Por lo general, en la víspera del Año Nuevo, actualizamos nuestro conjunto de datos sobre semántica abierta. Se ha hecho mucho trabajo este año, pero no ha llegado a su conclusión lógica y lo continuaremos el año que viene. Ahora queremos hablar sobre un conjunto de datos abierto no menos importante que despertó gran interés en varias conferencias lingüísticas este año, tanto por parte de investigadores como de representantes de la industria. Esta publicación se centrará en el diccionario tonal abierto del idioma ruso.

Por qué
La tonalidad, o en palabras simples bueno / malo, es una característica natural de las palabras. Natural para los humanos y sus percepciones, pero no para la comprensión informática. El lenguaje está organizado de tal manera que contiene simetría con respecto a la polaridad de las palabras y no es posible separar las palabras buenas de las malas sin recurrir al marcado externo. En realidad, inicialmente la tarea de crear un diccionario tonal surgió de la necesidad de agrupar las listas de palabras recibidas automáticamente por el algoritmo de acuerdo con su polaridad.
Por supuesto, la tonalidad es solo un aspecto del significado de una palabra, y una comprensión real del sentimiento requiere un análisis semántico completo, una comprensión de los roles en una situación particular y el conocimiento de la posición ocupada por el observador. Entonces, por ejemplo, "la reducción en el precio de las acciones" para diferentes partes puede tener una tonalidad diferente, pero "los costos han aumentado" y "las ganancias han aumentado" tienen una polaridad diferente, aunque en ambas frases el verbo crecer crece, que tiene una calificación bastante positiva (según nuestro conjunto de datos).
Hay una amplia gama de razones por las cuales atribuimos una palabra en particular a una clave específica. A veces estas son nuestras sensaciones inmediatas: alegría y anhelo; a veces son las cualidades de una persona: profesionalismo y descuido: y a veces conceptos como educación o emprendimiento asociados con instituciones sociales complejas y que brindan beneficios a largo plazo. Y la evaluación de tales palabras está fuertemente relacionada con la cultura y el contrato social. Y, en consecuencia, puede no tener una evaluación universalmente reconocida y universal.
Sin embargo, el lenguaje y la comunicación no podrían existir si los sistemas de coordenadas de diferentes personas dentro de la misma cultura no tuvieran nada en común entre sí. Y, por lo tanto, para grupos de palabras bastante grandes, su componente estimado es más o menos consistente.
Como?
Hay dos formas principales de recopilar una gran cantidad de datos lingüísticos: atraer expertos y entrevistar personas (o una versión más moderna de este último: crowdsourcing). No repetiremos sobre las diferencias obvias entre estos enfoques, sino que prestaremos atención a aquellos que tienen un impacto directo en las propiedades del conjunto de datos resultante.
El marcado experto implica una orientación clara para el uso futuro y, en consecuencia, estipula un método de toma de decisiones en una situación de ambigüedad dictada por esta aplicación. Para un conjunto de datos final, esto significa:
- fijación del área temática;
- Definición clara de la posición del observador.
Entonces, si un experto compila un diccionario tonal para analizar noticias dirigidas a una audiencia masiva, entonces ocupa la posición de un lector generalizado y acepta acuerdos tácitos entre los medios y los lectores. Digamos que la "reducción de costos" en tales instalaciones tendrá una evaluación positiva y un "crecimiento de tarifas" - negativo (de acuerdo con el conjunto de datos RusCentiLex-2017).
El crowdsourcing se ve privado de la posibilidad de establecer dicho marco y no es la herramienta óptima para resolver problemas aplicados altamente especializados. Pero nos permite capturar otro aspecto importante de la evaluación de la tonalidad: la consistencia entre los encuestados. Algunas palabras serán evaluadas inequívocamente como positivas o negativas; algunos dividirán la evaluación entre las opciones neutrales y polares; y un pequeño grupo de palabras mostrará una pronunciada inconsistencia de las calificaciones.
Distribución de consistencia de gradoA la izquierda en el gráfico está la máxima consistencia de las estimaciones, a la derecha está la máxima inconsistencia.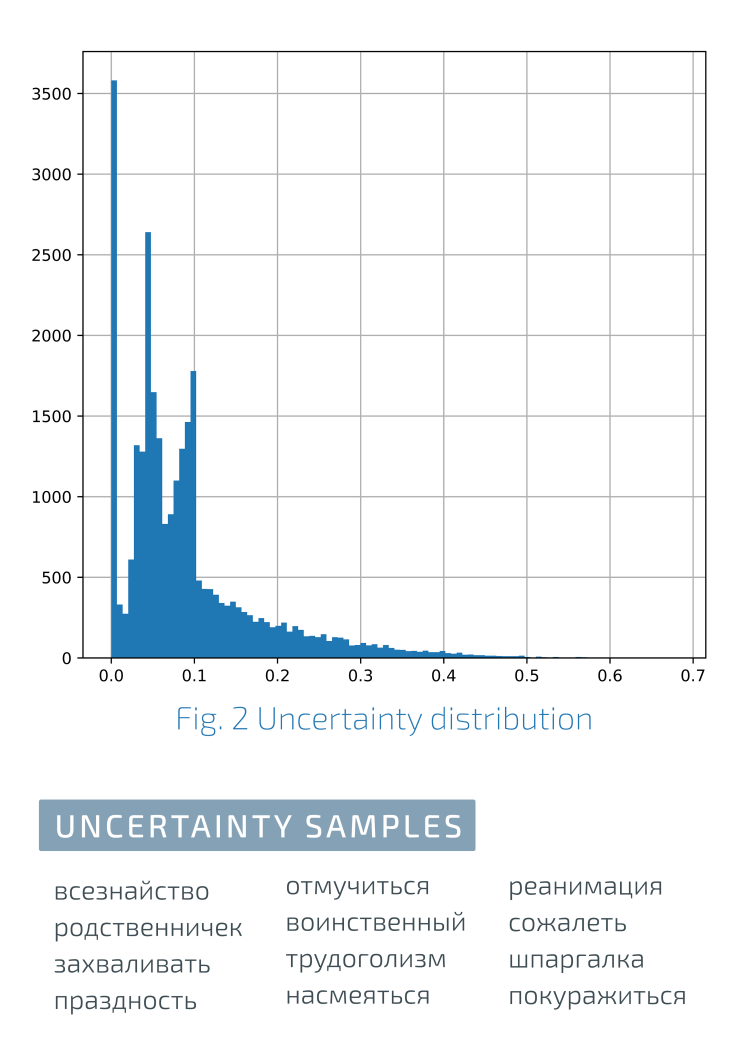
Además, a diferencia de la evaluación experta, el crowdsourcing le permite obtener un valor continuo de polaridad, delimitando palabras estrictamente positivas (negativas), bastante positivas (negativas) y neutrales. La distribución entre estos grupos depende, por supuesto, de los valores umbral seleccionados. Sin embargo, el muestreo es completamente opcional: es posible para varias aplicaciones que un valor continuo sea más conveniente.
Estructura del conjunto de datos
La estructura del conjunto de datos es bastante simple: es un diccionario tonal que hace coincidir las palabras con su evaluación en el rango de -1 (calificación negativa marginal) a +1 (calificación positiva marginal). Por conveniencia, se indica una etiqueta legible para humanos del conjunto de "positivo", "neutro", "negativo" calculado utilizando valores umbral.
Ejemplos de palabras positivas, neutrales y negativas del conjunto de datos.- positivo: confiable, reconciliar, amabilidad, perdón, concienzudo, inspirarse, fotogénico, lucro, buena crianza, reunión, inspirar, confianza, entusiasmo, niños, transformar, bienestar, inauguración de la casa, comodidad, sensible, beca, voluntario;
- neutral: abreviatura, cálculo, palo, túnica, poliedro, tacto, muebles, residente, clic, derretir, uso, paso, camino, ingrediente, desinflar, enfatizar, emblema, acostarse, armado largo, siete, dibujar;
- negativo: absentismo, risita, charla, rehén, campesino sureño, arrogante, falso, contaminación, envidioso, estrangular, congelar, derrochar, fraudulento, degradar, adicto, morder, resfriarse, encontrar fallas, asustarse, ladrón, ignorante;
Además, en esta versión del conjunto de datos (todavía hay una primera versión anterior), se proporcionan datos sin procesar: el porcentaje de votos emitidos para cada una de las opciones. Esto le permite aplicar modelos personalizados para calcular la polaridad total y el nivel de consistencia del marcado.
Nota La versión presentada del conjunto de datos cubre las palabras más reconocibles de OW (vocabulario activo); las frases no fueron etiquetadas. Al comparar con otros diccionarios de tonalidad, encontramos una serie de palabras que están disponibles en el vocabulario activo, pero que no están representadas en nuestro conjunto de datos. Haremos más marcas y planearemos incluir las unidades de idiomas faltantes durante el próximo año.
Planes adicionales
Marcar el sentimiento es una de las tareas especiales en el marco del estudio del sistema semántico del lenguaje. Como señalamos anteriormente, la utilidad del conjunto de datos presentado depende directamente de la capacidad de asociar los valores de polaridad presentados en él con otra información semántica. Con clases de palabras, por ejemplo. Comenzamos este trabajo y planeamos desarrollarlo en el futuro.
Otra área importante de investigación es el deseo de comprender la razón para colorear ciertas palabras, palabras relacionadas con sentimientos, emociones y evaluación directa y aquellas palabras en las que el concepto o la situación descritos por ellos prometen ganancias o pérdidas demoradas. Por lo tanto, tales palabras son más susceptibles a las influencias culturales y sociales.
También está previsto ampliar el marcado con frases, incluidas expresiones estables y unidades fraseológicas. Pero aquí ya estamos hablando de volúmenes de vocabulario completamente diferentes, por lo que la tarea general es comprender cómo funciona el sentimiento a un nivel más general (más bajo el spoiler).
Sentimiento y semántica.Tras un examen más detallado, queda claro que el lenguaje opera con un conjunto compacto de conceptos en relación con el número de palabras y sus combinaciones, cada una de las cuales puede expresarse en más de una forma. Esta observación se reflejó en detalle en los trabajos de los lingüistas rusos y en el modelo Sense-Text que crearon.
Por ejemplo, “reducción de precios”, “caída de precios”, “precios colapsados”, “precios disminuidos”: estas son diferentes maneras de describir un proceso similar, pero expresado por diversos medios lingüísticos. Al mismo tiempo, en contextos similares se pueden encontrar otros conceptos que tienen una expresión cuantitativa: "una caída en el nivel de confianza", "un aumento en el nivel de ingresos", etc. En cada caso, es suficiente entender la correspondencia arriba / abajo - buena / mala (nivel de conocimiento y del mundo) y por qué medio léxico se expresa el movimiento en una dirección dada (nivel de lenguaje).
Comentarios y distribución
Agradecemos cualquier comentario en los comentarios, desde críticas al trabajo y nuestros enfoques hasta enlaces a estudios interesantes y artículos relacionados.
Si tiene conocidos o colegas que pueden estar interesados en un conjunto de datos publicado, envíeles un enlace a un artículo o repositorio para ayudar a difundir los datos abiertos.
Enlace al conjunto de datos y licencia
Conjunto de datos: diccionario tonal abierto del idioma rusoEl
conjunto de datos tiene
28197 palabras de largo .
El conjunto de datos está licenciado bajo
CC BY-NC-SA 4.0 .
Enlaces a proyectos relacionados