Los sistemas de control de versiones han sido durante mucho tiempo una herramienta diaria para los desarrolladores. En los grandes repositorios, los requisitos para ellos son muy específicos. Debido a esto, las empresas adaptan las soluciones existentes, como lo hace Facebook con Mercurial y Microsoft con Git, o desarrollan sus propios sistemas: Piper y CitC en Google y Arc VCS en Yandex.
En el informe, el desarrollador Vladimir Kikhtenko
kikht explica por qué Yandex necesitaba su propio sistema de control de versiones y cómo funciona. Considérelo desde el lado de un desarrollador ordinario: cómo acceder al código fuente, reservar una rama para el desarrollo e integrar los cambios en una base de código común. Miramos debajo del capó: aprendemos sobre la representación interna de los datos y su visualización en un sistema de archivos virtual con una copia de trabajo. Discutiremos las dificultades para implementar las funciones de VCS en un sistema de archivos virtual y al cargar datos de manera perezosa. Hablemos sobre cómo garantizar la fiabilidad de la infraestructura del servidor del repositorio.
Al final, puede ver un registro no oficial del informe.
- Buenas tardes a todos, mi nombre es Vladimir. Todos escucharon discursos sobre no escribir bicicletas. Mi informe estará al otro lado de la barricada.
De hecho, Yandex tiene un monorepository en el que hay mucho código. Y llegamos a la conclusión de que estamos desarrollando nuestro propio sistema de control de versiones.

¿Cómo llegamos a tal vida? Históricamente, este monorepositivo vivió con nosotros en SVN. Practica el desarrollo basado en troncales. No hay sucursales con muy pocas excepciones. Todo el código primero debe ingresar al tronco y luego llenarse.
Con el crecimiento del repositorio, la única forma posible de trabajar con él era el pago selectivo, ya que es compatible con SVN. Cargar todo el repositorio para usted no es del todo imposible, pero trabajar con él es muy difícil.

¿Cuál es la escala de nuestro problema? Aquí hay algunos números: 6 millones de confirmaciones, casi 2 millones de archivos individuales. El tamaño total con el historial completo del repositorio es de 2 TB. Para dejar en claro lo que significan estos números en comparación con otros repositorios típicos, aquí hay un gráfico. La mediana de GitHub es el tamaño medio del repositorio en GitHub, 1 MB. El percentil 90 en GitHub es lo que mis colegas llamaron el "depósito del hijo de la novia de mi madre". Y todo lo demás son los famosos grandes repositorios.
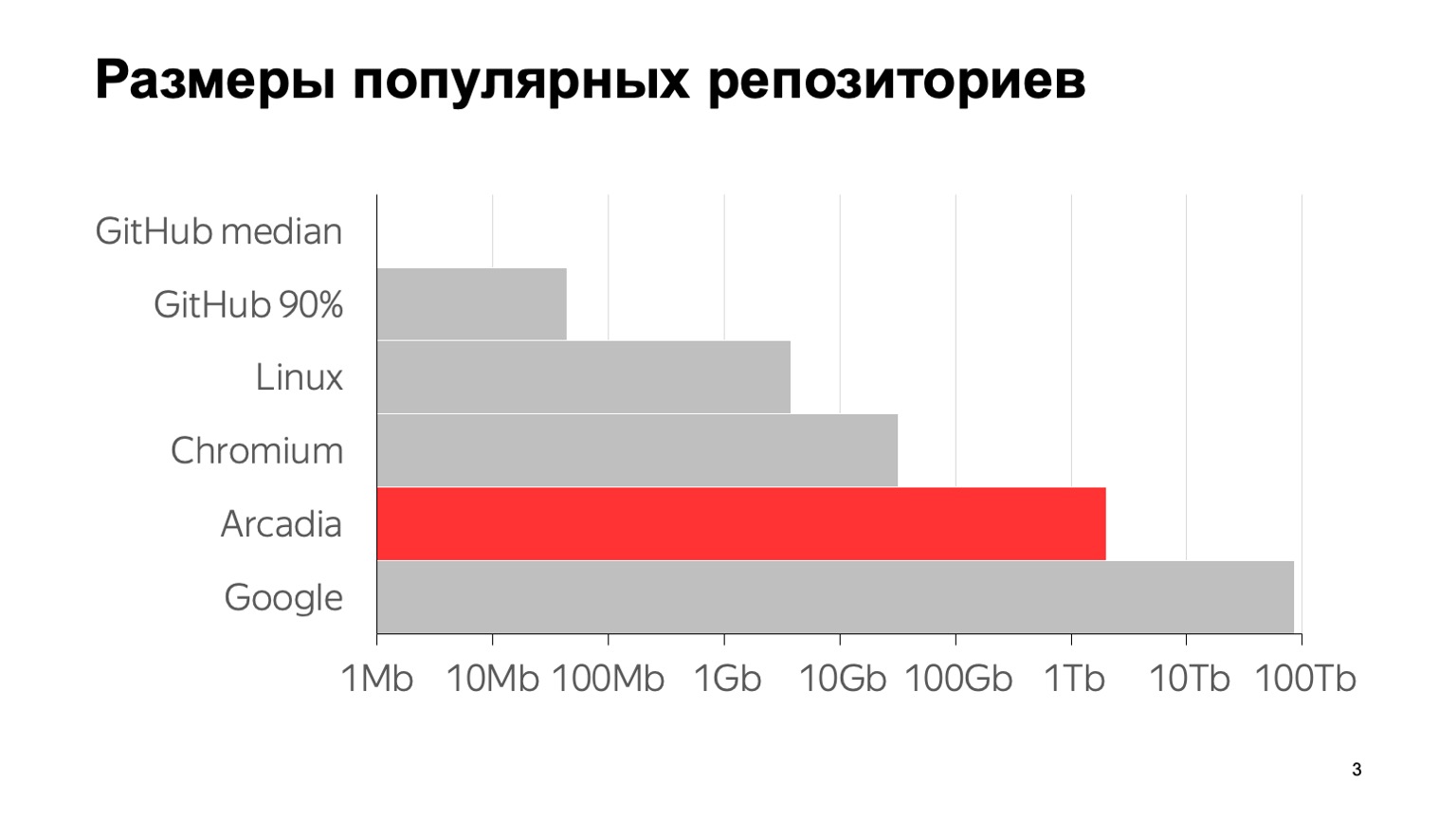
Que yo sepa, el repositorio más grande del mundo está con Google. Se da una estimación de su tamaño de un artículo en 2015, probablemente desde entonces han crecido. Como puede ver, la escala es logarítmica. Se puede ver que también somos bastante grandes.
¿Cómo funcionan los diferentes sistemas de control de versiones al intentar descargar todo este repositorio? Naturalmente, no comenzamos de inmediato a desarrollar nuestro sistema de control de versiones. Intentamos convertir nuestro repositorio a diferentes sistemas. El intento más serio se hizo con Mercurial. Y los resultados del tiempo de las operaciones típicas aún no nos satisfacen.
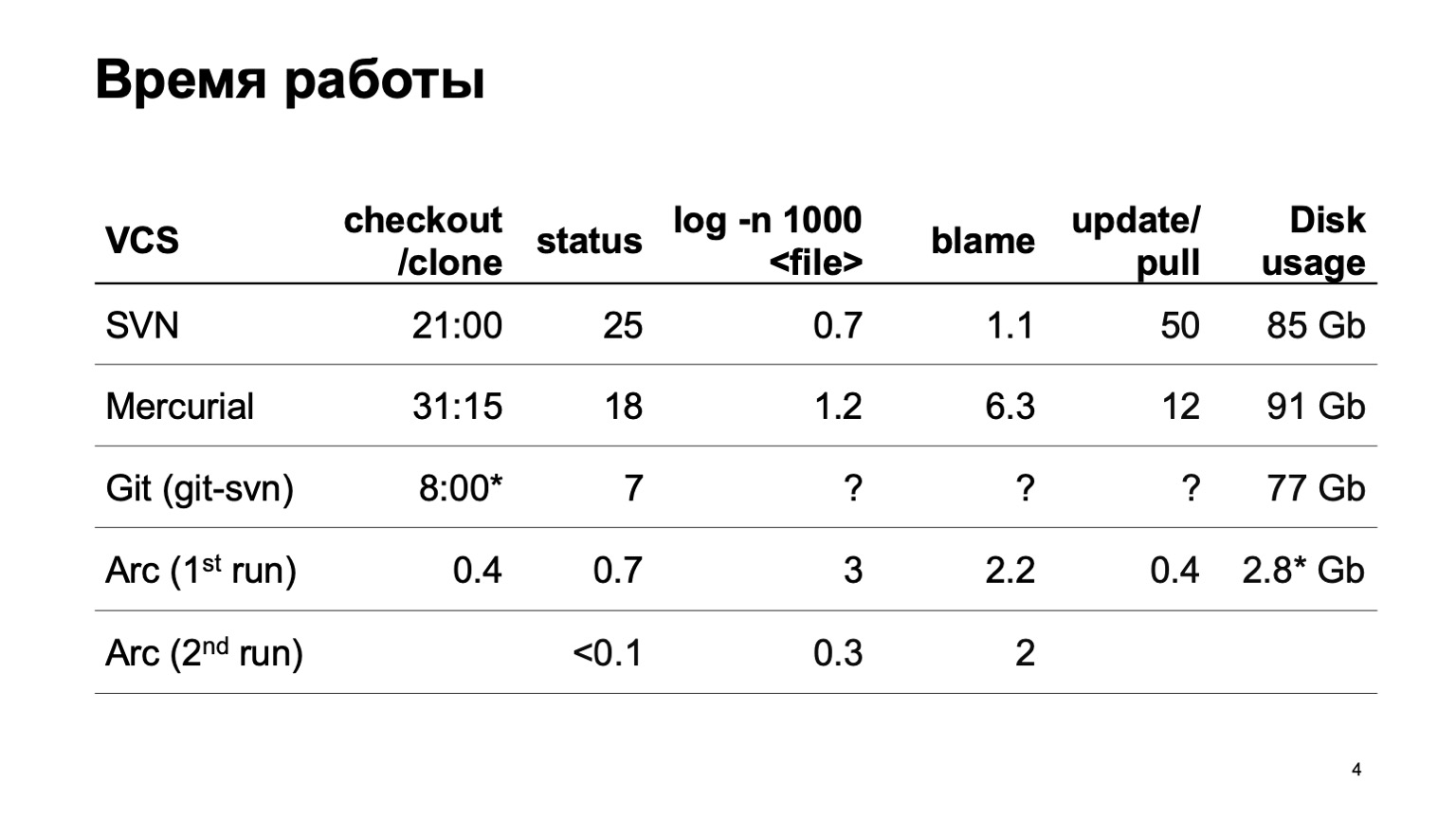
Durante la preparación del informe, desafortunadamente, git-svn no pudo convertir todo nuestro repositorio. Convirtió una porción de un pequeño número de confirmaciones, por lo que no puedo estimar cuántas operaciones relacionadas con el historial funcionan. En un segmento son rápidos, y cómo será para 6 millones de confirmaciones no está muy claro.
Al final están los números de nuestro sistema de control de versiones. Puede obtener instantáneamente una copia de trabajo. En el primer inicio, las operaciones de registro se ralentizan ligeramente; en el segundo inicio, todo funciona rápidamente.
Y el último dígito. Dado que nuestro sistema de control de versiones carga todos los datos de manera perezosa, solo los códigos fuente que realmente resolvimos, que realmente usamos, están en el disco. Esto es significativamente menos que descargar el conjunto.

¿Cómo logramos esto? La característica principal: la copia de trabajo que creamos no es un archivo real en el disco. Este es un sistema de archivos virtual. En Linux y Mac, esto se hace con fusible, en Windows con ProjFS. Cargamos todos los datos de manera perezosa, por lo que se utiliza tanto espacio en disco como realmente necesitamos, no estamos tratando de cargar todo por adelantado. Y llevamos a cabo todo tipo de operaciones pesadas en el servidor. En particular, la operación del registro y algo más.

La interfaz de nuestro sistema de control de versiones, en general, repite Git, por lo que no mostraré cómo es un flujo de trabajo típico. Imagina a Git. Todo es igual: finalice la compra para obtener la revisión deseada, ramifique para crear ramificaciones, confirme para confirmar, el escondite también es compatible de la misma manera. ¿Qué aporta este enfoque? Reducimos significativamente el umbral de entrada. La mayoría de los desarrolladores dentro y fuera de Yandex pueden trabajar con Git. No tienen que aprender nada nuevo.
Por otro lado, no tenemos el objetivo de dejar caer el reemplazo de Git. Hablaré de esto más adelante con más detalle. Para soportar toda la variedad de equipos git parece una locura, casi no los necesitamos a todos.

Te contaré un poco sobre el interior, sobre cómo funciona todo. Comencemos con el modelo de datos. Nuestro modelo de datos es muy similar al geográfico, con algunas diferencias. Del mismo modo, todos los objetos que creamos en su interior son inmutables, se dirigen a ellos mediante un hash de su contenido y, en su interior, se almacenan en buffers planos.

¿Cómo se ve la estructura? Hay objetos de confirmación, cada confirmación tiene uno o varios antepasados. Y de esta manera construyen algunas historias de DAG (gráfico acíclico dirigido).
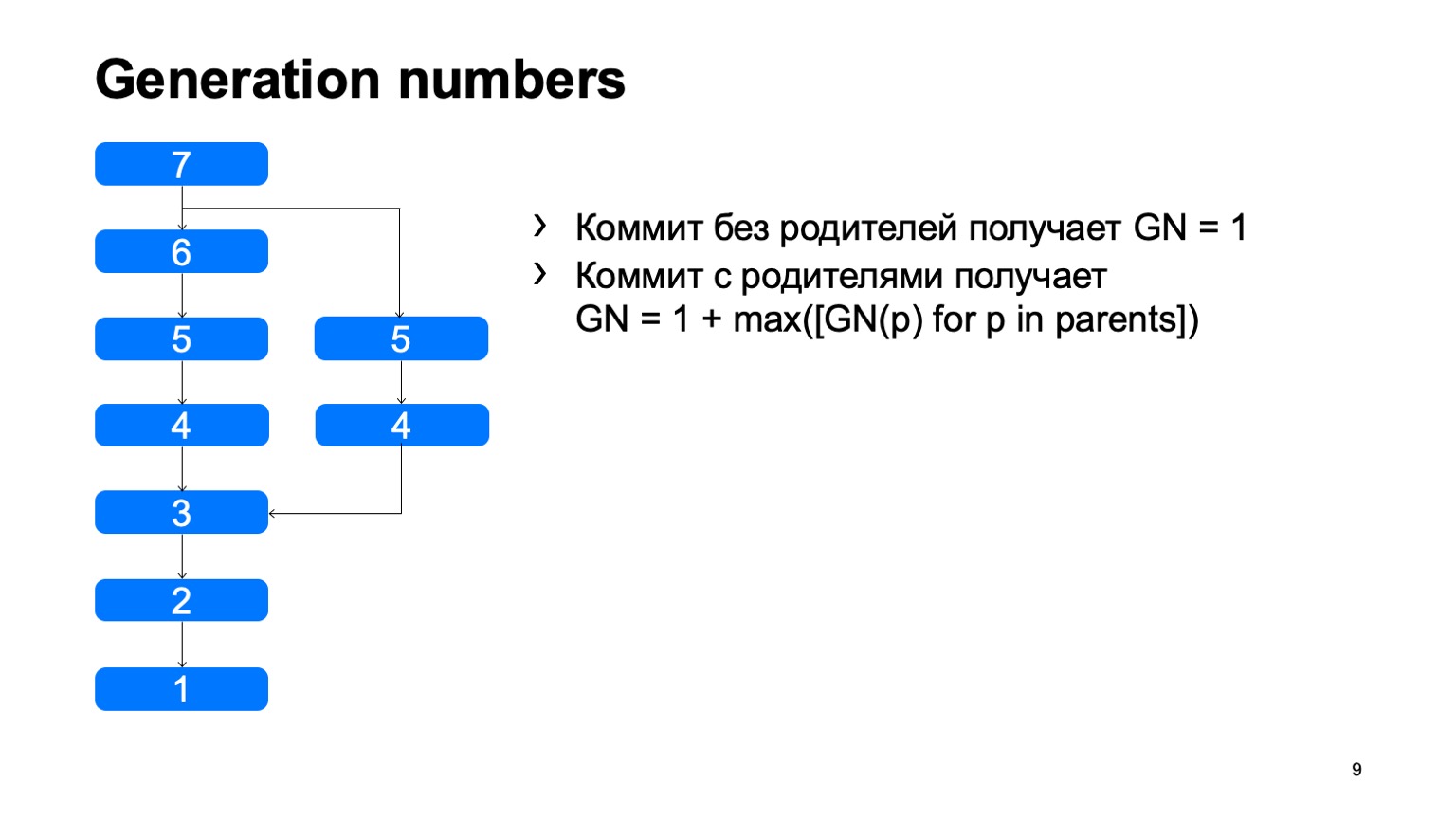
Lo que tenemos y lo que no apareció inmediatamente en Git son los números de generación. Usando un algoritmo simple, consideramos una cierta distancia desde la raíz del árbol. ¿Por qué necesitamos esto? Todo esto está cosido en la estructura de los objetos, una vez arreglado, y nunca cambia de nuevo.
Una operación bastante importante para un sistema de control de versiones es encontrar el ancestro común más pequeño para los dos commits. En la versión básica, se puede implementar simplemente dando vueltas en ancho, comenzando desde unos dos puntos, marcando todas las confirmaciones alcanzadas allí con uno u otro signo, tan pronto como encuentren una confirmación que tenga estos dos signos, existe el antepasado menos común.
¿Cómo funcionará esto en una implementación ingenua? Algo como esto: ve y encuentra nuestro compromiso deseado.
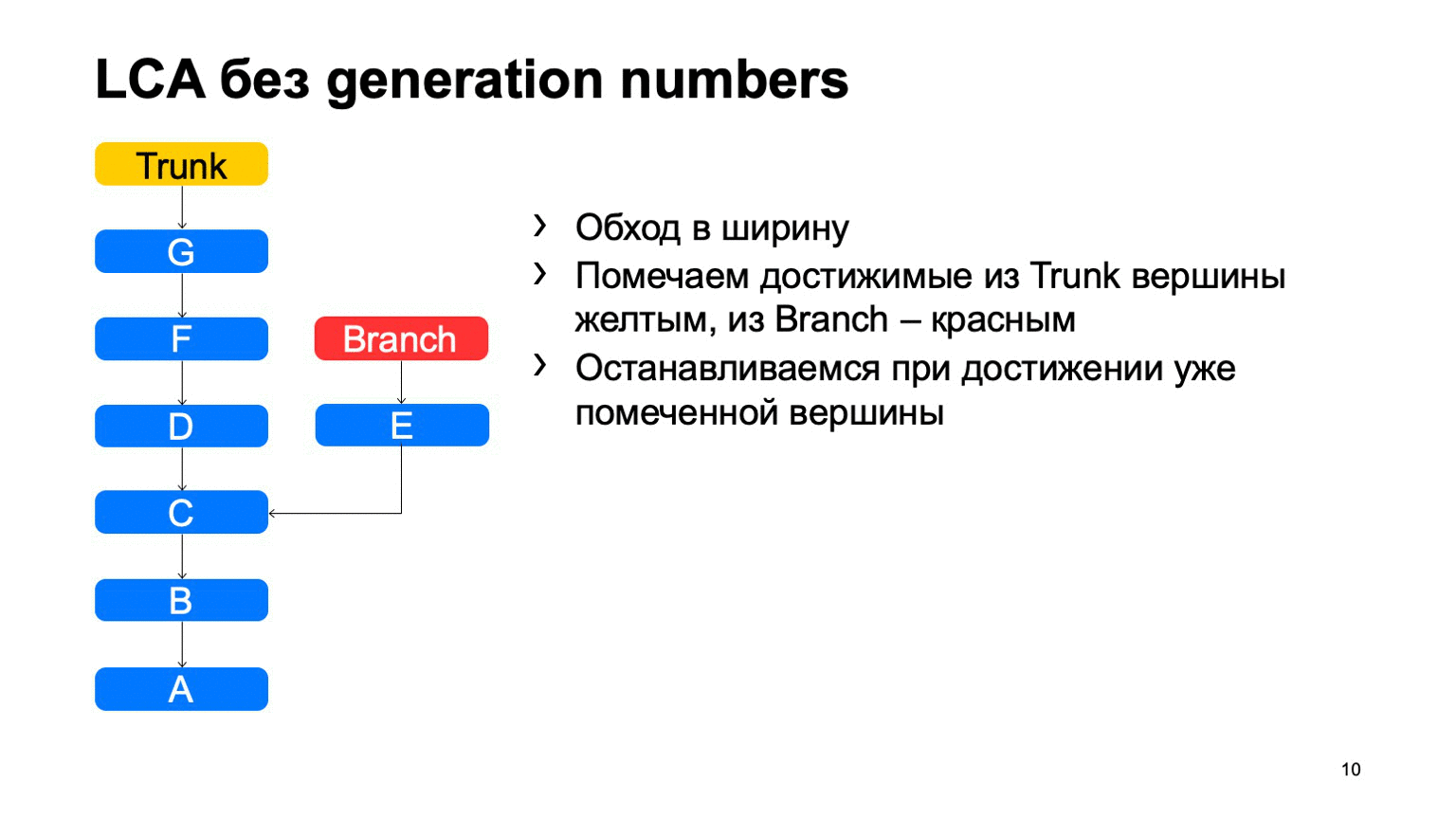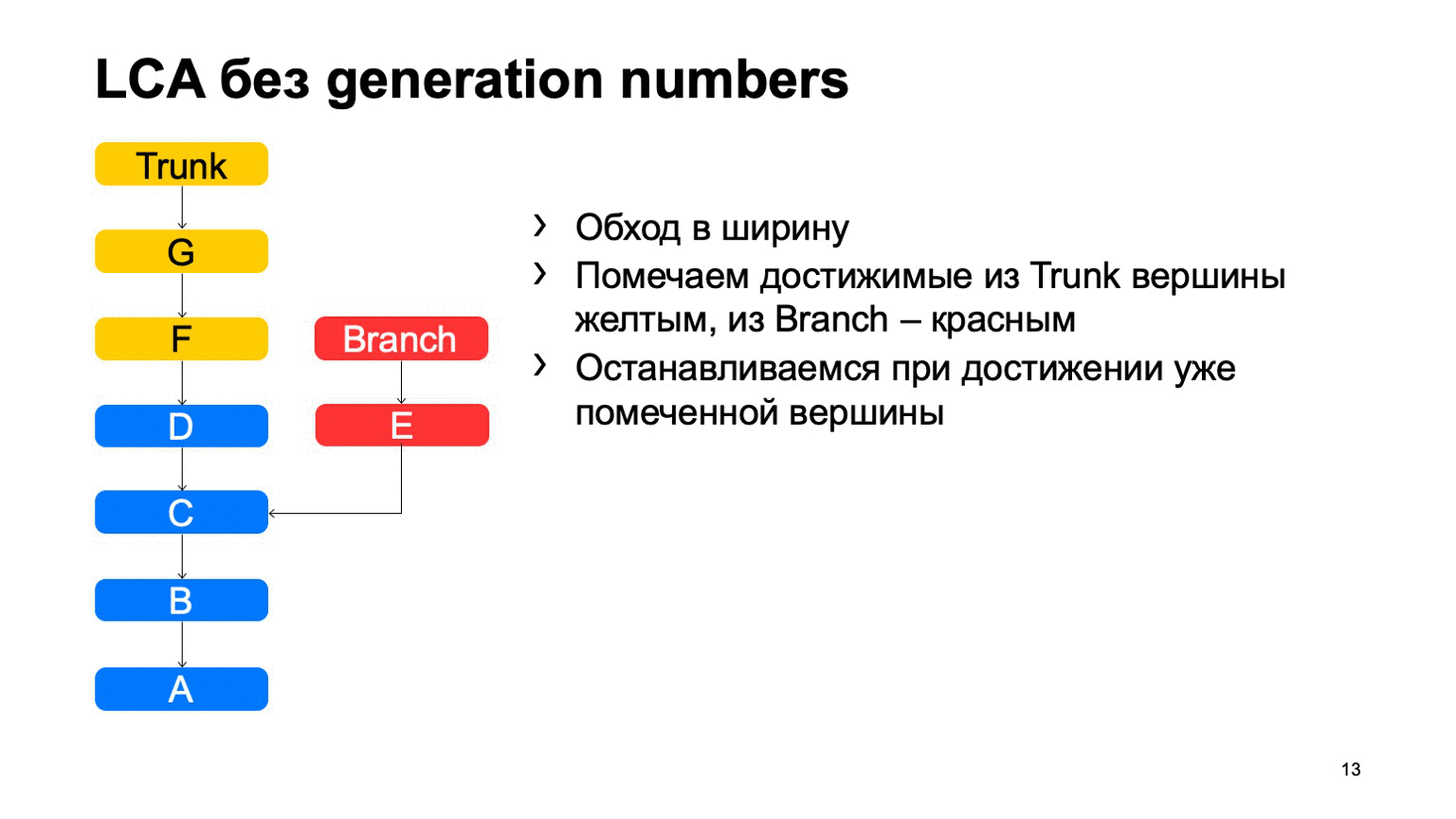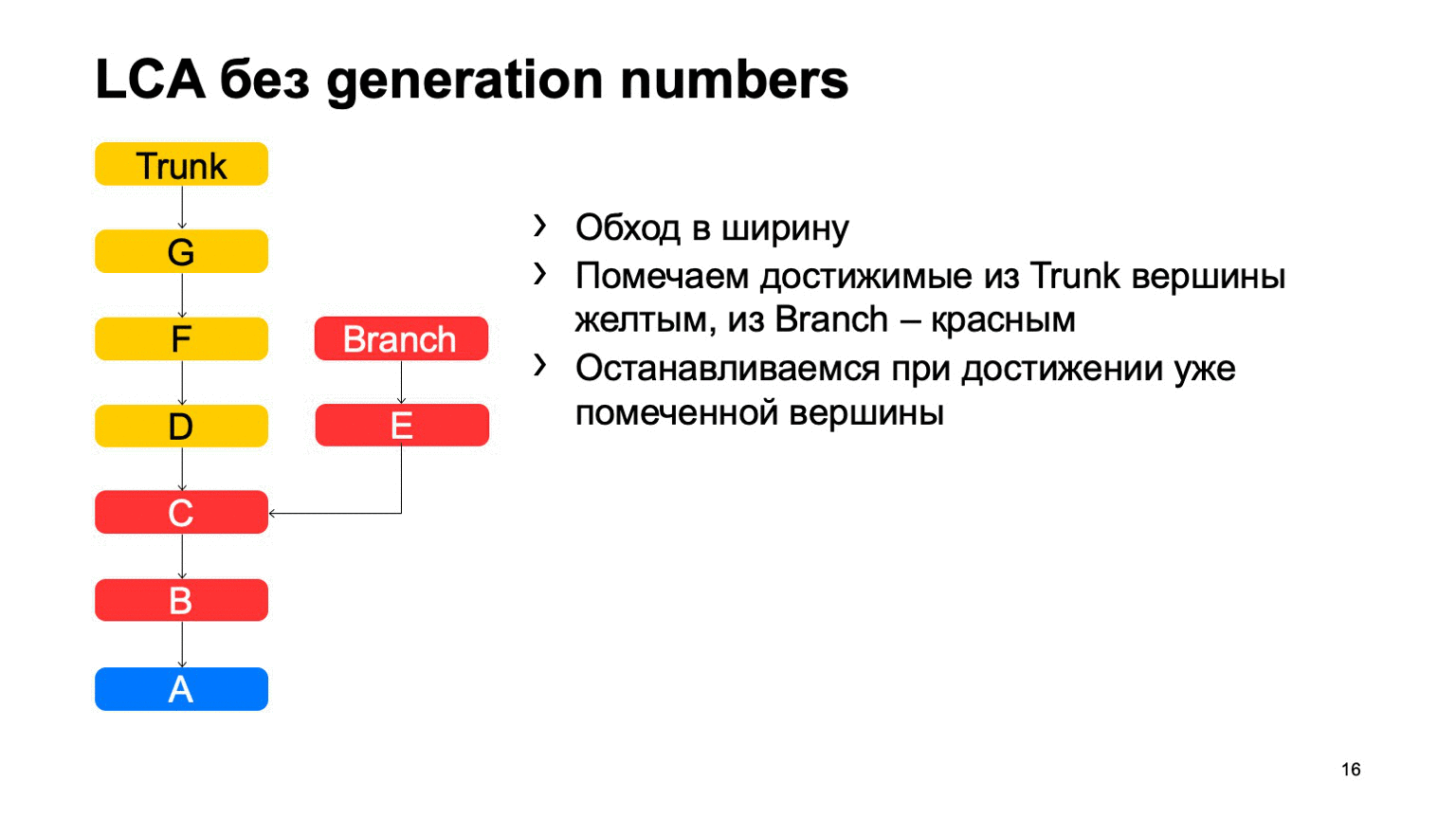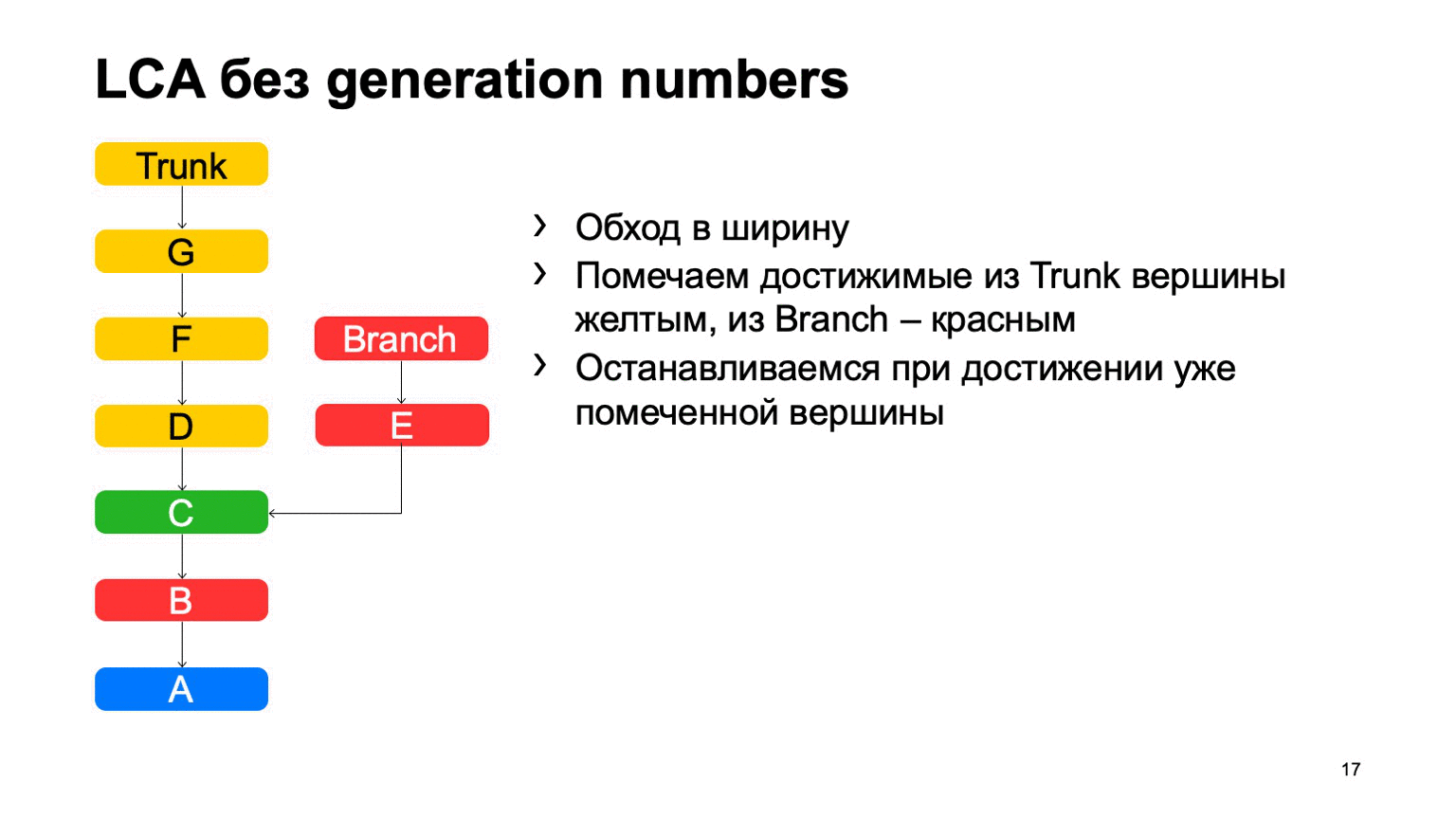
El problema es con B, que es superfluo. Parece que no pudimos entrar, pero lo miramos. Y cuanto más tengamos la diferencia entre una rama y un tronco usando un ejemplo, más confirmaciones adicionales encontraremos. En el caso de un monorepository, cuando la tasa de confirmaciones en un tronco es lo suficientemente alta, esta distancia puede ser muy grande. Y habrá decenas de miles de tales compromisos adicionales.


En el caso de que haya números de generación, podemos usar la cola de prioridad al rastrear, y el rastreo se verá más o menos así: una vez, e inmediatamente encontrará lo que necesita.

Este es un ejemplo de la diferencia entre nuestro modelo. En Git, esto era compatible anteriormente, usaban marcas de tiempo de números de generación, pero esto solo funcionará si los tiempos para crear confirmaciones son consistentes con el gráfico de confirmación.
Desafortunadamente, este no es el caso de nuestro historial de repositorios. Hay confirmaciones que resultan de la migración de otro repositorio, y el tiempo comienza a retroceder en ellas. En Git, esto fue compatible en algún momento, pero no siempre es aplicable allí, porque en Git puede reemplazar el objeto de confirmación con otro localmente. La inmunidad del modelo sufre de esto, por lo tanto, esos números de generación que no se registran, a veces no son aplicables a lo que está escrito en ellos, esto no es cierto. No tenemos tal problema.
Otra ventaja de esta optimización es que es completamente local. Para usar estos números, no necesitamos tener todo el gráfico de compromiso. Y, por lo general, no lo tenemos en absoluto, con nosotros se carga perezosamente. Cuanto menos cargamos perezosamente, mejor vivimos.
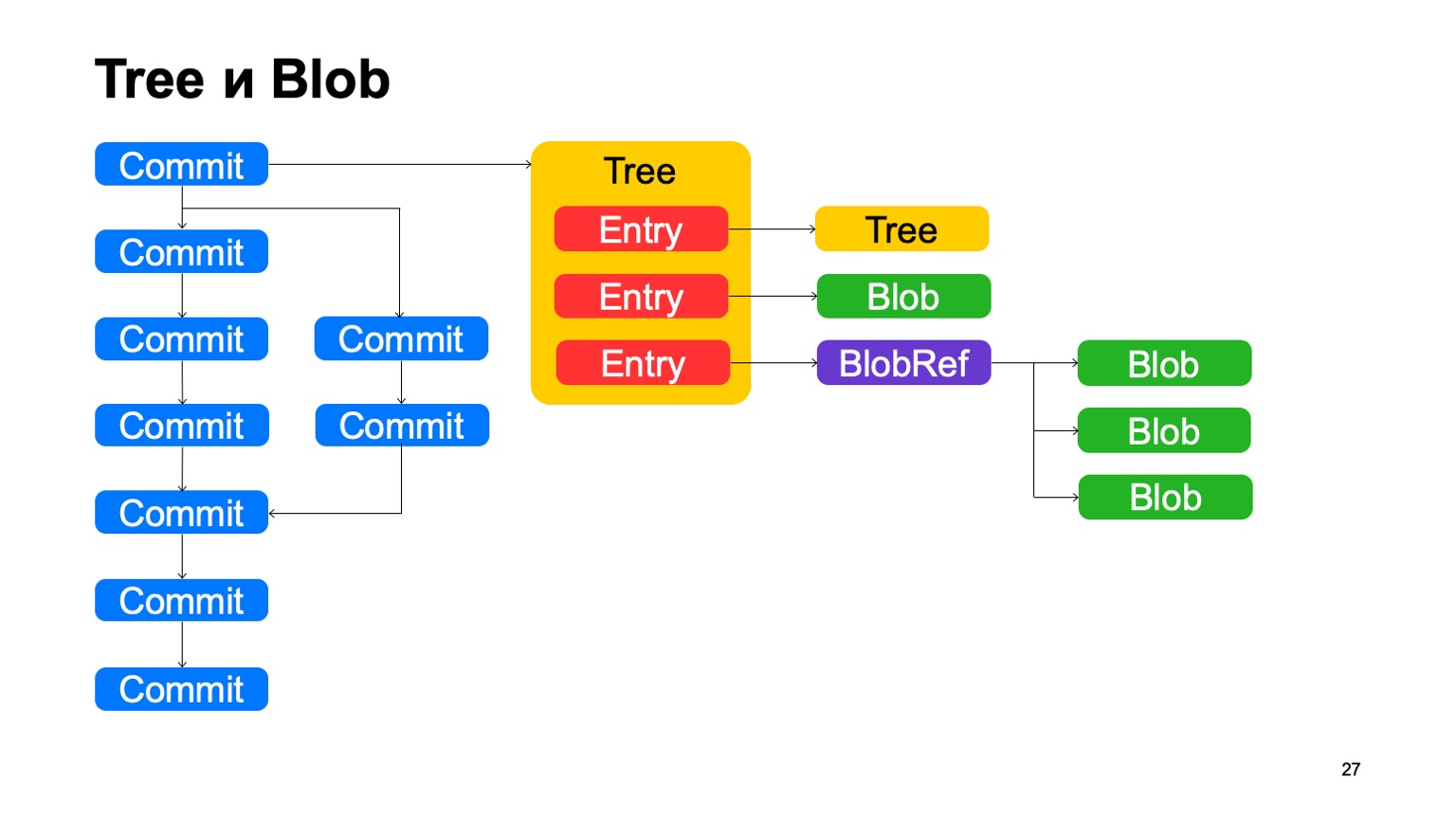
Además de commits, el modelo es muy similar a Git. Cada confirmación apunta a un determinado objeto de árbol, el árbol consta de registros, cada registro es otro árbol, y así es como se muestra la jerarquía de directorios en nosotros, o esto es un blob, algún archivo. Además, tenemos algo como BlobRef, cuando el archivo es muy grande, lo dividimos en pedazos y lo presentamos en un objeto especial. Eso es todo, como en Git.

¿Qué no nos gusta en Git? A esto le llamamos copy-info. Si el archivo se copió en algún tipo de confirmación, Git no guarda esta información de ninguna manera, y luego intenta restaurarla con heurística cuando muestra diferencias y estados. Guardamos esta información en el gráfico. Los registros pueden tener algún enlace de información de copia a otra confirmación, a la ruta dentro del repositorio en esta confirmación, por lo que sabemos que este archivo se copió en esta confirmación.
También hay deduplicación, ya que, por otro lado, este blob se almacena una vez. Pero la deduplicación sería la misma, porque el contenido del archivo no cambió; habría sido deduplicado por hash.
¿Cómo se organizan los backends? Si Git tiene un sistema de control de versiones distribuido, no necesita backends. Sentimos esto especialmente cuando GitHub está caído. Entendemos claramente que Git no necesita backends. Nuestro sistema es cliente-servidor, almacena todos los datos en el servidor y se necesita disponibilidad del servidor para descargar aquellos objetos que aún no están en el cliente.

Todos los datos que almacenamos en la base de datos Yandex. Esta es una base de datos muy interesante que proporciona la transacción, el nivel necesario de confiabilidad. Tiene todo lo que necesitamos, y esto nos salvó de muchos problemas.
Gracias a esto, los backends en sí mismos son completamente apátridas, todo el estado está en la base de datos y los backends podemos escalar fácilmente todo lo que necesitamos.
Y para la interacción que con los clientes, la del interservidor, usamos gRPC, hoy hubo un informe detallado al respecto.
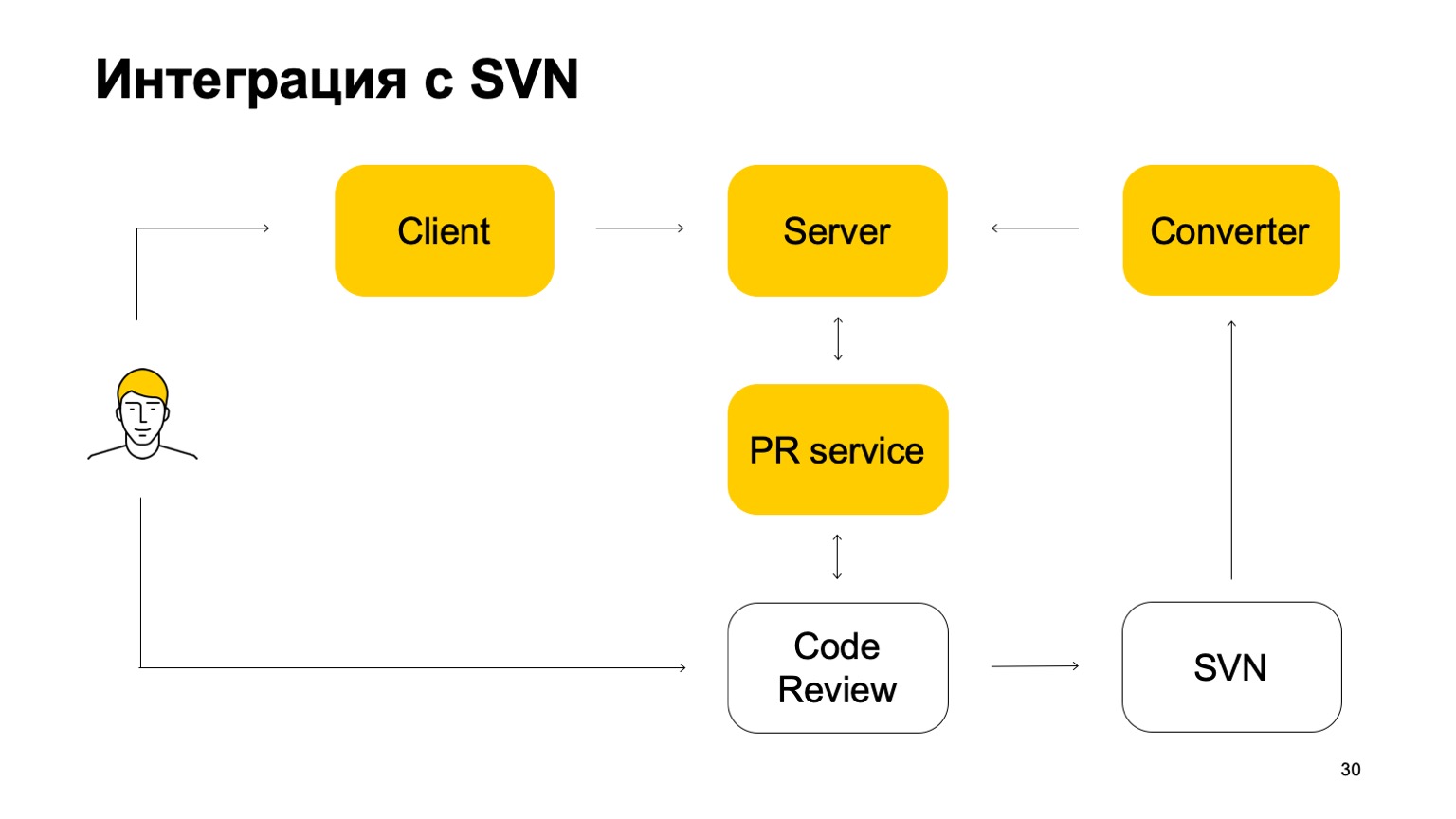
¿Cómo se integra nuestro sistema con SVN? El repositorio SVN continúa vivo. Además, nuestro sistema de control de versiones aún no es autosuficiente. ¿Cómo trabaja ella en esta parte? Inicialmente, hay algún componente Convertidor que monitorea el estado del repositorio SVN y convierte las confirmaciones SVN en confirmaciones Arc: nuestro sistema de control de versiones.
A continuación, hay un cliente que monta una copia de trabajo y va al servidor para obtener datos. Cuando un desarrollador confirma algo, primero se envía al servidor Arc, pero para que estos cambios vayan a troncal, nuestra rama principal, deben pasar por el sistema de solicitud de grupo y el sistema de revisión de código. Aquí viene otro servicio que monitorea las ramas de Arc, y si se actualizan, envía una solicitud de grupo a nuestra revisión del código del sistema. El siguiente es el sistema de revisión de código, cuando se decide que este parche debe fusionarse, lo confirma en SVN. No del todo simple: agrega una cierta cantidad de metadatos allí que esta confirmación es en realidad una fusión de tal y tal rama de Arc. Y luego este commit ya ve el convertidor, encuentra estos metadatos en él y crea un commit en el servidor Arc. Este es el ciclo de commits. Por lo tanto, si bien no podemos vivir sin SVN, porque tenemos troncal en SVN.
La rama principal está constantemente sincronizada con nuestro servidor, pero no permitimos comprometernos directamente con ella.

Sobre la fiabilidad de los backends. Por supuesto, planeamos que todos los desarrolladores de Yandex usen esta cosa, por lo que es importante para nosotros que no se rompa. Este es un estándar dentro del índice: nuestros servicios deben sobrevivir a la falla de cualquier centro de datos. El sistema de control de versiones no es una excepción. Aquí, nos salva enormemente el hecho de que YDB lo admite. Y nuestros backends no tienen estado, hay diferentes partes implementadas de maneras ligeramente diferentes. Los servidores que operan en objetos Arc operan en ramas, no tienen estado, se replican. Los convertidores que convierten constantemente desde SVN se replican de acuerdo con el esquema activo-activo. Hay varios convertidores trabajando simultáneamente, se convierten al mismo tiempo, y en el momento en que intentan actualizar la rama Arc, resuelven los conflictos. Uno tuvo éxito, el otro falló. Él está tratando de convertir algo más.
El servicio de solicitud de agrupación es replicado por maestro-esclavo. Hay uno principal funcionando. Si falla, se selecciona uno nuevo a través de YDB. Hay algo tan maravilloso como los semáforos, que tienen serias garantías de accesibilidad y fiabilidad. Los accesos a los semáforos están completamente serializados. Utilizamos semáforos tanto para el servicio de descubrimiento de solicitud de grupo como para seleccionar líderes.
Un poco sobre cómo funciona el cliente. Esta es la parte más difícil de nuestro sistema de control de versiones, porque hay un sistema de archivos virtual. De hecho, nos vemos obligados a implementar todas las operaciones en los archivos por nuestra cuenta. Revisaré algunas operaciones básicas, describiré con los dedos lo que sucede dentro cuando las hacemos.

Por ejemplo, abrimos un archivo para grabar. Cuando abrimos el archivo para escribir, encontramos el blob correspondiente de nuestro modelo de objetos. Si es necesario, suba algo del servidor. Si creamos físicamente un archivo en una tienda especial, todas las solicitudes adicionales que se dirijan a este archivo se enviarán por proxy allí. Por lo tanto, hasta que se confirmen los cambios localizados (en Git se llama sin etapas), se almacenan temporalmente. Llamamos a tales archivos materializados.

Si abrimos el archivo para leer, entonces no podemos materializar nada, sino simplemente dar datos directamente desde nuestro blob.

Este es el momento en que agregamos el archivo al índice. En este punto, debe ver si tenemos algo materializado. ¿Hay un archivo que ha cambiado? Si es así, cree un blob para él y guárdelo en el índice.

La siguiente operación es el estado del arco. Es interesante porque es lo que en los sistemas de control de versiones convencionales en tales tamaños es lento, porque tiene que atravesar todo el árbol de archivos. No tenemos que recorrer todo el árbol de archivos, porque todas las solicitudes de cambio de archivos pasan por nuestro controlador de fusibles, e inmediatamente sabemos qué archivos vale la pena verificar si hay cambios. Verificamos lo que logramos escribir en el índice e imprimimos la respuesta.

Comprometer el tiempo Todo parece estar claro. Hay un índice, ya hemos creado blobs para estos objetos, crear objetos de árbol que corresponden a este estado, crear un nuevo objeto de confirmación, escribirlo en el almacenamiento de objetos.

A continuación, cambiamos la copia de trabajo a la nueva confirmación. Esta es una operación complicada, claramente se puede hacer con el comando de pago. Y aquí puede pensar que todos nuestros cambios locales parecen haberse materializado, podemos suponer que deberíamos devolver los archivos que no se materializan a partir de nuevas confirmaciones. Y eso es todo. Todas las operaciones posteriores se envían simplemente a otro árbol y blobs.

¿Por qué podría no funcionar esto? La primera versión fue sobre esto. El problema está en todo tipo de operaciones complicadas como el restablecimiento de arco –soft. Nos cambian un interruptor de árbol, pero no materializan archivos. Siguen existiendo en algún lugar sagrado. También tenemos archivos sin seguimiento e ignorados, que también deben procesarse de manera especial. En este lugar, recolectamos muchos rastrillos y finalmente llegamos a la conclusión de que todavía necesitamos tomar un árbol (ahora una copia de trabajo) durante el proceso de pago, tomar el árbol del compromiso al que nos estamos cambiando, tomar el índice y ponerlo en orden. espera
Pero en términos de la complejidad de los algoritmos, no perdimos nada aquí: todos estos árboles de cambios locales son proporcionales a los cambios que hicimos. Por lo tanto, no deberíamos recorrer todo el repositorio con estas operaciones, todavía funcionan bastante rápido.
Al mismo tiempo, estamos haciendo algo de magia para que las marcas de tiempo que le damos a los archivos sean más o menos correctas. Si solo almacenamos archivos en el sistema de archivos, lo controla y el tiempo siempre avanza. Aquí nosotros mismos debemos recordar de alguna manera qué archivo vio el usuario en qué momento. Y si cambió a una confirmación anterior, no empiece a darle una oportunidad anterior. Debido a que los sistemas de ensamblaje, todos los IDE no están listos para esto, eliminan muchas cosas.

En nuestro sistema de control de versiones, el soporte para el desarrollo basado en troncales está clavado. En primer lugar, lo que ya he dicho: todos los cambios pasan por las solicitudes de grupo y el enlace troncal. Hay un par de puntos más. No tenemos soporte de sucursal grupal. Las ramas creadas en Arc están vinculadas a un usuario específico, y solo él puede comprometerse allí. Esto nos permite evitar ramas de larga vida. En SVN, esto no fue particularmente porque allí es inconveniente hacer ramas. Y es conveniente hacerlos en Arc, y si esto no se controla, tememos que algunas partes de nuestro mono-repositorio se irán a sus ramas y llevarán a cabo su desarrollo allí. Esto es contrario al modelo que queremos hacer.

En segundo lugar, no tenemos un comando de fusión. Todas las fusiones de sucursales se producen bajo nuestro estricto control. Ahora estamos desarrollando sucursales para lanzamientos, en los que también será posible fusionar. Esto también será llevado a cabo no por algún equipo de usuarios, sino por la maquinaria del servidor, muy probablemente.

¿Cuales son nuestros planes? El 20% de los desarrolladores de monorepository ya utilizan nuestro sistema de control de versiones. Ya hemos salido de algún tipo de estado infantil, este es un sistema muy utilizado, es simplemente imposible descartarlo así. El objetivo final es convertirse en el principal sistema de control de versiones en Yandex. De alguna manera debemos convencer al 80% restante de los desarrolladores de que somos bastante estables, confiables y utilizables. Está claro que para esto necesita corregir todos los errores y finalizar las funciones que están en Git.
Naturalmente, en cierta perspectiva, planeamos volvernos autosuficientes, abandonar el convertidor o implementarlo en la dirección opuesta, de modo que primero todos los cambios vayan a Arc, y luego a SVN para los programadores más persistentes.
Ahora tenemos un gran desafío: la integración del sistema de control de versiones en nuestro ensamblaje automático, en nuestro CI y otras tuberías. El desafío es que las personas son débiles en espíritu, escriben código lentamente y se comprometen lentamente. Y se descargan el código demasiado lentamente. Y los robots se ven privados de este inconveniente.
— , CI Arc, - . , . . , ++- , , . .
. « Git». : Git. , , .
. Git . , . - . , checkout reset, . , , . : Git. « , ». Git .
. Git, git begin-wave-stash?
:
— .
— , Git ? — , , , . , . Git . , . Gracias