El 14 de marzo de 2017, Arthur Khachuyan, CEO de Social Data Hub, habló en la sala de conferencias BBDO. Arthur habló sobre el monitoreo inteligente, la construcción de modelos de comportamiento, el reconocimiento de contenido de fotos y videos, así como otras herramientas y estudios del Social Data Hub, que le permiten dirigirse a su audiencia utilizando las redes sociales y las tecnologías de Big Data.
 Arthur Khachuyan (en adelante - AH):
Arthur Khachuyan (en adelante - AH): - ¡Hola! Hola a todos! Mi nombre es Arthur Khachuyan, lidero la empresa Social Data Hub, y estamos involucrados en varios análisis intelectuales interesantes de fuentes de datos abiertas, campos de información y hacemos todo tipo de estudios interesantes, etc.
Y hoy, colegas del Grupo BBDO pidieron hablar sobre tecnologías modernas para analizar grandes datos, grandes y no tantos datos para publicidad: cómo se usa, muestran algunos ejemplos interesantes. Espero que hagas preguntas en el camino, porque puedo comenzar a molestar y no revelar la esencia, etc., así que no seas tímido.
En realidad, las áreas principales, en algún lugar en el que alguna vez se aplicó algún tipo de soluciones de "casi grandes dígitos", son claras: esto es la focalización de la audiencia, el análisis, algún tipo de análisis e investigación de mercado. Pero siempre es interesante qué datos adicionales se pueden encontrar, qué significados adicionales se pueden encontrar después de aplicar el análisis.
¿Por qué necesitamos tecnología para publicidad?
Por donde empezamos Lo más comprensible es la publicidad en las redes sociales. Hoy lo filmé por la mañana: por alguna razón, Vkontakte cree que debería ver este anuncio en particular ... Para bien o para mal, esta es la segunda pregunta. Vemos que estoy en la categoría de reclutas con seguridad:

Lo primero e interesante que se puede tomar como una solución tecnológica ... Lo primero que quería resolver antes de comenzar era definir los términos: ¿qué son los datos abiertos y qué son los grandes datos? Porque todas las personas tienen su propio entendimiento sobre este tema, y no quiero imponer mis términos a nadie, pero ... Solo para que no haya discrepancias.
Personalmente, creo que los datos abiertos son todos los datos que puedo alcanzar sin ningún nombre de usuario o contraseña. Este es un perfil abierto en las redes sociales, se trata de resultados de búsqueda, son registros abiertos, etc. Big data, según tengo entendido, veo esto: si se trata de una placa de datos, son mil millones de líneas, si es algún tipo de almacenamiento de archivos, es en algún lugar petabyte de datos. El resto en mi terminología no es big data, sino algo alrededor.
Perfiles de perfiles y puntajes de alta precisión
Vamos en orden. Lo primero y más interesante que puede pensar en un análisis de fuentes de datos abiertas es la creación de perfiles y la puntuación de perfiles de alta precisión. Que es esto Esta es una historia en la que puede predecir no solo quién es usted, no solo sus intereses en su cuenta de red social.
Pero ahora, combinando varias fuentes, puede comprender el nivel promedio de su salario, cuánto es su apartamento, dónde está ubicado. Y todos estos datos pueden usarse literalmente por medios improvisados. Por ejemplo, si toma su cuenta en una red social, vea, digamos, dónde vive, dónde trabaja; comprender en qué sección del negocio se encuentra la empresa en la que trabaja; Aproveche la descarga de vacantes similares de HH y SuperJob si es analista, gerente, etc. vea dónde vive (base, digamos CIAN), comprenda cuánto cuesta alquilar una casa en este lugar, cuánto cuesta comprar una casa en este lugar, para predecir aproximadamente cuánto gana. Además, en sus redes sociales puede comprender cuánto viaja, dónde está, qué tan leal es al empleador.
En consecuencia, a partir de una cantidad tan grande de métricas, podemos hacer cualquier cosa. Podemos presentarle un producto que le interese. Imagina una tienda en línea? Usted va allí: esta tienda en línea captura su cuenta en la red social y le dice: "Masha, acabas de romper con un chico, aquí tienes ciertos, ciertos productos". Este no es el futuro cercano ...
¿Cómo determinar la geolocalización de una persona?
Respuestas a preguntas de la audiencia:- Por lo general, el 80% de todos los registros se consideran el lugar exacto de residencia. Pero para las personas que no se registran en ningún lugar, hay varias opciones: ya sea un registro, o una posición geográfica, o un análisis de publicaciones y publicaciones durante todo el período en que una persona escribió algo ... Y en algún lugar, que surja algo como "Quiero comprar una carriola cerca del Academic" o "Hace poco vi aquí graffiti feo en la pared". Es decir, casi el 80% de las personas pueden determinar su geolocalización, su lugar de trabajo y su lugar de residencia de acuerdo con los datos o metadatos que se pueden recopilar de las redes sociales.
Esto, nuevamente, es un análisis de las publicaciones. En el sentido más simple, este es un análisis de registros y geolocalizaciones en redes sociales que no eliminan metadatos jpeg (puede analizar algo en ellos). Pero para las personas restantes, generalmente son transmisiones de texto: o una persona "brilla" su ubicación cuando escribe sobre algo, o "brilla" su teléfono, en el que puede encontrar algunos de sus anuncios en Avito o su cuenta en "Auto.ru". De acuerdo con estos datos, puede combinar (por ejemplo, "Estoy vendiendo un automóvil cerca de Mayakovskaya") y asumir esto aproximadamente. - Por lo general, las personas publican esto en las redes sociales. Trabajamos solo con fuentes abiertas y aquí estamos hablando exclusivamente de fuentes abiertas. Por lo general, los anuncios se publican, es decir, el sesenta por ciento de las veces, la historia más frecuente es cuando las personas "brillan" su número de teléfono celular actual; estos son anuncios para vender algo. En algunos grupos, una persona escribe (“Vendo esto o aquello allí), o se va a algún lado.
Si! Suelen comentar, como por ejemplo: “Contéstame o envía un SMS, llámame al número. Esto sucede muy a menudo con personas que venden algo, compran en redes sociales, se comunican con alguien ... En consecuencia, con este número, puede vincular su perfil a él en el CIAN, si alguna vez publicó algo, o , de nuevo, en Avito. Estas son simplemente las fuentes principales más populares, continuarán siendo: esto es Avito, CIAN, etc. - Esto se refiere a una tienda en línea. El siguiente será la tecnología de reconocimiento facial y de coincidencia de perfiles (hablaremos de ello). Teóricamente, esto también se puede aplicar a una tienda fuera de línea. Y, en general, mi gran sueño es que cuando aparecen pancartas en la calle, cuando pasas junto a la cámara, "raya" tu cara. Pero este caso estará prohibido por ley, porque es una violación de la privacidad. Espero que tarde o temprano lo sea.
- Tengo por experiencia personal. Muy a menudo, cuando una persona te escribe algo, operas algunos hechos de su vida que no deberías saber ... La gente en la mayoría de los casos se asusta. Pero! Según estadísticas recientes, el número de cuentas cerradas en las redes sociales ha disminuido en un 14%. El número de falsificaciones está creciendo, el número de cuentas abiertas está creciendo: las personas se están moviendo cada vez más hacia la apertura. Creo que después de 3-4 años dejarán de reaccionar tan bruscamente ante el hecho de que alguien conozca información sobre ellos que potencialmente no debería saber. Pero, de hecho, es muy fácil de conseguir mirando su pared.
¿Qué se puede tomar de las fuentes abiertas?
Es una lista aproximada de cosas que pueden entenderse con bastante alta confiabilidad de fuentes abiertas. De hecho, hay aún más todo tipo de métricas diferentes; depende del cliente de dicha investigación. Hay alguna agencia de recursos humanos que está interesada en si juras en las redes sociales o en algún lugar del espacio público. Alguien está interesado en saber si le gustan los "me gusta" en las publicaciones de Navalny o, por el contrario, en las publicaciones de Rusia Unida, o algún tipo de contenido pornográfico; tales cosas suceden con bastante frecuencia.
Los principales son los valores familiares, el costo aproximado de un apartamento, casa, búsqueda de automóviles, etc. Por esta razón, las personas pueden dividirse en grupos sociales. Estos son los usuarios del "Tinder" de Moscú, quienes son (según sus imágenes encontradas en sus cuentas de Facebook); Según sus intereses, se dividen en varios grupos sociales:

Si nos acercamos a la publicidad, gradualmente hemos dejado la orientación estándar de la publicidad cuando elige en el "Vkontakte" condicional que le interesan los hombres de 18 años, suscritos a ciertos grupos. Tengo esa imagen más, ahora te mostraré:

La conclusión es que la mayoría de los servicios actuales que analizan, en principio, las personas que analizan las redes sociales, simplemente están interesados en analizar los intereses ... Lo primero que les viene a la mente es analizar los principales grupos de sus suscriptores. Quizás esto funciona con alguien, pero personalmente creo que esto es fundamentalmente incorrecto. Por qué
Tus me gusta recopilan y analizan
Ahora tome sus teléfonos, mire a sus grupos principales: seguramente habrá más del 50% de los grupos que ya ha olvidado, este es un tipo de contenido que en realidad es irrelevante para usted. No lo consume en absoluto, sin embargo, el sistema lo estirará de acuerdo con ellos: que está suscrito a recetas, a algunos grupos populares. Es decir, viola el sistema que analiza su perfil y sus intereses no estarán justificados.
Continuando ... ¿Qué hay allí? Asumimos que el resto de la gente lo está haciendo. La mayoría, en nuestra opinión, es una forma adecuada de evaluar los intereses de los usuarios. Por ejemplo, en Vkontakte no hay un feed similar, y la gente piensa que nadie sabe lo que les gusta. Sí, parte de los me gusta se introdujo en Instagram, vemos algo en Facebook, pero la mayoría del contenido en ciertos grupos no transmite esto con una transmisión común, y las personas viven y piensan que nadie sabrá lo que les gusta.
Y, después de recopilar cierto contenido de algún contenido que nos interesa, recopilar estas publicaciones, recopilar estos `` me gusta '' y luego verificar a esta persona de esta base de datos, podemos determinar con alta precisión quién es, qué destino tiene, en qué está interesado. Identificarse con precisión en un grupo social particular e interactuar con él.
Comprar un auto cambia el comportamiento
Tengo ese ejemplo. Inmediatamente haré una reserva de que tengo ejemplos de casi publicidad y casi marketing, porque, como saben, la mayoría de los casos están protegidos por la NDA, etc. Pero aún habrá muchas cosas interesantes. Entonces, la historia con estas personas: estos son hombres que compraron un automóvil entre 2010 y 2015. Cómo ha cambiado su comportamiento social en la red está codificado por colores. El porcentaje de niñas en los suscriptores ha cambiado, suscrito al público "patsansky", encontró una pareja sexual permanente ...

Todo esto se desglosa por marca de automóvil y por la cantidad de personas. Desde aquí puede sacar muchas conclusiones interesantes sobre el comportamiento de las personas, cómo funciona todo. Puedo decir que el "Porsche Cayenne" y el "Priora" plantado en términos de la cantidad de audiencias atraídas son casi iguales. La calidad de esta audiencia, su comportamiento es diferente, pero la cantidad es casi la misma. La conclusión a partir de aquí se puede hacer, más cerca de su mercado, lo que sea. Vendes Audi, haces el eslogan "¡Compra Audi," aléjate de tus padres! "Y así sucesivamente.
Esto es sí, un ejemplo ridículo del hecho de que el comportamiento de las personas basado en el análisis de me gusta, en función del grupo al que van, el contenido que analizan, hace que sea casi un 100% probable quién es usted. Porque si no tiene acceso al tráfico de la red, no lea mensajes privados, los "me gusta" siempre le dirán quién es esta persona: una mujer embarazada, una madre, un militar o un oficial de policía. Y para usted, como para una persona que puede anunciar, este es un gran éxito en el objetivo.
Respuestas a las preguntas de la audiencia:- Cada columna es el número de personas en un automóvil dado; cómo ha cambiado el patrón de su comportamiento. Mira: las personas que compraron Porsche Cayenne: alrededor de 550 personas (amarillo), el porcentaje de niñas en suscriptores ha aumentado.
- La muestra incluye usuarios de las redes sociales VKontakte, Facebook e Instagram de 2010 a 2015. La única aclaración: aquí hay máquinas seleccionadas que se pueden determinar con más del 80% de precisión en fotografías utilizando ciertas herramientas.
- Durante un cierto período de tiempo, su automóvil (bueno, es decir, no el suyo, lo dejamos para las redes sociales) ... Durante un cierto período de tiempo, una persona constantemente tomaba fotos con un automóvil, estaba con él, las publicaciones eran diferentes, las fotografías eran desde diferentes ángulos, etc. . Habrá una imagen adicional, qué personas son fotografiadas con qué máquinas y ... Sí, esta es la segunda pregunta: confiar en los datos de las redes sociales.
- Desde que lo planteamos, desafortunadamente, los datos en las redes sociales no siempre son correctos. Las personas no siempre están dispuestas a publicar su información. Personalmente, realicé dicho estudio: comparé el número de graduados de las universidades de Moscú con el número de personas registradas en las redes sociales. En promedio, un 60% más de personas están registradas en las redes sociales: los graduados de MSU por un año determinado en ciertas especialidades de lo que realmente existen en principio. Entonces sí, aquí, por supuesto, hay un porcentaje de errores, y nadie lo oculta. Aquí, los autos que se pueden determinar con más del 80% de probabilidad simplemente se toman como base.
Lista de fuentes para entrenamiento modelo
Aquí hay una lista de fuentes de muestra que se pueden utilizar, que se utilizan para determinar con gran certeza el perfil social de una persona, quién es.

De las redes sociales tomamos un perfil, de CIAN - el costo de un departamento es aproximadamente, "Head Hunter", "Super Job" - este es el salario promedio de esta persona. Espero que no haya representantes de Head Hunter aquí, porque creen que no es muy bueno tomar estos datos de ellos. Sin embargo, este es el salario promedio de ciertas regiones para ciertos tipos de actividad laboral.
Avito, Avto.ru: muy a menudo las personas, cuando encienden su teléfono, siempre tienen (en una gran cantidad de casos) al menos algo en Avito, o Avto.ru, o incluso varios sitios desde los cuales puedes entender quiénes son. Si vendió una carriola o un automóvil en este teléfono ... Rosstat y la USRLE son aún más registros con los que puede clasificar a la empresa del empleador de acuerdo con alguna fórmula, de acuerdo con un modelo que cualquier persona puede pedir (puede determinar aproximadamente el dinero de esta persona etc.)
"Tinder" ayuda a recopilar datos sobre la situación de las personas
Además, hay algo muy interesante (como opción, muy divertido en el estudio): esto, una vez más, es recopilar datos del Tinder de Moscú utilizando bots para este Tinder. Se determinó la distancia a las personas y luego se determinó su ubicación aproximada.

El objetivo de este estudio fue determinar el número de cuentas de Tinder en el territorio de las instituciones estatales, en la Duma, la oficina del fiscal, etc. Pero usted, como anunciante, puede imaginar cualquier cosa: puede ser, por ejemplo, Starbucks u otra persona ... Es decir, la cantidad de personas del mismo Tinder que beben café de usted, piden algo, están en tiendas. Respecto a esta geolocalización: esto se puede hacer con cualquier servicio.
La respuesta a una pregunta de la audiencia:- Yesca? Usted no sabe "Tinder" es una aplicación de citas en la que ves fotos (izquierda-derecha), y esta aplicación te muestra la distancia a una persona. Si obtiene la distancia a esta persona desde tres puntos diferentes, puede determinar aproximadamente (+ 5-7 metros) la ubicación. En este caso, para determinar el territorio de la fiscalía o la Duma del Estado, no es tan difícil. Pero, de nuevo, podría ser su tienda, podría ser cualquier cosa.
Por ejemplo, tuvimos un caso así (no investigado) durante mucho tiempo, cuando recibimos datos sobre la densidad de la corriente, datos sobre la densidad de movimiento de los puntos celulares de uno de los operadores celulares, y toda esta información se superpuso en las coordenadas de las vallas ubicadas en las autopistas . Y la tarea del operador móvil es determinar cómo aproximadamente un número de personas están conduciendo y pueden ver este anuncio publicitario.
Si hay especialistas en publicidad en vallas publicitarias, puede decir: es imposible de entender de manera súper confiable: alguien está viajando, alguien no ha mirado, alguien ha mirado ... Sin embargo, este es un ejemplo de cómo 20 mil millones de tales polígonos en Moscú que hay densidades de estas personas cada hora en ciertas rutas ... Puede ver por qué pasaron estas personas en cualquier momento y estimar aproximadamente el flujo de pasajeros.
La respuesta a una pregunta de la audiencia:- Nadie da tales datos. Realizamos dicho estudio para uno de los operadores, esta es una historia exclusivamente interna, por lo tanto, desafortunadamente, no se presenta en forma de imágenes. Pero a menudo las grandes agencias de publicidad no tienen problemas para contactar al operador. Al menos en Moscú hay muchos precedentes cuando, por ejemplo, las compañías de seguros recurren a compañías como GetTaxi, que proporcionan datos anónimos sobre la edad del conductor, cómo conducen (bueno - malo, imprudente - no) para eso. para pronosticar políticas, etc. Todos están luchando con esto, pero en algún nivel interno para dar datos anónimos, creo que nadie tiene ese problema.
Reconocimiento de imágenes e imágenes.
Sigamos adelante. Mi favorito es el reconocimiento de imágenes. Habrá una pequeña parte sobre cómo encontrar personas por caras, pero en su mayoría no tomamos esta parte. , – , .

:

. , , , . , ( ).
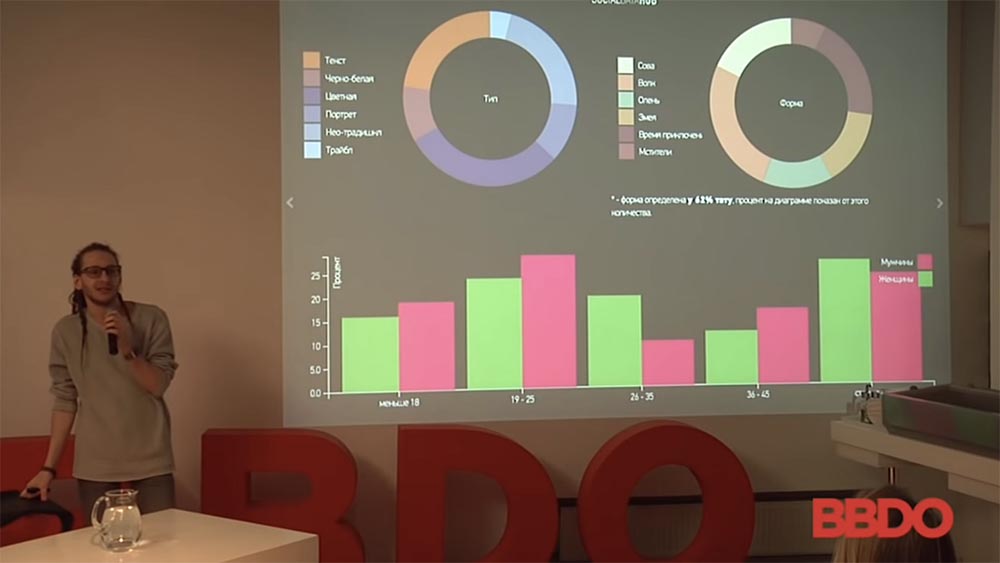
. , , , – - BMW X6, , , , . , .

: , ; – . : , - - ( ).

( ): . , , -, : . , - ( «») , , - . .
. , , . , .
:- – . . , , … , . . , , - … . , . , . , - .
, , , ( ), – , .
, . , . – :
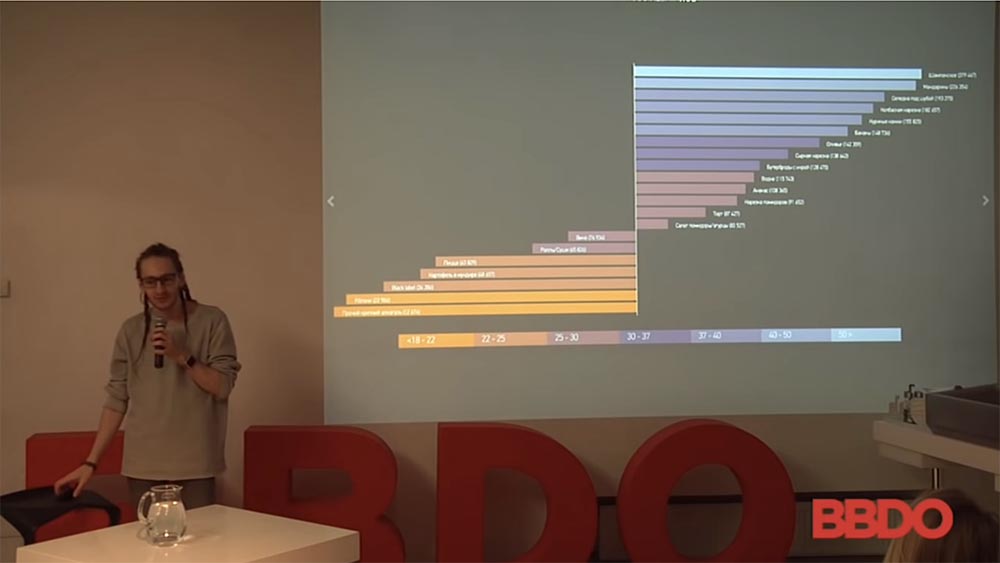
. , , . , , , : , . , , , . , - - .
. , , . , . , . .
:

, - , , . , , -, , , , , .
: , , , , ( ) , ; , , , . , . , , , .


: . , , , – , , .

– . , , , . , . , , . . , , - , - .
. - , . – , – , .

, , , , , … , , , … , :

. . , / – , Transparency International, « », . – , , « ».
, ( ), . , , . , , - . ( , ), - , , , - - – .
. : BBDO Group, . , , , …

, . , - , – , .
– , . – ; , , - . – (, ); , , , , . – , .
,
– , : , - , -, . , , , , , (, ).
– , , -, , - , , - «. » , . , , , .
, , – , . , , , ( , ). , – . , «».
– , , ; - . , «» , . , – . :

– ( ). , . – , – , . . , , , , . , . -, «» , - .
.
( , ) . , . , , . :

: « » , . , , . , «», , : , , « – », , , , . , , , - , . !
, . ! , , -. , ; ( ) , . ! …
, , , . . , . , , - , - , .
, , . .

. . … , , , , – «, 37% , – , – « ! !» : , .
, … , , , - , - - . - . - .
( , 10 ), , , , , . « », « » .
«», -
: , «» .

: , , , 2%, – « ». , – , - . , – , . , , , - .
. , ?

- , , , , . , -, , – . . , , … – ! , . , , .
:Big Data
De hecho, tengo muchos ejemplos políticos interesantes diferentes sobre Trump y sobre todos los demás, pero decidí no traerlos aquí. Pero hay un ejemplo político.
Esta es una elección para la Duma del Estado. Cuando estabas El año pasado? Hace casi un año y medio.

Aquí hay personas que lograron determinar su ubicación exacta, hasta cierto punto geográfico, para comprender en qué PEC selectivo se encuentran. Y luego solo aquellos que expresaron su opinión definitiva fueron tomados de estas personas, por quienes irían a votar.
Desde el punto de vista de las tecnologías políticas, esto no es muy correcto, porque todo debe normalizarse a la densidad de población, etc. Sin embargo, los azules van a votar aquí, ya sabes para quién, los rojos son para los camaradas de la oposición, quienes, por cierto, no eran muchos.
Personalmente, creo que Big Data no llegará a las tecnologías políticas muy pronto, pero, como opción, el candidato también es una marca. Y esto también es, hasta cierto punto, un análisis de hechos y opiniones sobre su marca, y una cosa bastante interesante, porque puede comprender en tiempo real quién está haciendo qué. Ahora conozco varios casos de la BBC cuando monitorearon las redes sociales en tiempo real en alguna transmisión: la respuesta es tal y tal, la gente escribe sobre eso, hace tal o cual pregunta, ¡y es genial! Creo que se aplicará muy pronto, porque es interesante para todos.
Modelando posiciones de marca

A continuación he modelado las posiciones de las marcas. Una pequeña cosa corta sobre cómo usar varias métricas (no me gusta de los suscriptores en las redes sociales, sino usar métricas complejas, interés en el contenido, tiempo dedicado a obtener métricas) puede clasificar las marcas.

Tengo un ejemplo para una "granja" para una determinada. Aquí, los círculos redondos pequeños son internos, brillantes: esta es la cantidad de contenido de texto que crea la marca, los círculos redondos grandes: esta es la cantidad de contenido de fotos y videos que crea la marca.
La proximidad al centro muestra cuán interesante es este contenido para la audiencia. Hay un gran modelo, hay muchos tipos de parámetros: me gusta, reposts, tiempo de respuesta, que compartieron allí en promedio ... Aquí puedes ver: hay un maravilloso "Kagocel" que gasta mucho dinero en crear tu propio contenido, y debido a esto están lo suficientemente cerca. al centro Y hay camaradas que también crean su contenido, pero no es interesante para el público. Este no es un ejemplo muy adecuado, porque todas estas cuentas están casi muertas.
Yegor Creed ama más que Basta

Desafortunadamente, el resto ... de qué mostrar ... Aquí, todavía hay raperos rusos, como opción, de compañías reales.
¿Cuál es el plus? El hecho de que una empresa puede poner casi cualquier cosa en ese modelo, a partir del salario promedio de los suscriptores que están en su marca; cualquier modelo que les guste. Debido a que cada agencia de publicidad considera sus propias métricas de manera diferente, las marcas consideran sus propias métricas de manera diferente.
También hay uno aquí: Basta, que genera una gran cantidad de contenido, pero se encuentra en la periferia, porque este contenido, aparentemente, no es muy interesante para el público. De nuevo, no pretendo juzgar. Sin embargo, está Yegor Creed, quien, según las redes sociales, es casi el mejor intérprete de nuestro tiempo, y al mismo tiempo publica solo sus fotos personales. Sin embargo, tiene una gran cantidad de suscriptores: hay alrededor de un millón de ellos. No recuerdo la cantidad exacta; Recuerdo que el porcentaje de participación de estas personas es muy superior al 85%, es decir, para un millón de suscriptores recibe 850 mil respuestas de estas personas reales, esto es una verdadera locura. Eso es asi.
 Respuestas a las preguntas de la audiencia:
Respuestas a las preguntas de la audiencia:¿Cuánto tiempo llevó compilar un modelo de análisis de rapero?
- Cada uno tiene su propio público objetivo, sus intereses, se cuenta a estas personas ... Todo esto se normaliza a una distancia al centro aproximadamente, su posición radial no es importante (solo está untada aquí por belleza, para que no se encuentren entre sí). Solo la proximidad aproximada al centro es importante. Este es el modelo que estamos usando. Por ejemplo, me gusta más el círculo, alguien lo hace pensando en un semicírculo.
- Este modelo se compiló rápidamente, en dos horas, en tres (sí, una persona). Aquí, se insertaron exclusivamente métricas: lo que multiplicamos, agregamos y luego normalizamos de alguna manera. Depende del modelo. Hay personas que están interesadas en el salario promedio (esto no es una broma) de sus suscriptores. Y para esto necesita encontrar sus contactos, "Avito", todo esto para calcular, multiplicar. Sucede, lleva mucho tiempo, pero específicamente (apunta a la diapositiva anterior): aquí hay parámetros muy simples: suscriptores, reenvíos, etc. Tomó alrededor de dos o tres horas. En consecuencia, esta cosa se actualiza en tiempo real, se puede usar.
Ahora la parte divertida. Tengo todo con ejemplos, porque no es interesante hablar solo durante mucho tiempo. Y espero que hagan preguntas ahora, y pasemos de un tema a otro, porque tengo ejemplos de cómo se pueden usar las tecnologías, etc.
Respuestas a las preguntas de la audiencia:- Tuve un único caso personal con uno, por así decirlo, okolokazino, cuando se colocó la cámara allí, se reconocieron los rostros, y así sucesivamente. El porcentaje de personas reconocidas es definitivamente bastante grande: lo que tenemos, lo que tienen nuestros competidores. Pero en realidad es lo suficientemente interesante. Veo esto como algo interesante: puedes entender quiénes son estas personas y predecir muy bien por qué vinieron aquí, qué ha cambiado en su vida, que decidieron venir al casino. Pero sobre tipos específicos de negocios ... Si pones algo así en una farmacia, entonces no tiene sentido: no puedes predecir por qué una persona vino a una farmacia.
La tarea global aquí era construir un modelo para comprender cuándo una persona podría interesarle potencialmente a su marca, darle un anuncio no después de que compró algo (como está sucediendo ahora), sino darle un anuncio "en el pronóstico" de cuando todo sucede. Con tal "okolokazino" fue interesante; allí, un porcentaje bastante interesante de estas personas resultó: por qué: alguien de repente recibió un aumento, alguien más algo, ideas tan interesantes. Pero con algunas tiendas, con tiendas minoristas, con una tienda de algunas píldoras, me parece que no será muy correcto.
¿Se utiliza Big Data sin conexión?
- Estaba fuera de línea. Solo necesita comprender exactamente, aproximadamente: este modelo convergerá, no convergerá. Una vez más, con agua de soda ... En realidad estoy interesado en todo, pero personalmente no entiendo cuánto pueden depender los perfiles de estas personas de su comportamiento cuando quieren comprar agua embotellada. Aunque esto puede ser cierto, no lo sé.
¿Cuántas cuentas abiertas hay en las redes sociales?
- Tenemos específicamente 11 redes sociales: esto es Vkontakte, Facebook, Twitter, Odnoklassniki, Instagram y algunas pequeñas cosas allí (puedo ver la lista, como Mail.ru, etc.). "Vkontakte" definitivamente tenemos una copia de todos estos camaradas. Tenemos gente Vkontakte: esto es 430 millones de todos los que han existido (de los cuales unos 200 millones están constantemente activos); hay grupos, hay conexiones entre estas personas, y hay contenido que nos interesa (texto) y parte de los medios, pero muy pequeño ... Hablando en términos generales, miramos esta imagen: si hay caras, las guardamos, si el memesic lo usamos No ahorramos, porque incluso con nosotros, no habría suficiente para preservar el contenido de los medios.
Hay un Facebook en ruso. En algún lugar ahora el 60-80% son Odnoklassniki, en un par de meses probablemente los conseguiremos a todos hasta el final. Ruso "Instagram". Para todas estas redes sociales, hay grupos, personas, conexiones entre ellas y el texto. - Unos 400 millones de personas. Hay una sutileza: hay personas que no tienen una ciudad (son potencialmente rusas / no rusas); de ellos en promedio en las redes sociales, aquí, en Vkontakte, el 14% de las cuentas cerradas, no sé el número exacto en Facebook.
- En Instagram tampoco guardamos medios, solo si hay caras allí. No guardamos dicho (otro) contenido multimedia. Generalmente interesante: solo texto, comunicación entre personas; Eso es todo. La investigación más frecuente de Instagram es la investigación habitual de la audiencia: quiénes son estas personas, como lo más importante aquí es la conexión de estas personas con otras redes sociales. Encuentre el perfil de esta persona en Vkontakte y Facebook para calcular su edad, etc.
- Hasta ahora, no hay necesidad de llevar a todos los demás, simplemente porque no hay clientes. En cuanto al idioma: tenemos ruso, inglés, español, pero todavía se usa hasta ahora exclusivamente para marcas de Rusia; bueno, o empresas que los lideran desde Rusia.
- Todos los días entrevistamos a personas en muchos, muchos, muchos flujos: recopilamos datos mediante la recopilación de la web y actualizamos estos indicadores utilizando Api. En 2-3 días puede recorrer todo el Vkontakte, habiéndolos escaneado; en algún lugar de una semana puedes revisar todo Facebook, dándote cuenta de quién ha actualizado allí, qué no. Y luego estas personas deberían reunirse por separado: qué ha cambiado exactamente, para escribir toda esta historia. En mi memoria, es muy raro que alguna tarea comercial real utilice el antiguo perfil de alguien en las redes sociales. Este era el momento en que un político se acercaba, y su tarea consistía en comprender qué tipo de personas acudían a la sede, quiénes eran estas personas hace 6-8 meses (no borraron su perfil, pero de hecho para otro candidato, llegaron las papeletas) estropear)
Y un par de veces: historias personales cuando las fotos de alguien se publicaron públicamente. Era necesario encontrar conexiones, etc. Desafortunadamente, es muy patético, pero no podemos testificar en la corte, porque nuestra base es legalmente ilíquida. - El repositorio de MongoDB es mi favorito.
Las redes sociales están luchando con la recopilación de datos.
- Por lo general, los anunciantes descargamos solo la lista de estas cuentas, y luego usan el estándar ... Es decir, en las redes sociales, en Vkontakte, puede especificar una lista de estas personas.
Pero para Facebook, se utilizan las cookies compradas. Nosotros mismos no trabajamos con cookies, pero hubo varias historias cuando el anunciante mismo les dio a algunas personas, interactuamos con ellas: tienen estas redes, con publicidad teaser, no teaser, estas cookies. Puedes unir, ¡no hay duda! Pero realmente no me gustan estas cosas, porque creo que esto no es muy confiable. En mi opinión, es puro, es como TNS, que "transmite" televisores; no está claro si miras este televisor, no miras, lavas los platos mientras tu televisor está funcionando ... Y lo mismo aquí: muy a menudo busco en Google algo Internet, pero eso no significa que quiera comprarlo. - Si usa una red estándar de algún tipo de publicidad contextual: tuve varias historias cuando les descargamos a estas personas, traté de usar sus interfaces para vincularlas con "cookies" en sus sitios. Pero realmente no me gustan esas cosas.
Fórmula de nómina de usuarios de Internet
- La fórmula general para el salario promedio: esta es la región donde vive la persona, esta es la categoría de negocio en la que trabaja (es decir, la compañía que es su empleador), luego se toma su posición en esta compañía, se pretende el salario promedio en esta posición ... Salario promedio tomado de Head Hunter y Super Job (y hay varias fuentes más) para una vacante determinada en una región determinada y para un contexto empresarial determinado.
Con Avito y Auto.ru, generalmente se toman parámetros adicionales si una persona enciende el teléfono. Con Avito puede ver las cosas que vende una persona: costosas, económicas, usadas, no usadas. Con "Auto.ru" puedes ver si tiene un auto, es dueño, no es dueño. Esto es menos del 20% de las personas que accidentalmente dejaron caer su teléfono en algún lugar, y su cuenta se puede vincular con estos datos.
¿Qué tan grande es la empresa de recolección de datos?
- El volumen de fotos almacenadas en petabytes es 6.4. No puedo decir con certeza la tasa de crecimiento en este momento, porque en 2016 comenzamos a grabar periscopios y comenzamos a grabar un poco de video.
No puedo decir exactamente cuándo fue cero. Fuimos de compañía en compañía, todas estas son historias largas. Pero puedo decir que VK, Facebook, Instagram y Twitter, todo este negocio (personas, grupos y enlaces entre ellos) con texto y contenido, en realidad no son tantos datos, apenas es un petabyte recogido Creo que este es un gigabyte de 700, probablemente 800.
¿Ayuda a los clientes a identificar el nicho actual, dónde "cavar"?
- Cuando llega un cliente, le decimos esas cosas, pero nosotros, como Google Trends, no hacemos estas cosas.
- Tuvimos varias historias casi sociológicas, con una historia electiva, preelectoral, analizamos todo esto. Con las marcas y las opiniones de evaluación sobre las marcas, casi todo está de acuerdo. Estas son las historias de elecciones electivas: no (con una evaluación de qué candidato debe ganar). Bueno, quién está equivocado aquí, nosotros, o aquellos que creen en VTsIOM, no lo sé.
- Por lo general, tomamos estos resultados de control de la propia marca, los toman de los camaradas que solicitan investigación: teléfono allí, mercadeo, etc. Además, todo esto puede verificarse con cosas básicas: alguien respondió el boletín allí, alguien encuesta ... Si se trata de una marca grande (Coca-Cola, por ejemplo), deben tener un millón o dos comentarios internos de los clientes. - estos no son solo comentarios en las redes sociales y cualquier opinión; algunos sistemas internos, revisiones, etc.
¡La ley no "sabe" qué son los datos personales!
- Analizamos fuentes de datos exclusivamente abiertas; nunca nos metemos en ninguna chernukha sucia. Nuestro modelo se basa en el hecho de que almacenamos todos los datos abiertos en algunos centros de datos públicos, los alquilamos en otro lugar y los analizamos en casa, en el territorio de las oficinas, en nuestros servidores, y esto no va más allá del territorio.
Pero nuestra legislación de datos abiertos es muy vaga.
No tenemos una comprensión clara de qué son los datos abiertos, qué son los datos personales: existe esta 152a Ley Federal, pero de todos modos ... ¿Piensan cómo? Ahora, si tengo su nombre y su teléfono en una base de datos, tengo su teléfono y su correo electrónico en otra base de datos, y en la tercera, digamos, su correo electrónico y su automóvil; Todo esto es como datos no personales. Si lo pones todo junto, parece que por ley se convertirán en datos personales.
Lo solucionamos de dos maneras. Primero, ponemos el servidor con software al cliente, y luego estos datos no van más allá de su territorio, y luego el cliente es responsable de difundir estos datos personales, no datos personales, etc. O la segunda opción: si se trata de algún tipo de historia en la que tienes que demandar a la red social u otra cosa ...
Tuvimos un estudio de este tipo cuando recopilamos (eran las primarias de Rusia Unida) las cuentas de LifeNews de estos camaradas y vimos qué tipo de porno les gustaba. Lo curioso fue, pero no obstante. Vendemos esto como nuestra propia opinión personal, sin revelar legalmente en los documentos que analizamos: el registro, el salario, las redes sociales; vendemos la opinión de expertos, y ya al margen le explicamos a la persona lo que analizamos y cómo.
Hubo varias historias, pero se asociaron con algunos proyectos comerciales públicos. Por ejemplo, tenemos un proyecto gratuito sin fines de lucro para quienes montan longboards (tales tableros son largos): la tarea consistía en recopilar las publicaciones de las personas, cuando alguien publica: "Fui al parque de Gorky a montar". Y luego debería aparecer en el mapa, y las personas a su alrededor pueden ver que alguien está a su lado. VK pasó mucho tiempo luchando con nosotros sobre este tema, porque no les gustó que publiquemos esta información sin el permiso de las personas. Pero luego el asunto no fue a los tribunales, porque dentro de varias comunidades grandes agregamos a las reglas que los datos pueden ser utilizados por agencias de terceros, agencias, análisis, etc. Por supuesto, no fue particularmente ético, pero de todos modos. - De repente nos dimos cuenta y comenzamos a vender nuestra opinión experta a todos.
¿Trabajas con instituciones educativas?
- Cooperamos con lo educativo, sí. Tenemos toda una serie: tenemos un programa de maestría en la Escuela Superior, cooperamos con otras universidades. ¡Universidades que realmente amamos!
- Ahí están mis contactos, puedes escribir. Y una referencia a la presentación, si alguien estaría interesado, hay todos estos ejemplos, puede moverse.
- Si se conoce un teléfono, el correo es casi una opción absoluta, nadie lo eliminará. Si no hay teléfono, generalmente es una imagen, no hay imagen: este es el año, el lugar de residencia, el trabajo. Es decir, por año, el lugar de residencia y el trabajo, casi todos, siempre se pueden identificar de manera bastante sutil. Pero esto, nuevamente, es una pregunta sobre la tarea.
Tenemos, por ejemplo, un cliente que vende TV por Internet. Alguien les compró una suscripción a estos Juegos de Tronos, y la tarea es encontrar a estas personas desde su CRM en las redes sociales, y luego encontrar potenciales de su área de influencia. Solo digo que tienen, digamos, un nombre, apellido y correo electrónico ... Y luego es muy difícil hacer algo. Puede encontrar personas en la mayoría de los casos por correo electrónico. - En términos de amigos, generalmente "emparejamos" a las personas con las redes sociales, pero esto no siempre es correcto. No es que no siempre sea correcto, no siempre funciona. En primer lugar, esto requiere mucho trabajo, porque esta operación (para emparejar personas) tendrá que llevarse a cabo primero para cada uno de los amigos, para comprender si se cambiaron de las redes sociales o no. Y luego, para nadie es un hecho desconocido que "Vkontakte" solo tenemos amigos, en "Facebook" tenemos otros amigos. No para todos, sino para mí, por ejemplo, así; .
?
- . , , . NDA. , , , , – , , . , – , – .
?
- , , , – , , – . , , , – Social Data Hub, . . , , , , . , …
- ( ?) , , .
( ): , , . - «» – 14%, «» ( ). , – .
, !
- , – . , «». , , … , ! - – , . – , . , , …
- : «, - ! !» , . - , – , , … , , 5 , - . , HR-, , : « – »!
. ?
- -10 . : … – , HR- , . , , - …
- ( ) 25 , .
- , , , 50 %. , - . , 40 , 50-60 % . . , - , , - , , … , – , . .
Un poco de publicidad :)
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos
VPS basado en la nube para desarrolladores desde $ 4.99 , un
análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?