Hoy en día, existen soluciones preparadas (patentadas) para monitorear transmisiones IP (TS), por ejemplo, VB e iQ , tienen un conjunto bastante rico de funciones y, por lo general, tales soluciones están disponibles para grandes operadores que se ocupan de servicios de TV. Este artículo describe una solución basada en el proyecto de código abierto TSDuck , diseñado para minimizar el control de los flujos de IP (TS) por el contador CC (contador de continuidad) y la velocidad de bits. Una posible aplicación es controlar la pérdida de paquetes o el flujo completo a través de un canal L2 alquilado (que no se puede monitorear normalmente, por ejemplo, leyendo los contadores de pérdida en las colas).
Muy breve sobre TSDuck
TSDuck es un software de código abierto (licencia BSD de 2 cláusulas) (un conjunto de utilidades de consola y una biblioteca para desarrollar sus utilidades o complementos) para manipular flujos de TS. Como entrada, puede funcionar con IP (multidifusión / unidifusión), http, hls, sintonizadores dvb, demodulador dektec dvb-asi, hay un generador de flujo TS interno y lectura de archivos. La salida puede ser un archivo, IP (multidifusión / unidifusión), hls, dektec dvb-asi y moduladores HiDes, reproductores (mplayer, vlc, xine) y soltar. Entre la entrada y la salida, puede activar varios procesadores de tráfico, por ejemplo, reasignación de PID, codificación / descifrado, análisis de contadores CC, cálculo de tasa de bits y otras operaciones típicas de los flujos TS.
En este artículo, se utilizarán flujos de IP (multidifusión) como entrada, se utilizarán procesadores bitrate_monitor (por el nombre está claro de qué se trata) y continuidad (análisis de contadores CC). Sin ningún problema, puede reemplazar la multidifusión IP con otro tipo de entrada compatible con TSDuck.
Hay compilaciones / paquetes oficiales de TSDuck para la mayoría de los sistemas operativos actuales. Para Debian, no lo son, pero fue posible ensamblar sin problemas bajo debian 8 y debian 10.
Luego, se usa TSDuck versión 3.19-1520, Linux se usa como SO (debian 10 se usó para preparar la solución, CentOS 7 se usó para uso real)
Preparando TSDuck y OS
Antes de monitorear flujos reales, debe asegurarse de que TSDuck funcione correctamente y que no haya caídas en el nivel de la tarjeta de red o del sistema operativo (socket). Esto es necesario para no adivinar más tarde dónde se produjeron las caídas: en la red o "dentro del servidor". Puede verificar las caídas en el nivel de la tarjeta de red con el comando ethtool -S ethX, el ajuste se realiza con la misma ethtool (por lo general, debe aumentar el búfer RX (-G) y, a veces, desactivar algunas descargas (-K)). Como recomendación general, puede recomendar el uso de un puerto separado para recibir el tráfico analizado, si es posible, esto minimiza los falsos positivos asociados con el hecho de que la caída se produjo de manera coherente en el puerto del analizador debido a la presencia de otro tráfico. Si esto no es posible (se utiliza una mini computadora / NUC con un solo puerto), entonces es altamente deseable priorizar el tráfico analizado en relación con el resto del dispositivo al que está conectado el analizador. Con respecto a los entornos virtuales, aquí debe tener cuidado y poder encontrar paquetes descartados comenzando desde el puerto físico y terminando con la aplicación dentro de la máquina virtual.
Generación y recepción de un flujo dentro del host.
Como primer paso para preparar TSDuck, generaremos y recibiremos tráfico dentro del mismo host usando netns.
Entorno de cocción:
ip netns add P
El ambiente está listo. Iniciamos el analizador de tráfico:
ip netns exec P tsp --realtime -t \ -I ip 239.0.0.1:1234 \ -P continuity \ -P bitrate_monitor -p 1 -t 1 \ -O drop
donde "-p 1 -t 1" significa que necesita calcular la tasa de bits cada segundo y mostrar información sobre la tasa de bits cada segundo
Iniciamos el generador de tráfico con una velocidad de 10 Mbps:
tsp -I craft \ -P regulate -b 10000000 \ -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
donde "-p 7 -e" significa que necesita empacar 7 paquetes TS en 1 paquete IP y hacerlo duro (-e), es decir espere siempre 7 paquetes TS del último procesador antes de enviar un paquete IP.
El analizador comienza a mostrar los mensajes esperados:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s * 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s * 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/s
Ahora agregue algunas gotas:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROP
y aparecen mensajes como estos:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets * 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets
Lo que se espera. Deshabilite la pérdida de paquetes (ip netns exec P iptables -F) e intente aumentar la tasa de bits del generador a 100 Mbps. El analizador informa un montón de errores CC y aproximadamente 75 Mbit / s en lugar de 100. Tratamos de averiguar quién tiene la culpa: el generador no tiene tiempo o el problema no está en él, para esto comenzamos a generar un número fijo de paquetes (700,000 paquetes TS = 100,000 paquetes IP):
# ifconfig veth0 | grep TX TX packets 151825460 bytes 205725459268 (191.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234 * count: PID 0 (0x0000): 700,000 packets # ifconfig veth0 | grep TX TX packets 151925460 bytes 205861259268 (191.7 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Como puede ver, se generaron exactamente 100,000 paquetes IP (151925460-151825460). Entonces entendemos lo que sucede con el analizador, para esto verificamos con el contador RX en veth1, es estrictamente igual al contador TX en veth0, luego observamos lo que sucede en el nivel del socket:
# ip netns exec P cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355
Aquí puede ver el número de caídas = 24355. En los paquetes TS esto es 170485 o 24.36% de 700000, por lo que vemos que el 25% de la tasa de bits perdida son caídas en el zócalo udp. Las caídas en un socket UDP generalmente ocurren debido a la falta de un buffer, mira cuál es el tamaño del buffer de socket predeterminado y el tamaño máximo del buffer de socket:
# sysctl net.core.rmem_default net.core.rmem_default = 212992 # sysctl net.core.rmem_max net.core.rmem_max = 212992
Por lo tanto, si las aplicaciones no solicitan explícitamente el tamaño del búfer, los sockets se crean con un búfer de 208 KB, pero si solicitan más, aún no recibirán lo que se solicita. Dado que en tsp puede establecer el tamaño del búfer (- tamaño del búfer) para la entrada IP, no tocaremos el tamaño del zócalo de forma predeterminada, solo establecemos el tamaño máximo del búfer del zócalo y especificamos el tamaño del búfer explícitamente mediante argumentos tsp:
sysctl net.core.rmem_max=8388608 ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O drop
Con este ajuste del búfer de socket, la tasa de bits ahora reportada es de aproximadamente 100 Mbit / s, no hay errores de CC.
Por consumo de CPU por la propia aplicación tsp. En relación con un núcleo de la CPU i5-4260U a 1.40 GHz, el análisis de un flujo de 10Mbit / s requiere 3-4% de CPU, 100Mbit / s - 25%, 200Mbit / s - 46%. Al configurar el% de pérdida de paquetes, la carga en la CPU prácticamente no aumenta (pero puede disminuir).
En un hardware más productivo, fue posible generar y analizar flujos de más de 1 Gb / s sin problemas.
Prueba en tarjetas de red reales
Después de probar en un par, debe tomar dos hosts o dos puertos de un host, conectar los puertos entre sí, ejecutar el generador en uno y el analizador en el segundo. No hubo sorpresas, pero en realidad todo depende del hierro, cuanto más débil sea, más interesante será.
Uso de los datos recibidos por el sistema de monitoreo (Zabbix)
Tsp no tiene ninguna API legible por máquina como SNMP o similar. Los mensajes CC deben agregarse al menos 1 segundo (con un alto porcentaje de pérdida de paquetes, puede haber cientos / miles / decenas de miles por segundo, dependiendo de la tasa de bits).
Por lo tanto, para guardar información y dibujar gráficos de errores CC y velocidad de bits y hacer algún tipo de accidente, las siguientes opciones pueden ser más avanzadas:
- Analiza y agrega (según CC) la salida de tsp, es decir conviértalo a la forma deseada.
- Agregue los complementos tsp y / o procesador bitrate_monitor y la continuidad misma para que el resultado se muestre en un formato legible por máquina adecuado para un sistema de monitoreo.
- Escriba su solicitud en la parte superior de la biblioteca tsduck.
Obviamente, desde el punto de vista de los costos laborales, la opción 1 es la más simple, especialmente teniendo en cuenta que tsduck está escrito en un lenguaje de bajo nivel (según los estándares modernos) (C ++)
Un prototipo simple del analizador + agregador en bash mostró que en una transmisión de 10Mbit / sy una pérdida de paquetes del 50% (el peor de los casos), el proceso de bash consumió 3-4 veces más CPU que el proceso de tsp. Este escenario es inaceptable. En realidad, una pieza de este prototipo a continuación
Además del hecho de que funciona inaceptablemente lento, no hay subprocesos normales en bash, los trabajos de bash son procesos independientes, y tuve que registrar el valor de los paquetes que faltan en el efecto secundario una vez por segundo (cuando recibo mensajes de tasa de bits que vienen cada segundo). Como resultado, bash se quedó solo y se decidió escribir un contenedor (analizador + agregador) en golang. El consumo de CPU de un código de golang similar es 4-5 veces menor que el proceso tsp en sí. Acelerar el contenedor reemplazando bash con golang resultó ser unas 16 veces y, en general, el resultado es aceptable (sobrecarga en la CPU en un 25% en el peor de los casos). El archivo fuente en Golang está aquí .
Lanzamiento del envoltorio
Para ejecutar el contenedor, se creó la plantilla de servicio más simple para systemd ( aquí ). Se supone que el contenedor en sí está compilado en un archivo binario (vaya a construir tsduck-stat.go), ubicado en / opt / tsduck-stat /. Se supone que golang se usa con soporte para reloj monotónico (> = 1.9).
Para crear una instancia del servicio, debe ejecutar el comando systemctl enable tsduck-stat@239.0.0.1: 1234, luego comenzar a usar systemctl start tsduck-stat@239.0.0.1: 1234.
Descubrimiento de Zabbix
Para que zabbix pueda descubrir servicios en ejecución, se ha creado un generador de lista de grupo (discovery.sh), en el formato necesario para el descubrimiento de Zabbix, se supone que está ubicado allí, en / opt / tsduck-stat. Para iniciar el descubrimiento a través de zabbix-agent, debe agregar el archivo .conf al directorio con las configuraciones de zabbix-agent para agregar el parámetro de usuario.
Plantilla Zabbix
La plantilla creada (tsduck_stat_template.xml) contiene la regla de detección automática, prototipos de elementos de datos, gráficos y disparadores.
Una breve lista de verificación (bueno, ¿y si alguien decide usarla?)
- Asegúrese de que tsp no deje caer paquetes en condiciones "ideales" (el generador y el analizador están conectados directamente), si hay caídas, consulte la sección 2 o el texto del artículo sobre este tema.
- Realice el ajuste del búfer de socket máximo (net.core.rmem_max = 8388608).
- Compile tsduck-stat.go (vaya a construir tsduck-stat.go).
- Coloque la plantilla de servicio en / lib / systemd / system.
- Inicie los servicios usando systemctl, verifique que los contadores comenzaron a aparecer (grep "" / dev / shm / tsduck-stat / *). Número de servicios por el número de flujos de multidifusión. Aquí puede que necesite crear una ruta al grupo de multidifusión, tal vez apague rp_filter o cree una ruta a la fuente ip.
- Ejecute discovery.sh, asegúrese de que genera json.
- Adjunte la configuración del agente zabbix, reinicie el agente zabbix.
- Descargue la plantilla en zabbix, aplíquela al host en el que se supervisa e instala zabbix-agent, espere unos 5 minutos, vea que han aparecido nuevos elementos de datos, gráficos y disparadores.
Resultado
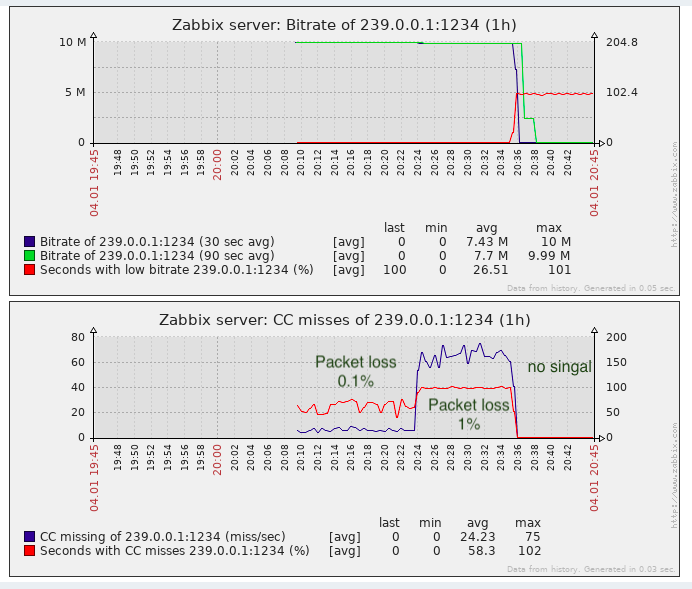
Para la tarea de detectar la pérdida de paquetes es casi suficiente, al menos es mejor que la falta de monitoreo.
De hecho, las “pérdidas” CC pueden ocurrir al pegar videoclips (hasta donde yo sé, las inserciones se realizan en telecentros locales en la Federación de Rusia, es decir, sin contar el contador CC), esto debe recordarse. En las soluciones patentadas, este problema se omite parcialmente al detectar etiquetas de etiquetas SCTE-35 (si el generador de flujo las agrega).
UPD: se agregó soporte para etiquetas SCTE-35 a la plantilla wrapper y zabbix
Desde el punto de vista de monitorear la calidad del transporte, no hay suficiente jitter de monitoreo (IAT), porque El equipo de TV (ya sean moduladores o dispositivos finales) tiene requisitos para este parámetro y no siempre es posible inflar jitbuffer hasta el infinito. Y la fluctuación de fase puede flotar cuando se utiliza equipo con grandes amortiguadores en tránsito y la QoS no está configurada o no está bien configurada para transmitir dicho tráfico en tiempo real.