A veces, puede ser necesario perfilar el rendimiento del programa o el consumo de memoria en un programa C ++. Desafortunadamente, a menudo esto no es tan fácil como parece.
Aquí consideraremos las características de los programas de creación de perfiles utilizando las
herramientas Valgrind y
Google Perftools . El material resultó no ser muy estructurado, es más bien un intento de reunir una base de conocimiento "para fines personales" para que en el futuro no tenga que recordar frenéticamente "por qué esto no funciona" o "cómo hacerlo". Lo más probable es que no todos los casos no obvios se vean afectados aquí, si tiene algo que agregar, escriba los comentarios.
Todos los ejemplos se ejecutarán en el sistema Linux.
Perfiles de tiempo de ejecución
Preparación
Para analizar las características de la creación de perfiles, ejecutaré pequeños programas, que generalmente consisten en un archivo main.cpp y un archivo func.cpp junto con la inclusión.
Los compilaré con el
compilador g ++ 8.3.0 .
Dado que la creación de perfiles de programas no optimizados es una tarea bastante extraña, compilaremos con la opción
-Ofast , y para obtener caracteres de depuración en la salida, no olvidaremos agregar la opción
-g . Sin embargo, a veces, en lugar de los nombres de funciones normales, solo puede ver direcciones de llamadas inaudibles. Esto significa que ha habido una "aleatorización de la asignación de espacio de direcciones". Esto se puede determinar llamando al comando
nm en el binario. Si la mayoría de las direcciones se parecen a esto 00000000000030e0 (una gran cantidad de ceros al principio), entonces lo más probable es que sea así. En un programa normal, las direcciones se ven como 0000000000402fa0. Por lo tanto, debe agregar la opción
-no-pie . Como resultado, el conjunto completo de opciones se verá así:
-Ofast -g -no-piePara ver los resultados, utilizaremos el programa
KCachegrind , que puede funcionar con el
formato de informe
callgrindCallgrind
La primera utilidad que veremos hoy es
callgrind . Esta utilidad es parte de la herramienta valgrind. Emula cada instrucción ejecutable del programa y, sobre la base de métricas internas sobre el "costo" de cada instrucción, emite la conclusión que necesitamos. Debido a este enfoque, a veces sucede que callgrind no puede reconocer la siguiente instrucción y se cae con un error
Instrucciones no reconocidas en la direcciónLa única forma de salir de esta situación es reconsiderar todas las opciones de compilación e intentar encontrar la interferencia.
Creemos un programa para probar esta herramienta, que consta de una biblioteca compartida y una biblioteca estática (dejaremos las bibliotecas más adelante en otras pruebas). Cada biblioteca, así como el programa en sí, proporcionará una función computacional simple, por ejemplo, el cálculo de la secuencia de Fibonacci.
Compilamos el programa y ejecutamos valgrind de la siguiente manera:
valgrind --tool=callgrind ./test_profiler 100000000
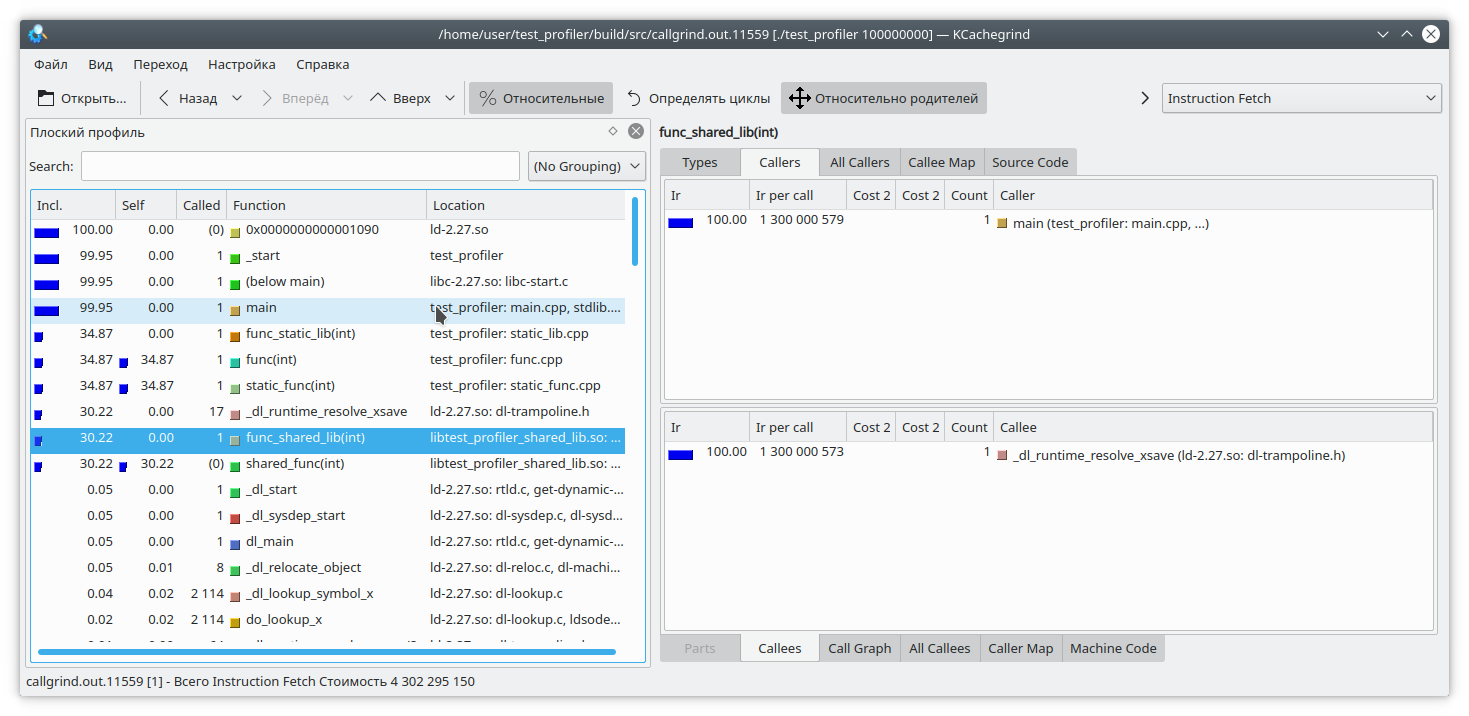
Vemos que para una biblioteca estática y una función regular, el resultado es similar al esperado. Pero en la biblioteca dinámica, callgrind no pudo resolver completamente la función.
Para solucionar esto, al iniciar el programa, debe establecer la variable
LD_BIND_NOW en 1, así:
LD_BIND_NOW=1 valgrind --tool=callgrind ./test_profiler 100000000
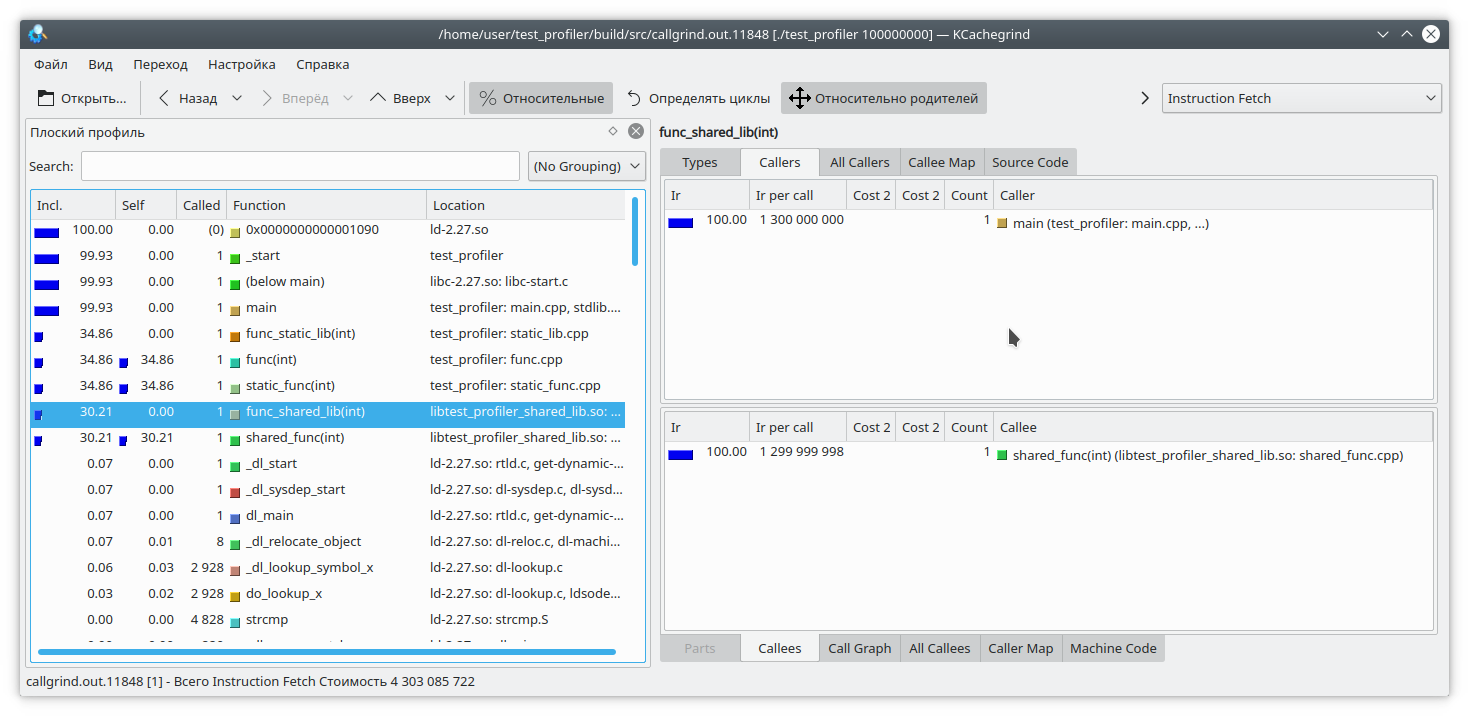
Y ahora, como puedes ver, todo está bien
El siguiente problema de callgrind que surge de la creación de perfiles emulando instrucciones es que la ejecución del programa se ralentiza mucho. Esto puede llevar una estimación relativa incorrecta del tiempo de ejecución de varias partes del código.
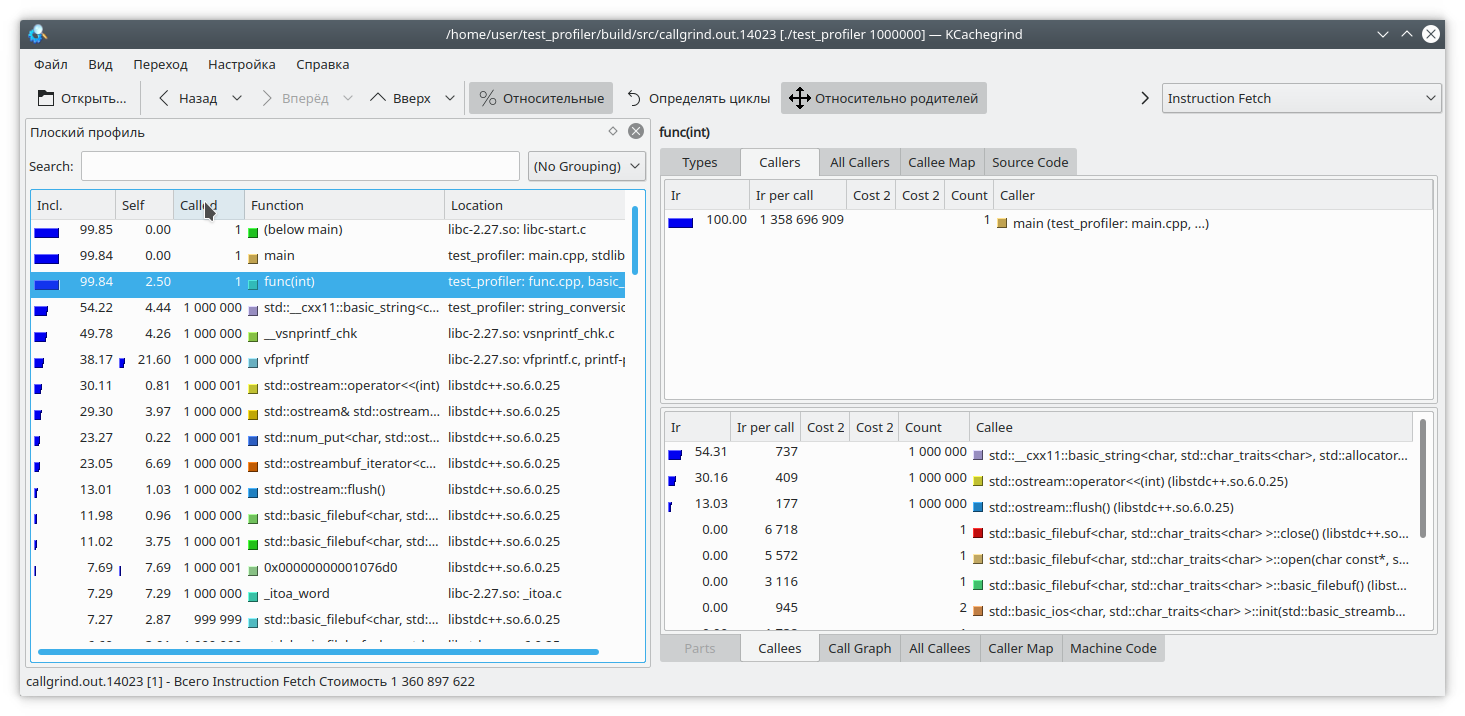
Veamos este código:
int func(int arg) { int fst = 1; int snd = 1; std::ofstream file("tmp.txt"); for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; std::string r = std::to_string(res); file << res; file.flush(); fst = snd; snd = res + r.size(); } return fst; }
Aquí, agregué una pequeña cantidad de datos a un archivo para cada iteración del bucle. Como escribir en un archivo es una operación bastante larga, como contrapeso, agregué una generación de línea desde un número a cada iteración del bucle. Obviamente, en este caso, la operación de escritura en el archivo lleva más tiempo que el resto de la lógica de la función. Pero callgrind piensa diferente:
También vale la pena considerar que callgrind solo puede medir el costo de una función cuando funciona. La función no funciona, por lo tanto, el costo no aumenta. Esto complica la depuración de programas que de vez en cuando ingresan al bloqueo o funcionan con un sistema / red de archivos de bloqueo. Vamos a ver:
#include "func.h" #include <mutex> static std::mutex mutex; int funcImpl(int arg) { std::lock_guard<std::mutex> lock(mutex); int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; } return fst; } int func2(int arg){ return funcImpl(arg); } int func(int arg) { return funcImpl(arg); } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); auto future = std::async(std::launch::async, &func2, arg); std::cout << "result: " << func(arg) << std::endl; std::cout << "second result " << future.get() << std::endl; return 0; }
Aquí hemos incluido toda la ejecución de la función en el bloqueo del mutex, y llamamos a esta función desde dos hilos diferentes. El resultado de callgrind es bastante predecible: no ve ningún problema en capturar un mutex:
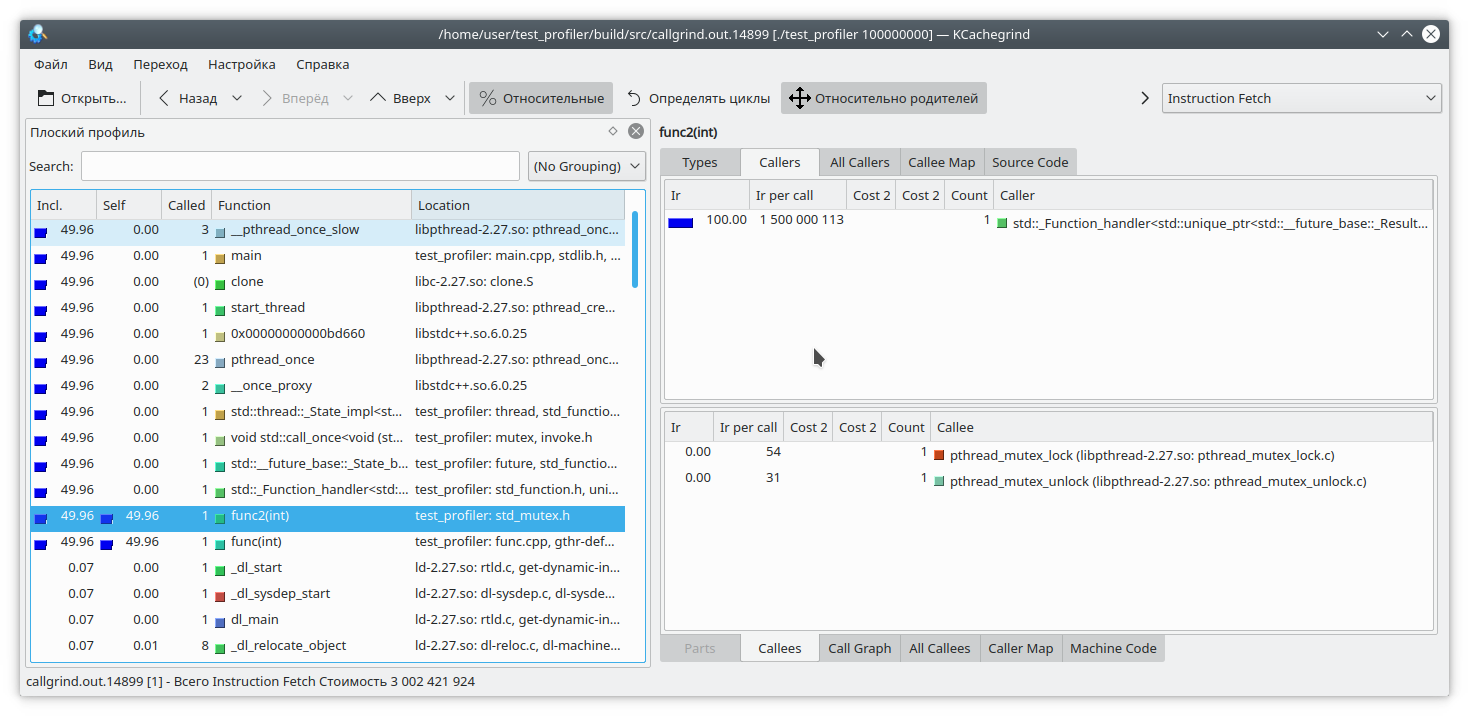
Entonces, examinamos algunos de los problemas de usar el generador de perfiles callgrind. Pasemos al siguiente tema de prueba: el perfilador de perftools de google
perftools de google
A diferencia de callgrind, el generador de perfiles de Google funciona con un principio diferente.
En lugar de analizar cada instrucción del programa ejecutable, detiene el programa a intervalos regulares e intenta determinar en qué función se encuentra actualmente. Como resultado, esto casi no afecta el rendimiento de la aplicación en ejecución. Pero este enfoque también tiene sus debilidades.
Comencemos perfilando el primer programa con dos bibliotecas.
Como regla general, para comenzar a generar perfiles con esta utilidad, debe precargar la biblioteca libprofiler.so, establecer la frecuencia de muestreo y especificar el archivo para guardar el volcado. Desafortunadamente, el generador de perfiles requiere que el programa finalice "por sí solo". La terminación forzada del programa hará que el informe simplemente no se descarte. Esto es inconveniente cuando se perfilan programas de larga duración que no se detienen, como los demonios. Para sortear este obstáculo, creé este script:
gprof.sh rnd=$RANDOM if [ $# -eq 0 ] then echo "./gprof.sh command args" echo "Run with variable N_STOP=true if hand stop required" exit fi libprofiler=$( dirname "${BASH_SOURCE[0]}" ) arg=$1 nostop=$N_STOP profileName=callgrind.out.$rnd.g gperftoolProfile=./gperftool."$rnd".txt touch $profileName echo "Profile name $profileName" if [[ $nostop = "true" ]] then echo "without stop" trap 'echo trap && kill -12 $PID && sleep 1 && kill -TERM $PID' TERM INT else trap 'echo trap && kill -TERM $PID' TERM INT fi if [[ $nostop = "true" ]] then CPUPROFILESIGNAL=12 CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & else CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & fi PID=$! if [[ $nostop = "true" ]] then sleep 1 kill -12 $PID fi wait $PID trap - TERM INT wait $PID EXIT_STATUS=$? echo $PWD ${libprofiler}/pprof --callgrind $arg $gperftoolProfile* > $profileName echo "Profile name $profileName" rm -f $gperftoolProfile*
Esta utilidad debe ejecutarse, pasando como parámetros el nombre del archivo ejecutable y una lista de sus parámetros. Además, se supone que junto al script están los archivos que necesita libprofiler.so y pprof. Si el programa es de larga duración y se detiene al interrumpir la ejecución, debe establecer la variable N_STOP en true, por ejemplo, así:
N_STOP=true ./gprof.sh ./test_profiler 10000000000
Al final del trabajo, el script generará un informe en mi formato favorito de callgrind.
Entonces, ejecutemos nuestro programa bajo este generador de perfiles.
./gprof.sh ./test_profiler 1000000000

En principio, todo está bastante claro.
Como dije, el generador de perfiles de Google funciona deteniendo la ejecución del programa y calculando la función actual. ¿Cómo hace eso? Lo hace haciendo girar la pila. ¿Pero qué pasa si, en el momento de la promoción de la pila, el programa en sí mismo desenrolla la pila? Bueno, obviamente, nada bueno sucederá. Vamos a verlo Escribamos tal función:
int runExcept(int res) { if (res % 13 == 0) { throw std::string("Exception"); } return res; } int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; try { res = runExcept(res); } catch (const std::string &e) { res = res - 1; } fst = snd; snd = res; } return fst; }
Y ejecuta el perfilado. El programa se congela bastante rápido.
Hay otro problema relacionado con la peculiaridad de la operación del generador de perfiles. Supongamos que logramos desenrollar la pila y ahora necesitamos unir las direcciones con las funciones específicas del programa. Esto puede ser muy poco trivial, ya que en C ++ hay una gran cantidad de funciones en línea. Veamos un ejemplo como este:
#include "func.h" static int func1(int arg) { std::cout << 1 << std::endl; return func(arg); } static int func2(int arg) { std::cout << 2 << std::endl; return func(arg); } static int func3(int arg) { std::cout << 3 << std::endl; if (arg % 2 == 0) { return func2(arg); } else { return func1(arg); } } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); int arg2 = func3(arg); int arg3 = func(arg); std::cout << "result: " << arg2 + arg3; return 0; }
Obviamente, si ejecuta el programa, por ejemplo, así:
./gprof.sh ./test_profiler 1000000000
entonces la función func1 nunca se llamará. Pero el perfilador piensa de manera diferente:
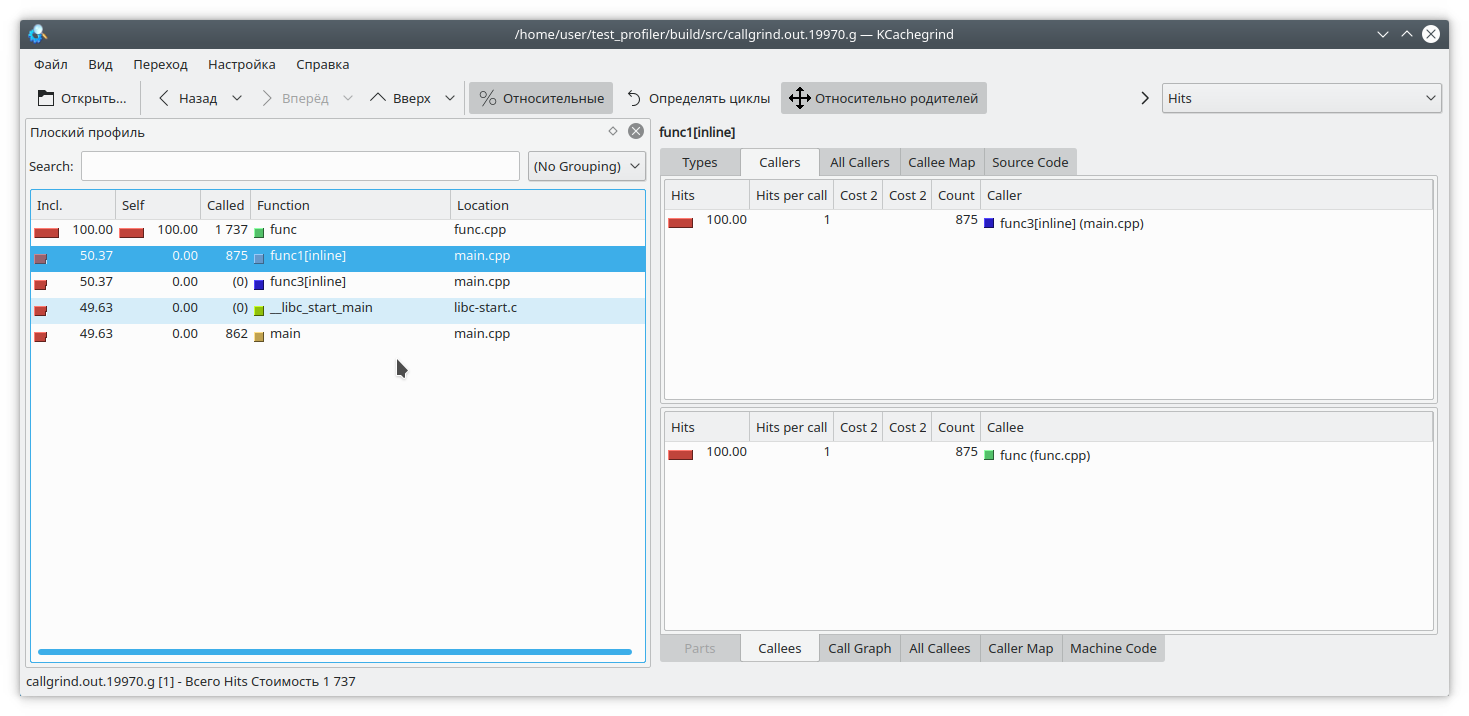
(Por cierto, valgrind aquí decidió guardar silencio modestamente y no especificar de qué función específica provenía la llamada).
Perfiles de memoria
A menudo hay situaciones en las que la memoria de la aplicación en algún lugar "fluye". Si esto se debe a la falta de limpieza de recursos, entonces Memcheck debería ayudar a identificar el problema. Pero en C ++ moderno no es tan difícil prescindir de la gestión manual de recursos. unique_ptr, shared_ptr, vector, map hacen que la manipulación de puntos desnudos no tenga sentido.
Sin embargo, en tales aplicaciones, la memoria se pierde. ¿Cómo va esto? En pocas palabras, por regla general, es algo así como "poner el valor en un mapa de larga vida, pero olvidé eliminarlo". Intentemos rastrear esta situación.
Para hacer esto, reescribimos nuestra función de prueba de esta manera
#include "func.h" #include <deque> #include <string> #include <map> static std::deque<std::string> deque; static std::map<int, std::string> map; int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; deque.emplace_back(std::to_string(res) + " integer"); map[i] = "integer " + std::to_string(res); deque.pop_front(); if (res % 200 != 0) { map.erase(i - 1); } } return fst; }
Aquí, en cada iteración, agregamos algunos elementos al mapa, y por casualidad (verdadero, verdadero) olvidamos eliminarlos a veces de allí. Además, para evitar nuestros ojos, torturamos std :: deque un poco.
Detectaremos pérdidas de memoria con dos herramientas:
valgrind massif y
google heapdump .
Macizo
Ejecute el programa con este comando
valgrind --tool=massif ./test_profiler 1000000
Y vemos algo como
Macizo time=1277949333 mem_heap_B=313518 mem_heap_extra_B=58266 mem_stacks_B=0 heap_tree=detailed n4: 313518 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 195696 0x109A69: func(int) (new_allocator.h:111) n0: 195696 0x10947A: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 42966 0x10A7EC: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (new_allocator.h:111) n1: 42966 0x10AAD9: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 42966 0x1099D4: func(int) (basic_string.h:1932) n0: 42966 0x10947A: main (main.cpp:18) n0: 0 in 2 places, all below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
Se puede ver que el macizo pudo detectar una fuga en la función, pero hasta ahora no está claro dónde. Reconstruyamos el programa con el
indicador -fno-inline y
volvamos a ejecutar el análisis.
macizo time=3160199549 mem_heap_B=345142 mem_heap_extra_B=65986 mem_stacks_B=0 heap_tree=detailed n4: 345142 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 221616 0x10CDBC: std::_Rb_tree_node<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >* std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_create_node<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .isra.81] (stl_tree.h:653) n1: 221616 0x10CE0C: std::_Rb_tree_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_emplace_hint_unique<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::_Rb_tree_const_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .constprop.87] (stl_tree.h:2414) n1: 221616 0x10CF2B: std::map<int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::operator[](int const&) (stl_map.h:499) n1: 221616 0x10A7F5: func(int) (func.cpp:20) n0: 221616 0x109F8E: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 48670 0x10B866: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:317) n1: 48639 0x10BB2C: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 48639 0x10A643: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > std::operator+<char, std::char_traits<char>, std::allocator<char> >(char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&&) [clone .constprop.86] (basic_string.h:6018) n1: 48639 0x10A7E5: func(int) (func.cpp:20) n0: 48639 0x109F8E: main (main.cpp:18) n0: 31 in 1 place, below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
Ahora está claro dónde está la fuga al agregar el elemento del mapa. Massif puede detectar objetos de corta duración, por lo que las manipulaciones con std :: deque son invisibles en este volcado.
Heapdump
Para que Google Heapdump funcione, debe vincular o precargar la biblioteca
tcmalloc . Esta biblioteca reemplaza las funciones estándar de asignación de memoria malloc, gratuita, ... Además, puede recopilar información sobre el uso de estas funciones, que utilizaremos al analizar el programa.
Dado que este método funciona muy lentamente (incluso en comparación con el macizo), le recomiendo que desactive inmediatamente la compilación de funciones con la opción
-fno-inline al compilar. Entonces, reconstruimos nuestra aplicación y corremos con el equipo
HEAPPROFILESIGNAL=23 HEAPPROFILE=./heap ./test_profiler 100000000
Aquí se supone que la biblioteca tcmalloc está vinculada a nuestra aplicación.
Ahora, esperamos el tiempo necesario para la formación de una fuga notable y enviamos a nuestro proceso una señal 23
kill -23 <pid>
Como resultado, aparece un archivo llamado heap.0001.heap, que convertimos al formato callgrind con el comando
pprof ./test_profiler "./heap.0001.heap" --inuse_space --callgrind > callgrind.out.4
También preste atención a las opciones de pprof. Puede elegir entre las opciones
inuse_space ,
inuse_objects ,
alloc_space ,
alloc_objects , que muestran el espacio u objetos que están en uso, o el espacio y los objetos asignados durante todo el programa, respectivamente. Estamos interesados en la opción inuse_space, que muestra el espacio de memoria utilizado actualmente.
Abra nuestro kCacheGrind favorito y vea
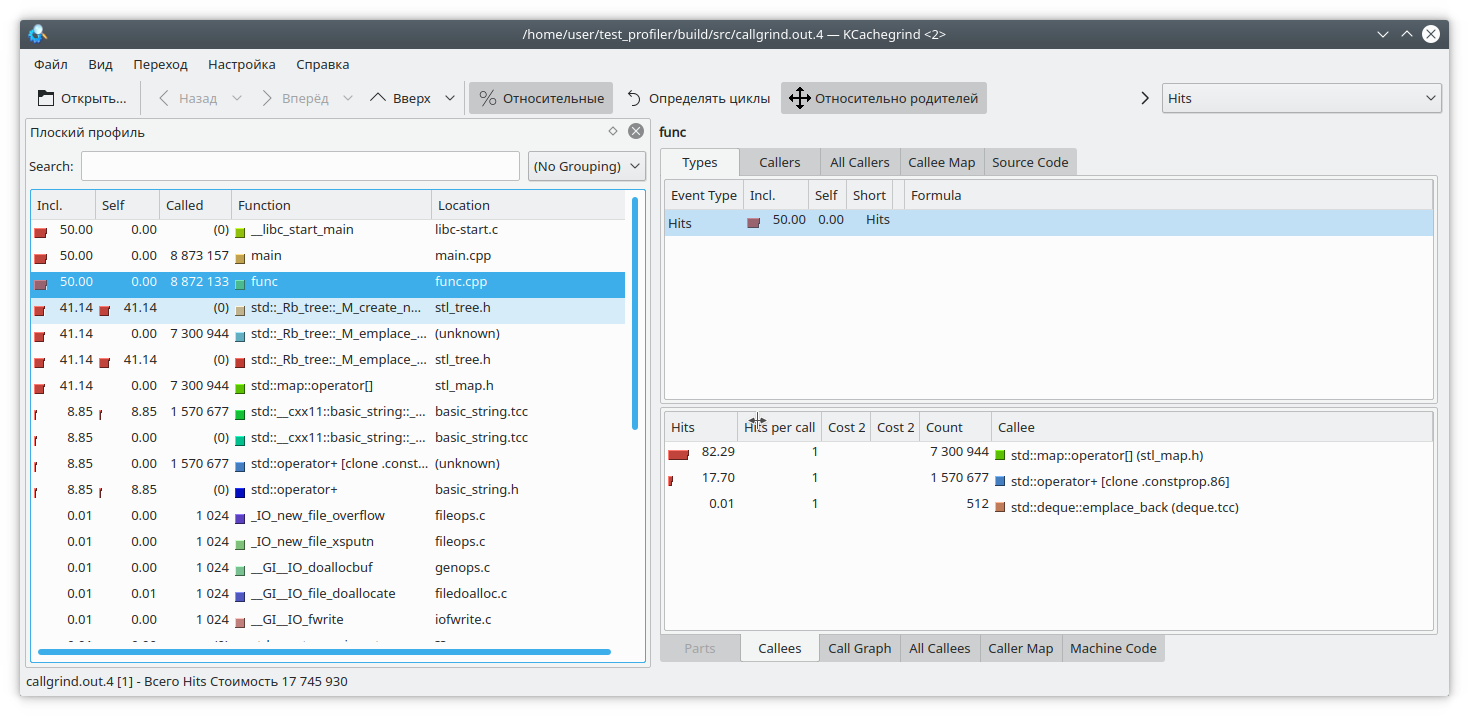
std :: map ha consumido demasiada memoria. Probablemente una fuga en él.
Conclusiones
Perfilar en C ++ es una tarea muy difícil. Aquí tenemos que lidiar con funciones de alineación, instrucciones no compatibles, resultados incorrectos, etc. No siempre es posible confiar en los resultados del generador de perfiles.
Además de las funciones propuestas anteriormente, hay otras herramientas diseñadas para perfilar: perf, intel VTune y otras. Pero también muestran algunas de estas deficiencias. Por lo tanto, no olvide el método de creación de perfiles "abuelo" midiendo el tiempo de ejecución de las funciones y mostrándolo en el registro.
Además, si tiene técnicas interesantes para perfilar su código, publíquelas en los comentarios