Hola a todos A continuación se muestra una transcripción del informe con Big Monitoring Meetup 4 .
Prometheus es un sistema de monitoreo para varios sistemas y servicios, con el cual los administradores del sistema pueden recopilar información sobre los parámetros actuales de los sistemas y configurar alertas para recibir notificaciones de desviaciones en la operación de los sistemas.
El informe comparará Thanos y VictoriaMetrics , proyectos para el almacenamiento a largo plazo de métricas Prometheus.


Primero, hablaré sobre Prometeo. Este es un sistema de monitoreo que recopila métricas de objetivos dados y las guarda en el almacenamiento local. Prometheus puede escribir métricas en un repositorio remoto, puede generar alertas y reglas de grabación.

Limitaciones de Prometeo:
- No tiene una vista de consulta global. Esto es cuando tienes varias instancias independientes de prometeo. Recopilan métricas. Y desea realizar una solicitud además de todas estas métricas recopiladas de diferentes instancias de prometheus. Prometeo no permite esto.
- Con prometheus, el rendimiento se limita a un solo servidor. Prometheus no puede escalar automáticamente a varios servidores. Solo puede dividir manualmente sus objetivos entre múltiples Prometheus.
- El volumen de métricas en Prometheus se limita a un solo servidor por la misma razón por la que no puede escalar automáticamente a varios servidores.
- En Prometheus, no es tan fácil organizar la seguridad de los datos.

¿Resolviendo estos problemas / desafíos?
Las soluciones son:
Todas estas soluciones de almacenamiento remoto recopiladas por Prometheus. Resuelven el problema de almacenamiento remoto de la diapositiva anterior de diferentes maneras. En esta presentación, solo hablaré sobre las dos primeras soluciones: Thanos y VictoriaMetrics .
Por primera vez, la información sobre Thanos apareció en este enlace . Describe la arquitectura de Thanos y cómo funciona.

Thanos toma los datos que Prometheus guardó en el disco local y los copia en S3, en GCS o en otro almacenamiento de objetos.

De esta manera, Thanos proporciona una vista de consulta global. Puede solicitar datos almacenados en el almacenamiento de objetos desde múltiples instancias de Prometheus.

Thanos admite PromQL y la API de consulta Prometheus .

Thanos usa el código de Prometheus para almacenar datos.

Thanos está siendo desarrollado por los mismos desarrolladores que Prometheus.
Sobre VictoriaMetrics . Aquí está el enlace donde hablamos por primera vez sobre VictoriaMetrics .

VictoriaMetrics recibe datos de varios prometeos a través del protocolo API de escritura remota compatible con Prometheus.
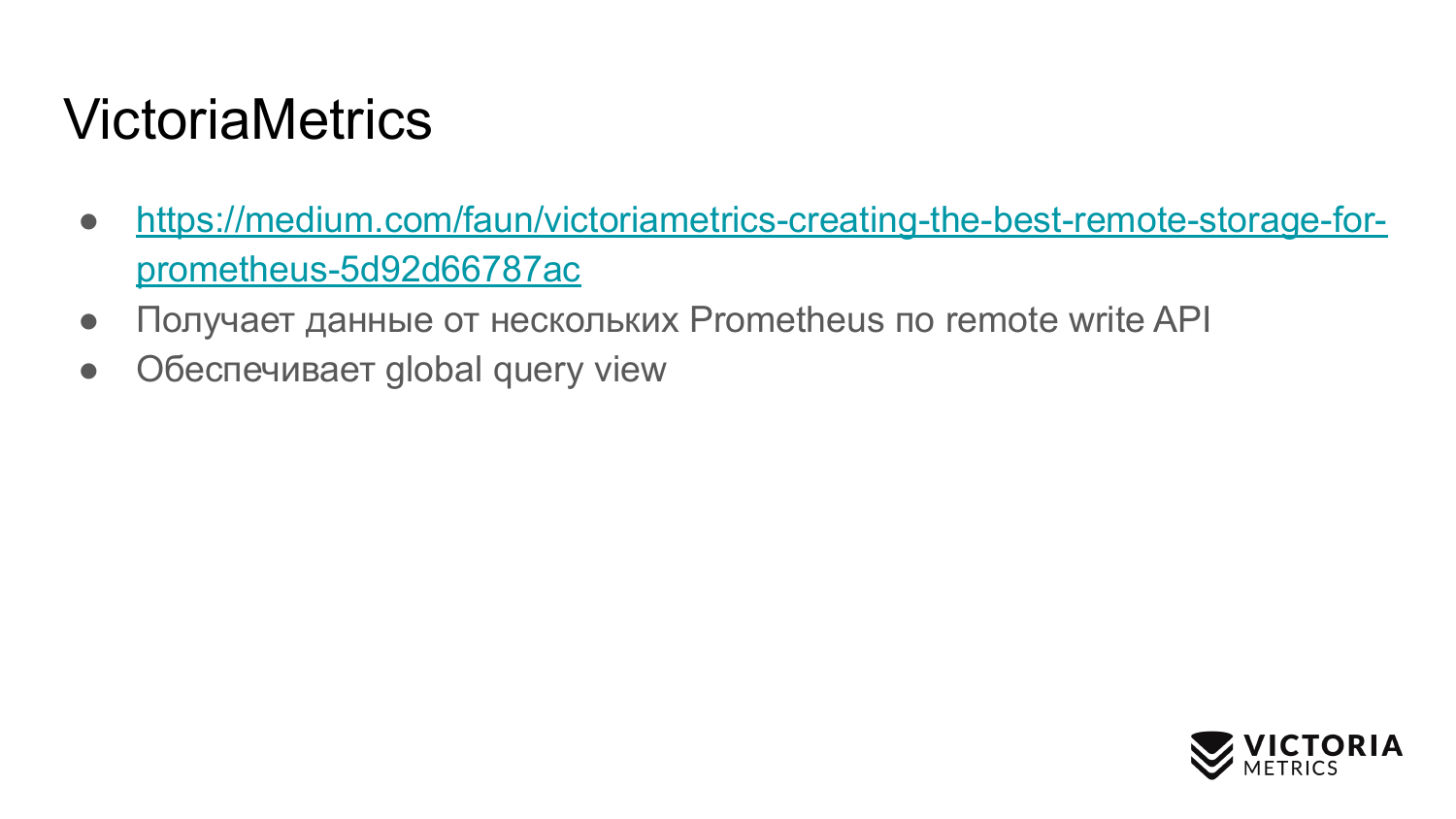
VictoriaMetrics proporciona una vista de consulta global, ya que varias instancias de Prometheus pueden escribir datos en una VictoriaMetrics. En consecuencia, puede realizar solicitudes para todos estos datos.

VictoriaMetrics también es compatible, como Thanos, PromQL y la API de consulta Prometheus.

A diferencia de Thanos, el código fuente de VictoriaMetrics está escrito desde cero y optimizado para la velocidad y los recursos.

VictoriaMetrics, a diferencia de Thanos, se escala tanto vertical como horizontalmente. Hay una versión de nodo único que se escala verticalmente. Puede comenzar con un procesador y 1 GB de memoria y crecer gradualmente hasta cientos de procesadores y 1 TB de memoria. VictoriaMetrics puede usar todos estos recursos. Su rendimiento aumentará aproximadamente 100 veces en comparación con un sistema de un solo núcleo.

La historia de Thanos comenzó en noviembre de 2017, cuando apareció el primer compromiso público. Antes de esto, Thanos fue desarrollado internamente por improbable.io .

En junio de 2019, hubo una versión histórica 0.5.0, en la que se eliminó el protocolo de chismes . Fue retirado de Thanos porque no hizo lo mejor que pudo. A menudo, el clúster de Thanos no funcionaba correctamente, los nodos se conectaban incorrectamente debido al protocolo de chismes. Por lo tanto, decidieron eliminarlo de allí. Creo que esta es la decisión correcta.

También en junio de 2019, enviaron la solicitud número 256 a la Cloud Native Computing Foundation .

Y después de un par de meses, Thanos se unió a la Cloud Native Computing Foundation , que incluye a Prometheus, Kubernetes y otros proyectos populares.

En enero de 2018, comenzó el desarrollo de VictoriaMetrics.

En septiembre de 2018, primero mencioné públicamente VictoriaMetrics.

En diciembre de 2018, se publicó la versión de nodo único.

En mayo de 2019 , se publicaron las fuentes de las versiones Single-node y cluster.

En junio de 2019, al igual que Thanos, aplicamos a la fundación CNCF en el número 255 . Solicitamos un día antes de que Thanos aplicara.

Pero, desafortunadamente, todavía no hemos sido aceptados allí. Necesito ayuda de la comunidad.

Considere las diapositivas más importantes que muestran la arquitectura de Thanos y VictoriaMetrics.

Comencemos con Thanos. Los componentes amarillos son componentes de Prometeo. Todo lo demás son los componentes de Thanos. Comencemos con el componente más importante. Thanos Sidecar es un componente que se instala junto a cada Prometheus. Está comprometido a cargar datos de Prometheus del almacenamiento local en S3 o en otro Object Storage.
También existe un componente como Thanos Store Gateway, que puede leer estos datos desde Object Storage a las solicitudes entrantes de Thanos Query. Thanos Query implementa PromQL y la API Prometheus. Es decir, desde afuera parece un Prometeo. Acepta consultas de PromQL, las envía a Thanos Store Gateway, Thanos Store Gateway recupera los datos necesarios del Object Storage y los devuelve.
Pero hemos almacenado datos en Object Storage sin las últimas dos horas debido a la peculiaridad de la implementación de Thanos Sidecar, que no puede cargar las últimas dos horas en Object Storage S3, porque durante estas dos horas Prometheus aún no ha creado archivos en el almacenamiento local.
¿Cómo decidieron evitar esto? Thanos Query, además de las solicitudes de Thanos Store Gateway, envía solicitudes paralelas a cada Thanos Sidecar ubicado junto a Prometheus.
Y Thanos Sidecar, a su vez, representa solicitudes adicionales en Prometheus y obtiene datos de las últimas dos horas.
Además de estos componentes, también hay un componente opcional sin el cual Thanos no se sentirá bien. Este es Thanos Compact, que combina archivos pequeños en Object Storage en archivos más grandes que Thanos Sidecar ha subido aquí. Thanos Sidecar carga archivos de datos allí en dos horas. Estos archivos, si no los fusiona en archivos más grandes, entonces su número puede crecer significativamente. Cuantos más archivos de este tipo, más memoria se necesita para Thanos Store Gateway, más recursos se necesitan para transferir datos a través de la red, metadatos. Thanos Store Gateway se está volviendo ineficiente. Por lo tanto, definitivamente debe ejecutar Thanos Compact, que combina archivos pequeños en archivos más grandes para que haya menos archivos y reducir la sobrecarga en Thanos Store Gateway.
También existe un componente como Thanos Ruler. Sigue las reglas de alerta de Prometheus y puede calcular las reglas de grabación de Prometheus para volver a escribir datos en Object Storage. Pero este componente no es recomendable, porque él está inclinado a devolver datos incompletos .
Este es un esquema simple para Thanos.
Ahora compare con el esquema VictoriaMetrics.
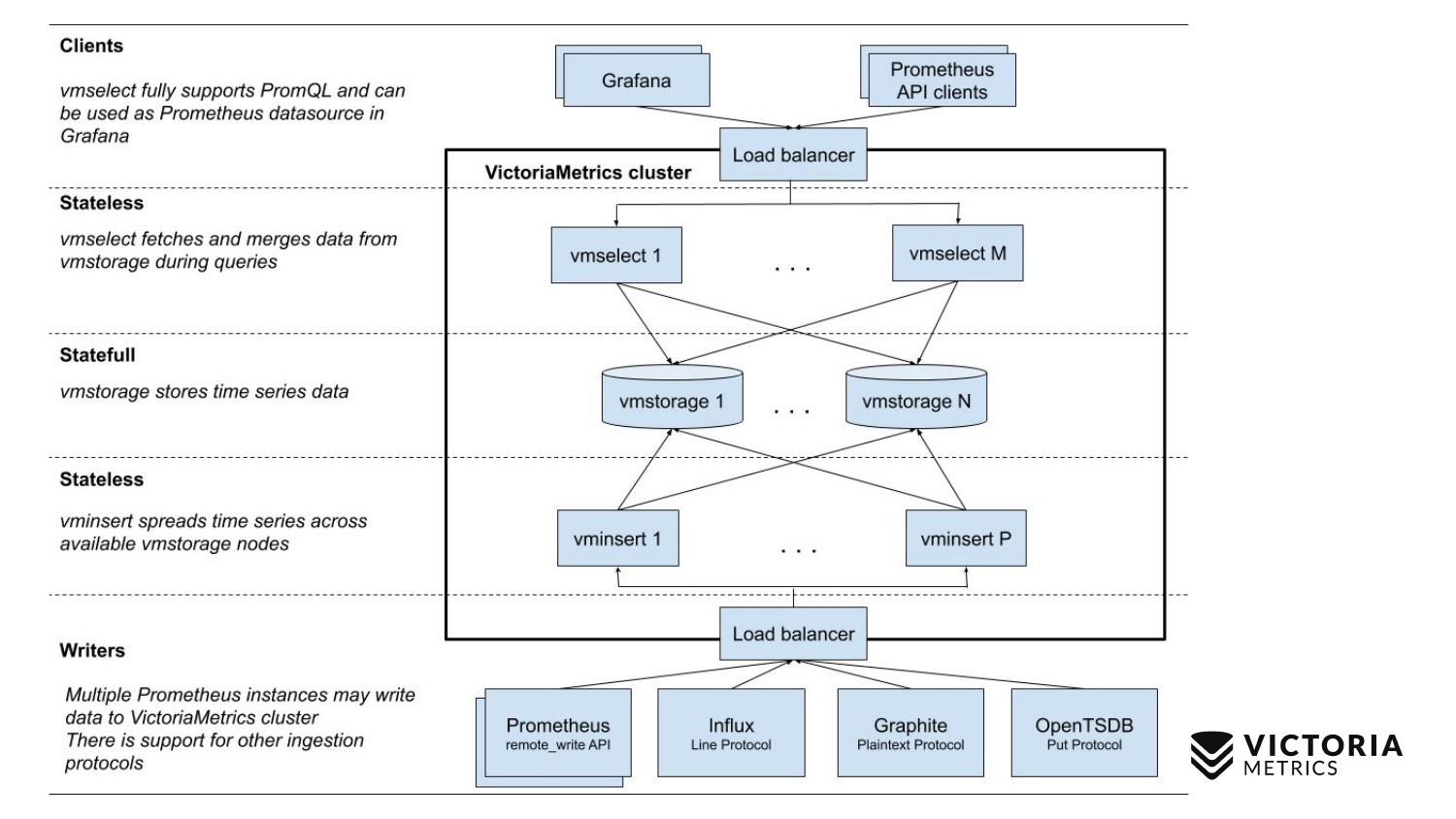
VictoriaMetrics tiene 2 versiones: versión de nodo único y de clúster. El nodo único se ejecuta en una sola computadora. El nodo único no tiene estos componentes, solo un binario. Este binario en la diapositiva se parece a este cuadrado. Todo lo que está dentro del cuadrado es el contenido del archivo binario para la versión de nodo único. No necesitas saber sobre él. Simplemente inicie el binario, y todo funciona para nosotros.
La versión del clúster es más complicada. En su interior hay tres componentes diferentes: vmselect, vminsert y vmstorage. Por su nombre, debe quedar claro lo que cada uno de ellos hace. El componente Insert acepta datos en diferentes formatos: desde la API de escritura remota Prometheus, el protocolo de línea Influx, el protocolo Graphite y el protocolo OpenTSDB. El componente Insertar los acepta, los analiza y los distribuye entre los componentes de almacenamiento existentes, donde los datos ya están almacenados. El componente Seleccionar, a su vez, acepta consultas PromQL. Implementa PromQL , así como la API de consulta de Prometheus, y puede usarse como un reemplazo para Prometheus en Grafana u otros clientes de la API de Prometheus. Select acepta una solicitud promql, la analiza, lee los datos necesarios para ejecutar esta solicitud desde el nodo de almacenamiento, procesa estos datos y devuelve una respuesta.

Compare la dificultad de instalar Thanos y VictoriaMetrics.

Comencemos con Thanos. Antes de comenzar a trabajar con Thanos, debe crear un depósito en Object Storage, como S3 o GCS, para que Thanos Sidecar pueda escribir datos allí.

Luego, para cada Prometheus necesita instalar Thanos Sidecar. Antes de eso, debe recordar deshabilitar la compactación de datos en Prometheus. La compactación de datos comprime periódicamente los datos en el almacenamiento local de Prometheus para reducir el consumo de recursos.
Cuando instala Thanos Sidecar en su Prometheus, debe desactivar esta compactación de datos, porque Thanos Sidecar no puede funcionar normalmente cuando la compactación de datos está activada. Esto significa que su Prometheus comienza a guardar datos en bloques de dos horas y deja de fusionar estos bloques en bloques más grandes. En consecuencia, si realiza solicitudes que son más largas que las últimas dos horas, no funcionarán tan eficientemente como podrían si se habilitara la compactación de datos.

Por lo tanto, Thanos recomienda reducir el tiempo de retención de datos en el almacenamiento local a 6-8 horas para reducir esta sobrecarga de una gran cantidad de pequeños bloques.
Después de instalar Thanos Sidecar, debe instalar dos componentes para cada Depósito de almacenamiento de objetos. Estos son Thanos Compactor y Thanos Store Gateway.

Después de eso, debe instalar Thanos Query y configurarlo para que sepa cómo conectarse a todos los Thanos Store Gateway que tiene, y también sabe cómo conectarse a todos los Thanos Sidecar.
Puede haber un pequeño problema.

Debe configurar una conexión confiable y segura de Thanos Query a estos componentes. Y si su Prometheus está ubicado en diferentes centros de datos, o en diferentes VPC, entonces están prohibidas las conexiones externas a ellos. Pero para que Thanos Query funcione, debe configurar de alguna manera la conexión allí, y tiene que encontrar una manera.
Si tiene muchos de estos centros de datos, entonces, en consecuencia, la confiabilidad de todo el sistema disminuye. Dado que Thanos Query debe mantenerse constantemente conectado a todos los Sidecar de Thanos ubicados en diferentes centros de datos. Con cada solicitud entrante, enviará solicitudes a todos los Sidecar de Thanos. Si se interrumpe la conexión, recibirá un conjunto de datos incompleto u obtendrá la respuesta "el clúster no funciona".

En VictoriaMetrics, las cosas son un poco más fáciles. Para la versión de nodo único, es suficiente con ejecutar un binario y todo funciona.

En una versión en clúster, es suficiente ejecutar todos los tres tipos de componentes anteriores en cualquier cantidad que necesite, o usar el gráfico de timón para automatizar el lanzamiento de componentes en Kubernetes. Todavía estamos planeando hacer un operador de Kubernetes. El gráfico de timón no cubre algunos casos y le permite dispararle a la pierna. Por ejemplo, le permite reducir la cantidad de nodos de almacenamiento, lo que conducirá a la pérdida de datos.

Después de haber lanzado una versión binaria o de clúster, solo necesita agregar la configuración para la URL de escritura remota a la configuración de Prometheus para que comience a escribir datos en paralelo al almacenamiento local y al almacenamiento remoto. Como notó, esta configuración debería funcionar de manera mucho más confiable en comparación con la configuración de Thanos. No necesitamos mantener VictoriaMetrics conectado a todos los Prometheus, porque los Prometheus se conectan a VictoriaMetrics y transmiten los datos.

Considere las escoltas de Thanos y VictoriaMetrics.

Thanos necesita vigilar Sidecar para que no deje de cargar datos en Object Storage. Pueden detener esta carga de datos debido a errores de carga, por ejemplo, su conexión de red con Object Storage se desconecta temporalmente o Object Storage no está disponible temporalmente. Thanos Sidecar en este momento lo notará, informará un error, puede caerse y luego dejar de funcionar. Si no lo controla, sus datos ya no se transferirán al Almacenamiento de objetos. Si el tiempo de retención pasa (se recomiendan 6-8 horas), perderá los datos que no cayeron en el Almacenamiento de objetos.

Los compactadores Thanos pueden dejar de funcionar debido a la carrera con Sidecar . Los compactadores toman datos del Almacenamiento de objetos y los fusionan en grandes cantidades de datos. Dado que los compactadores no están sincronizados con el Sidecar, esto puede suceder: Sidecar aún no ha terminado de escribir el bloque, Compactor decide que este bloque está completamente grabado. Compactor comienza a leerlo. No lee el bloque en su totalidad y deja de funcionar. Ver detalles aquí .

Store Gateway puede proporcionar datos inconsistentes debido a la carrera entre Compactor y Sidecar. Esto es lo mismo, porque Store Gateway no está de ninguna manera sincronizado con Compactor y Sidecar. En consecuencia, puede ocurrir una condición de carrera cuando Store Gateway no ve parte de los datos o ve un exceso de datos.

El componente de consulta en Thanos se predetermina a resultados parciales si algún Sidecar o Gateway de tienda no están disponibles actualmente. Recibirá una parte de los datos y ni siquiera sabrá que no se recibieron todos los datos. Que funciona así por defecto. En una situación similar, VictoriaMetrics devuelve los datos marcados como parciales.

A diferencia de Thanos, VictoriaMetrics rara vez pierde datos. Incluso si se interrumpe la conexión de Prometheus a VictoriaMetrics, esto no es un problema, ya que Prometheus continúa registrando datos nuevos entrantes en Write Ahead Log, que tiene un tamaño de 2 horas. Si se vuelve a conectar a VictoriaMetrics en dos horas, los datos no se perderán. Prometheus puede agregar datos después de volver a conectarse a VictoriaMetrics .

A diferencia de Thanos, que solo escribe datos en el almacenamiento de objetos después de dos horas, Prometheus replica automáticamente los datos a través del protocolo de escritura remota en el almacenamiento remoto, como VictoriaMetrics. No tiene miedo de perder el almacenamiento local en Prometheus. Si de repente perdió el almacenamiento local, en el peor de los casos perderá los últimos segundos de datos que no tuvieron tiempo de escribir en el almacenamiento remoto.

Kubernetes gestiona automáticamente el clúster, a diferencia de Thanos. Todos los componentes de Thanos son difíciles de colocar en un solo clúster de Kubernetes, a diferencia de los componentes del clúster VictoriaMetrics.

VictoriaMetrics tiene una actualización muy simple a la nueva versión. Simplemente detenga VictoriaMetrics, actualice los binarios y ejecute. Al detenerse a través de una señal SIGINT, todos los binarios de VictoriaMetrics se apagan con gracia. Guardan correctamente los datos necesarios, cierran correctamente las conexiones entrantes para no perder nada. Por lo tanto, no perderá nada al actualizar.

VictoriaMetrics tiene una forma muy simple de expandir un clúster. Simplemente agregue los componentes necesarios y continúe trabajando.

Sobre las trampas en Thanos y Victoria Metrics.

Thanos tiene las siguientes trampas. Prometheus debería almacenar datos de las últimas dos horas. Si se pierden, los perderá por completo, ya que aún no han logrado registrarse en Object Storage, como S3.

El componente Store Gateway y el componente compactador pueden requerir mucha memoria para funcionar con el almacenamiento de objetos grandes si se almacenan allí muchos archivos pequeños. Cuanto mayor sea el número y el volumen de archivos, se necesitará más Store Gateway y memoria del compactador para almacenar la metainformación. Thanos tiene muchos problemas sobre Store Gateway y la caída del compactador con datos grabados promedio .

Se afirma que Thanos puede escalar indefinidamente por la cantidad de su Prometeo. Esto en realidad no es cierto. Como todas las solicitudes pasan por el componente Consulta, que debe sondear simultáneamente todos los componentes de Store Gateway y todos los componentes de Sidecar, extraiga los datos de allí y luego preprocese. Obviamente, la velocidad de consulta está limitada por el enlace débil más lento, el Gateway de tienda más lento o el Sidecar más lento.
Estos componentes pueden estar cargados de manera desigual. Por ejemplo, tiene un Prometheus que recopila millones de métricas por segundo. Y está Prometheus, que recopila miles de métricas por segundo. Prometheus, que recopila millones de métricas por segundo, carga el servidor en el que se ejecuta mucho más. En consecuencia, Sidecar es más lento allí. En general, todo funciona lentamente allí. Y el componente Consulta extraerá datos muy lentamente desde allí. En consecuencia, el rendimiento de todo su clúster estará limitado por este Sidecar lento.

De forma predeterminada, Thanos devuelve datos parciales si algunos Sidecar y Store Gateway no están disponibles. Por ejemplo, si tiene un Sidecar disperso por todo el mundo en diferentes centros de datos, entonces la probabilidad de una desconexión y la falta de disponibilidad de componentes aumenta enormemente. En consecuencia, en la mayoría de los casos, recibirá datos parciales sin siquiera saberlo.

VictoriaMetrics también tiene dificultades. El primer escollo es una opción que limita la cantidad de RAM utilizada para el caché VictoriaMetrics. Por defecto, es igual al 60% de la RAM en la máquina donde se ejecuta VictoriaMetrics, o el 60% de la RAM de pod VictoriaMetrics en Kubernetes.
Si cambia incorrectamente este valor, puede arruinar el rendimiento de VictoriaMetrics. Por ejemplo, si establece el valor demasiado bajo, es posible que los datos ya no quepan en el caché VictoriaMetrics. Debido a esto, tendrá que hacer un trabajo extra y cargar el procesador con el disco. Si hace que esta opción sea demasiado grande, aumenta, en primer lugar, la probabilidad de que VictoriaMetrics se bloquee con un error de falta de memoria y, en segundo lugar, esto llevará a que quede muy poca memoria operativa en el sistema operativo memoria para el caché de archivos. Y VictoriaMetrics se basa en un caché de archivos para el rendimiento. Si no es suficiente, la carga en el disco puede aumentar considerablemente. Por lo tanto, un consejo: no cambie el parámetro a menos que sea absolutamente necesario.
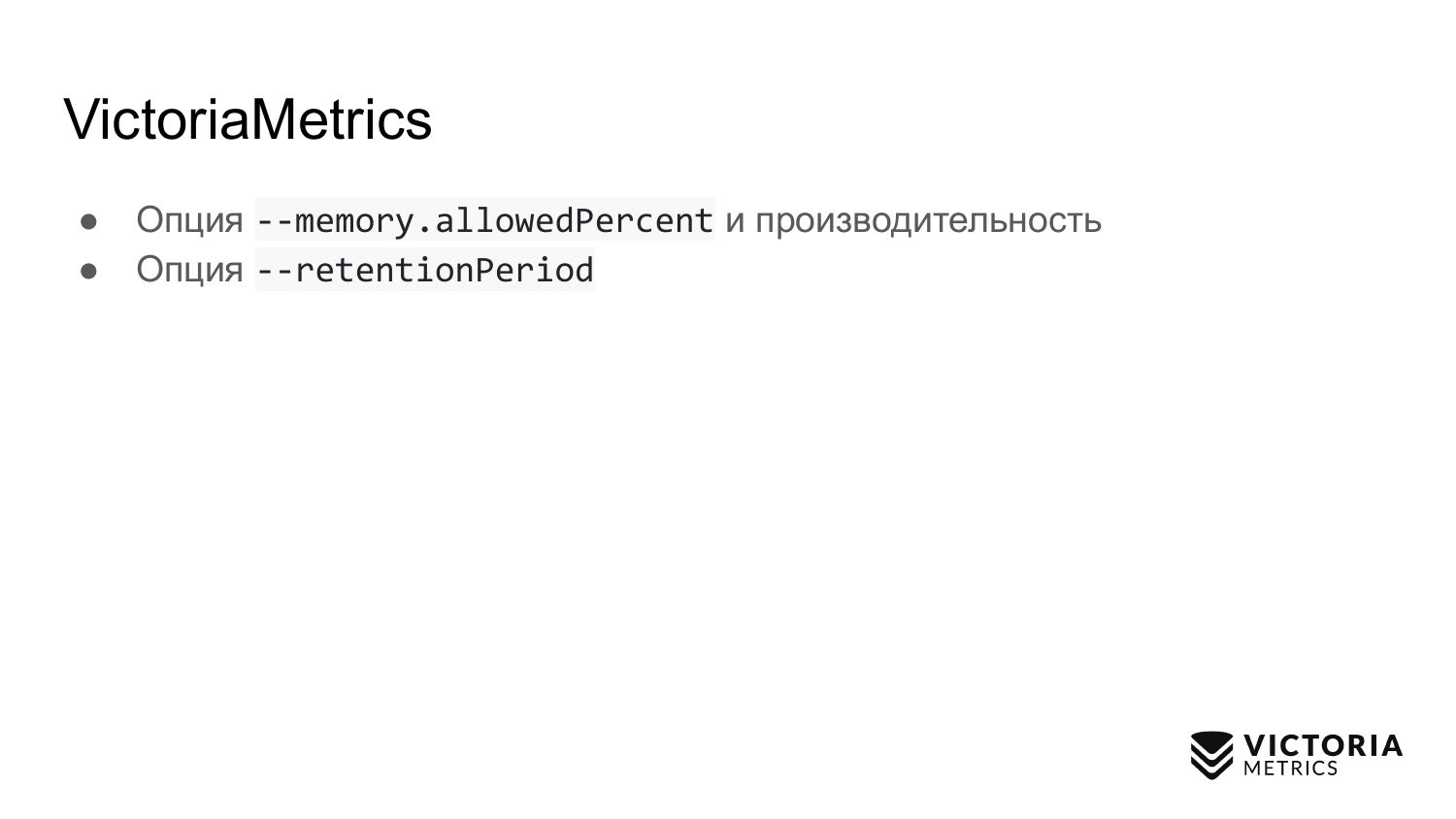
La segunda opción. Este es el período de retención: el período establecido de forma predeterminada en 1 mes. Este es el momento en que VictoriaMetrics almacena datos. Después de este período, VictoriaMetrics elimina los datos.
Muchos ejecutan VictoriaMetrics sin este parámetro, registran datos durante un mes. Y luego preguntan: ¿por qué desaparecieron los datos del mes anterior? Porque el Período de retención es de 1 mes por defecto. Por lo tanto, debe conocer y establecer el período de retención correcto.

Pasemos por oportunidades únicas.

Thanos tiene una función como el muestreo descendente: intervalos de 5 minutos y horas, que a menudo no funcionan correctamente . Si lo buscas en Google y miras su problema en Github, hay muchos problemas relacionados con este muestreo, que a veces no funciona correctamente o no funciona como los usuarios esperan.

Thanos tiene deduplicación de datos para pares Prometheus HA. Cuando dos Prometheus'a recopilan las mismas métricas del mismo objetivo 'y Thanos las coloca en Almacenamiento de objetos. Thanos , VictoriaMetrics.

Thanos alert , Thanos. production .

Thanos , Thanos Prometheus — . Thanos Prometheus . Thanos Prometheus .

VictoriaMetrics — MetricsQL. VictoriaMetrics PromQL, big monitoring metup.

VictoriaMetrics . VictoriaMetrics Prometheus, Influx, OpenTSDB Graphite.

VictoriaMetrics Thanos Prometheus.
, 2-5 Prometheus Thanos.

VictoriaMetrics — .

.

Thanos , object storage, .
object storage, ($10 ). object storage, , AWS — . , $10 $230 1. , Thanos .

Thanos Compact, Store Gateway, Query , , .

VictoriaMetrics . GCE HDD , $40 1. VictoriaMetrics HDD , SSD, . VictoriaMetrics HDD.

VictoriaMetrics necesita servidores para componentes: ya sea Single-nod o para componentes de clúster, que, a diferencia de los componentes de Thanos, requieren mucha menos CPU, RAM, será más barato en consecuencia.

Ejemplos de implementación.

El ejemplo de implementación de Thanos es Gitlab. Gitlab es totalmente alimentado por Thanos. Pero no es tan suave. Si observa sus problemas , puede ver que constantemente tienen algún tipo de problemas operativos con Thanos : no hay suficiente memoria para los componentes de Store Gateway o Query. Constantemente tienen que aumentar la cantidad de memoria.
Debido a esto, los costos de resolver estos problemas aumentan.
La segunda implementación, que puede ser más exitosa, es la compañía Improbable, que comenzó el desarrollo de Thanos. Publicaron la fuente de Thanos. Improbable es una empresa que desarrolla motores de juego.

Los ejemplos públicos de implementación de VictoriaMetrics son:
- creador de sitios wix.com
- Adidas presenta VictoriaMetrics e incluso realizó una presentación en la última PromCon 2019
- TrafficStars - red publicitaria
- Seznam.cz es un popular motor de búsqueda checo.
Y luego fui al nombre de la compañía, que no puedo nombrar ahora. No estuvieron de acuerdo.
- Uno de los principales desarrolladores de juegos. Más grande que ellos Improbable.
- Un importante desarrollador de software gráfico.
- Gran banco ruso.
- Fabricante europeo de turbinas eólicas que ha probado con éxito VictoriaMetrics. Este fabricante implementa VictoriaMetrics para monitorear los datos de las turbinas eólicas a una velocidad de 50 muestras por segundo por sensor. Cada turbina eólica tiene varios cientos de sensores. Tienen varios cientos de aerogeneradores.
- Aerolíneas rusas que quieren presentar VictoriaMetrics, pero aún no pueden. Estamos en la etapa de contrato con ellos.
 Conclusiones
Conclusiones
VictoriaMetrics y Thanos resuelven problemas similares, pero de diferentes maneras:
- Vista de consulta global
- escala horizontal
- retención arbitraria

Gracias
Te esperamos en nuestro canal de telegramas .
