicamente.
¿Qué es importante para los negocios?- LTV. Necesito mantener clientes. Si antes el cliente grababa una vez y se iba, ahora, obviamente, es necesario mantenerlo para construir un servicio de usuario.
- Marca / Reputación. Si las personas anteriores que contactaban a DocDoc podrían pensar que se trata de una clínica, ahora saben que están en el servicio que les ayuda.
- SLA A medida que las personas comienzan a usar el servicio constantemente, la disponibilidad del servicio se vuelve crítica, porque cualquier tiempo de inactividad afecta directamente al dinero.
- Datos. Aparecen los primeros datos, tanto de producto como técnicos y de usuario, que deben poder procesarse y almacenarse. Hay una pregunta de seguridad.
- Conversión En la etapa de escalado, no se crea un producto fundamentalmente nuevo, pero el creado mejora.
El control de calidad ya incluye aproximadamente 30-50 métricas. Medimos:
- Carga: backend, servidor y frontal, y en diferentes sectores.
- Seguridad
- Tasa de liberación.
- Velocidad de automatización.
- Estabilidad de la automatización: la velocidad y la estabilidad de la automatización afectan directamente la velocidad de los lanzamientos, porque la regresión manual no es el lugar en esta etapa del desarrollo del proyecto.
- Cobertura de automatización.
Recopilamos datos como antes, pero hay más sistemas utilizados.
Dificultades
Todo no sucede sin problemas y no somos la excepción. Te diré qué dificultades encontramos cuando el proyecto ha crecido lo suficiente.
Hay muchos sistemas , es necesario administrarlos de alguna manera. Mirar cada sistema es al menos mucho tiempo.
El número de direcciones , tanto de comestibles como técnicas,
ha crecido . Además, cada dirección se desarrolla de manera diferente, algunas de ellas se lanzan como una startup y será un error poner métricas y garantía de calidad en todas ellas.
Los procesos se volvieron más complicados : si antes 5 personas trabajaban en el proyecto, era fácil ponerse de acuerdo y actuar en consecuencia, ahora necesitamos monitorear los procesos. Por ejemplo, las personas nuevas necesitan ser introducidas gradualmente, de lo contrario les será difícil comprender la cantidad acumulada de sistemas.
Los datos y los informes son únicos dentro del servicio. Esto se deduce del hecho de que hay muchos sistemas, y debe verlos todos. Cada servicio genera sus propios informes, y debe seguirlos a todos. Además, cada vez es más difícil configurarlos usted mismo: debe ponerse en contacto con el soporte técnico para obtener un nuevo informe o intentar configurarlo usted mismo utilizando scripts.
Y si hay muchos datos,
Excel no ayuda . Especialmente si docenas de personas comienzan a trabajar en un archivo en el que todo está configurado en fórmulas (alguien cambió algo, todo se descompuso), lo vieron en una semana.
Tal vez así es como los analistas aparecen en las empresas: personas especiales que recopilan y mantienen estadísticas y datos, porque lleva demasiado tiempo combinarlos.
Y, por supuesto, se vuelve mucho
más difícil analizar la información debido al hecho de que nuevamente hay muchos sistemas, datos diferentes que desea relacionar entre sí.
Tratar la tristeza
Puedes ir al mar, relajarte, volver y mirar la experiencia de otras compañías.
La solución lógica es unir todo en términos de datos y convertirlo en métricas.
Formulamos los siguientes criterios:
- Recolecta automáticamente para que nadie entregue nada en ningún lado
- Implemente varias representaciones de datos.
- Debería haber un montón de sistemas: si la mitad de los datos se toman de Jira, la mitad de TestRail, deben caer en una alcancía, de la cual se obtendrá un informe único.
- Todo debe ser manejable y fácil de mantener. Esto significa que las personas mismas pueden construir los informes necesarios sobre la base del sistema y respaldarlos ellos mismos.
Tableros
Tenemos muchos paneles de control, solo los técnicos activos tienen ahora alrededor de 30 y alrededor de 100 en total.
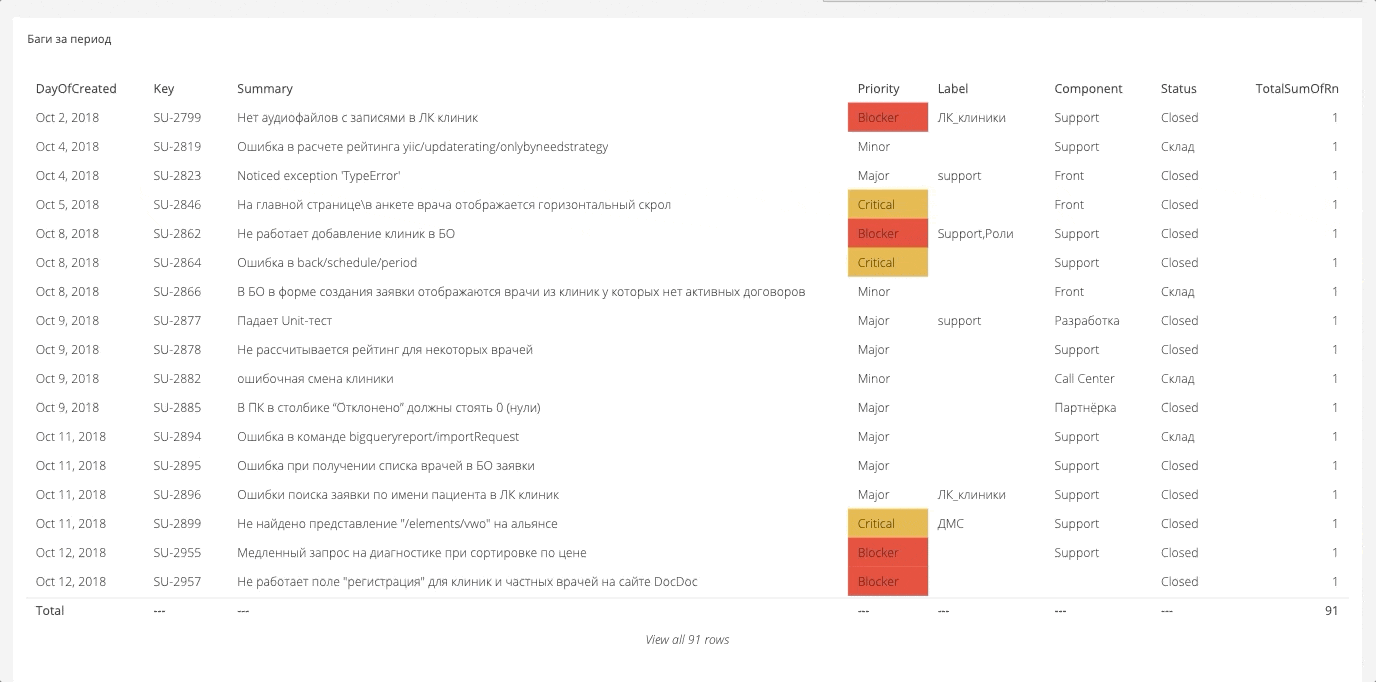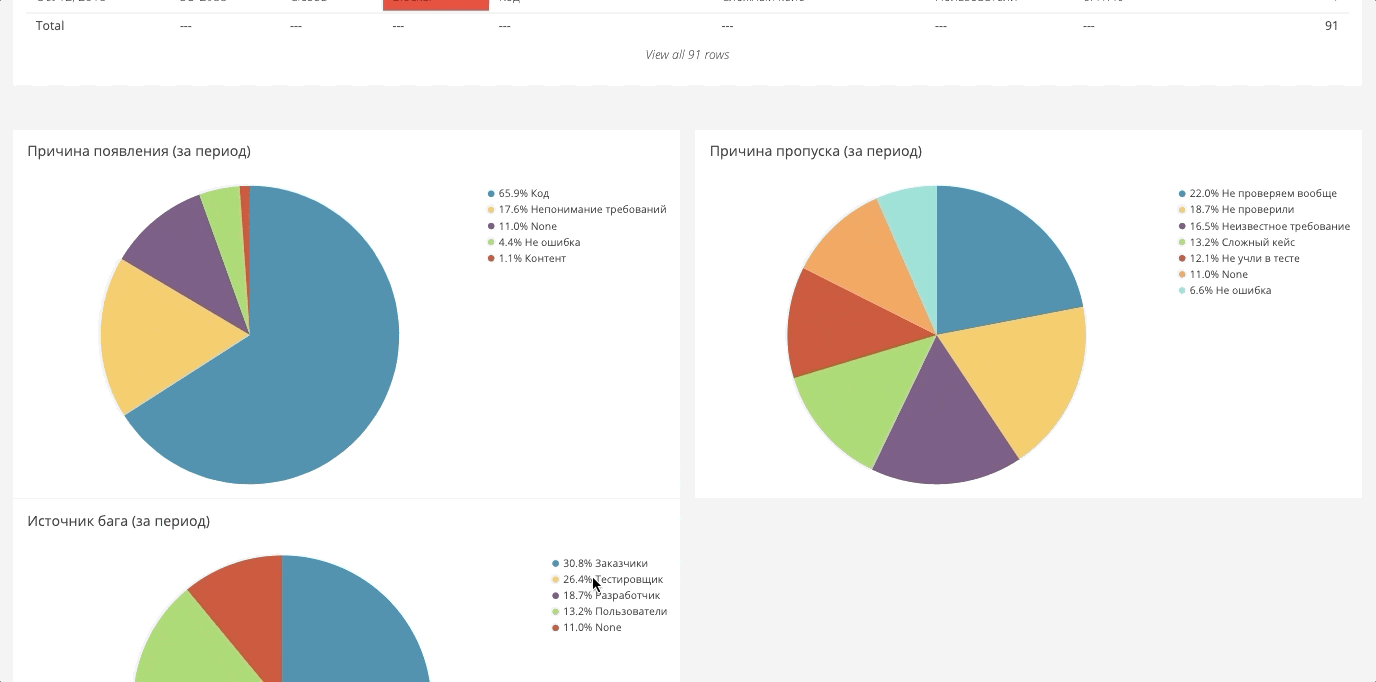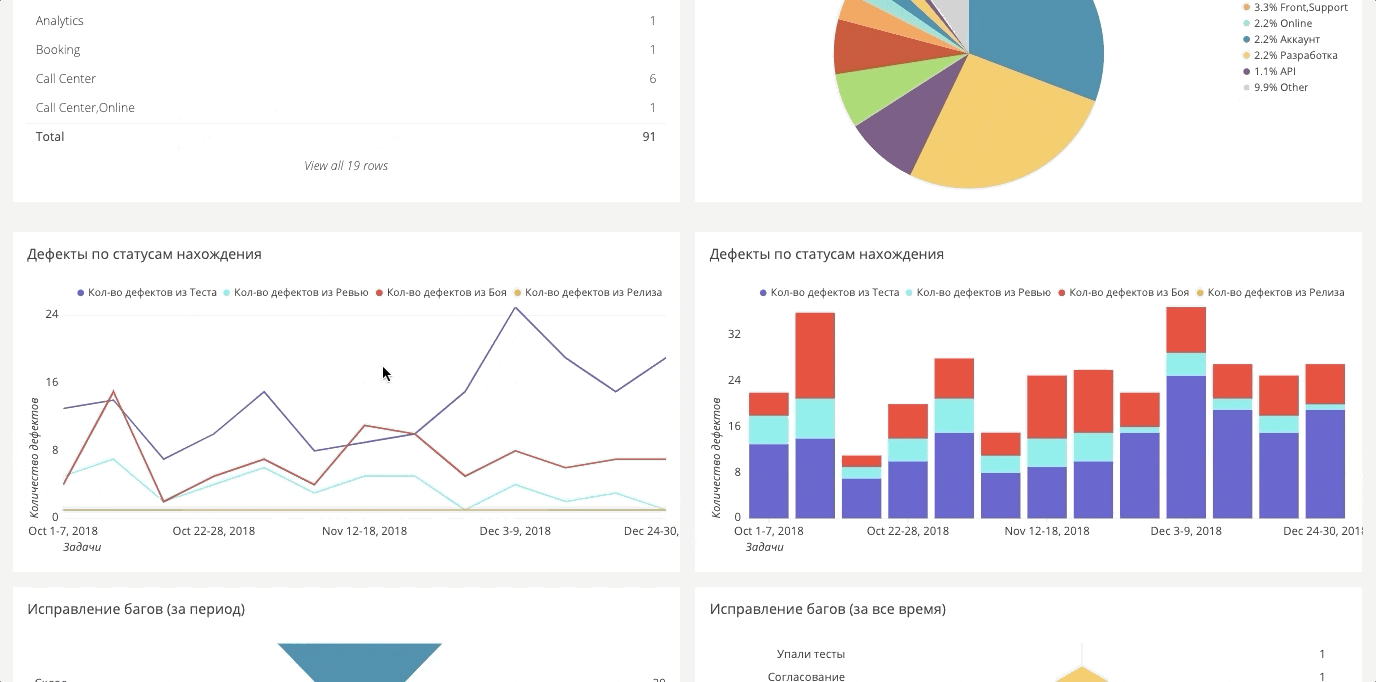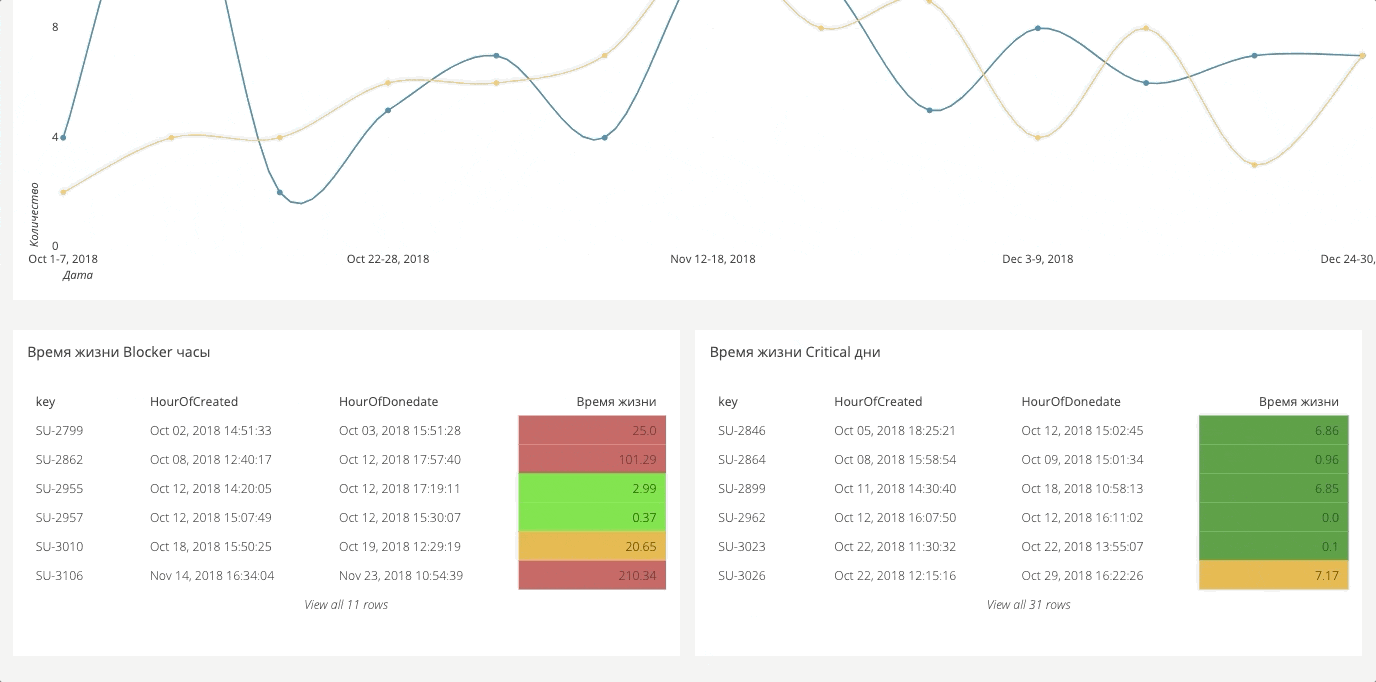
Los datos para el tablero se recopilan generalmente de todas partes. Resulta un gran lienzo desde el que puede generar los informes necesarios. A continuación hay algunos ejemplos.
Desglose de error crítico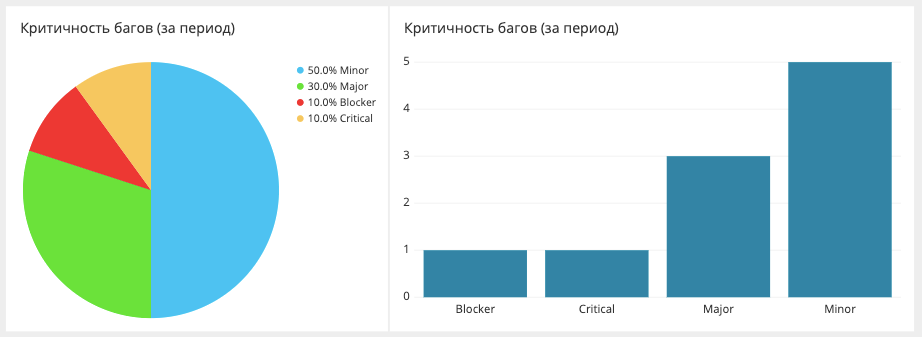
Aquí medimos y mostramos el número de errores durante un período determinado y cuán críticos fueron. Los datos se extraen de Jira. La propia Jira, probablemente, puede construir tal informe, pero no de una manera muy conveniente.
Desglose de errores por campos propiosEn Jira, puede empaquetar cualquier campo personalizado, y estos campos pueden ser analíticos, que también se cargan en el sistema general. Por ejemplo, a continuación se encuentran los errores de los componentes.
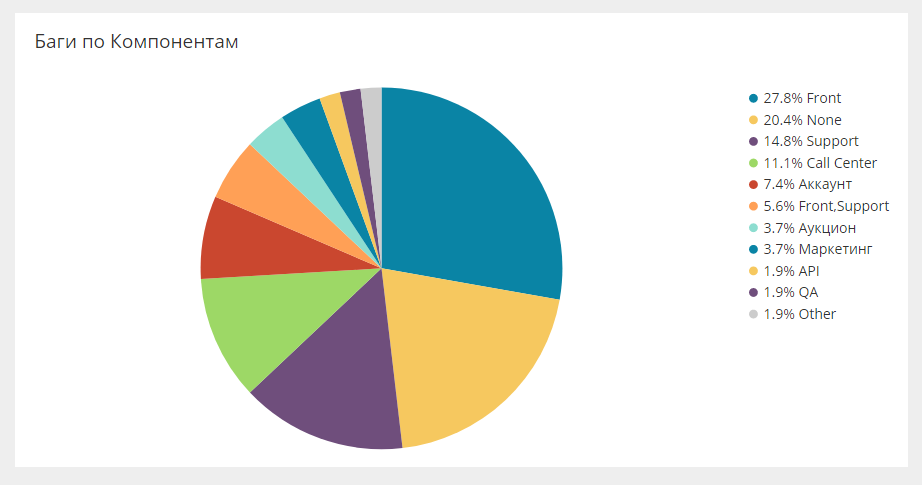
Hay el mismo corte para equipos, personas, direcciones. Esto le permite ver una variedad de rodajas.
La proporción de errores nuevos y cerradosSi creamos 20 errores y cerramos solo 5, en algún momento nos revolcaremos en ellos. Por lo tanto, debe seguir los números y esforzarse por que la relación sea igual a 1.
 Tendencia de errores para el período
Tendencia de errores para el períodoEl sistema conveniente que presentamos es que cargamos todos los datos históricos y podemos ver la dinámica.

En Jira, esto es un poco complicado. Todo funciona para nosotros automáticamente, y puede elegir cualquier período y ver si logró mejorar algo y si los procesos e ideas introducidos funcionaron.
Etapas de encontrar erroresSi antes medíamos solo los errores en la batalla, ahora nos esforzamos por garantizar que no haya errores en la batalla, y construimos sectores en diferentes etapas: batalla, lanzamiento, prueba, automatización, revisión, requisitos.
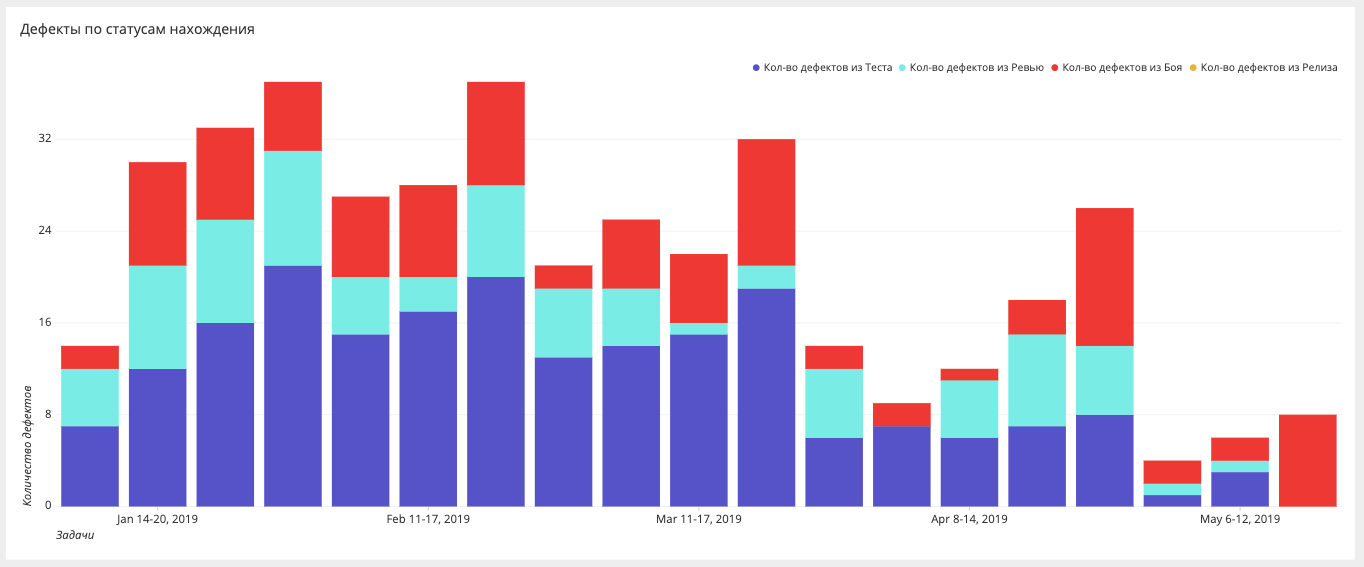 Panel de automatización
Panel de automatizaciónPara las pruebas automáticas, también hay un tablero de instrumentos. Es muy grande, por lo que a continuación hay dos fragmentos separados.

Muestra la cantidad de errores perdidos. Si tiene una cobertura del 90%, pero en realidad la mitad de los errores simplemente se comentan o se omiten, entonces esto es muy crítico, porque en realidad solo el 50% de la funcionalidad funciona correctamente.
Lo mismo ocurre con el fallo: cuántas pruebas se bloquean. Por lo general, identificamos diferentes causas de bloqueos: bloqueo del sistema, bloqueo de errores, la funcionalidad ha cambiado. Por separado, compartimos bloqueos que dependían del sistema y del entorno, y que se basaban exclusivamente en pruebas. El primero es el trabajo del equipo de operaciones, el segundo es la automatización.
También observamos la cobertura de automatización. Tomamos todas las suites de TestRial, y también podemos sumergirnos en los bloques de funcionalidad y determinar, por ejemplo, que la búsqueda está cubierta en un 30%.

Además, los datos sobre el corte de estado se reflejan aquí:
- Nuevo - nueva funcionalidad.
- Necesita corrección: necesita actualizar el caso.
- No es necesario, no quiero cubrir la automatización.
- Hecho - Cubierto.
La crítica también tiene su propio corte.
Rendimiento del tableroEstamos construyendo este panel en Grafana, y estamos cargando las métricas por separado por API, frontend, backend y servidor. Hay un bloque que muestra la porción actual de la última versión. En consecuencia, puede caer en cada una de las métricas y ver la dinámica.

Todo se superpone con diferentes funcionalidades, diferentes páginas del sitio.
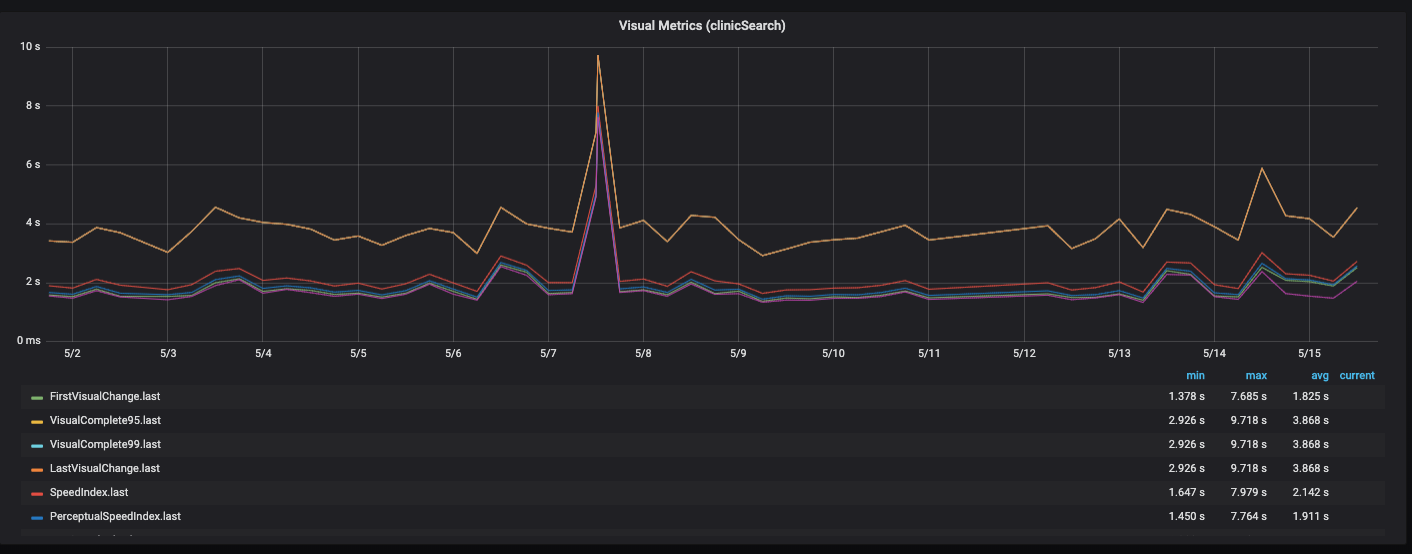
Volar en
Parece que ahora todo está bien: se reúne y en un lugar, un montón de métricas. Puedes seguir adelante con seguridad.
Pero hay nuevos problemas en el camino. Hay demasiados gráficos y, por lo tanto, se observan con menos frecuencia. Cuando hay 5 horarios, son fáciles de verificar todos los días. Con un aumento en su número, se obtiene un régimen de una vez por semana, también bueno. Y luego, de repente, hace 3 días hubo un fakap, que nadie notó. Por lo tanto, la reacción se vuelve larga, y las métricas y los paneles logran quedar obsoletos. Hay varias razones para esto, que también deben ser capaces de luchar.
Necesitamos hacer
gráficos agregados : de 10 hacemos uno que muestre el estado de estos 10. Además, sacamos los principales indicadores. Abre el panel e inmediatamente ve los valores deseados, y luego todo lo demás, que revela las métricas con más detalle.
Compartimos: métricas comerciales, métricas de procesos, métricas de control de calidad (Web / Mobile, Manual / Automatización, Rendimiento).
Así es como se ve el gráfico agregado (NPS, CSAT).
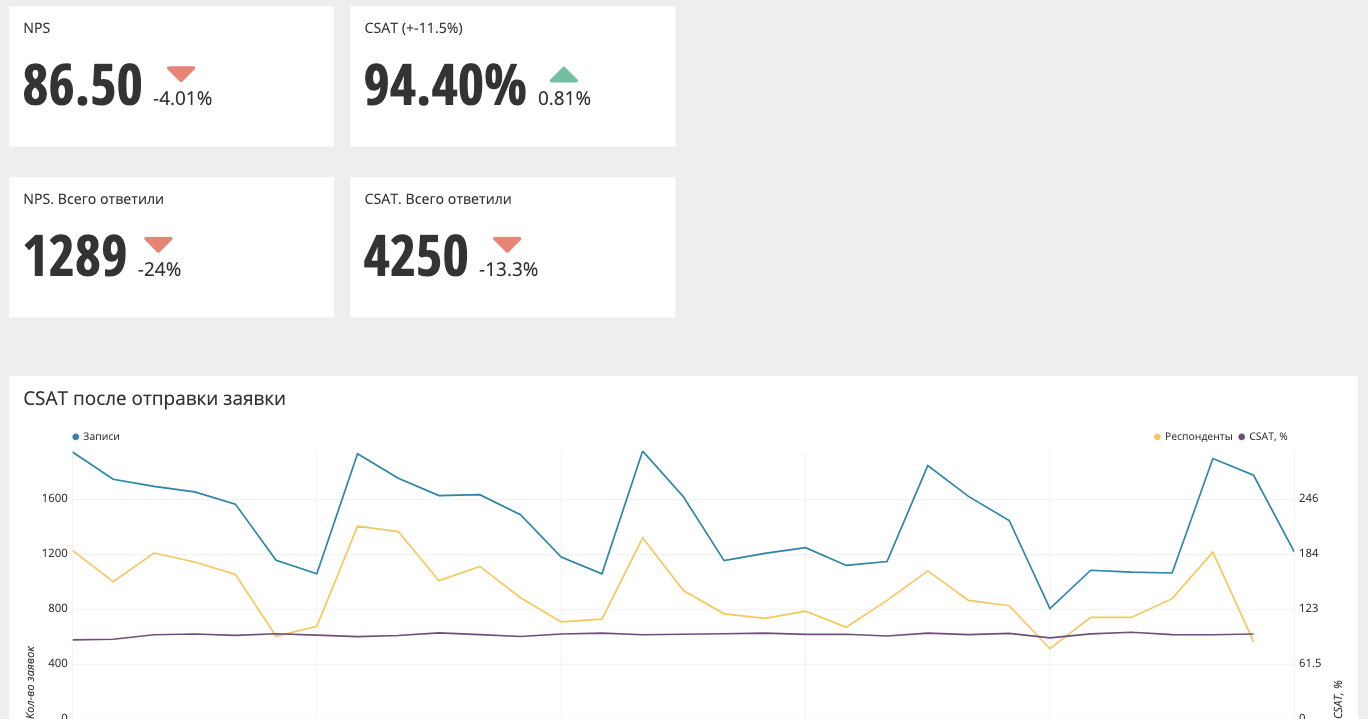
En la parte superior están los valores y delta en comparación con el período anterior. En este caso, si la flecha es roja, entonces debe hacer algo, al menos mire los gráficos con más detalle. Si la flecha es verde, entonces todo está bien y no puedes reaccionar.
Además, los gráficos tienen la
capacidad de caer a un nivel más bajo , sin ir a ninguna parte.

Los errores están relacionados con las personas que los permitieron (probadores o desarrolladores). Si hace clic por separado en algún probador, se abrirá una tabla separada, una porción para las tareas.
El siguiente paso es resolver el problema de que los gráficos rara vez se controlan. Es decir, ampliaremos el esquema de trabajo con datos y métricas: agregue notificaciones a las métricas necesarias.
Alertas
Usamos muchas alertas. Daré ejemplos de categorías y situaciones específicas:
- Rendimiento
- Pruebas automáticas. Por ejemplo, si el porcentaje de errores perdidos es demasiado alto, o si las pruebas no cubren demasiada funcionalidad nueva.
- Errores entrantes. En nuestra empresa, cualquiera puede tener un error en el sistema de tickets. Anteriormente, esto iba acompañado de un mensaje en PM, y ahora hay un canal para notificaciones de nuevos errores, además, los errores se asignan automáticamente al ejecutor a su vez. La persona designada debe analizar el error, de lo contrario el bot le recordará cada 15 minutos.
- Velocidad de prueba / Prueba pendiente. Si está claro que una persona se ha enterrado a sí misma en una tarea, no importa, la codificó, hizo una revisión, la probó, debería aparecer una alerta: "Ya está haciendo tres tareas, tal vez haya enterrado, solicite ayuda".
- Defectos en la tarea / equipo.
- Revisión de casos de prueba. Esto es solo automatización del proceso, para no hacerlo a mano.
Ejemplos de alertas
Para las tareas que se queman, el bot escribe el número de la tarea, el estado, la prioridad, cuánto tiempo la tarea ya se está probando y quién la está probando.

Una notificación, redactada en forma de resumen, llega a una persona que analiza los problemas que tiene. Aquí hay un ejemplo de alertas para el caso de prueba que envía TestRial.

Indica qué casos se asignan a quién, con qué estado y quién necesita ser observado.
Otro ejemplo es el bot Yabeda, que monitorea los procesos.

Esto fue necesario para configurar el proceso de vinculación del error y la tarea. El desarrollador, analizando el error, debe encontrar la tarea en la que omitimos este error, para un análisis más detallado, para saber por qué lo perdimos. Este es un tipo de análisis del incidente, pero con retraso.
¿Cuántas alertas necesitas y con qué frecuencia?
Si habrá muchas alertas, habrá mucho estrés por parte de ellos. Por lo tanto, hemos establecido reglas de administración de alertas para nosotros mismos.
Demasiadas alertas: deja de responder. 500 alertas por día definitivamente se detendrá para tener tiempo de navegar, lo que significa que puede omitir lo importante.
Demasiado poco, sin problemas. Si hay muy pocos mensajes, por ejemplo, simplemente deseche la mitad, es posible que no vea algún tipo de problema.
No hay problema: un resumen de los hechos. En ausencia de problemas, también se deben enviar alertas, pero en forma de resumen: qué sucedió durante el día, qué funcionó, qué tareas fueron, qué sucedió. Si no hace un resumen, podría pensar que todo se rompió y debe buscar qué alertas se han caído.
: , . , , - , . ,
:
- — , .
- — , , . , , . .
- — , , , , .
,
:- — , , .
- / . , , .
- . , .
- . , . , . , , .
. , . . , , , , . , , : , .
, :
, , . . -, , , , , 15 , . -, , . . -, . , , , , , .
Online
. , . , . , .

QA
, QA .
: , , .
: , , .
:

— , X ( ), () (). , - , ( ) : , . , . , , . , , .
: — , , ( , , ).
: « ». , , , , . - . .
, , . , , . .
-
: , , . , .
: , , , .
, 10 , 500, . , .
. , , .

,
, , . , , . «5 », .
, , , .
Resumen
— , . , . , . , , , — , .
:. , , , . .
— . , . , , - .
. , .
:- ~ 50 QA 100 .
- ~ 30 .
- — , .
- .
- .
- QA must have.
Nuestra conferencia, que combina todos los aspectos del desarrollo de productos de alta calidad, renacerá el próximo año, saldrá de RIT ++ y se convertirá en un evento independiente a gran escala TechLead Conf. Pronto anunciaremos la fecha y el lugar en el canal de telegramas , pero si ha visto por su propia experiencia que el proceso de desarrollo no es un conjunto de ladrillos desconectados y desea compartir soluciones para procesos de ingeniería de edificios, solicite un informe sin esperar anuncios.