Hola Habr!
Al final del año, logramos compartir con ustedes la noticia de que estamos comenzando a trabajar en las Estadísticas Bayesianas de manera divertida por No Starch Press. Ofrecemos una traducción de una entrevista detallada con el autor del libro; El texto se refiere tanto al libro como a temas relacionados, e incluso a lecturas adicionales.

Yo, como la mayoría de los desarrolladores, estoy inmediatamente interesado en muchas cosas: programación funcional, sistemas operativos, sistemas de tipos, sistemas distribuidos y ciencia de datos. Es por eso que me inspiró tanto saber que
Will Kurt , el autor de
Get Programming with Haskell , escribió un libro sobre estadísticas bayesianas, que fue publicado por No Starch Press. No hay mucha gente escribiendo libros sobre diversos temas. Estoy seguro de que Will tiene algo que compartir con los lectores en su nuevo libro, y no me decepcionó. El libro es un excelente material introductorio, especialmente para aquellos que no son demasiado buenos para las matemáticas difíciles, pero que aún quieren lograr algo en el campo de la ciencia de datos. Recomiendo leer el nuevo libro de Kurt después de Think Stats, pero antes de Probabilistic Python Programming: Bayesian Inference and Algorithms, Bayesian Analysis with Python y Doing Bayesian Data Analysis.
1. ¿Por qué necesitamos otro libro sobre estadísticas?Casi todos los muchos libros existentes actualmente sobre estadísticas bayesianas sugieren que el lector ya tiene una idea general de las estadísticas y una base sólida en la programación. Por lo tanto, en la actualidad, las estadísticas bayesianas a menudo se perciben como una alternativa avanzada a las estadísticas clásicas (es decir, de frecuencia). Por lo tanto, aunque las estadísticas bayesianas están creciendo en popularidad, los materiales están diseñados principalmente para personas que ya tienen una buena capacitación cuantitativa.
Cuando una persona decide simplemente "estudiar estadísticas", toma un libro introductorio en el que se presentan las estadísticas desde un punto de vista de frecuencia, lo lee, medio descifró un montón de pruebas y reglas, y siente que todo este tema es muy confuso. Quería escribir un libro sobre estadísticas bayesianas que cualquiera pueda tomar, leer y, después de leer, tener una idea intuitiva de lo que es pensar estadísticamente y cómo resolver problemas reales con la ayuda de las estadísticas. No veo ninguna razón por la cual las estadísticas bayesianas no puedan servir como el primer curso introductorio en este tema para un principiante absoluto.
Me gustaría mucho que algún día con la palabra "estadística" la gente comenzara a referirse a las estadísticas bayesianas, y las estadísticas de frecuencia se convirtieran en uno de los nichos académicos. Para esto, se necesitan más libros en los que se proponga el conocimiento de las estadísticas para una amplia gama de lectores utilizando métodos bayesianos, además, el autor tuvo en cuenta que esta puede ser la primera vez que el lector conoce las estadísticas.
Inmediatamente pensé en llamar a este libro "Estadísticas de la manera divertida", pero pensé que probablemente recibiría un montón de cartas de enojo de las personas que compraron ese libro para prepararse para el examen de ingreso de estadísticas, y encontré que es completamente diferente allí! Espero que mi libro sea un pequeño paso hacia el momento en que se preguntarán las estadísticas bayesianas en los exámenes de ingreso, y será aconsejable leer dicho libro incluso para aquellos que se están preparando para el examen.
2. ¿Cuál es el público objetivo del libro? ¿Puede una persona leerlo sin antecedentes matemáticos?Trabajando en "Las estadísticas bayesianas es genial", traté de crear un libro, en principio, comprensible para cualquiera que aprendiera matemáticas en el alcance del programa para la escuela secundaria. Incluso si solo recuerda vagamente el álgebra, el ritmo de presentación en un libro es tal que puede mantenerse al día. Las estadísticas bayesianas requieren muy poco análisis matemático y aún más simplificado con un poco de soporte de código de software, por lo que agregué dos aplicaciones al libro que brindan los conceptos básicos del lenguaje R. Este material es suficiente para que R le sirva como una calculadora avanzada, y las ideas básicas del análisis matemático se presentan en tanto, que puede descubrir todos los ejemplos de este libro, en lo que respecta a las integrales. Sin embargo, prometo que para leer el libro no tendrá que resolver ningún problema del campo del análisis matemático.
Además, por mucho que trabaje duro, tratando de minimizar la cantidad de conocimiento matemático que se necesita para leer un libro, a medida que lo lea, gradualmente comenzará a aprender la forma matemática de pensar. Si comprende las matemáticas con las que está operando correctamente, lo entenderá aún mejor. Por lo tanto, no traté de evadir las matemáticas reales, sino de explicarlas paso a paso, de modo que todas las matemáticas se vuelvan obvias para usted. Como muchos, una vez creí que las matemáticas son una ciencia compleja y es difícil trabajar con ellas. Con el tiempo, me convencí de que con el enfoque correcto, las matemáticas no causan casi ninguna dificultad. Por lo general, cualquier confusión en las matemáticas surge solo debido a los intentos de revisar el material demasiado rápido; debido a esto, se omiten los pasos importantes necesarios para un razonamiento adecuado.
3. ¿Por qué un programador debe estudiar teoría de probabilidad y estadística?Realmente creo que todos deberían estudiar la teoría de la probabilidad y las estadísticas hasta cierto punto, ya que este conocimiento ayudará a juzgar la incertidumbre que nos rodea en todas partes de la vida. En cuanto al programador, definitivamente tendrá que ocuparse de algunas tareas típicas en las que es útil comprender las estadísticas. Es muy probable que, en algún momento de su carrera profesional, tenga que escribir un código en el que algunas decisiones se tomen en función de factores difusos a priori. Quizás esto sea una medida de la conversión de la página web, la generación de algunas recompensas aleatorias en el juego, la distribución aleatoria de los usuarios en grupos, o incluso la lectura de información de algún sensor difuso. En todos estos casos, una comprensión sólida de la teoría de la probabilidad lo ayudará mucho. Mi propia práctica muestra que el enfoque probabilístico ayuda mucho a depurar muchos errores que son difíciles de reproducir o rastrear hasta un problema complejo. Si resulta que el error es causado por una memoria insuficiente, ¿puede estar seguro de que ocurrirá con más frecuencia si la memoria se corta aún más? Si un error complejo puede explicarse de dos maneras, ¿cuál es la mejor oportunidad para explorar primero? En todos estos casos, la teoría de la probabilidad puede ayudar. Por supuesto, el apogeo del aprendizaje automático y la ciencia de datos lleva al hecho de que los ingenieros tienen cada vez más que lidiar con tareas donde la programación ofrece trabajo directo con probabilidades.
4. ¿Es posible describir brevemente la diferencia entre la frecuencia y los enfoques bayesianos de la teoría de la probabilidad?En la interpretación de frecuencia, la probabilidad se interpreta como una declaración sobre la frecuencia con la que debe ocurrir un evento durante intentos repetidos. Entonces, lanzando una moneda dos veces, uno debería esperar que el águila la deje caer 1 vez, ya que la moneda tiene dos caras, y una de ellas tiene un águila. En la interpretación bayesiana, la probabilidad se interpreta como una característica de nuestro conocimiento, en principio, como una continuación de la lógica. La probabilidad de lanzar una moneda con un águila es 0.5, porque no veo ninguna razón por la cual un águila deba caer más a menudo que las colas. Entonces, en el caso de un lanzamiento de moneda, ambos enfoques son completamente funcionales. Sin embargo, cuando se trata de cosas como las probabilidades de que su equipo favorito gane la Copa del Mundo, el factor de confianza se vuelve mucho más significativo. Esto, por cierto, también significa que las estadísticas bayesianas hacen declaraciones no sobre el mundo, sino sobre nuestra comprensión del mundo. Dado que todos entienden el mundo de manera un poco diferente, las estadísticas bayesianas nos ayudan a tener en cuenta estas diferencias en nuestro análisis. En muchos sentidos, el análisis bayesiano es la ciencia de la evolución de las opiniones.
5. ¿Por qué se centra el libro en el enfoque bayesiano?Hay muchas buenas razones filosóficas para centrarse en las estadísticas bayesianas, pero me guié por una razón completamente práctica: con el enfoque bayesiano, todo se vuelve lógico. Basado en un conjunto relativamente pequeño de reglas intuitivas, puede desarrollar una solución para casi cualquier problema que pueda encontrar. Es por eso que las estadísticas bayesianas son tan poderosas y flexibles, y por qué son tan fáciles de aprender. Creo que la forma de razonar bayesiana se adapta exactamente a los programadores. No intenta resolver el problema con la ayuda de pruebas improvisadas, pero razona sobre ello y gradualmente llega a una solución verdaderamente justificada. En principio, las estadísticas bayesianas: este es el razonamiento. Usted está de acuerdo con el análisis estático solo si es realmente lógico y convincente para usted, y no porque su prueba que parece arbitraria le dé un valor igualmente sin fundamento. Además, las estadísticas bayesianas permiten dudar del resultado y desde un punto de vista cualitativo. En la práctica diaria, a menudo sucede que a dos personas se les presentan los mismos hechos, pero sus conclusiones son diferentes. Las estadísticas bayesianas nos permiten modelar formalmente tal diferencia de opinión, para que podamos verificar por nosotros mismos qué hechos serán necesarios para que cambiemos nuestro punto de vista. No tiene que creer los resultados declarados en el papel debido a algún valor p, los cree, porque le parecen realmente convincentes.
6. Cómo se relacionan las estadísticas bayesianas con el aprendizaje automáticoEntre las similitudes entre el aprendizaje automático (en particular, las redes neuronales) y las estadísticas bayesianas en las que he pensado están las siguientes: en ambas disciplinas, el análisis matemático puede ser extremadamente complicado. En principio, el aprendizaje automático es la comprensión y solución de derivados muy no triviales. Obtiene una función, y para ello, una función de pérdida, luego (automáticamente) calcula la derivada e intenta seguirla hasta que lo lleve a los parámetros óptimos. Muchos notan maliciosamente que la propagación hacia atrás es solo una "regla de cadena", pero en casi todas las tareas complejas relacionadas con el aprendizaje automático, se usa con mucho éxito.
La estadística bayesiana es otra faceta del análisis matemático asociado con la resolución de integrales verdaderamente complejas. Michael Betancourt, el autor de Stan, notó perfectamente que casi todos los análisis bayesianos están relacionados con el cálculo de expectativas, es decir, con el cálculo de integrales. Como resultado del análisis bayesiano, todavía tiene una distribución posterior, pero no puede usarla de ninguna manera sin integrarla y, por lo tanto, no obtener una respuesta concreta. Afortunadamente, nadie hace comentarios viciosos sobre las integrales, ya que todos saben que incluso la integral más trivial es bastante complicada. Así es como se formula aforísticamente en uno de los cómics de xkcd:
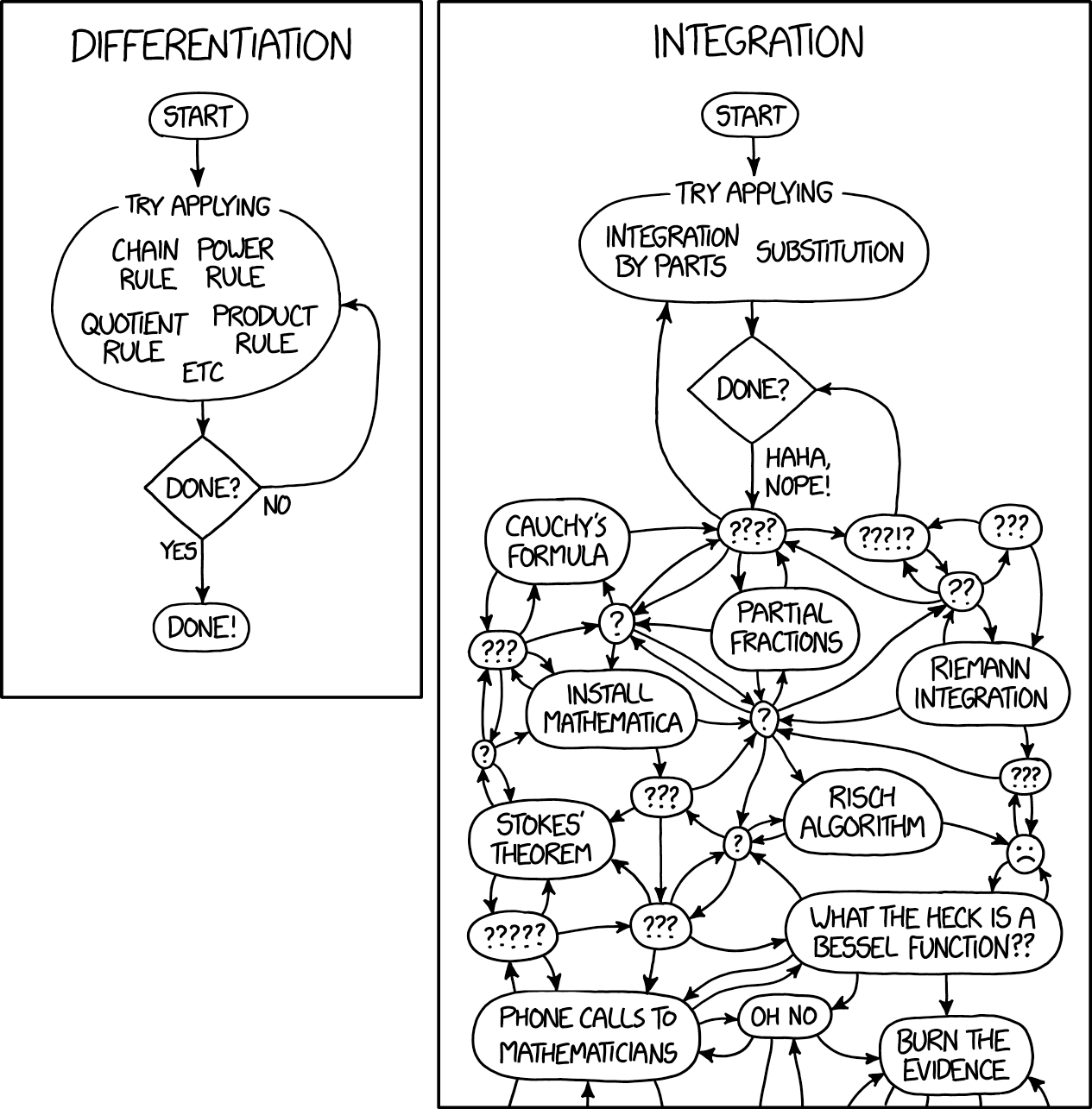
Hoy en día, el aprendizaje automático y las estadísticas bayesianas se encuentran en un estado tan extraño: desarrollamos las ideas más simples del análisis matemático a tal grado de complejidad que solo se presta a la computación.
Esta relación también destaca un punto clave. Cuando hablamos de derivados, estamos buscando un punto específico relacionado con una función. Entonces, si conoce la posición y el tiempo, entonces la velocidad es una derivada que se supone que determina cuándo se movía más rápido. Un pequeño paso hacia el progreso en MO es cuando descubres que una sola métrica es mejor que nadie. La integración es la suma de todo el proceso. Una vez más, si conoce el lugar y el tiempo, entonces la integral es la distancia, le permite averiguar qué tan lejos ha llegado. Las estadísticas bayesianas son un resumen de todo lo que sabe sobre un problema, pero le permite no solo hacer pronósticos por separado, sino también caracterizar el grado de confianza en nuestros pronósticos, que se encuentran en una amplia gama de opciones. El progreso en las estadísticas bayesianas es una comprensión de los sistemas de información cada vez más complejos.
7. Si los lectores quieren familiarizarse más con el tema del libro, ¿qué materiales (libros, cursos, blogs) les aconsejarán?Tomé la máxima inspiración del libro de I. T. Jane "Teoría de la probabilidad: la lógica de la ciencia". Secretamente, espero que mi libro "Las estadísticas bayesianas es genial" pueda convertirse en un análogo de su libro, pero dirigido a una amplia gama de lectores. Trabajar con el libro de Janes no es una tarea fácil, y presenta un resultado muy radical de las estadísticas bayesianas. Aubrey Clayton hizo un buen servicio a sus lectores al escribir una
serie de conferencias sobre los capítulos de este libro.
Por supuesto, si te gusta el libro, entonces probablemente te gustará mi blog. Recientemente, no escribí mucho allí, porque escribí el libro "Las estadísticas bayesianas son geniales", y antes de eso "Obtener programación con Haskell", pero ahora tengo una cabeza llena de ideas, y no todas están dedicadas estrictamente a Bayesiano temas Como regla general, reflexiono sobre un tema del campo de la estadística / probabilidad, y de esta idea selecciono cuidadosamente un nuevo artículo para el blog.
8. En su experiencia, ¿qué concepto en el campo de la teoría de la probabilidad / estadística es particularmente difícil de entender?Honestamente, la parte más difícil es la interpretación de las probabilidades. La gente realmente perdió la fe en muchos analistas bayesianos, como Nate Silver (y muchos otros), cuando predijeron que Hillary Clinton ganaría las elecciones de 2016 con una probabilidad del 80%, y ella perdió. La gente pensaba que alguien los había engañado, y todos estaban equivocados, pero, de hecho, la probabilidad del 80% no es tanto. Si el médico me dice que mis posibilidades de supervivencia son del 80%, entonces estoy muy nervioso.
Como regla general, este problema se resuelve de la siguiente manera: indicamos las probabilidades como tales y declaramos que no son adecuadas para expresar incertidumbre. Para hacer frente a este inconveniente, debe utilizar coeficientes o razones de probabilidad, o algún tipo de sistema similar a decibelios, como el concepto de Jane de "evidencia". Sin embargo, después de haber pensado en las probabilidades durante mucho tiempo, llegué a la conclusión de que no existe una forma especialmente adecuada para expresar la incertidumbre.
La esencia del problema es que cada uno de nosotros está profundamente convencido de que hay certeza en el mundo. Incluso los especialistas experimentados en teoría de la probabilidad tienen la sensación de que, si realiza el análisis correcto, descubre los datos a priori necesarios, agrega otro nivel a su modelo jerárquico, tendrá éxito y se librará de la incertidumbre o al menos la reducirá. . Las probabilidades son en parte atractivas para mí debido a esta extraña combinación de estos dos factores: el deseo de comprender el mundo y el reconocimiento de que, no importa cómo lo intentes, el mundo te sorprenderá de todos modos.
9. ¿Qué opina de los valores p como una medida de significación estadística? ¿Podría describir brevemente qué es p-hacking?En el caso de los valores p, a menudo se malinterpretan dos cosas. Primero, una persona inteligente no intentará responder preguntas con valores p. Imagine cómo sería la siguiente conversación en el trabajo:
Gerente: "Arreglaste este error, ¿cómo te fue asignado?"
Usted: "Bueno, estoy más que seguro de que no lo arreglé ..."
Gerente: "Si lo arregló, marque que lo arregló".
Usted: "Oh, no, no puedo decir que lo arreglé ..."
Gerente: "Bueno, ¿vas a marcarlo" No lo arreglaré "?"
Usted: "No, no, por supuesto, no es así en absoluto"
Los valores p de muchos son confusos, ya que son intrínsecamente oscuros. Las estadísticas bayesianas le indican una probabilidad posterior, que es una respuesta positiva a una pregunta formulada como desee. En el diálogo anterior, el Bayesiano dice: "Estoy bastante seguro de que el error se ha solucionado". Si el gerente quiere que responda con más confianza, el Bayesiano puede recopilar información adicional y decir: "Yo, en principio, estoy seguro de que está solucionado".
El segundo problema es el hábito arraigado de elegir 0.05 como algún tipo de significado mágico, supuestamente significativo. Volviendo a la pregunta anterior sobre la comprensión de las probabilidades, la probabilidad del 5% de que ocurra un determinado evento no significa que este evento sea raro. Tendrá un 5% de posibilidades de obtener 20 puntos al lanzar un dado de 20 lados. Sin embargo, cualquiera que haya jugado Dungeons and Dragons sabe que esto está lejos de ser imposible. Más allá de los juegos de rol, tirar un hueso no es la mejor herramienta para distinguir la verdad de las mentiras.
Aquí llegamos a p-hacking. Imagine que juega Dungeons and Dragons con sus amigos y tira 20 dados a la vez. Luego, señala el punto en el que cayeron 20 puntos y declara: "era este hueso el que iba a lanzar, y todos los demás eran de prueba". Formalmente, realmente obtuviste 20 puntos, pero esto sigue siendo una estafa, ya ves. Esta es la esencia del p-hacking. Usted hace el análisis hasta que encuentra algo "esencial", y luego afirma que esto es lo que estaba buscando desde el principio.
10. ¿Recomendaciones finales sobre qué libro leer después del tuyo?, , , , . «Bayesian Analysis with Python» (, Not Monad Tutorial). , PyMC3. , . , — “Statistical Rethinking” . , .
. « – ». , «Doing Bayesian Data Analysis» .