
Introduccion
Me gusta mucho la programación, soy aficionado y la primera y última vez que gané dinero en programación en 1996. Pero a veces escribo algo para automatizar las tareas cotidianas. Hace aproximadamente un año, se descubrió el golang. Como herramienta para crear utilidades, golang resultó ser muy conveniente. Entonces
Era necesario procesar una gran cantidad (más de mil, y veo las sonrisas de un profesional) de archivos con información geofísica especial. El formato del archivo es texto, simple. Si de repente te interesa, este es un formato LAS .
El archivo LAS contiene encabezado y datos.
Los datos son prácticamente CSV, solo delimitadores de tabulación o espacios.
Y el encabezado contiene una descripción de los datos y aquí generalmente contiene texto en ruso. Este puede ser el nombre del campo, el nombre de los estudios registrados en un archivo, etc.
Estos archivos se crearon en diferentes momentos y en diferentes programas, se trata del hecho de que una parte del archivo está codificada en CP1251 y otra parte en CP866. Necesito procesar estos archivos, lo que significa entender. Por lo tanto, era necesario determinar automáticamente la codificación del archivo.
Como resultado, inventó una bicicleta en Golang y, en consecuencia, nació una pequeña biblioteca con la capacidad de detectar una página de códigos.
Sobre codificaciones. No hace mucho tiempo en habr había un buen artículo sobre codificaciones Cómo funcionan las codificaciones de texto. ¿De dónde vienen los "cocodrilos"? Los principios de codificación. Generalización y análisis detallado: si desea comprender qué son los "huesos" o los "huesos", entonces vale la pena leerlos.
Al principio tiré mi decisión. Luego intenté encontrar una solución de trabajo lista para usar en Golang, pero fallé. Había dos soluciones, pero ambas no funcionan.
- El primer "fuera de la caja" - golang.org/x/net/html/charset function DetermineEncoding ()
- Segunda biblioteca - saintfish / chardet en github
Ambos seguramente están equivocados en algunas codificaciones. El estándar generalmente no puede determinar casi nada a partir de archivos de texto, es comprensible, se hizo para páginas html.
Cuando buscaba, a menudo me encontraba con utilidades listas para usar del mundo de Linux: enca . Encontró su versión compilada para WIN32, versión 1.12. También lo consideraré, hay cosas divertidas allí. Me disculpo de inmediato por mi completa ignorancia de Linux, lo que significa que probablemente hay más soluciones que también puede intentar atornillar al código de Golang, ya no busqué.
Comparación de soluciones encontradas para la autodetección de codificación
Preparó un catálogo de datos de prueba softlandia \ cpd con archivos en diferentes codificaciones. El contenido de los archivos es muy corto y el mismo. Una línea "ruso en la codificación CodePageName". Agregué archivos con una mezcla de codificaciones y algunos casos complejos e intenté determinar.
Creo que resultó divertido.
Observación 1
enca no determinó la codificación del archivo UTF-16LE sin la lista de materiales; esto es extraño, está bien. Intenté agregar más texto, pero no obtuve el resultado.
Observación 2. Problemas con las codificaciones CP1251 y KOI8-R
Líneas 15 y 16. El comando enca tiene problemas.
Aquí haré una explicación, el hecho es que las codificaciones CP1251 (también conocido como Windows 1251) y KOI8-R están muy cerca si consideramos solo los caracteres alfabéticos.
Tabla CP 1251
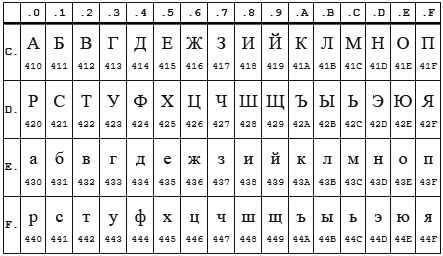
Mesa KOI8-r

En ambas codificaciones, el alfabeto está ubicado de 0xC0 a 0xFF , pero donde una codificación tiene letras mayúsculas, la otra tiene minúsculas. Aparentemente enca funciona en letras minúsculas. Por lo tanto, si envía la línea "STP" codificada en CP1251 al programa enca , decidirá que es una línea "salvajemente" codificada en KOI8-r , que se informará. El reverso también funciona.
Observación 3
La biblioteca estándar html / charset solo se puede confiar con una definición UTF-8 , ¡pero tenga cuidado! Debe usarse exactamente charset.DetermineEncoding () , ya que el método utf8.Valid (b [] byte) en archivos codificados utf-16be devuelve verdadero .
Bicicleta propia

La autodetección de codificación solo es posible por métodos heurísticos, inexactos. Si no sabemos en qué idioma y en qué codificación está escrito el archivo de texto, entonces es posible determinar la codificación con alta precisión, pero será difícil ... y necesitará mucho texto.
Para mí, este objetivo no estaba establecido. Es suficiente para mí determinar las codificaciones bajo el supuesto de que hay ruso. Y en segundo lugar, debe determinar mediante un pequeño número de caracteres: 10 caracteres deben tener una definición bastante segura, y preferiblemente 5-6 caracteres en general.
Algoritmo
Cuando descubrí la coincidencia de las codificaciones KOI8-r y CP1251 por la ubicación del alfabeto, estuve triste por un par de días ... quedó claro que tenía que pensar un poco. Resultó así.
Decisiones clave:
- Trabajaremos con una porción de bytes, por compatibilidad con charset.DetermineEncoding ()
- La codificación UTF-8 y los casos de BOM se verifican por separado
- Los datos de entrada se pasan a su vez a cada codificación. Cada uno calcula dos criterios enteros. Cuya suma de dos criterios es mayor, ganó.
Criterios de cumplimiento
Primer criterio
El primer criterio es el número de las letras más populares del alfabeto ruso.
Las letras más comunes son: o, e, a, y, n, t, s, p, b, l, k, m, d, p, y . Estas cartas dan una cobertura del 82%. Para todas las codificaciones, excepto KOI8-r y CP1251, utilicé solo las primeras 9 letras: o, e, a y, n, t, s, p, c. Esto es suficiente para una determinación confiable.
Pero para KOI8-r y CP1251 tuve que modificar el archivo. Los códigos de algunas de estas letras coinciden, por ejemplo, la letra o tiene el código 0xEE en CP1251, mientras que en KOI8-r este código tiene la letra n . Se tomaron las siguientes letras populares para estas codificaciones. Para CP1251 usé a, y, n, c, p, b, l, k, i. Para KOI8-r - o, a, u, t, s, b, l, k, m.
Segundo criterio
Desafortunadamente, para casos muy cortos (la longitud total del texto en ruso es de 5-6 caracteres), la aparición de letras populares está en el nivel de 1-3 piezas y hay una superposición de las codificaciones KOI8-r y CP1251. Tuve que introducir un segundo criterio. Consonante + recuento de vocales .
Se espera que tales combinaciones ocurran con mayor frecuencia en el idioma ruso y, en consecuencia, en esa codificación en la que el número de tales pares es mayor, esa codificación tiene un criterio más amplio.
Ambos criterios se calculan, se suman y la cantidad recibida es el criterio final.
El resultado se muestra en la tabla anterior.
Características que encontré
Un pequeño toque en los encantos y problemas asociados con golang. La sección puede ser interesante solo para principiantes para escribir en golang.
Los problemas
Caminé personalmente por algunas de las piedras subacuáticas de las 50 sombras de Go: trampas, trampas y errores comunes para principiantes .
Demasiado preocupado e intentando soplar en el agua, al escuchar a otros sobre las terribles quemaduras de la leche, fue demasiado lejos al verificar el parámetro de entrada del tipo io.Reader. Verifiqué una variable como io.Reader con reflexión.
Pero como resultó en mi caso, es suficiente para verificar cero. Ahora todo es más fácil
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
una llamada a bufio.NewReader (r) .Peek (ReadBufSize) pasa silenciosamente la siguiente prueba:
var data *os.File res, err := CodePageDetect(data)
En este caso, Peek () devuelve un error.
Una vez pisó un rastrillo con la transferencia de matrices por valor. Ligeramente estúpido al tratar de cambiar los elementos almacenados en el mapa, ejecutándolos en el rango ...
Delicias
Es difícil decir con exactitud si las manos temblorosas constantes de la interfaz y el compilador o el uso activo del rango, o todo junto, pero prácticamente no hay incursiones para sacar el índice de los límites.
Por supuesto, es muy agradable vivir con el recolector de basura. Supongo que todavía tengo que dominar el rastrillo de automatizar la asignación / liberación de memoria, pero hasta ahora la sonrisa tonta no sale de mi rostro.
La mecanografía fuerte también es una pieza de felicidad.
Las variables que tienen un tipo de función son, en consecuencia, una implementación fácil de varios comportamientos para objetos del mismo tipo.
Poco extraño tuvo que sentarse en el depurador, releer el código generalmente da el resultado.
El deleite de los cachorros de tener muchas herramientas listas para usar, es una sensación maravillosa cuando el compilador, el idioma, la biblioteca y el código IDE Visual Studio Code trabajan juntos en armonía.
Gracias falconandy por los consejos constructivos y útiles.
Gracias a el
- pruebas traducidas en testificar y realmente se volvieron más legibles
- pruebas fijas para rutas de archivos de datos para compatibilidad con Linux
- caminó junto a un linter , pero encontró un error real (maldita copia / pasado)
Sigo agregando pruebas, se reveló un caso de no definir UTF16. Actualizado Ahora UTF16 y LE y BE se detectan incluso en ausencia de letras rusas