 ¡Solo duele por primera vez!
¡Solo duele por primera vez!Hola a todos! Queridos amigos, en este artículo quiero compartir mi experiencia usando TensorRT, RetinaNet basado en el repositorio
github.com/aidonchuk/retinanet-examples (esta es una bifurcación de la llave en mano oficial de
nvidia , que nos permitirá comenzar a usar modelos optimizados en producción lo antes posible).
Al desplazarme por los canales de la comunidad
ods.ai , me encuentro con preguntas sobre el uso de TensorRT, y la mayoría de las preguntas se repiten, así que decidí escribir
una guía lo
más completa posible para usar una inferencia rápida basada en TensorRT, RetinaNet, Unet y Docker.
Descripción de la tareaPropongo configurar la tarea de esta manera: necesitamos marcar el conjunto de datos, entrenar la red RetinaNet / Unet en Pytorch1.3 +, convertir los pesos recibidos a ONNX, luego convertirlos al motor TensorRT y ejecutar todo esto en Docker, preferiblemente en Ubuntu 18 y extremadamente preferiblemente en arquitectura ARM (Jetson) *, minimizando así la implementación manual del entorno. Como resultado, tendremos un contenedor listo no solo para la exportación y capacitación de RetinaNet / Unet, sino también para el desarrollo completo y capacitación de clasificación, segmentación con todos los enlaces necesarios.
Etapa 1. Preparación del medio ambiente.Es importante tener en cuenta aquí que recientemente abandoné por completo el uso y la implementación de al menos algunas bibliotecas en la máquina de escritorio, así como en devbox. Lo único que debe crear e instalar es el entorno virtual de python y cuda 10.2 (puede restringirse a un solo controlador nvidia) de deb.
Supongamos que tiene un Ubuntu 18. recién instalado. Instale cuda 10.2 (deb), no me detendré en el proceso de instalación en detalle, la documentación oficial es suficiente.
Ahora instale docker, la guía de instalación de docker se puede encontrar fácilmente, aquí hay un ejemplo
www.digitalocean.com/community/tutorials/docker-ubuntu-18-04-1-en , la versión 19+ ya está disponible - póngala. Bueno, no olvides hacer posible el uso de docker sin sudo, será más conveniente. Después de que todo resultó, hacemos así:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.imtqy.com/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.imtqy.com/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker
Y ni siquiera tiene que buscar en el repositorio oficial
github.com/NVIDIA/nvidia-docker .
Ahora haga git clone
github.com/aidonchuk/retinanet-examples .
Sigue siendo solo un poco, para comenzar a usar Docker con nvidia-image, debemos registrarnos en NGC Cloud e iniciar sesión. Entramos aquí
ngc.nvidia.com , nos registramos y, una vez que
ingresamos a NGC Cloud, presionamos SETUP en la esquina superior izquierda de la pantalla o seguimos este enlace
ngc.nvidia.com/setup/api-key . Haga clic en "generar clave". Recomiendo guardarlo, de lo contrario, la próxima vez que lo visite, tendrá que regenerarlo y, en consecuencia, desplegarlo en una nueva carretilla, repetir esta operación.
Ejecutar:
docker login nvcr.io Username: $oauthtoken Password: <Your Key> -
Nombre de usuario solo copia. Bueno, considere, ¡el entorno está implementado!
Etapa 2. Montaje del contenedor acoplableEn la segunda etapa de nuestro trabajo, ensamblaremos la ventana acoplable y nos familiarizaremos con su interior.
Vayamos a la carpeta raíz relativa al proyecto retina-examples y ejecutemos
docker build --build-arg USER=$USER --build-arg UID=$UID --build-arg GID=$GID --build-arg PW=alex -t retinanet:latest retinanet/
Recopilamos la ventana acoplable lanzando al usuario actual; esto es muy útil si escribe algo en un VOLUMEN montado con los derechos del usuario actual, de lo contrario habrá raíz y dolor.
Mientras Docker va, exploremos el Dockerfile:
FROM nvcr.io/nvidia/pytorch:19.10-py3 ARG USER=alex ARG UID=1000 ARG GID=1000 ARG PW=alex RUN useradd -m ${USER} --uid=${UID} && echo "${USER}:${PW}" | chpasswd RUN apt-get -y update && apt-get -y upgrade && apt-get -y install curl && apt-get -y install wget && apt-get -y install git && apt-get -y install automake && apt-get install -y sudo && adduser ${USER} sudo RUN pip install git+https://github.com/bonlime/pytorch-tools.git@master COPY . retinanet/ RUN pip install --no-cache-dir -e retinanet/ RUN pip install /workspace/retinanet/extras/tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl RUN pip install tensorboardx RUN pip install albumentations RUN pip install setproctitle RUN pip install paramiko RUN pip install flask RUN pip install mem_top RUN pip install arrow RUN pip install pycuda RUN pip install torchvision RUN pip install pretrainedmodels RUN pip install efficientnet-pytorch RUN pip install git+https://github.com/qubvel/segmentation_models.pytorch RUN pip install pytorch_toolbelt RUN chown -R ${USER}:${USER} retinanet/ RUN cd /workspace/retinanet/extras/cppapi && mkdir build && cd build && cmake -DCMAKE_CUDA_FLAGS="--expt-extended-lambda -std=c++14" .. && make && cd /workspace RUN apt-get install -y openssh-server && apt install -y tmux && apt-get -y install bison flex && apt-cache search pcre && apt-get -y install net-tools && apt-get -y install nmap RUN apt-get -y install libpcre3 libpcre3-dev && apt-get -y install iputils-ping RUN mkdir /var/run/sshd RUN echo 'root:pass' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile CMD ["/usr/sbin/sshd", "-D"]
Como puede ver en el texto, tomamos todos nuestros favoritos, compilamos retinanet, distribuimos herramientas básicas para la conveniencia de trabajar con Ubuntu y configuramos el servidor openssh. La primera línea es solo la herencia de la imagen de nvidia, para la cual iniciamos sesión en NGC Cloud y que contiene Pytorch1.3, TensorRT6.xxx y un montón de libs que nos permiten compilar el código fuente de cpp para nuestro detector.
Etapa 3. Inicio y depuración del contenedor acoplablePasemos al caso principal de usar el contenedor y el entorno de desarrollo, para comenzar, ejecute nvidia docker. Ejecutar:
docker run --gpus all --net=host -v /home/<your_user_name>:/workspace/mounted_vol -d -P --rm --ipc=host -it retinanet:latest
Ahora el contenedor está disponible en ssh <curr_user_name> @localhost. Después de un lanzamiento exitoso, abra el proyecto en PyCharm. A continuación, abrir
Settings->Project Interpreter->Add->Ssh Interpreter
Paso 1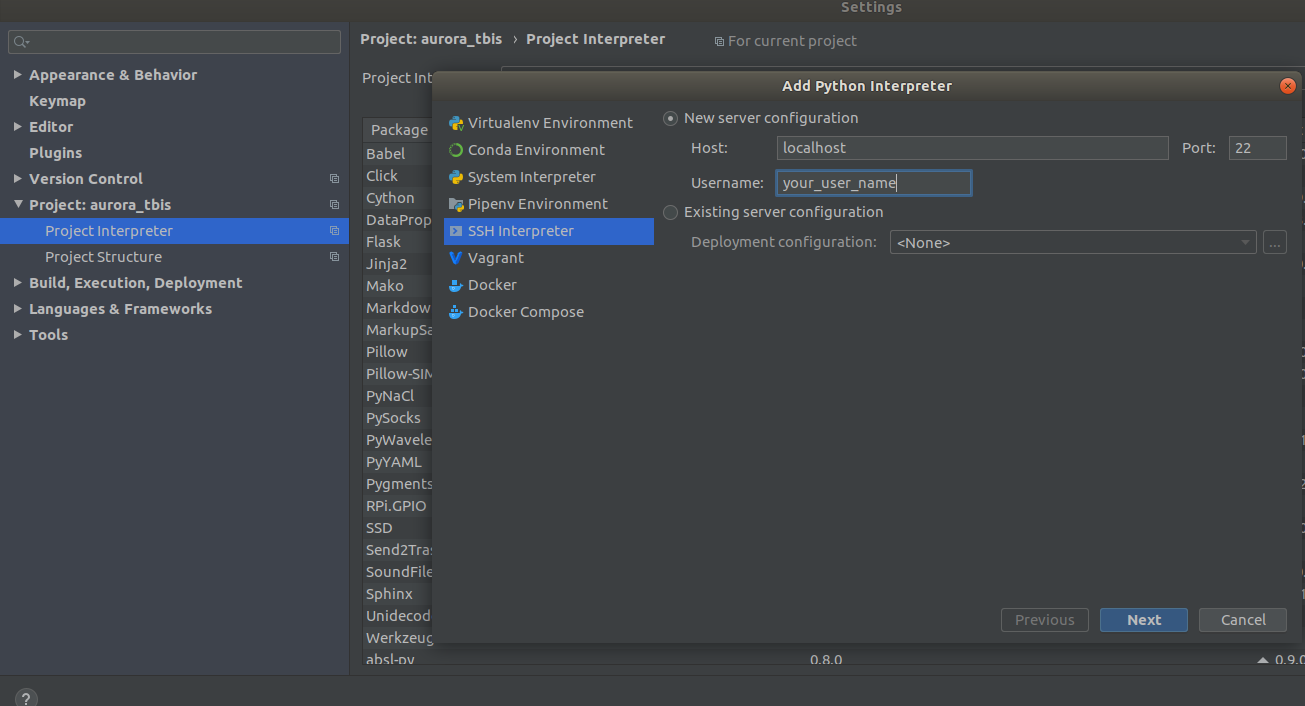 Paso 2
Paso 2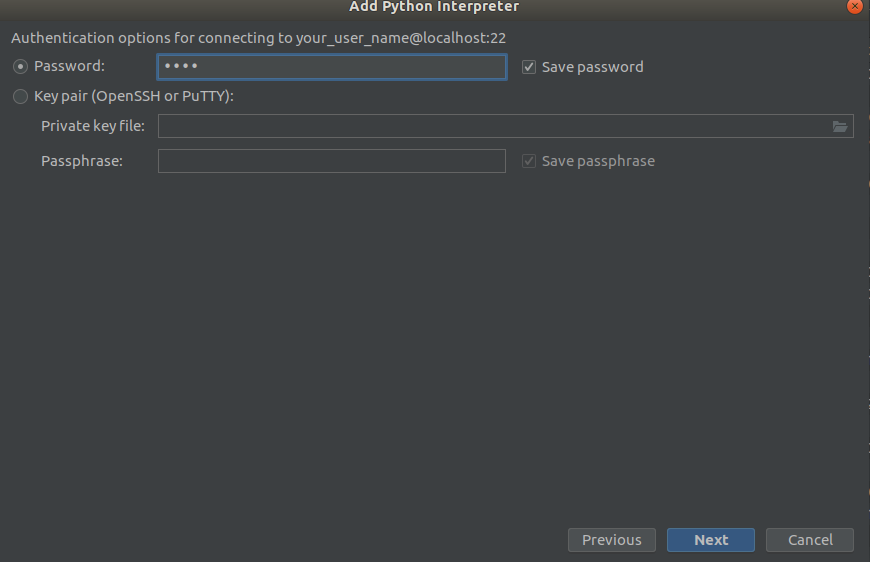 Paso 3
Paso 3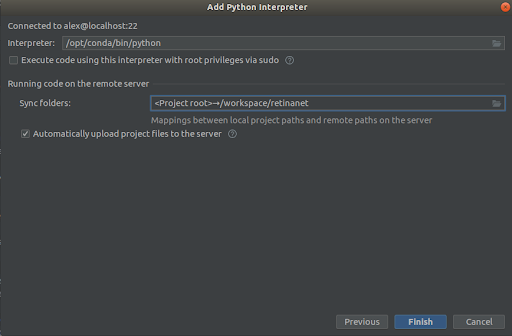
Seleccionamos todo como en las capturas de pantalla,
Interpreter -> /opt/conda/bin/python
- Esto será en Python3.6 y
Sync folder -> /workspace/retinanet
Presionamos la línea de meta, esperamos indexación, y eso es todo, ¡el entorno está listo para usar!
IMPORTANTE !!! Inmediatamente después de la indexación, extraiga los archivos compilados para Retinanet de la ventana acoplable. En el menú contextual en la raíz del proyecto, seleccione
Deployment->Download
Aparecerán un archivo y dos carpetas de compilación, retinanet.egg-info y _so
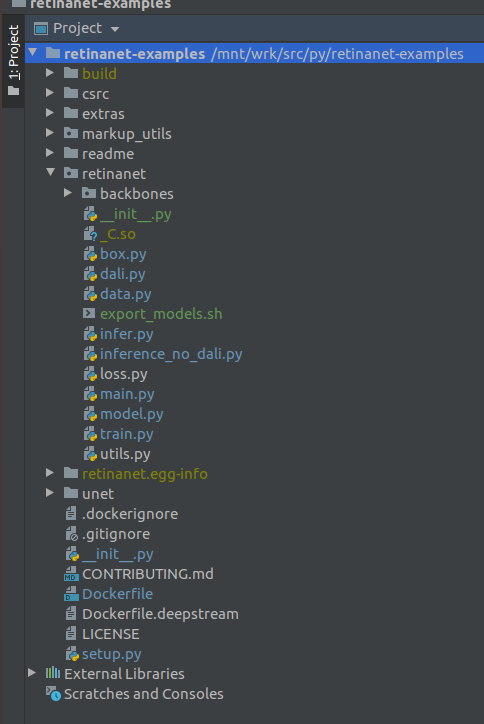
Si su proyecto se ve así, entonces el entorno ve todos los archivos necesarios y estamos listos para aprender RetinaNet.
Etapa 4. Marcado de los datos y entrenamiento del detector.Para el marcado, uso principalmente
supervise.ly , una herramienta agradable y conveniente, en la última vez que se repararon un montón de jambas y se volvió mucho mejor comportamiento.
Supongamos que marcó el conjunto de datos y lo descargó, pero no funcionará de inmediato ponerlo en nuestra RetinaNet, ya que está en su propio formato y para ello necesitamos convertirlo a COCO. La herramienta de conversión está en:
markup_utils/supervisly_to_coco.py
Tenga en cuenta que la Categoría en el script es un ejemplo y necesita insertar la suya propia (no necesita agregar la categoría de fondo)
categories = [{'id': 1, 'name': '1'}, {'id': 2, 'name': '2'}, {'id': 3, 'name': '3'}, {'id': 4, 'name': '4'}]
Por alguna razón, los autores del repositorio original decidieron que no entrenará nada excepto COCO / VOC para la detección, por lo que tuve que modificar ligeramente el archivo fuente
retinanet/dataset.py
Agregue sus albumentations.readthedocs.io/en/plastments aumentados favoritos
allí y recorte las categorías unidas de COCO. También es posible rociar grandes áreas de detección si está buscando objetos pequeños en imágenes grandes, tiene un pequeño conjunto de datos =), y nada funciona, pero más sobre eso en otro momento.
En general, el circuito del tren también es débil, inicialmente no salvó los puntos de control, usó un programador horrible, etc. Pero ahora todo lo que tiene que hacer es seleccionar la columna vertebral y ejecutar
/opt/conda/bin/python retinanet/main.py
con parámetros:
train retinanet_rn34fpn.pth --backbone ResNet34FPN --classes 12 --val-iters 10 --images /workspace/mounted_vol/dataset/train/images --annotations /workspace/mounted_vol/dataset/train_12_class.json --val-images /workspace/mounted_vol/dataset/test/images_small --val-annotations /workspace/mounted_vol/dataset/val_10_class_cropped.json --jitter 256 512 --max-size 512 --batch 32
En la consola verás:
Initializing model... model: RetinaNet backbone: ResNet18FPN classes: 2, anchors: 9 Selected optimization level O0: Pure FP32 training. Defaults for this optimization level are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 1.0 Processing user overrides (additional kwargs that are not None)... After processing overrides, optimization options are: enabled : True opt_level : O0 cast_model_type : torch.float32 patch_torch_functions : False keep_batchnorm_fp32 : None master_weights : False loss_scale : 128.0 Preparing dataset... loader: pytorch resize: [1024, 1280], max: 1280 device: 4 gpus batch: 4, precision: mixed Training model for 20000 iterations... [ 1/20000] focal loss: 0.95619, box loss: 0.51584, 4.042s/4-batch (fw: 0.698s, bw: 0.459s), 1.0 im/s, lr: 0.0001 [ 12/20000] focal loss: 0.76191, box loss: 0.31794, 0.187s/4-batch (fw: 0.055s, bw: 0.133s), 21.4 im/s, lr: 0.0001 [ 24/20000] focal loss: 0.65036, box loss: 0.30269, 0.173s/4-batch (fw: 0.045s, bw: 0.128s), 23.1 im/s, lr: 0.0001 [ 36/20000] focal loss: 0.46425, box loss: 0.23141, 0.178s/4-batch (fw: 0.047s, bw: 0.131s), 22.4 im/s, lr: 0.0001 [ 48/20000] focal loss: 0.45115, box loss: 0.23505, 0.180s/4-batch (fw: 0.047s, bw: 0.133s), 22.2 im/s, lr: 0.0001 [ 59/20000] focal loss: 0.38958, box loss: 0.25373, 0.184s/4-batch (fw: 0.049s, bw: 0.134s), 21.8 im/s, lr: 0.0001 [ 71/20000] focal loss: 0.37733, box loss: 0.23988, 0.174s/4-batch (fw: 0.049s, bw: 0.125s), 22.9 im/s, lr: 0.0001 [ 83/20000] focal loss: 0.39514, box loss: 0.23878, 0.181s/4-batch (fw: 0.048s, bw: 0.133s), 22.1 im/s, lr: 0.0001 [ 94/20000] focal loss: 0.39947, box loss: 0.23817, 0.185s/4-batch (fw: 0.050s, bw: 0.134s), 21.6 im/s, lr: 0.0001 [ 105/20000] focal loss: 0.37343, box loss: 0.20238, 0.182s/4-batch (fw: 0.048s, bw: 0.134s), 22.0 im/s, lr: 0.0001 [ 116/20000] focal loss: 0.19689, box loss: 0.17371, 0.183s/4-batch (fw: 0.050s, bw: 0.132s), 21.8 im/s, lr: 0.0001 [ 128/20000] focal loss: 0.20368, box loss: 0.16538, 0.178s/4-batch (fw: 0.046s, bw: 0.131s), 22.5 im/s, lr: 0.0001 [ 140/20000] focal loss: 0.22763, box loss: 0.15772, 0.176s/4-batch (fw: 0.050s, bw: 0.126s), 22.7 im/s, lr: 0.0001 [ 148/20000] focal loss: 0.21997, box loss: 0.18400, 0.585s/4-batch (fw: 0.047s, bw: 0.144s), 6.8 im/s, lr: 0.0001 Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.52674 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.91450 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.35172 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61881 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.58824 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.61765 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.00000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.00000 Saving model: 148
Para estudiar todo el conjunto de parámetros mira
retinanet/main.py
En general, son estándar para la detección y tienen una descripción. Ejecute el entrenamiento y espere los resultados. Un ejemplo de inferencia se puede encontrar en:
retinanet/infer_example.py
o ejecuta el comando:
/opt/conda/bin/python retinanet/main.py infer retinanet_rn34fpn.pth --images /workspace/mounted_vol/dataset/test/images --annotations /workspace/mounted_vol/dataset/val.json --output result.json --resize 256 --max-size 512 --batch 32
La pérdida focal y varias cadenas principales ya están integradas en el repositorio, y sus
retinanet/backbones/*.py
Los autores dan algunas características en la placa de identificación:
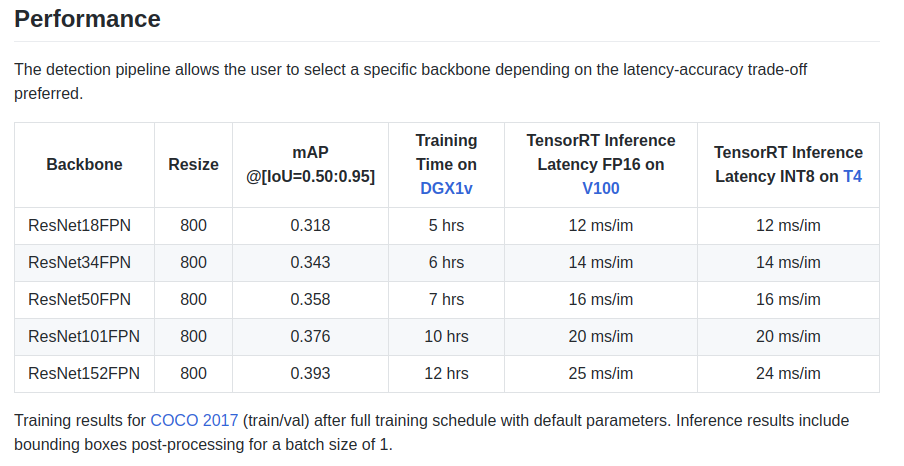
También hay un backbone ResNeXt50_32x4dFPN y ResNeXt101_32x8dFPN, tomado de torchvision.
Espero que hayamos descubierto un poco la detección, pero definitivamente debería leer la documentación oficial para
comprender los modos de exportación y registro .
Etapa 5. Exportación e inferencia de modelos Unet con codificador ResnetComo probablemente haya notado, las bibliotecas para la segmentación se instalaron en el Dockerfile, y en particular la maravillosa biblioteca
github.com/qubvel/segmentation_models.pytorch . En el paquete Yunet, puede encontrar ejemplos de inferencia y exportación de puntos de control de pytorch en el motor TensorRT.
El principal problema al exportar modelos similares a Unet de ONNX a TensoRT es la necesidad de establecer un tamaño fijo de Upsample o usar ConvTranspose2D:
import torch.onnx.symbolic_opset9 as onnx_symbolic def upsample_nearest2d(g, input, output_size):
Con esta conversión, puede hacer esto automáticamente al exportar a ONNX, pero ya en la versión 7 de TensorRT este problema se resolvió y tuvimos que esperar muy poco.
ConclusiónCuando comencé a usar Docker, tenía dudas sobre su rendimiento para mis tareas. En una de mis unidades, ahora hay bastante tráfico de red creado por varias cámaras.
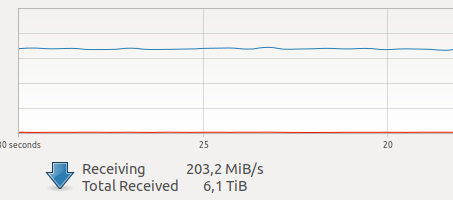
Varias pruebas en Internet revelaron una sobrecarga relativamente grande para la interacción de la red y la grabación en VOLUME, más un GIL desconocido y terrible, y desde que se dispara un cuadro, la operación del controlador y la transmisión de un cuadro a través de una red son operaciones atómicas en modo de
tiempo real difícil , retrasos en línea son muy críticos para mí.
Pero no pasó nada =)
PD: ¡Queda por agregar su circuito de tren favorito para la segmentación y la producción!
GraciasGracias a la comunidad
ods.ai , ¡es imposible desarrollarse sin ella! ¡Muchas gracias a
n01z3 , DL, que deseaba que tomara DL, por su inestimable consejo y extraordinaria profesionalidad!
¡Use modelos optimizados en producción!
Aurorai, llc