Las redes neuronales han crecido de un estado de curiosidad académica a una industria masiva.

Durante la última década, las computadoras han mejorado significativamente su capacidad de comprender el mundo que las rodea. El software para equipos fotográficos reconoce automáticamente los rostros de las personas. Los teléfonos inteligentes convierten la voz en texto. Los robomobiles reconocen objetos en el camino y evitan colisiones con ellos.
En el corazón de todos estos avances está la tecnología de inteligencia artificial (IA) llamada aprendizaje profundo (GO). GO se basa en redes neuronales (NS), estructuras de datos inspiradas en redes compuestas de neuronas biológicas. Los NS están organizados en capas, y las entradas de una capa están conectadas a las salidas de la vecina.
Los informáticos han estado experimentando con NS desde la década de 1950. Sin embargo, la base de la vasta industria de GO de hoy se estableció por dos avances importantes: uno ocurrió en 1986, el segundo en 2012. El avance de 2012, la revolución de GO, se asoció con el descubrimiento de que el uso de NS con una gran cantidad de capas nos permitirá mejorar significativamente su eficiencia. El descubrimiento fue facilitado por los crecientes volúmenes de datos y potencia informática.
En este artículo, le presentaremos el mundo de la Asamblea Nacional. Explicaremos qué es NS, cómo funcionan y de dónde provienen. Y estudiaremos por qué, a pesar de muchas décadas de investigación previa, los NS se convirtieron en algo realmente útil solo en 2012.
Las redes neuronales aparecieron en la década de 1950.
 Frank Rosenblatt está trabajando en su perceptrón, uno de los primeros modelos de NS
Frank Rosenblatt está trabajando en su perceptrón, uno de los primeros modelos de NSLa idea de la Asamblea Nacional es bastante antigua, al menos según los estándares de la informática. En 1957,
Frank Rosenblatt, de la Universidad de Cornell, publicó un
informe que describe un concepto de NS temprano llamado perceptrón. En 1958, con el apoyo de la Marina de los EE. UU., Creó un sistema primitivo capaz de analizar 20x20 píxeles y reconocer formas geométricas simples.
El objetivo principal de Rosenblatt no era crear un sistema práctico de clasificación de imágenes. Trató de entender cómo funciona el cerebro humano, creando sistemas informáticos organizados a su imagen. Sin embargo, este concepto ha generado un entusiasmo excesivo por parte de terceros.
"Hoy, la Marina de los EE. UU. Ha revelado al mundo el germen de una computadora electrónica, que se espera que pueda caminar, hablar, ver, escribir, reproducirse y ser consciente de su existencia", escribió el New York Times.
De hecho, cada neurona en el NS es solo una función matemática. Cada neurona calcula la suma ponderada de los datos de entrada: cuanto mayor es el peso de entrada, más fuertemente afectan estos datos de entrada a la salida de la neurona. Luego, la suma ponderada se alimenta a la función de "activación" no lineal; en este paso, los NS pueden simular fenómenos no lineales complejos.
Las habilidades de los primeros perceptrones con los que Rosenblatt experimentó, y NS en general, provienen de su capacidad de "aprender" con ejemplos. Los NS se entrenan ajustando los pesos de entrada de las neuronas en función de los resultados de la red con los datos de entrada seleccionados, por ejemplo. Si la red clasifica correctamente la imagen, los pesos que contribuyen a la respuesta correcta aumentan, mientras que otros disminuyen. Si la red está mal, los pesos se ajustan en la otra dirección.
Tal procedimiento permitió a los NS tempranos "aprender" de una manera que recordaba el comportamiento del sistema nervioso humano. La exageración que rodea este enfoque no se detuvo en la década de 1960. Sin embargo, el
influyente libro de 1969 de los autores de los científicos informáticos Marvin Minsky y Seymour Papert mostró que estos primeros NA tienen limitaciones significativas.
Los primeros NS de Rosenblatt tenían solo una o dos capas entrenadas. Minsky y Papert demostraron que tales NS son matemáticamente incapaces de modelar fenómenos complejos del mundo real.
En principio, las NS más profundas eran más capaces. Sin embargo, tal NS sobrecargaría esos recursos informáticos miserables que tenían las computadoras en ese momento. Los algoritmos de
búsqueda ascendente más simples utilizados en los primeros NS no escalaban para NS más profundos.
Como resultado, la Asamblea Nacional perdió todo el apoyo en los años setenta y principios de los ochenta, fue parte de la era del "invierno de la IA".
Algoritmo innovador
 Mi propia red neuronal basada en "equipo blando" cree que la probabilidad de tener un hot dog en esta foto es 1. ¡Nos haremos ricos!
Mi propia red neuronal basada en "equipo blando" cree que la probabilidad de tener un hot dog en esta foto es 1. ¡Nos haremos ricos!La suerte volvió a recurrir al NS gracias al famoso
trabajo de 1986, que introdujo el concepto de propagación hacia atrás, un método práctico para enseñar NS.
Suponga que trabaja como programador en una compañía de software imaginaria y se le ha indicado que cree una aplicación que determine si hay un hot dog en la imagen. Comienza a trabajar con un NS inicializado al azar, que toma una imagen de entrada y genera un valor de 0 a 1, donde 1 significa "hot dog" y 0 significa "no hot dog".
Para entrenar a la red, recopila miles de imágenes, debajo de cada una de las cuales hay una etiqueta que indica si hay un hot dog en esta imagen. Le das de comer la primera imagen, y hay un hot dog en ella, en la red neuronal. Da un valor de salida de 0.07, lo que significa "no hot dog". Esta es la respuesta incorrecta; la red debería haber devuelto una respuesta cercana a 1.
El objetivo del algoritmo de retropropagación es ajustar los pesos de entrada para que la red produzca un valor más alto si se le vuelve a dar esta imagen, y, preferiblemente, otras imágenes donde hay perros calientes. Para esto, el algoritmo de retropropagación comienza examinando las neuronas de entrada de la capa de salida. Cada valor tiene una variable de peso. El algoritmo de retropropagación ajusta cada peso en una dirección tal que el NS da un valor más alto. Cuanto mayor sea el valor de entrada, más aumenta su peso.
Hasta ahora, estoy describiendo el ascenso más simple a la cima familiar para los investigadores en la década de 1960. El avance de la retropropagación fue el siguiente paso: el algoritmo utiliza derivadas parciales para distribuir la "falla" de la salida incorrecta entre las entradas de las neuronas. El algoritmo calcula cómo un pequeño cambio en cada valor de entrada afectará la salida final de una neurona, y si este cambio acercará el resultado a la respuesta correcta, o viceversa.
El resultado es un conjunto de valores de error para cada neurona en la capa anterior; de hecho, una señal que evalúa si el valor de cada neurona es demasiado grande o demasiado pequeño. Luego, el algoritmo repite el proceso de ajuste para nuevas neuronas desde la segunda capa [desde el final]. Cambia ligeramente los pesos de entrada de cada neurona para acercar la red a la respuesta correcta.
Luego, el algoritmo nuevamente utiliza derivadas parciales para calcular cómo el valor de cada entrada de la capa anterior afectó los errores de salida de esta capa, y propaga estos errores nuevamente a la capa anterior, donde el proceso se repite nuevamente.
Este es solo un modelo simplificado de retropropagación. Si necesita detalles matemáticos detallados, le recomiendo el libro de Michael Nielsen sobre este tema [
y tenemos su traducción / aprox. transl.]. Para nuestros propósitos, es suficiente que la distribución inversa cambie radicalmente el rango de NS entrenado. Las personas ya no estaban limitadas a redes simples con una o dos capas. Podrían crear redes con cinco, diez o cincuenta capas, y estas redes podrían tener una estructura interna arbitrariamente compleja.
La invención de la propagación hacia atrás lanzó el segundo auge de la Asamblea Nacional, que comenzó a producir resultados prácticos. En 1998, un grupo de investigadores de AT&T mostró cómo las redes neuronales se pueden usar para reconocer números escritos a mano, lo que permitió automatizar el procesamiento de cheques.
"El mensaje principal de este trabajo es que podemos crear sistemas mejorados para reconocer patrones, confiando más en el aprendizaje automático y menos en la heurística desarrollada manualmente", escribieron los autores.
Y, sin embargo, en esta fase, los NS fueron solo una de las muchas tecnologías a disposición de los investigadores de aprendizaje automático. Cuando estudié en un curso de IA en el instituto en 2008, las redes neuronales eran solo uno de los nueve algoritmos MO, de los cuales podíamos elegir la opción adecuada para la tarea. Sin embargo, GO ya se estaba preparando para eclipsar el resto de la tecnología.
Big data demuestra el poder del aprendizaje profundo
 Relajación detectada. Posibilidad de la playa 1.0. Comenzamos el procedimiento de usar Mai Tai.
Relajación detectada. Posibilidad de la playa 1.0. Comenzamos el procedimiento de usar Mai Tai.La retropropagación facilitó el proceso de cálculo de NS, pero las redes más profundas aún necesitaban más recursos informáticos que las pequeñas. Los resultados de los estudios realizados en los años 1990 y 2000 a menudo mostraron que era posible obtener cada vez menos beneficios de una complicación adicional de la NS.
Luego, el famoso trabajo de 2012 cambió el pensamiento de la gente, que describió el NS bajo el nombre de AlexNet, llamado así por el investigador líder Alex Krizhevsky. Al igual que las redes más profundas, podrían proporcionar una eficiencia innovadora, pero solo en combinación con una gran cantidad de energía de la computadora y una gran cantidad de datos.
AlexNet ha desarrollado un trío de informáticos de la Universidad de Toronto para participar en la competencia científica ImageNet. Los organizadores del concurso recopilaron un millón de imágenes en Internet, cada una de las cuales fue etiquetada y asignada a una de las miles de categorías de objetos, por ejemplo, "cereza", "portacontenedores" o "leopardo". Se pidió a los investigadores de IA que entrenaran sus programas de MO en partes de estas imágenes, y luego trataran de poner las etiquetas correctas para otras imágenes que el software no había encontrado antes. El software tuvo que seleccionar cinco posibles etiquetas para cada imagen, y el intento se consideró exitoso si una de ellas coincidía con la real.
Esta fue una tarea difícil, y hasta 2012 los resultados no fueron muy buenos. Para el ganador de 2011, la tasa de error fue del 25%.
En 2012, el equipo de AlexNet superó a todos los competidores al dar respuestas con un 15% de errores. Para el competidor más cercano, esta cifra fue del 26%.
Investigadores de Toronto combinaron varias técnicas para lograr resultados innovadores. Uno de ellos fue el uso de
neurosis convolucionales (SNS). De hecho, el SNA, por así decirlo, entrena pequeñas redes neuronales, cuyos datos de entrada son cuadrados con un lado de 7 a 11 píxeles, y luego los "superpone" en una imagen más grande.
"Es como si tomas una plantilla pequeña o una plantilla y tratas de compararla con cada punto de la imagen", nos dijo el investigador de IA Jie Tan el año pasado. - ¿Tienes una plantilla de un perro, y la pegas a la imagen y ves si hay un perro allí? Si no, mueva la plantilla. Y así, para toda la imagen. Y no importa dónde aparezca el perro en la imagen. La plantilla coincidirá con ella. Cada subsección de red no debe convertirse en un clasificador de perro separado ".
Otro factor clave de éxito para AlexNet ha sido el uso de tarjetas gráficas para acelerar el proceso de aprendizaje. Las tarjetas gráficas tienen un poder de procesamiento paralelo, muy adecuado para la informática repetitiva necesaria para entrenar una red neuronal. Al transferir la carga de la informática a un par de GPU, la Nvidia GTX 580, con 3 GB de memoria cada una, los investigadores pudieron desarrollar y entrenar una red extremadamente grande y compleja. AlexNet tenía ocho capas entrenables, 650,000 neuronas y 60 millones de parámetros.
Finalmente, el éxito de AlexNet también fue asegurado por el gran tamaño de la base de datos de imágenes de capacitación de ImageNet: un millón de piezas. Se necesitan muchas imágenes para ajustar 60 millones de parámetros. Para lograr una victoria decisiva, AlexNet fue ayudado por una combinación de una red compleja y un gran conjunto de datos.
Me pregunto por qué tal avance no ocurrió antes:
- El par de GPU de grado de consumo utilizado por los investigadores de AlexNet estaba lejos de ser el dispositivo informático más poderoso para 2012. Cinco e incluso diez años antes de eso, había computadoras más potentes. Además, la tecnología para acelerar el aprendizaje de NS mediante tarjetas gráficas se conoce desde al menos 2004.
- La base de un millón de imágenes era inusualmente grande para enseñar algoritmos de MO en 2012, sin embargo, recopilar dichos datos no era una tecnología nueva para ese año. Un equipo de investigación bien financiado podría reunir fácilmente una base de datos de este tamaño cinco o diez años antes.
- Los algoritmos principales utilizados en AlexNet no eran nuevos. El algoritmo de retropropagación para 2012 ya existía durante aproximadamente un cuarto de siglo. Las ideas clave relacionadas con las redes neuronales convolucionales se desarrollaron en los años ochenta y noventa.
Por lo tanto, cada uno de los elementos de éxito de AlexNet existía por separado mucho antes de que ocurriera el avance. Obviamente, a nadie se le ocurrió combinarlos, en su mayor parte porque nadie sabía cuán poderosa sería esta combinación.
El aumento de la profundidad del NS prácticamente no mejoró la eficiencia de su trabajo si no usaban conjuntos de datos de entrenamiento lo suficientemente grandes. Y expandir el conjunto de datos no mejoró el rendimiento de las redes pequeñas. Para ver el aumento de la eficiencia, necesitábamos redes más profundas y conjuntos de datos más grandes, además de una potencia informática considerable que nos permitiera llevar a cabo el proceso de capacitación en un período de tiempo razonable. El equipo de AlexNet fue el primero en reunir los tres elementos en un solo programa.
El boom del aprendizaje profundo

Muchas personas notaron la demostración de todo el poder del NS profundo, proporcionado por una cantidad suficiente de datos de capacitación, tanto entre científicos, investigadores como entre representantes de la industria.
El primer concurso de ImageNet para cambiar. Hasta 2012, la mayoría de los concursantes usaban tecnologías distintas al aprendizaje profundo. En la competencia de 2013, como escribieron los patrocinadores, "la mayoría" de los concursantes usaron GO.
El porcentaje de errores entre los ganadores disminuyó gradualmente, de un impresionante 16% en AlexNet en 2012 a 2.3% en 2017:
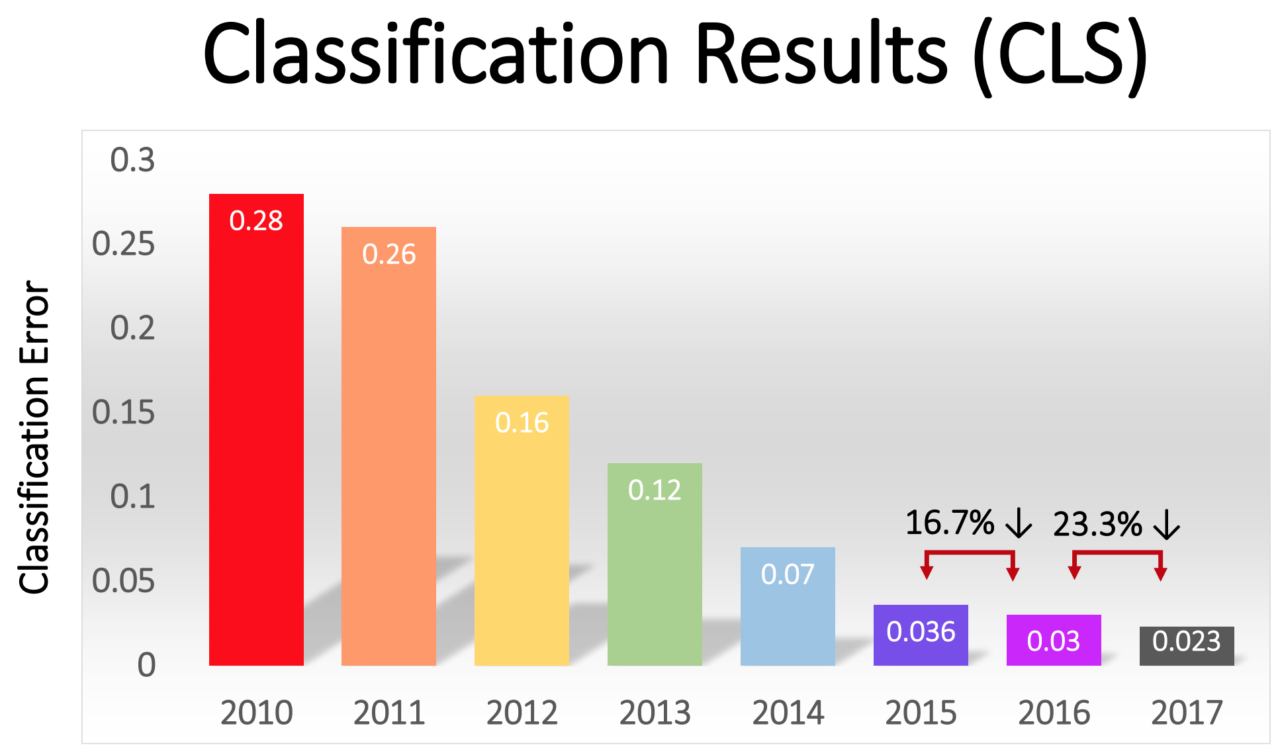
La revolución GO se extendió rápidamente por toda la industria. En 2013, Google adquirió una startup formada por los autores de AlexNet y utilizó su tecnología como base para la función de búsqueda de imágenes en Google Photos. Para 2014, Facebook promocionaba su propio software que reconoce imágenes usando GO. Apple ha estado utilizando GO para el reconocimiento facial en iOS desde al menos 2016.
GO también subyace a la reciente mejora en la tecnología de reconocimiento de voz. Siri de Apple, Alexa de Amazon, Cortana de Microsoft y el asistente de Google usan GO, ya sea para comprender las palabras de una persona, o para generar una voz más natural, o ambas.
En los últimos años, ha surgido una tendencia autosostenida en la industria, en la que el aumento de la potencia informática, el volumen de datos y la profundidad de la red se apoyan mutuamente. El equipo de AlexNet usó la GPU porque ofrecían computación paralela a un precio razonable. Pero en los últimos años, cada vez más empresas han comenzado a desarrollar sus propios chips, diseñados específicamente para su uso en el campo de MO.
Google anunció el lanzamiento del chip Tensor Processing Unit específicamente diseñado para el NS en 2016. En el mismo año, Nvidia anunció el lanzamiento de una nueva GPU llamada Tesla P100, optimizada para el NS. Intel respondió a la llamada con su chip AI en 2017. En 2018, Amazon anunció el lanzamiento de su propio chip AI, que puede usarse como parte de los servicios en la nube de la compañía. Incluso se dice que Microsoft está trabajando en su chip AI.
Los fabricantes de teléfonos inteligentes también están trabajando en chips que permitirán que los dispositivos móviles realicen más cómputo utilizando NS localmente, sin tener que cargar datos a los servidores. Tal computación en dispositivos reduce la latencia y mejora la privacidad.
Incluso Tesla entró en este juego con fichas especiales. Este año, Tesla mostró una nueva y poderosa computadora, optimizada para calcular NS. Tesla lo nombró Full Self-Driving Computer y lo presentó como un momento clave en la estrategia de la compañía para convertir la flota de Tesla en vehículos robóticos.
La disponibilidad de capacidades informáticas optimizadas para IA ha generado una solicitud de los datos necesarios para entrenar NS cada vez más complejas. Esta dinámica es más evidente en el sector robomóvil, donde las empresas recopilan datos sobre millones de kilómetros de carreteras reales. Tesla puede recopilar estos datos automáticamente de los automóviles de los usuarios, y sus competidores, Waymo y Cruise, pagaron a los conductores que conducían sus automóviles en vías públicas.

La solicitud de datos ofrece una ventaja a las grandes compañías en línea que ya tienen acceso a grandes volúmenes de datos de usuarios.
El aprendizaje profundo ha conquistado tantas áreas diferentes debido a su extrema flexibilidad. Las décadas de prueba y error han permitido a los investigadores desarrollar los bloques de construcción básicos para las tareas más comunes en el campo de MO, como las redes de convolución para el reconocimiento eficiente de imágenes. Sin embargo, si tiene una red de alto nivel adecuada para el esquema y suficientes datos, entonces el proceso de capacitación será simple. Los NS profundos pueden reconocer una gama excepcionalmente amplia de patrones complejos sin la guía especial de los desarrolladores humanos.
Hay limitaciones, por supuesto. Por ejemplo, algunas personas se entregaron a la idea de entrenar robomóviles con la ayuda de solo GO, es decir, alimentar imágenes recibidas de una cámara, una red neuronal y recibir instrucciones de ella para girar el volante y el pedal. Soy escéptico de este enfoque.
La Asamblea Nacional aún no ha demostrado la capacidad de llevar a cabo un razonamiento lógico complejo, que se requiere para comprender ciertas condiciones que surgen en el camino. Además, los NS son "cajas negras", cuyo flujo de trabajo es prácticamente invisible. Sería difícil evaluar y confirmar la seguridad de dicho sistema.Sin embargo, GO permitió dar saltos muy amplios en una gama inesperadamente grande de aplicaciones. En los próximos años, uno puede esperar el próximo progreso en esta área.