En este artículo, les presento mis pensamientos sobre la historia y las perspectivas del desarrollo de Internet, redes centralizadas y descentralizadas y, como resultado, la posible arquitectura de la red descentralizada de próxima generación.
Algo está mal con Internet
Conocí Internet por primera vez en 2000. Por supuesto, esto está lejos de ser el principio: la Red ya existía antes de eso, pero ese momento se puede llamar el primer apogeo de Internet. La World Wide Web es un invento brillante de Tim Berners-Lee, web1.0 en su forma canónica clásica. Muchos sitios y páginas que enlazan entre sí con hipervínculos. A primera vista, una arquitectura simple, como toda brillante:
descentralizada y gratuita . Quiero: estoy viajando por los sitios de otras personas, siguiendo hipervínculos; Quiero crear mi propio sitio web en el que publico lo que me interesa, por ejemplo, mis artículos, fotos, programas, hipervínculos a sitios que me interesan. Y otros publican enlaces a mí.
Parecería: ¿una imagen idílica? Pero ya sabes cómo terminó todo.
Había demasiadas páginas, y la búsqueda de información se convirtió en algo muy trivial. Los hipervínculos registrados por los autores simplemente no pudieron estructurar esta gran cantidad de información. Primero hubo directorios llenados manualmente, y luego motores de búsqueda gigantes que comenzaron a usar algoritmos de clasificación heurísticos ingeniosos. Los sitios fueron creados y abandonados, la información fue duplicada y distorsionada. Internet se comercializaba rápidamente y se alejaba de la red académica ideal. El lenguaje de marcado se convirtió rápidamente en un lenguaje de formato. Hubo publicidad, viles banners molestos y la tecnología de promoción y engaño de los motores de búsqueda: SEO. La red rápidamente se obstruyó con basura informativa. Los hipervínculos dejaron de ser una herramienta de comunicación lógica y se convirtieron en una herramienta de promoción. Los sitios fueron guardados, cerrados sobre sí mismos, pasados de "páginas" abiertas a "aplicaciones" herméticas, se convirtieron en el único medio de generar ingresos.
Incluso entonces, tuve un cierto pensamiento de que "algo está mal aquí". Un montón de sitios diferentes, que van desde páginas de inicio primitivas con una apariencia vyrviglazny, y que terminan en "megaportales", sobrecargados con pancartas parpadeantes. Incluso si los sitios están en el mismo tema, no tienen relación alguna, cada uno tiene su propio diseño, su propia estructura, pancartas molestas, búsquedas que funcionan mal, problemas con la descarga (sí, quería tener información fuera de línea). Incluso entonces, Internet comenzó a convertirse en una especie de televisión, donde todo tipo de guirnaldas estaba sujeto a contenido útil con uñas.
La descentralización se ha convertido en una pesadilla.
Que quieres
Paradójicamente, como usuario, ¡no necesitaba descentralización! Recordando mis pensamientos claros de aquellos tiempos, llegué a la conclusión de que necesitaba ... ¡una
sola base de datos ! Tal consulta a la que daría todos los resultados, pero no la más adecuada para el algoritmo de clasificación. Uno en el que todos estos resultados serían diseñados y diseñados de manera uniforme por mi propio diseño único, en lugar de diseños vyrviglaznymi hechos por uno mismo por numerosos Vasya Pupkin. Uno que podría mantenerse fuera de línea y no tener miedo de que mañana el sitio desaparezca y la información desaparezca para siempre. Uno en el que podría ingresar mi información, por ejemplo, comentarios y etiquetas. Uno en el que podría buscar, ordenar y filtrar con mis algoritmos personales.
Web 2.0 y redes sociales
Mientras tanto, el concepto de Web 2.0 ha entrado en la arena. Formulado en 2005 por Tim O'Reilly como "una metodología para diseñar sistemas que, teniendo en cuenta las interacciones de red, mejoran a medida que más personas los utilizan", e implica la participación activa de los usuarios en la creación y edición colectiva de contenido web. Sin exagerar, las redes sociales se convirtieron en el pináculo y el triunfo de este concepto. Plataformas gigantes que reúnen a miles de millones de usuarios y almacenan cientos de petabytes de datos.
¿Qué obtuvimos en las redes sociales?
- unificación de interfaz; Resultó que todas las posibilidades para crear un diseño diverso vyviglazny los usuarios no necesitan; todas las páginas de todos los usuarios tienen el mismo diseño y se adapta a todos y es incluso conveniente; Solo el contenido es diferente.
- unificación funcional; toda la variedad de guiones también era innecesaria. Lenta, amigos, álbumes ... durante la existencia de las redes sociales, su funcionalidad se ha estabilizado más o menos y es poco probable que cambie: después de todo, la funcionalidad está determinada por los tipos de actividad de las personas, y las personas prácticamente no cambian.
- base de datos única; trabajar con una base de datos de este tipo resultó ser mucho más conveniente que con muchos sitios dispares; La búsqueda se ha vuelto mucho más fácil. En lugar de escanear continuamente una variedad de páginas sueltas, almacenar todo esto en caché, clasificar por algoritmos heurísticos complejos, una consulta unificada relativamente simple a una única base de datos con una estructura conocida.
- interfaz de comentarios: me gusta y reposts en la web normal, el mismo Google no pudo obtener comentarios de los usuarios después de hacer clic en el enlace en los resultados de búsqueda. En las redes sociales, esta conexión era simple y natural.
Que hemos perdido
Hemos perdido la descentralización, lo que significa libertad . Se cree que ahora nuestros datos no nos pertenecen. Si antes podíamos alojar una página de inicio incluso en nuestra propia computadora, ahora damos todos nuestros datos a gigantes de Internet.
Además, a medida que Internet evolucionó, los gobiernos y las corporaciones se interesaron en ella, y hubo problemas de censura política y restricciones de derechos de autor. Nuestras páginas en las redes sociales se pueden prohibir y eliminar si el contenido no cumple con las reglas de la red social; para un puesto descuidado - llevar a responsabilidad administrativa e incluso penal.
Y aquí estamos nuevamente pensando: ¿es posible devolvernos la descentralización? ¿Pero en una forma diferente, desprovista de las deficiencias del primer intento?
Redes de igual a igual
Las primeras redes p2p aparecieron mucho antes de la web 2.0 y se desarrollaron en paralelo con el desarrollo de la web. La principal aplicación clásica de p2p es compartir archivos; Las primeras redes fueron diseñadas para compartir música. Las primeras redes (como Napster) estaban esencialmente centralizadas y, por lo tanto, los titulares de derechos de autor las cubrieron rápidamente. Los seguidores tomaron el camino de la descentralización. En 2000, aparecieron los protocolos ED2K (el primer cliente eDokney) y Gnutella; en 2001, apareció el protocolo FastTrack (cliente KaZaA). Poco a poco, el grado de descentralización aumentó, las tecnologías mejoraron. Los sistemas con una "cola de descarga" fueron reemplazados por torrents, y apareció el concepto de tablas hash DHT distribuidas. A medida que los Estados Unidos apretaron las tuercas, el anonimato de los participantes se hizo más exigente. Desde 2000, la red Freenet ha estado en desarrollo, desde 2003 I2P, y en 2006 se lanzó el proyecto RetroShare. Puede mencionar las numerosas redes p2p que existían anteriormente y que ya han desaparecido, y que ahora están operativas: WASTE, MUTE, TurtleF2F, RShare, PerfectDark, ARES, Gnutella2, GNUNet, IPFS, ZeroNet, Tribbler y muchos otros. Hay muchos de ellos. Son diferentes Muy diferente, tanto en propósito como en diseño ... Probablemente muchos de ustedes ni siquiera conocen todos estos nombres. Y esto está lejos de todo.
Sin embargo, las redes p2p tienen muchas desventajas. Además de las fallas técnicas inherentes a cada implementación específica del protocolo y el cliente, por ejemplo, un inconveniente bastante general es la complejidad de la búsqueda (es decir, todo lo que encontró la Web 1.0, pero en una versión aún más complicada). Google no está aquí con su búsqueda ubicua e instantánea. Y si para redes de intercambio de archivos aún puede utilizar la búsqueda por nombre de archivo o metainformación, encontrar algo, por ejemplo, en redes de cebolla o superposición i2p, es muy difícil, si es posible.
En general, si dibujamos analogías con la Internet clásica, entonces la mayoría de las redes descentralizadas están atrapadas en algún lugar en el nivel FTP. Imagine Internet, en el que no hay nada más que FTP: ni sitios modernos, ni web2.0, ni Youtube ... Eso es todo en este estado, y hay redes descentralizadas. Y a pesar de los intentos individuales de cambiar algo, hay pocos cambios.
Contenido
Pasemos a otra pieza importante de este rompecabezas: el contenido. El contenido es el principal problema de cualquier recurso de Internet, y en particular descentralizado. ¿De dónde conseguirlo? Por supuesto, puede confiar en un grupo de entusiastas (como es el caso de las redes p2p existentes), pero luego el desarrollo de la red será bastante largo y habrá poco contenido.
Trabajar con Internet normal es buscar y estudiar contenido. A veces es preservación (si el contenido es interesante y útil, entonces muchos, especialmente aquellos que llegaron a la Red durante el tiempo de acceso telefónico, incluyéndome a mí) lo mantienen sabiamente fuera de línea para no perderse; porque Internet es algo incontrolable para nosotros, hoy no hay sitio web mañana , hoy hay un video en YouTube: mañana se eliminó, etc.
Y para los torrents (que percibimos más como un medio de entrega que como una red p2p), la preservación generalmente está implícita. Y este, por cierto, es uno de los problemas de los torrents: es difícil mover el archivo descargado una vez a donde es más conveniente usarlo (por regla general, necesita regenerar manualmente la distribución) y es absolutamente imposible cambiarle el nombre (puede hacer un enlace duro, pero muy pocas personas lo saben).
En general, muchos almacenan contenido de una forma u otra. ¿Cuál es su futuro destino? Por lo general, los archivos guardados aparecen en algún lugar del disco, en una carpeta como Descargas, en un montón común, y se encuentran allí junto con muchos miles de otros archivos. Esto es malo, y malo para el usuario mismo. Si Internet tiene motores de búsqueda, la computadora local del usuario no tiene nada de eso. Es bueno si el usuario está ordenado y se usa para ordenar los archivos descargados "entrantes". Pero no todos ellos ...
De hecho, ahora hay muchos que no guardan nada, sino que confían completamente en Internet. Pero en las redes p2p, se supone que el contenido se almacena localmente en el dispositivo del usuario y se distribuye a otros participantes. ¿Es posible encontrar una solución que permita involucrar a ambas categorías de usuarios en una red descentralizada sin cambiar sus hábitos y, además, facilitarles la vida?
La idea es bastante simple: ¿qué pasa si hacemos un medio conveniente y transparente para que el usuario guarde contenido de Internet normal y ahorre de manera inteligente con metainformación semántica, y no en un montón general, sino en una estructura específica con la posibilidad de una mayor estructuración y al mismo tiempo distribuir el contenido guardado a descentralizado? la red?
Comencemos ahorrando
No consideraremos el uso utilitario de Internet para ver los pronósticos del tiempo o los horarios de los aviones. Estamos más interesados en objetos autónomos y más o menos inmutables: artículos (comenzando desde tweets / publicaciones de redes sociales y terminando con artículos grandes, como aquí en Habré), libros, imágenes, programas, grabaciones de audio y video. ¿De dónde viene la información? Por lo general
- redes sociales (varias noticias, pequeñas notas - "tweets", fotos, audio y video)
- artículos sobre recursos temáticos (como Habr); no hay muchos recursos buenos, generalmente estos recursos también se basan en el principio de las redes sociales
- sitios de noticias
Como regla, hay funciones estándar allí: como, volver a publicar, compartir en redes sociales, etc.
Imagine un
complemento de navegador que guardará de manera especial todo lo que nos gustó, volvió a publicar, guardó en el "favorito" (o hizo clic en un botón de complemento especial que se muestra en el menú del navegador en caso de que el sitio no tenga una función similar) / repost / bookmark). La idea principal es que simplemente le guste, como lo hizo un millón de veces antes, y el sistema guarda el artículo, la imagen o el video en un almacenamiento especial fuera de línea y este artículo o imagen está disponible, y para su visualización fuera de línea a través de la interfaz descentralizada del cliente , y en la red más descentralizada! En cuanto a mí, es muy conveniente. No hay acciones innecesarias, e inmediatamente resolvemos muchos problemas:
- guardar contenido valioso que puede perderse o eliminarse
- red descentralizada de llenado rápido
- agregación de contenido de diferentes fuentes (puede estar registrado en docenas de recursos de Internet, y todos los me gusta / reposts se agruparán en una sola base de datos local)
- estructurando su contenido de acuerdo con sus reglas
Obviamente, el complemento del navegador debe configurarse en la estructura de cada sitio (esto es bastante realista, ya hay complementos para guardar contenido de Youtube, Twitter, VK, etc.). No hay tantos sitios para los que tenga sentido crear complementos personales. Como regla general, se trata de redes sociales generalizadas (apenas hay más de una docena de ellas) y una cierta cantidad de sitios temáticos de alta calidad como Habr (también hay pocos). Con el código fuente abierto y las especificaciones, el desarrollo de un nuevo complemento basado en una plantilla en blanco no debería llevar mucho tiempo. Para otros sitios, puede usar el botón de guardar universal, que guardaría toda la página en mhtml, posiblemente después de borrar la página de la publicidad.
Ahora sobre estructurar
Por ahorro "inteligente" me refiero al menos a guardar con metainformación: fuente de contenido (URL), conjunto de me gusta previamente establecidos, etiquetas, comentarios, sus identificadores, etc. De hecho, durante el almacenamiento normal, esta información se pierde ... Una fuente puede significar no solo una URL directa, sino también un componente semántico: por ejemplo, un grupo en las redes sociales o un usuario que volvió a publicar. El complemento puede ser lo suficientemente inteligente como para usar esta información para la estructuración y etiquetado automático. Además, debe entenderse que el usuario mismo siempre puede agregar cierta metainformación al contenido almacenado, para lo cual debe proporcionar herramientas de interfaz enmascaradas y convenientes (tengo muchas ideas sobre cómo hacer esto).
Por lo tanto, se resuelve el problema de estructurar y organizar archivos de usuarios locales. Este es un beneficio listo para usar que puede usarse incluso sin ningún p2p. Es solo una especie de base de datos fuera de línea que sabe qué, dónde y en qué contexto hemos guardado, y le permite realizar pequeños estudios. Por ejemplo, busque usuarios de una red social externa a quienes les guste más que nada en las mismas publicaciones que usted. ¿Cuántas redes sociales permiten esto explícitamente?
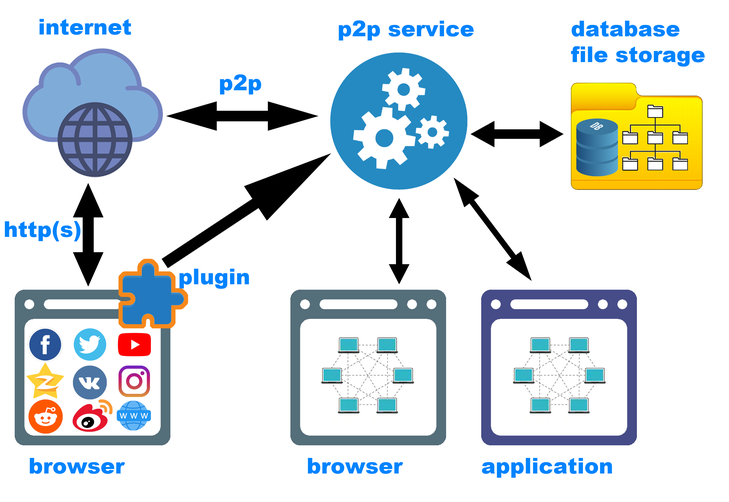
Ya debería mencionarse aquí que un complemento de navegador ciertamente no es suficiente. El segundo componente más importante del sistema es un servicio de red descentralizado que se ejecuta en segundo plano y sirve tanto a la propia red p2p (solicitudes de la red como al cliente), así como a guardar contenido nuevo utilizando el complemento. El servicio, en colaboración con el complemento, colocará el contenido en el lugar correcto, calculará los valores hash (y posiblemente determinará que dicho contenido ya se ha guardado), agregará la metainformación necesaria a la base de datos local.
Lo que es interesante: el sistema ya sería útil de esta forma, sin ningún p2p. Muchas personas usan cortadoras web que agregan contenido interesante de la web, por ejemplo, a Evernote. La arquitectura propuesta es una versión extendida de tal clipper.
Finalmente, intercambio p2p
La mejor parte es que se puede intercambiar información y metainformación (tanto capturada de la web como la suya propia). El concepto de una red social está bien portado a la arquitectura p2p. Podemos decir que la red social y p2p parecen estar hechos el uno para el otro. Idealmente, cualquier red descentralizada debe construirse como una red social, solo entonces funcionará de manera eficiente. “Amigos”, “Grupos”: estas son las mismas fiestas con las que debería haber vínculos estables, y se toman de una fuente natural: los intereses comunes de los usuarios.
Los principios de almacenamiento y distribución de contenido en una red descentralizada son completamente idénticos a los principios de almacenamiento (captura) de contenido de Internet normal. Si usa algún contenido de la red (lo que significa que lo guardó), cualquiera puede usar sus recursos (disco y canal) necesarios para recibir este contenido específicamente.
Los me gusta son la herramienta más fácil de guardar y compartir. Si me gusta, no importa, en Internet externo o dentro de una red descentralizada, entonces me gusta el contenido, y si es así, estoy listo para mantenerlo localmente y distribuirlo a otros miembros de la red descentralizada.
- El contenido no se "pierde"; ahora está almacenado localmente conmigo, puedo volver a él más tarde, en cualquier momento, sin preocuparme de que alguien lo elimine o lo bloquee
- Puedo (inmediatamente o más tarde) clasificarlo, etiquetarlo, comentarlo, asociarlo con otro contenido, en general hacer algo significativo con él, llamémoslo "formación de metainformación"
- Puedo compartir esta metainformación con otros miembros de la red.
- Puedo sincronizar mi metainformación con la metainformación de otros participantes
Probablemente, el rechazo de los disgustos también parece lógico: si no me gusta el contenido, entonces es bastante lógico que no quiera desperdiciar mi espacio en disco para el almacenamiento y mi canal de Internet para distribuir este contenido. Por lo tanto, los disgustos muy orgánicos no encajan en la descentralización (aunque a veces todavía es
útil ).
A veces también necesitas guardar lo que no te gusta. Hay una palabra "necesaria" :)
“
Marcadores ” (o “Favoritos”): no expreso mi actitud hacia el contenido, pero lo guardo en mi base de datos de marcadores local. «» (favorites) ( ), «» (bookmarks) — . «» — «» (.. «» ), «» - . ?
"
". , , , . () .
"
" — , , - , — , . , «», , — , / , .
, . — . — . , , , .
, , . , , , . , -, , ; , , .
, . , . , , , .. , . — , (, «» — , … , ).
, — ( i2p Retroshare), TOR VPN.
( ). , — , . — p2p , («backend»). , . — frontend. - ( ), GUI- (Windows, Linux, MacOS, Andriod, iOS ..). frontend'. backend'.
, . (.. , , , , — , , , ..), ( , Libgen), ( Freenet), ( ), ( — , , , , ..) .
1. — . (, ...) (, ...) —
2. , — /; p2p,
3.
4. /