Clickhouse es un motor de base de datos del sistema de gestión de bases de datos de consulta analítica de código abierto (OLAP) creado por Yandex. Yandex, CloudFlare, VK.com, Badoo y otros servicios de todo el mundo lo utilizan para almacenar grandes cantidades de datos (inserte miles de líneas por segundo o petabytes de datos almacenados en el disco).
En el DBMS de "cadena" habitual, cuyos ejemplos son MySQL, Postgres, MS SQL Server, los datos se almacenan en este orden:
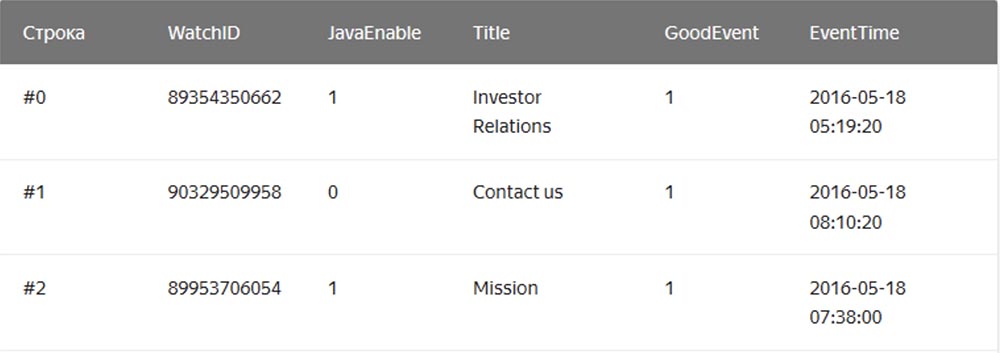
En este caso, los valores relacionados con una fila se almacenan físicamente uno al lado del otro. En un DBMS columnar, los valores de diferentes columnas se almacenan por separado, y los datos de una columna se almacenan juntos:
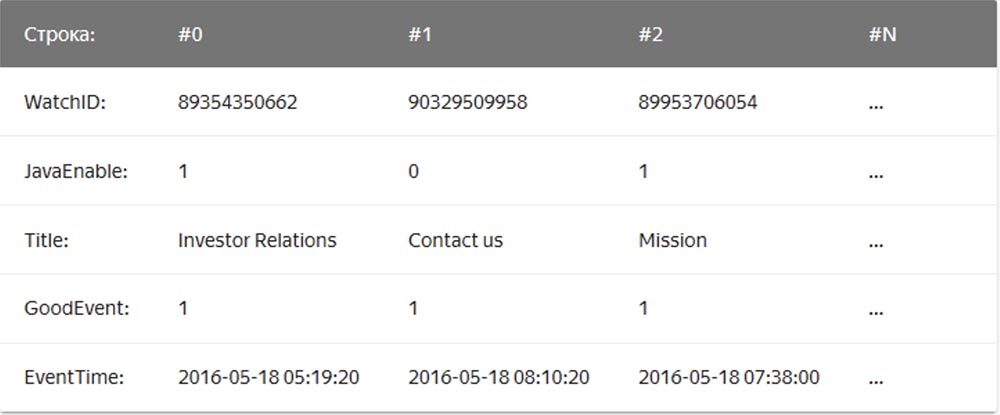
Ejemplos de DBMS en columna son Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb +.
La compañía de
reenvío de correo Qwintry comenzó a usar Clickhouse en 2018 para generar informes y quedó muy impresionada con su simplicidad, escalabilidad, compatibilidad con SQL y velocidad. La velocidad de este DBMS estaba rodeada de magia.
Simplicidad
Clickhouse se instala en Ubuntu con un solo comando. Si conoce SQL, puede comenzar a usar Clickhouse de inmediato para sus necesidades. Sin embargo, esto no significa que pueda ejecutar "show create table" en MySQL y copiar y pegar SQL en Clickhouse.
En comparación con MySQL, en este DBMS hay diferencias importantes de tipos de datos en las definiciones de esquemas de tabla, por lo que para un trabajo cómodo todavía necesita algo de tiempo para cambiar las definiciones del esquema de tabla y estudiar los motores de tabla.
Clickhouse funciona muy bien sin ningún software adicional, pero si desea utilizar la replicación, deberá instalar ZooKeeper. El análisis del rendimiento de las consultas muestra excelentes resultados: las tablas del sistema contienen toda la información y todos los datos se pueden obtener utilizando el antiguo y aburrido SQL.
Rendimiento
- Punto de referencia que compara Clickhouse con Vertica y MySQL en un servidor de configuración: dos zócalos de CPU Intel® Xeon® E5-2650 v2 @ 2.60GHz; 128 GiB RAM; md RAID-5 en 8 6TB SATA HDD, ext4.
- Punto de referencia que compara Clickhouse con el almacenamiento de datos en la nube de Amazon RedShift.
- Extractos del Blog de Cloudflare Clickhouse Performance :

La base de datos ClickHouse tiene un diseño muy simple: todos los nodos del clúster tienen la misma funcionalidad y solo usan ZooKeeper para la coordinación. Creamos un pequeño grupo de varios nodos y realizamos pruebas, durante las cuales descubrimos que el sistema tiene un rendimiento bastante impresionante, que corresponde a las ventajas declaradas en los puntos de referencia de los DBMS analíticos. Decidimos analizar más de cerca el concepto detrás de ClickHouse. El primer obstáculo para la investigación fue la falta de herramientas y el pequeño tamaño de la comunidad ClickHouse, por lo que profundizamos en el diseño de este sistema de administración de bases de datos para comprender cómo funciona.
ClickHouse no admite la recepción de datos directamente de Kafka (en este momento ya sabe cómo hacerlo), ya que es solo una base de datos, por lo que escribimos nuestro propio servicio de adaptador en Go. Leyó los mensajes codificados de Cap'n Proto de Kafka, los convirtió a TSV y los insertó en ClickHouse en lotes a través de la interfaz HTTP. Más tarde, reescribimos este servicio para usar la biblioteca Go junto con nuestra propia interfaz ClickHouse para mejorar el rendimiento. Al evaluar el rendimiento de recibir paquetes, descubrimos algo importante: resultó que en ClickHouse este rendimiento depende en gran medida del tamaño del paquete, es decir, el número de filas insertadas al mismo tiempo. Para comprender por qué sucede esto, examinamos cómo ClickHouse almacena datos.
El motor principal, o más bien, la familia de motores de mesa utilizados por ClickHouse para almacenar datos, es MergeTree. Este motor es conceptualmente similar al algoritmo LSM utilizado por Google BigTable o Apache Cassandra, pero evita construir una tabla de memoria intermedia y escribe datos directamente en el disco. Esto le proporciona un excelente rendimiento de escritura, ya que cada paquete insertado se clasifica solo por la clave primaria de "clave primaria", se comprime y se escribe en el disco para formar un segmento.
La ausencia de una tabla de memoria o cualquier concepto de "actualización" de los datos también significa que solo se pueden agregar; el sistema no admite cambiarlos ni eliminarlos. Hoy, la única forma de eliminar datos es eliminarlos por meses calendario, ya que los segmentos nunca cruzan el límite del mes. El equipo de ClickHouse está trabajando activamente para que esta característica sea personalizable. Por otro lado, esto hace que la grabación y fusión de segmentos sea perfecta, por lo que el ancho de banda de recepción se escala linealmente con el número de inserciones paralelas hasta que las E / S o los núcleos estén saturados.
Sin embargo, este hecho también significa que el sistema no es adecuado para paquetes pequeños, por lo tanto, los servicios e inserciones de Kafka se utilizan para el almacenamiento en búfer. Además, ClickHouse en el fondo continúa realizando constantemente la fusión de segmentos, de modo que muchas pequeñas piezas de información se combinarán y grabarán más veces, aumentando así la intensidad de grabación. En este caso, demasiadas partes no relacionadas causarán un estrangulamiento agresivo de los insertos mientras continúe la fusión. Descubrimos que el mejor compromiso entre la recepción de datos en tiempo real y el rendimiento de la recepción es recibir un número limitado de inserciones por segundo en la tabla.
La clave para el rendimiento de lectura de tablas es la indexación y el posicionamiento de datos en el disco. Independientemente de cuán rápido sea el procesamiento, cuando el motor necesite escanear terabytes de datos del disco y usar solo una parte de ellos, llevará tiempo. ClickHouse es un almacén de columnas, por lo que cada segmento contiene un archivo para cada columna (columna) con valores ordenados para cada fila. Por lo tanto, las columnas enteras que no están en la consulta se pueden omitir primero, y luego se pueden procesar varias celdas en paralelo con la ejecución vectorizada. Para evitar una exploración completa, cada segmento tiene un pequeño archivo de índice.
Dado que todas las columnas están ordenadas por "clave principal", el archivo de índice contiene solo las etiquetas (filas capturadas) de cada enésima fila para poder almacenarlas en la memoria incluso para tablas muy grandes. Por ejemplo, puede establecer la configuración predeterminada "marcar cada 8192a fila", luego la indexación "exigua" de la tabla con 1 billón. Las líneas, que se ajustan fácilmente a la memoria, ocuparán solo 122.070 caracteres.
Desarrollo del sistema
El desarrollo y la mejora de Clickhouse se pueden rastrear hasta el
repositorio de Github y asegurarse de que el proceso de "crecimiento" avance a un ritmo impresionante.
Popularidad
Clickhouse parece estar creciendo exponencialmente, especialmente en la comunidad de habla rusa. La conferencia del año pasado High load 2018 (Moscú, del 8 al 9 de noviembre de 2018) mostró que monstruos como vk.com y Badoo usan Clickhouse, con el que pegan datos (por ejemplo, registros) de decenas de miles de servidores al mismo tiempo. En un video de 40 minutos,
Yuri Nasretdinov del equipo VKontakte habla sobre cómo se hace esto . Pronto publicaremos la transcripción en Habr para la conveniencia de trabajar con el material.
Áreas de aplicación
Después de pasar un tiempo investigando, creo que hay áreas en las que ClickHouse puede ser útil o capaz de reemplazar por completo otras soluciones más tradicionales y populares, como MySQL, PostgreSQL, ELK, Google Big Query, Amazon RedShift, TimescaleDB, Hadoop, MapReduce, Pinot y Druid. Los siguientes son detalles sobre el uso de ClickHouse para actualizar o reemplazar por completo los DBMS anteriores.
Extendiendo MySQL y PostgreSQL
Más recientemente, reemplazamos parcialmente MySQL con ClickHouse para la
plataforma de boletines informativos Mautic . El problema era que MySQL, debido a su diseño mal concebido, registraba cada correo electrónico enviado y cada enlace en este correo electrónico con un hash base64, creando una gran tabla MySQL (email_stats). Después de enviar solo 10 millones de cartas a los suscriptores del servicio, esta tabla ocupaba 150 GB de espacio de archivos, y MySQL comenzó a "aburrirse" en consultas simples. Para solucionar el problema del espacio de archivos, utilizamos con éxito la compresión de la tabla InnoDB, que la redujo 4 veces. Sin embargo, todavía no tiene sentido almacenar más de 20-30 millones de correos electrónicos en MySQL solo por el simple hecho de leer la historia, ya que cualquier consulta simple que, por alguna razón, necesite realizar un escaneo completo conduce a un intercambio y una gran carga de E / S, por sobre el cual recibimos regularmente advertencias de Zabbix.

Clickhouse utiliza dos algoritmos de compresión que reducen la cantidad de datos en aproximadamente
3-4 veces , pero en este caso particular los datos fueron especialmente "comprimibles".

Reemplazo ELK
Según nuestra propia experiencia, la pila ELK (ElasticSearch, Logstash y Kibana, en este caso particular, ElasticSearch) requiere muchos más recursos para ejecutar de lo que es necesario para almacenar registros. ElasticSearch es un gran motor si necesita una buena búsqueda de registro de texto completo (y no creo que realmente lo necesite), pero me pregunto por qué de hecho se ha convertido en el motor de registro estándar. Su rendimiento de recepción en combinación con Logstash nos creó problemas incluso con cargas bastante pequeñas y requirió la adición de una cantidad creciente de RAM y espacio en disco. Como base de datos, Clickhouse es mejor que ElasticSearch por las siguientes razones:
- Soporte de dialecto SQL;
- La mejor relación de compresión de datos almacenados;
- Soporte para búsquedas de expresiones regulares de expresiones regulares en lugar de búsquedas de texto completo;
- Planificación de consultas mejorada y mayor rendimiento general.
Actualmente, el mayor problema que surge al comparar ClickHouse con ELK es la falta de soluciones para los registros de envío, así como la falta de documentación y ayudas de capacitación sobre este tema. Al mismo tiempo, cada usuario puede configurar ELK utilizando la Guía Digital del Océano, que es muy importante para la rápida implementación de dichas tecnologías. Aquí hay un motor de base de datos, pero todavía no hay Filebeat para ClickHouse. Sí, hay un sistema
fluido para trabajar con registros de
loghouse , hay una herramienta de
cola de clic para ingresar archivos de registro en ClickHouse, pero todo esto lleva más tiempo. Sin embargo, ClickHouse todavía lidera debido a su simplicidad, por lo que incluso los principiantes lo instalan de manera primaria y comienzan a usarlo completamente en solo 10 minutos.
Prefiriendo soluciones minimalistas, intenté usar FluentBit, una herramienta para enviar registros con una cantidad muy pequeña de memoria, junto con ClickHouse, mientras intentaba evitar usar Kafka. Sin embargo, las incompatibilidades menores, como los
problemas de formato de fecha , deben corregirse antes de que esto se pueda hacer sin una capa proxy que convierta los datos de FluentBit a ClickHouse.
Como alternativa a Kibana, puede usar
Grafana como el
backend de ClickHouse. Según tengo entendido, esto puede causar problemas de rendimiento al representar una gran cantidad de puntos de datos, especialmente con versiones anteriores de Grafana. En Qwintry, aún no lo hemos intentado, pero de vez en cuando aparecen quejas sobre esto en el canal de soporte ClickHouse en Telegram.
Sustitución de Google Big Query y Amazon RedShift (solución para grandes empresas)
El caso de uso ideal para BigQuery es descargar 1 TB de datos JSON y realizar consultas analíticas sobre ellos. Big Query es un gran producto cuya escalabilidad es difícil de sobreestimar. Este es un software mucho más complejo que ClickHouse, que se ejecuta en un clúster interno, pero desde el punto de vista del cliente, tiene mucho en común con ClickHouse. BigQuery puede subir de precio rápidamente tan pronto como pague por cada SELECT, por lo que esta es una solución SaaS real con todas sus ventajas y desventajas.
ClickHouse es la mejor opción cuando realiza muchas consultas computacionalmente costosas. Cuantas más consultas SELECT ejecute cada día, más sentido tiene reemplazar Big Query con ClickHouse, porque dicho reemplazo le ahorrará miles de dólares cuando se trata de muchos terabytes de datos procesados. Esto no se aplica a los datos almacenados, que es bastante barato de procesar en Big Query.
El artículo del cofundador de Altinity, Alexander Zaitsev,
"Cambiando a ClickHouse", habla sobre los beneficios de tal migración de DBMS.
Sustitución de TimescaleDB
TimescaleDB es una extensión PostgreSQL que optimiza el trabajo con series de tiempo en una base de datos regular (
https://docs.timescale.com/v1.0/introduction ,
https://habr.com/en/company/zabbix/blog/458530 / ).
Aunque ClickHouse no es un competidor serio en el nicho de series temporales, pero la estructura de columnas y la ejecución vectorial de consultas, en la mayoría de los casos de procesamiento de consultas analíticas, es mucho más rápido que TimescaleDB. Al mismo tiempo, el rendimiento de recibir datos de paquetes ClickHouse es aproximadamente 3 veces mayor, además, utiliza 20 veces menos espacio en disco, lo cual es realmente importante para procesar grandes cantidades de datos históricos:
https://www.altinity.com/blog/ClickHouse-for -tiempo-serie .
A diferencia de ClickHouse, la única forma de ahorrar espacio en disco en TimescaleDB es usar ZFS o sistemas de archivos similares.
Es probable que las próximas actualizaciones de ClickHouse introduzcan la compresión delta, lo que lo hará aún más adecuado para procesar y almacenar datos de series temporales. TimescaleDB puede ser una mejor opción que un ClickHouse desnudo en los siguientes casos:
- instalaciones pequeñas con una cantidad muy pequeña de RAM (<3 GB);
- una gran cantidad de INSERT pequeños que no desea almacenar en fragmentos grandes;
- mejor consistencia, uniformidad y requisitos de ACID;
- Soporte PostGIS;
- fusionándose con las tablas existentes de PostgreSQL, ya que Timescale DB es esencialmente PostgreSQL.
Competencia con los sistemas Hadoop y MapReduce
Hadoop y otros productos MapReduce pueden realizar muchos cálculos complejos, pero generalmente funcionan con grandes retrasos. ClickHouse soluciona este problema al procesar terabytes de datos y entregar resultados casi instantáneamente. Por lo tanto, ClickHouse es mucho más eficiente para realizar una investigación analítica rápida e interactiva, lo que debería ser interesante para los especialistas en procesamiento de datos.
Competencia con Pinot y Druida
Los competidores más cercanos de ClickHouse son Pinot y Druid, un producto de código abierto columnar escalable linealmente. Un excelente trabajo al comparar estos sistemas fue publicado en un artículo de
Roman Leventov del 1 de febrero de 2018.
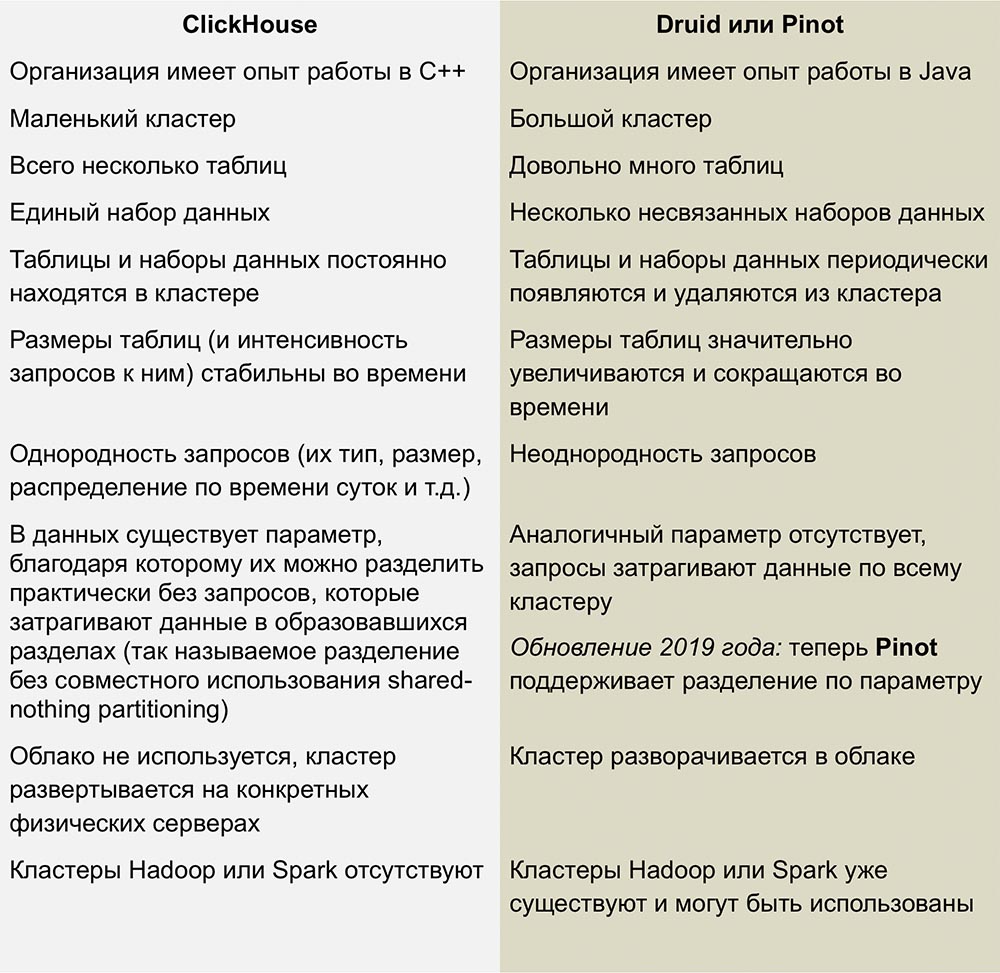
Este artículo requiere actualización: establece que ClickHouse no admite las operaciones ACTUALIZAR y ELIMINAR, lo cual no es del todo cierto para las últimas versiones.
No tenemos suficiente experiencia con estos DBMS, pero no me gusta la complejidad de la infraestructura utilizada para ejecutar Druid y Pinot: se trata de un montón de "partes móviles" rodeadas de Java por todos lados.
Druid y Pinot son proyectos de incubadoras de Apache, cuyo progreso de desarrollo está cubierto en detalle por Apache en las páginas de sus proyectos de GitHub. Pinot apareció en la incubadora en octubre de 2018, y Druid nació 8 meses antes, en febrero.
La falta de información sobre cómo funciona AFS me da algunas, y quizás preguntas tontas. Me pregunto si los autores de Pinot notaron que la Fundación Apache está más dispuesta hacia los druidas, ¿y esta actitud hacia el competidor causó envidia? ¿Se ralentizará el desarrollo de Druid y Pinot se acelerará si los patrocinadores que apoyan al primero de repente se interesan en el segundo?
Desventajas de ClickHouse
Inmadurez: Obviamente, esto todavía no es una tecnología aburrida, pero en cualquier caso, no se observa nada similar en otros DBMS columnares.
Los insertos pequeños no funcionan bien a alta velocidad: los insertos deben dividirse en piezas grandes, porque el rendimiento de los insertos pequeños disminuye en proporción al número de columnas en cada fila. Así es como ClickHouse almacena datos en el disco: cada columna significa 1 archivo o más, por lo que para insertar 1 fila que contenga 100 columnas, debe abrir y escribir al menos 100 archivos. Esta es la razón por la cual se requiere un intermediario para almacenar las inserciones en el búfer (a menos que el cliente mismo proporcione el almacenamiento en búfer), generalmente se trata de Kafka o algún tipo de sistema de gestión de colas. También puede usar el motor de la tabla de almacenamiento intermedio para luego copiar grandes fragmentos de datos en tablas MergeTree.
Las uniones de tabla están limitadas por la RAM del servidor, ¡pero al menos están ahí! Por ejemplo, Druid y Pinot no tienen tales conexiones en absoluto, ya que son difíciles de implementar directamente en sistemas distribuidos que no admiten el movimiento de grandes piezas de datos entre nodos.
Conclusiones
En los próximos años, planeamos hacer un uso extensivo de ClickHouse en Qwintry, ya que este DBMS proporciona un excelente equilibrio de rendimiento, baja sobrecarga, escalabilidad y simplicidad. Estoy bastante seguro de que comenzará a extenderse rápidamente tan pronto como la comunidad ClickHouse presente más formas de usarlo en instalaciones pequeñas y medianas.
Un poco de publicidad :)
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos
VPS basado en la nube para desarrolladores desde $ 4.99 , un
análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?