
Ante ustedes nuevamente, la tarea de detectar objetos. Prioridad: velocidad con precisión aceptable. Tomas la arquitectura de YOLOv3 y la entrenas. La precisión (mAp75) es mayor que 0.95. Pero la velocidad de carrera sigue siendo baja. El infierno
Hoy evitaremos la cuantización. Y debajo del corte, considere la poda de modelos : recorte de partes de red redundantes para acelerar la inferencia sin perder precisión. Visualmente: dónde, cuánto y cómo cortar. Veamos cómo hacerlo manualmente y dónde puede automatizar. Al final hay un repositorio sobre keras.
Introduccion
En el último lugar de trabajo, Perm Macroscop, tuve un hábito: siempre monitorear el tiempo de ejecución de los algoritmos. Y el tiempo de ejecución de la red siempre debe verificarse a través del filtro de adecuación. Por lo general, el estado de la técnica en el producto no pasa este filtro, lo que me llevó a la poda.
La poda es un tema antiguo del que se habló en las conferencias de Stanford de 2017. La idea principal es reducir el tamaño de la red entrenada sin perder precisión eliminando varios nodos. Suena bien, pero rara vez escucho sobre su uso. Probablemente, no hay suficientes implementaciones, no hay artículos en ruso, o simplemente todo el mundo considera los conocimientos técnicos de poda y silenciosos.
Pero ve a desmontar
Una mirada a la biología
Me encanta cuando en Deep Learning las ideas provienen de la biología. Se puede confiar en ellos, como la evolución (¿sabías que ReLU es muy similar a la función de activar las neuronas en el cerebro ?)
El proceso de poda modelo también está cerca de la biología. La respuesta de la red aquí se puede comparar con la plasticidad del cerebro. Un par de ejemplos interesantes están en el libro de Norman Dodge :
- El cerebro de una mujer que tenía solo la mitad del nacimiento se reprogramó para realizar las funciones de la mitad desaparecida.
- El tipo se disparó a sí mismo la parte del cerebro responsable de la visión. Con el tiempo, otras partes del cerebro asumieron estas funciones. (no intentes de nuevo)
Entonces, desde su modelo, puede cortar algunos de los paquetes débiles. En casos extremos, los paquetes restantes ayudarán a reemplazar los cortados.
¿Te gusta Transferir aprendizaje o aprender desde cero?
Opción número uno. Estás utilizando Transfer Learning en Yolov3. Retina, Máscara-RCNN o U-Net. Pero la mayoría de las veces, no necesitamos reconocer 80 clases de objetos, como en COCO. En mi práctica, todo está limitado a 1-2 clases. Se puede suponer que la arquitectura para 80 clases es redundante aquí. Supone la idea de que la arquitectura necesita ser reducida. Además, me gustaría hacer esto sin perder los pesos pre-entrenados existentes.
Opción número dos. Quizás tenga muchos datos y recursos informáticos, o simplemente necesite una arquitectura súper personalizada. No importa Pero aprendes la red desde cero. El orden habitual es observar la estructura de datos, seleccionar una arquitectura que se REDUZCA en términos de potencia e impulsar el abandono del reciclaje. Vi abandonos 0.6, Carl.
En ambos casos, la red se puede reducir. Promocionado Ahora vamos a averiguar qué tipo de circuncisión poda
Algoritmo general
Decidimos que podríamos eliminar la convolución. Se ve muy simple:
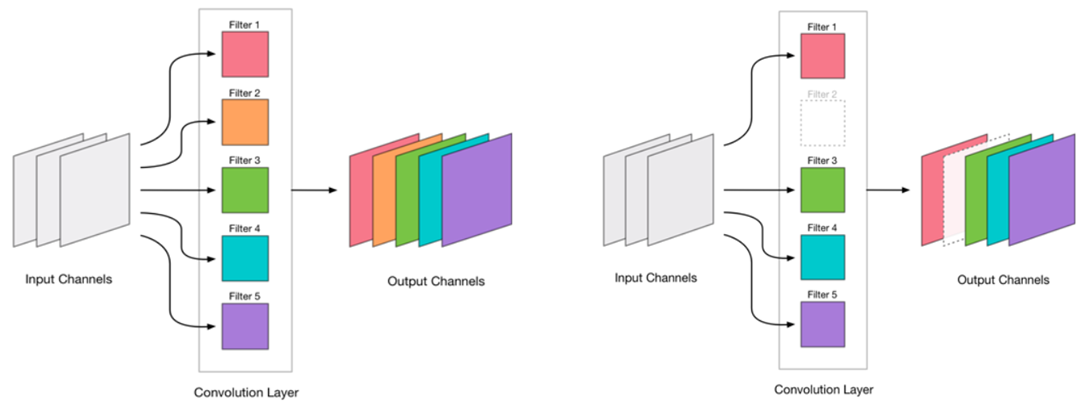
Eliminar cualquier convolución es un estrés para la red, que generalmente conduce a un aumento en el error. Por un lado, este crecimiento en error es un indicador de cuán correctamente eliminamos las convoluciones (por ejemplo, un gran crecimiento indica que estamos haciendo algo mal). Pero el crecimiento pequeño es bastante aceptable y a menudo se elimina mediante un entrenamiento posterior fácil y posterior con un LR pequeño. Agregamos un paso de reentrenamiento:
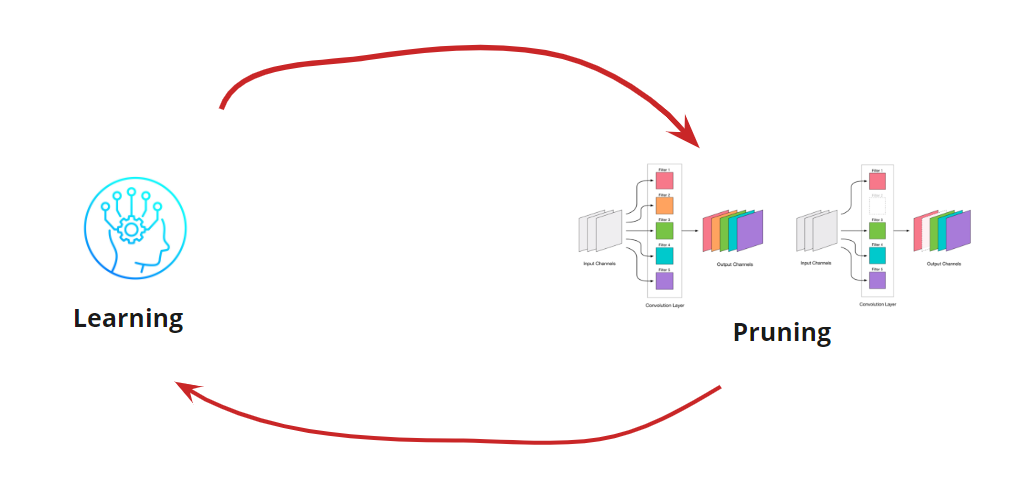
Ahora tenemos que entender cuándo queremos detener nuestro ciclo de Aprendizaje <-> Poda. Puede haber opciones exóticas cuando necesitamos reducir la red a un cierto tamaño y velocidad de ejecución (por ejemplo, para dispositivos móviles). Sin embargo, la opción más común es continuar el ciclo hasta que el error sea más alto que el permitido. Añadir condición:
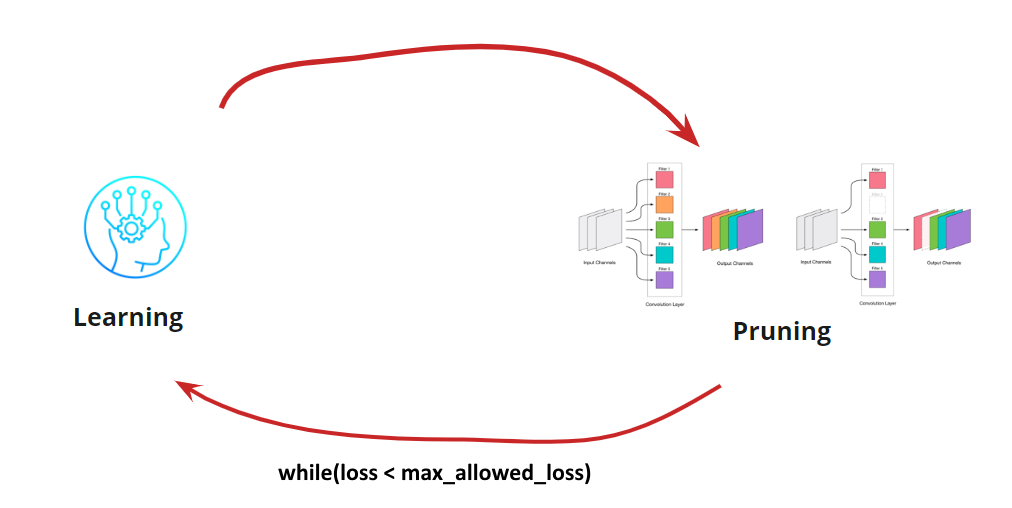
Entonces, el algoritmo se vuelve claro. Queda por desmontar cómo determinar las circunvoluciones eliminadas.
Busque la convolución que se eliminará
Necesitamos eliminar algunas convoluciones. Avanzar y "disparar" cualquiera es una mala idea, aunque funcionará. Pero si tiene cabeza, puede pensar e intentar seleccionar convoluciones "débiles" para eliminarlas. Hay varias opciones:
- La medida L1 más pequeña o poda de baja_magnitud . La idea de que las convoluciones con pequeños pesos hacen una pequeña contribución a la decisión final
- La medida L1 más pequeña teniendo en cuenta la desviación promedio y estándar. Complementamos la evaluación de la naturaleza de la distribución.
- Enmascarar las convoluciones y eliminar lo menos que afecte la precisión resultante . Una definición más precisa de convoluciones insignificantes, pero que consume mucho tiempo y recursos.
- Otros
Cada una de las opciones tiene derecho a la vida y sus propias características de implementación. Aquí consideramos la variante con la medida L1 más pequeña
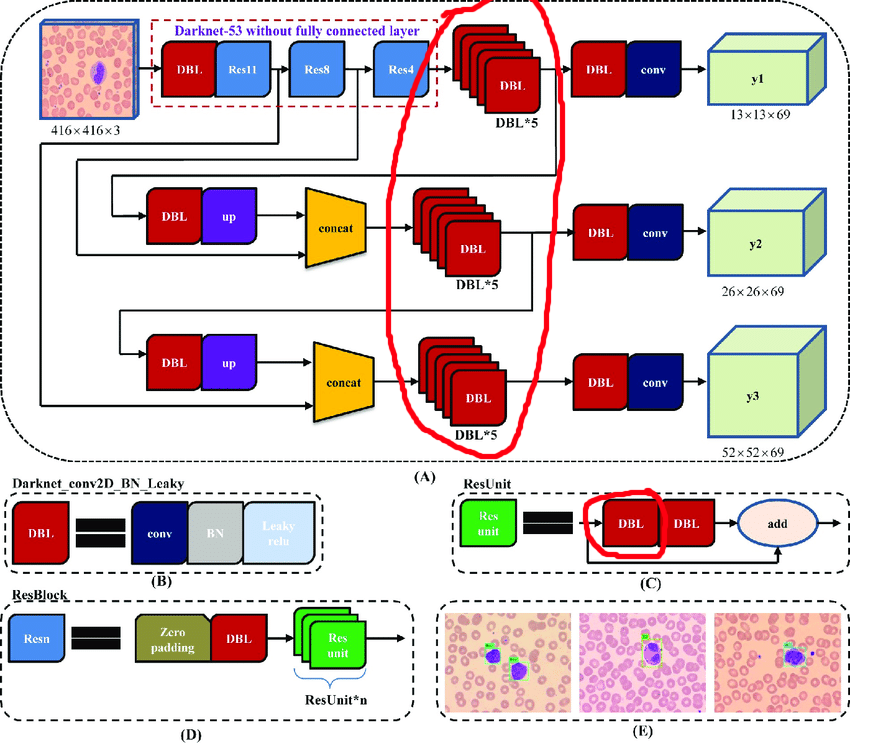
Proceso manual para YOLOv3
La arquitectura original contiene bloques residuales. Pero no importa cuán geniales sean para las redes profundas, nos obstaculizarán un poco. La dificultad es que no puede eliminar las conciliaciones con diferentes índices en estas capas:

Por lo tanto, seleccionamos las capas de las que podemos eliminar libremente las conciliaciones:
Ahora construyamos un ciclo de trabajo:
- Descarga de activación
- Nos preguntamos cuanto cortar
- Recortar
- Aprende 10 eras con LR = 1e-4
- Prueba
La descarga de convoluciones es útil para evaluar qué parte podemos eliminar en un determinado paso. Ejemplos de descarga:

Vemos que en casi todas partes, el 5% de las convoluciones tienen una norma L1 muy baja y podemos eliminarlas. En cada paso, dicha descarga se repitió y se realizó una evaluación de qué capas y cuánto podrían cortarse.
Todo el proceso se completó en 4 pasos (aquí y en todas partes los números para el RTX 2060 Super):
Al paso 2, se agregó un efecto positivo: el tamaño del parche 4 quedó en la memoria, lo que aceleró enormemente el proceso de reentrenamiento.
En el paso 4, el proceso se detuvo porque incluso una educación superior prolongada no elevó el mAp75 a valores antiguos.
Como resultado, logramos acelerar la inferencia en un 15% , reducir el tamaño en un 35% y no perder precisión.
Automatización para arquitecturas más simples.
Para arquitecturas de red más simples (sin adición condicional, bloques concaternos y residuales), es muy posible centrarse en el procesamiento de todas las capas convolucionales y automatizar el proceso de corte de convoluciones.
He implementado esta opción aquí .
Es simple: solo tiene una función de pérdida, un optimizador y generadores de lotes:
import pruning from keras.optimizers import Adam from keras.utils import Sequence train_batch_generator = BatchGenerator... score_batch_generator = BatchGenerator... opt = Adam(lr=1e-4) pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt) pruner.prune(train_batch, valid_batch)
Si es necesario, puede cambiar los parámetros de configuración:
{ "input_model_path": "model.h5", "output_model_path": "model_pruned.h5", "finetuning_epochs": 10, # the number of epochs for train between pruning steps "stop_loss": 0.1, # loss for stopping process "pruning_percent_step": 0.05, # part of convs for delete on every pruning step "pruning_standart_deviation_part": 0.2 # shift for limit pruning part }
Además, se implementa una restricción basada en la desviación estándar. El objetivo es limitar una parte de las eliminadas, excluyendo convoluciones con medidas L1 ya "suficientes":
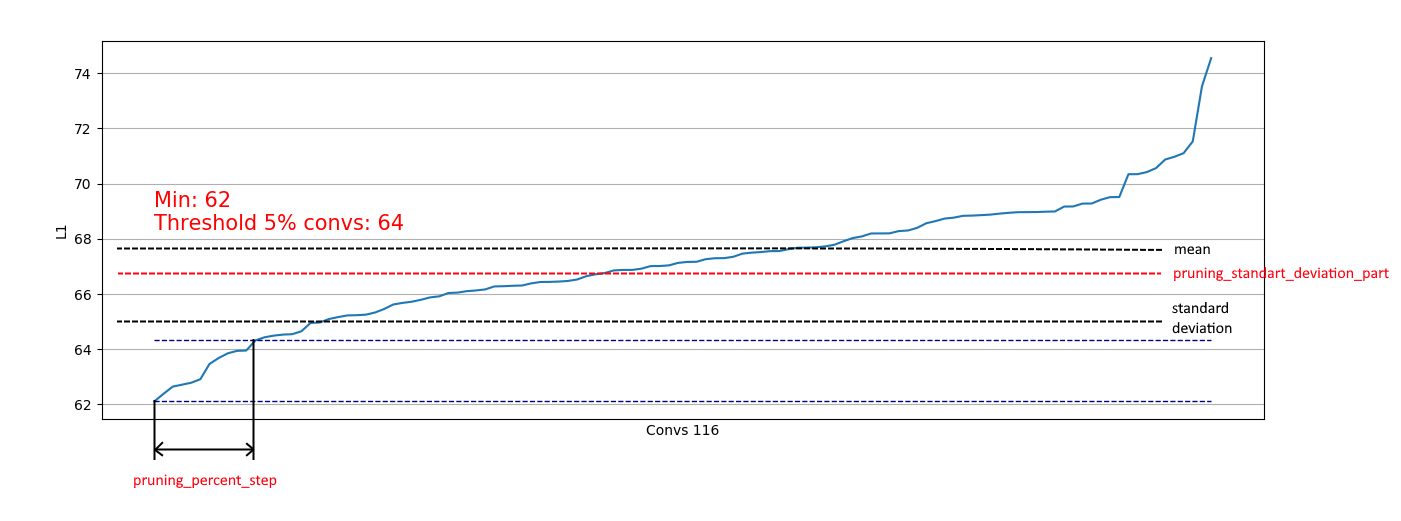
Por lo tanto, podemos eliminar solo convoluciones débiles de distribuciones similares a la derecha y no afectar la eliminación de distribuciones como la izquierda:

Cuando la distribución se acerca a lo normal, el coeficiente pruning_standart_deviation_part se puede seleccionar de:

Recomiendo una suposición de 2 sigma. O no puede enfocarse en esta característica, dejando el valor <1.0.
El resultado es un gráfico del tamaño de la red, la pérdida y el tiempo de ejecución de la red para toda la prueba, normalizado a 1.0. Por ejemplo, aquí el tamaño de la red se redujo casi 2 veces sin pérdida de calidad (una red de convolución pequeña para 100k pesos):
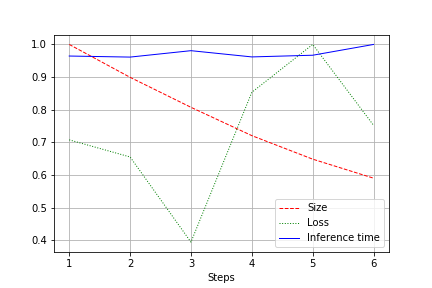
La velocidad de carrera está sujeta a fluctuaciones normales y no ha cambiado mucho. Hay una explicación para esto:
- El número de convoluciones cambia de conveniente (32, 64, 128) a no el más conveniente para tarjetas de video: 27, 51, etc. Aquí puedo estar equivocado, pero lo más probable es que afecte.
- La arquitectura no es amplia, sino consistente. Al reducir el ancho, no tocamos la profundidad. Por lo tanto, reducimos la carga, pero no cambiamos la velocidad.
Por lo tanto, la mejora se expresó en una disminución en la carga de CUDA durante la ejecución en un 20-30%, pero no en una disminución en el tiempo de ejecución
Resumen
Reflexionar. Consideramos 2 opciones de poda: para YOLOv3 (cuando tiene que trabajar con las manos) y para redes con arquitecturas más fáciles. Se puede ver que en ambos casos es posible lograr una reducción en el tamaño de la red y la aceleración sin pérdida de precisión. Resultados:
- Reducción de personal
- Ejecutar la aceleración
- Reducción de carga CUDA
- Como resultado, respeto al medio ambiente (Optimizamos el uso futuro de los recursos informáticos. En algún lugar, Greta Tunberg se regocija sola)
Apéndice
- Después del paso de poda, también puede girar la cuantización (por ejemplo, con TensorRT)
- Tensorflow proporciona características para baja_magnitud_pruning . Funciona
- Quiero desarrollar el repositorio y estaré encantado de ayudar