Cubo en cubo, metaclusters, celdas, asignación de recursos
Fig. 1. Ecosistema de Kubernetes en la nube de AlibabaDesde 2015, Alibaba Cloud Container Service for Kubernetes (ACK) ha sido uno de los servicios en la nube de más rápido crecimiento en Alibaba Cloud. Sirve a numerosos clientes y también es compatible con la infraestructura interna de Alibaba y otros servicios en la nube de la empresa.
Al igual que en los servicios de contenedores similares de proveedores de nube de clase mundial, nuestras principales prioridades son la fiabilidad y la disponibilidad. Por lo tanto, se ha creado una plataforma escalable y accesible a nivel mundial para decenas de miles de clústeres de Kubernetes.
En este artículo, compartiremos nuestra experiencia en la administración de una gran cantidad de clústeres de Kubernetes en una infraestructura en la nube, así como la arquitectura de la plataforma subyacente.
Entrada
Kubernetes se ha convertido en el estándar de facto para varias cargas de trabajo en la nube. Como se muestra en la fig. 1 en la parte superior, más y más aplicaciones de Alibaba Cloud ahora funcionan en clústeres de Kubernetes: estas son aplicaciones con estado / sin estado, así como administradores de aplicaciones. La gestión de Kubernetes siempre ha sido un tema de discusión interesante y serio para los ingenieros involucrados en la construcción y el mantenimiento de la infraestructura. Cuando se trata de proveedores de la nube como Alibaba Cloud, la escala se destaca. ¿Cómo gestionar los clústeres de Kubernetes en esta escala? Ya hablamos sobre las mejores prácticas para administrar grandes grupos de Kubernetes de 10,000 nodos. Por supuesto, este es un problema de escala interesante. Pero hay otra escala de escala: la cantidad
de clústeres en sí .
Discutimos este tema con muchos usuarios de ACK. La mayoría de ellos prefieren ejecutar docenas, si no cientos, de grupos de Kubernetes pequeños o medianos. Hay razones razonables para esto: limitar el daño potencial, particionar grupos para diferentes equipos, crear grupos virtuales para pruebas. Si ACK busca servir a una audiencia global con este modelo de uso, debe administrar de manera confiable y eficiente un gran número de clústeres en más de 20 regiones.
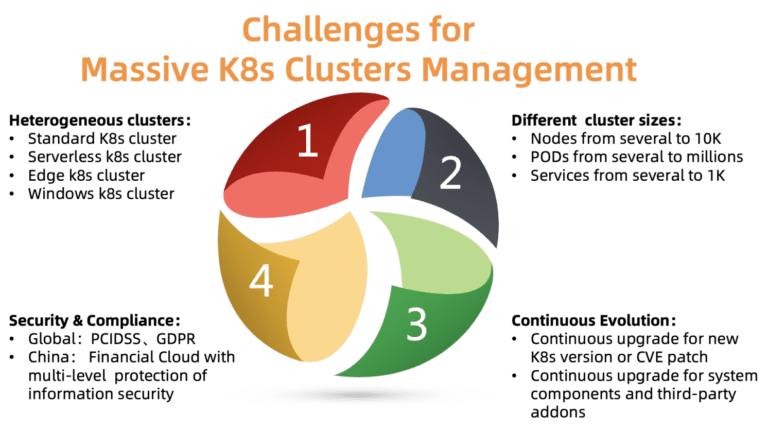 Fig. 2. Desafíos de administrar una gran cantidad de grupos de Kubernetes
Fig. 2. Desafíos de administrar una gran cantidad de grupos de Kubernetes¿Cuáles son los principales problemas de la gestión de clústeres en esta escala? Como se muestra en la figura, hay cuatro problemas que deben abordarse:
ACK debe admitir varios tipos de clústeres, incluidos estándar, sin servidor, Edge, Windows y algunos otros. Los diferentes grupos requieren diferentes parámetros, componentes y modelos de alojamiento. Algunos clientes necesitan ayuda con la personalización para sus casos específicos.
- Diferentes tamaños de racimo
Los grupos varían en tamaño: desde un par de nodos con varias vainas hasta decenas de miles de nodos con miles de vainas. Los requisitos de recursos también son muy diferentes. La asignación inadecuada de recursos puede afectar el rendimiento o incluso conducir al fracaso.
Kubernetes está creciendo rápidamente. Se lanzan nuevas versiones cada pocos meses. Los clientes siempre están listos para probar nuevas funciones. Por lo tanto, quieren colocar la carga de prueba en nuevas versiones de Kubernetes, y la carga de trabajo en versiones estables. Para cumplir con este requisito, ACK debe entregar continuamente nuevas versiones de Kubernetes a sus clientes, mientras mantiene versiones estables.
- Cumplimiento de seguridad
Los grupos se distribuyen en diferentes regiones. Por lo tanto, deben cumplir con varios requisitos de seguridad y regulaciones oficiales. Por ejemplo, un clúster en Europa debe cumplir con GDPR, y una nube financiera en China debe tener niveles adicionales de protección. Estos requisitos son obligatorios, es inaceptable ignorarlos, ya que esto crea grandes riesgos para los clientes de la plataforma en la nube.
La plataforma ACK está diseñada para resolver la mayoría de los problemas anteriores. Actualmente, administra de manera confiable y estable más de 10 mil grupos de Kubernetes en todo el mundo. Veamos cómo logramos esto, incluso debido a varios principios clave de diseño / arquitectura.
Diseño
Cubo en cubo y panales
A diferencia de una jerarquía centralizada, la arquitectura basada en células generalmente se usa para escalar una plataforma más allá de un solo centro de datos o para ampliar el alcance de la recuperación ante desastres.
Cada región en la nube de Alibaba consta de varias zonas (AZ) y generalmente corresponde a un centro de datos específico. En una región grande (como Huangzhou), a menudo se encuentran miles de clústeres de clientes de Kubernetes que ejecutan ACK.
El ACK administra estos clústeres de Kubernetes utilizando Kubernetes en sí, es decir, tenemos el metacluster de Kubernetes para administrar los clústeres de clientes de Kubernetes. Esta arquitectura también se llama "cubo sobre cubo" (kube-on-kube, KoK). La arquitectura KoK simplifica la administración de clústeres de clientes a medida que la implementación de un clúster se vuelve simple y determinista. Más importante aún, podemos reutilizar las características de Kubernetes nativos. Por ejemplo, administrar servidores API a través de la implementación, utilizando el operador etcd para administrar múltiples etcd. Tal recursividad siempre trae un placer particular.
Dentro de la misma región, se implementan varios metaclusters de Kubernetes, dependiendo del número de clientes. A estos metaclusters los llamamos células. Para protegerse contra el fallo de una zona completa, ACK admite implementaciones multiactivas en una región: el metacluster distribuye los componentes del asistente de clúster de clientes Kubernetes en varias zonas y los inicia simultáneamente, es decir, en modo multiactivo. Para garantizar la fiabilidad y la eficacia del asistente, el ACK optimiza la colocación de componentes y garantiza que el servidor API y etcd estén cerca uno del otro.
Este modelo le permite administrar Kubernetes de manera efectiva, flexible y confiable.
Planificación de recursos de metacluster
Como ya hemos mencionado, la cantidad de metaclusters en cada región depende de la cantidad de clientes. ¿Pero en qué punto agrega un nuevo metacluster? Este es un problema típico de planificación de recursos. Como regla general, es habitual crear uno nuevo cuando los metaclusters existentes han agotado todos sus recursos.
Tome los recursos de la red, por ejemplo. En la arquitectura KoK, los componentes de Kubernetes de los clústeres de clientes se implementan como pods en el metacluster. Utilizamos
Terway (Fig. 3), un complemento de alto rendimiento desarrollado por Alibaba Cloud para la gestión de la red de contenedores. Proporciona un amplio conjunto de políticas de seguridad y le permite conectarse a clientes de nube privada virtual (VPC) a través de la interfaz de red elástica de nube de Alibaba (ENI). Para distribuir eficientemente los recursos de red entre nodos, pods y servicios en un metacluster, debemos monitorear cuidadosamente su uso dentro de un metacluster desde nubes privadas virtuales. Cuando los recursos de la red llegan a su fin, se crea una nueva celda.
Para determinar la cantidad óptima de clústeres de clientes en cada metacluster, también tenemos en cuenta nuestros costos, requisitos de densidad, cuota de recursos, requisitos de confiabilidad y estadísticas. La decisión de crear un nuevo metacluster se basa en toda esta información. Tenga en cuenta que los grupos pequeños pueden expandirse en gran medida en el futuro, por lo que el consumo de recursos aumenta incluso con el mismo número de grupos. Por lo general, dejamos suficiente espacio libre para el crecimiento de cada grupo.
 Fig. 3. Arquitectura de red Terway
Fig. 3. Arquitectura de red TerwayEscalar componentes del asistente en clústeres de clientes
Los componentes del asistente tienen diferentes requisitos de recursos. Dependen de la cantidad de nodos y pods en el clúster, la cantidad de controladores / operadores no estándar que interactúan con APIServer.
En el ACK, cada clúster de clientes de Kubernetes es diferente en tamaño y requisitos de tiempo de ejecución. No existe una configuración universal para alojar componentes del asistente. Si por error establecemos un límite bajo de recursos para un cliente grande, entonces su clúster no hará frente a la carga. Si establece un límite alto conservador para todos los clústeres, los recursos se desperdiciarán.
Para encontrar un compromiso sutil entre confiabilidad y costo, ACK utiliza un sistema de tipos. A saber, definimos tres tipos de grupos: pequeños, medianos y grandes. Cada tipo tiene un perfil de asignación de recursos separado. El tipo se determina en función de la carga de los componentes del asistente, el número de nodos y otros factores. El tipo de clúster puede cambiar con el tiempo. ACK monitorea constantemente estos factores y, en consecuencia, puede aumentar / disminuir el tipo. Después de cambiar el tipo de clúster, la distribución de recursos se actualiza automáticamente con una mínima intervención del usuario.
Estamos trabajando para mejorar este sistema en términos de escalado de grano más fino y actualizaciones de tipos más precisas, para que estos cambios ocurran más suavemente y tengan más sentido económico.
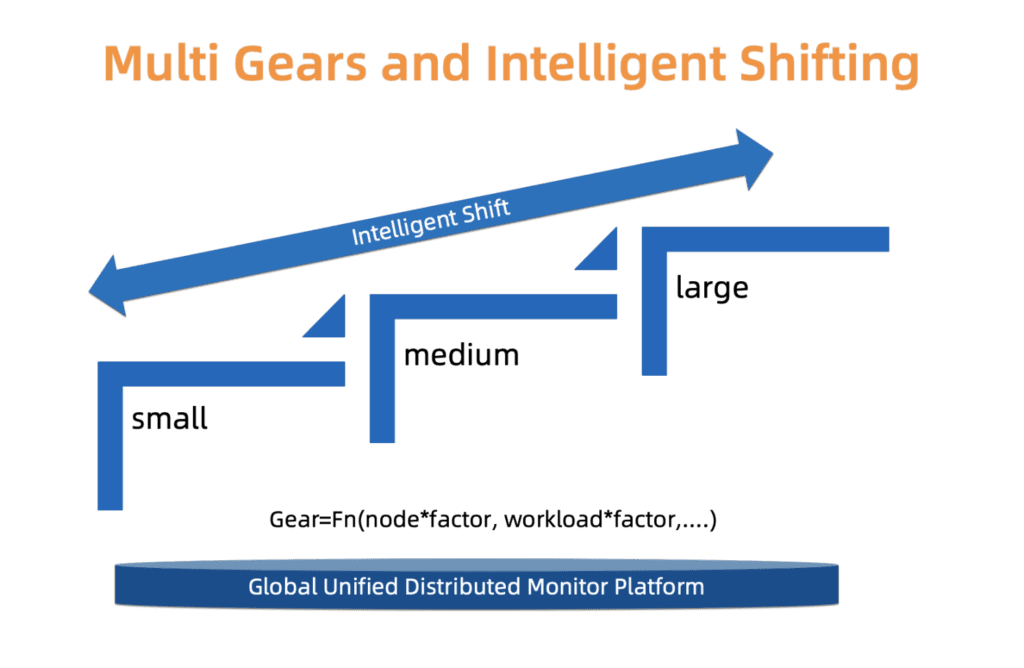 Fig. 4. Conmutación inteligente del tipo de etapas múltiples
Fig. 4. Conmutación inteligente del tipo de etapas múltiplesLa evolución de los clústeres de clientes a escala
Las secciones anteriores describieron algunos aspectos de la gestión de una gran cantidad de clústeres de Kubernetes. Sin embargo, hay otro problema que debe abordarse: la evolución del clúster.
Kubernetes es Linux en el mundo de la nube. Se actualiza continuamente y se vuelve más modular. Debemos suministrar constantemente a nuestros clientes nuevas versiones, corregir vulnerabilidades y actualizar los clústeres existentes, así como administrar una gran cantidad de componentes relacionados (CSI, CNI, Device Plugin, Scheduler Plugin y muchos otros).
Tome la gestión de componentes de Kubernetes como ejemplo. Para comenzar, desarrollamos un sistema centralizado de registro y administración para todos estos componentes enchufables.
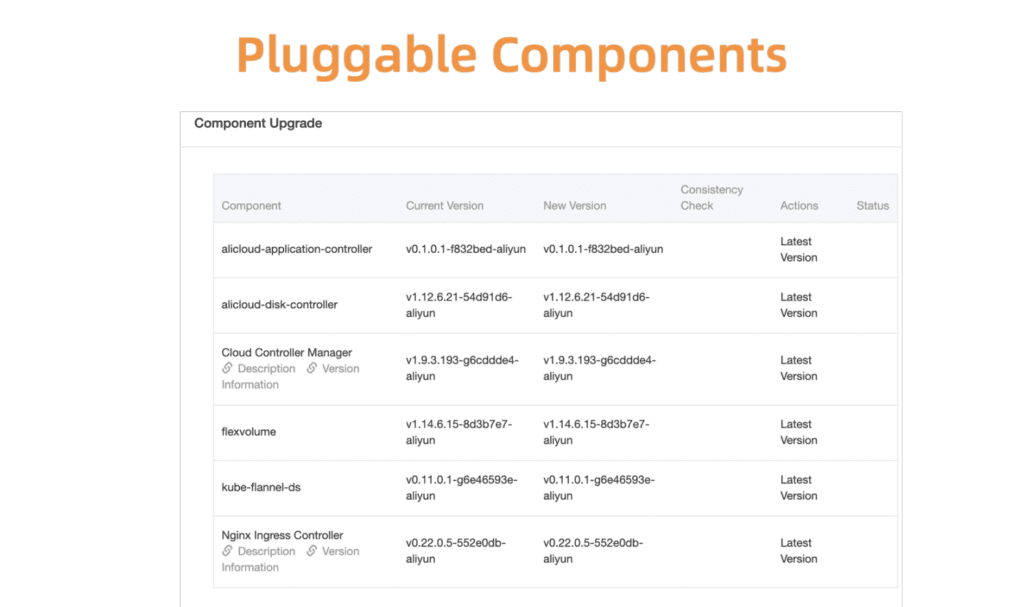 Fig. 5. Componentes flexibles y enchufables
Fig. 5. Componentes flexibles y enchufablesAntes de continuar, debe asegurarse de que la actualización sea exitosa. Para hacer esto, hemos desarrollado un sistema de verificación de salud de componentes. La validación se realiza antes y después de la actualización.
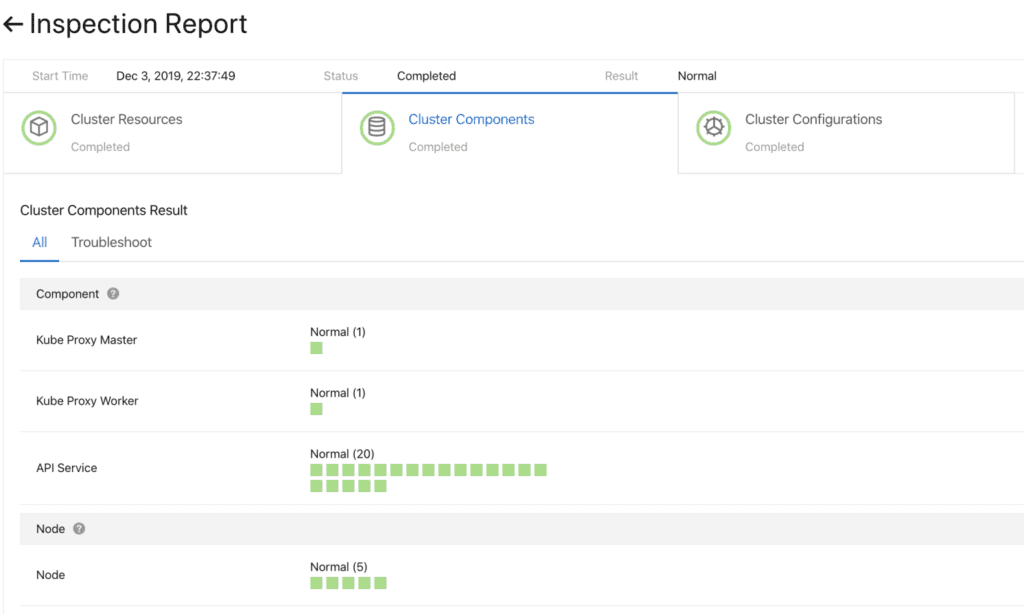 Fig. 6. Comprobación preliminar de los componentes del clúster.
Fig. 6. Comprobación preliminar de los componentes del clúster.Para actualizar estos componentes de manera rápida y confiable, un sistema de implementación continua funciona con soporte para promoción parcial (escala de grises), pausas y otras funciones. Los controladores estándar de Kubernetes no son adecuados para este uso. Por lo tanto, para administrar los componentes del clúster, hemos desarrollado un conjunto de controladores especializados, que incluyen un complemento y un módulo de control auxiliar (administración de sidecar).
Por ejemplo, el controlador BroadcastJob está diseñado para actualizar componentes en cada máquina en funcionamiento o para verificar nodos en cada máquina. El trabajo de difusión ejecuta un pod en cada nodo del clúster, como un DaemonSet. Sin embargo, DaemonSet siempre admite la operación continua del pod, mientras que BroadcastJob lo minimiza. El controlador Broadcast también inicia pods en nodos recién conectados e inicializa nodos con los componentes necesarios. En junio de 2019, abrimos el código fuente del motor de automatización OpenKruise, que nosotros mismos usamos dentro de la empresa.
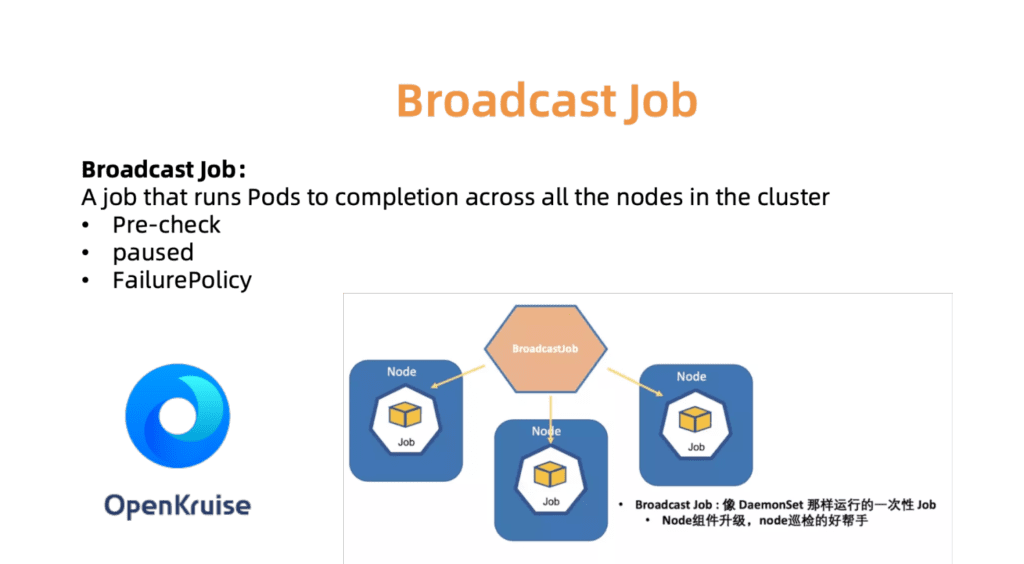 Fig. 7. OpenKurise organiza las tareas de difusión en todos los sitios.
Fig. 7. OpenKurise organiza las tareas de difusión en todos los sitios.Para ayudar a los clientes a elegir las configuraciones de clúster adecuadas, también proporcionamos un conjunto de perfiles predefinidos, incluidos los perfiles Serverless, Edge, Windows y Bare Metal. A medida que el paisaje se expande y las necesidades de nuestros clientes crecen, agregaremos más perfiles para simplificar el tedioso proceso de configuración.
 Fig. 8. Perfiles de clúster avanzados y flexibles para diferentes escenarios.
Fig. 8. Perfiles de clúster avanzados y flexibles para diferentes escenarios.Observabilidad global del centro de datos
Como se muestra a continuación en la fig. 9, Alibaba Cloud Container se implementa en veinte regiones del mundo. Dada esta escala, una de las tareas clave de ACK es monitorear fácilmente el estado de los clústeres en ejecución: si el clúster del cliente encuentra un problema, podemos responder rápidamente a la situación. En otras palabras, debe encontrar una solución que le permita recopilar de manera eficiente y segura estadísticas en tiempo real de los clústeres de clientes en todas las regiones, y presentar visualmente los resultados.
 Fig. 9. Despliegue global del servicio de contenedores en la nube de Alibaba en veinte regiones
Fig. 9. Despliegue global del servicio de contenedores en la nube de Alibaba en veinte regionesAl igual que con muchos sistemas de monitoreo de Kubernetes, tenemos a Prometheus como nuestra herramienta principal. Para cada metacluster, los agentes de Prometheus recopilan las siguientes métricas:
- Métricas del sistema operativo, como los recursos del host (procesador, memoria, disco, etc.) y el ancho de banda de la red.
- Métricas para el sistema de gestión de clúster de clientes y metaclusters, como kube-apiserver, kube-controller-manager y kube-Scheduler.
- Métricas de kubernetes-state-metrics y cadvisor.
- Métricas de Etcd, como el tiempo de escritura del disco, el tamaño de la base de datos, el rendimiento entre nodos, etc.
Las estadísticas globales se recopilan utilizando un modelo típico de agregación multicapa. Los datos de monitoreo de cada metacluster se agregan primero en cada región y luego se envían a un servidor central, que muestra el panorama general. Todo funciona a través del mecanismo de federación. El servidor de Prometheus en cada centro de datos recopila las métricas de este centro de datos, y el servidor central de Prometheus es responsable de agregar los datos de monitoreo. AlertManager se conecta al Prometheus central y, si es necesario, envía alertas a través de DingTalk, correo electrónico, SMS, etc. Visualización: utilizando Grafana.
En la Figura 10, el sistema de monitoreo se puede dividir en tres niveles:
La capa más alejada del centro. El servidor Edge de Prometheus se ejecuta en cada metacluster, recopilando métricas de clústeres de meta y clientes dentro del mismo dominio de red.
La función de capa en cascada de Prometheus es recopilar datos de monitoreo de varias regiones. Estos servidores operan al nivel de unidades geográficas más grandes como China, Asia, Europa y América. A medida que los clústeres crecen en una región, se puede dividir, y luego aparecerá un servidor Prometheus de nivel en cascada en cada nueva región grande. Con esta estrategia, puede escalar sin problemas según sea necesario.
El servidor central de Prometheus se conecta a todos los servidores en cascada y realiza la agregación de datos final. Para mayor confiabilidad, dos instancias centrales de Prometheus conectadas a los mismos servidores en cascada se generaron en diferentes zonas.
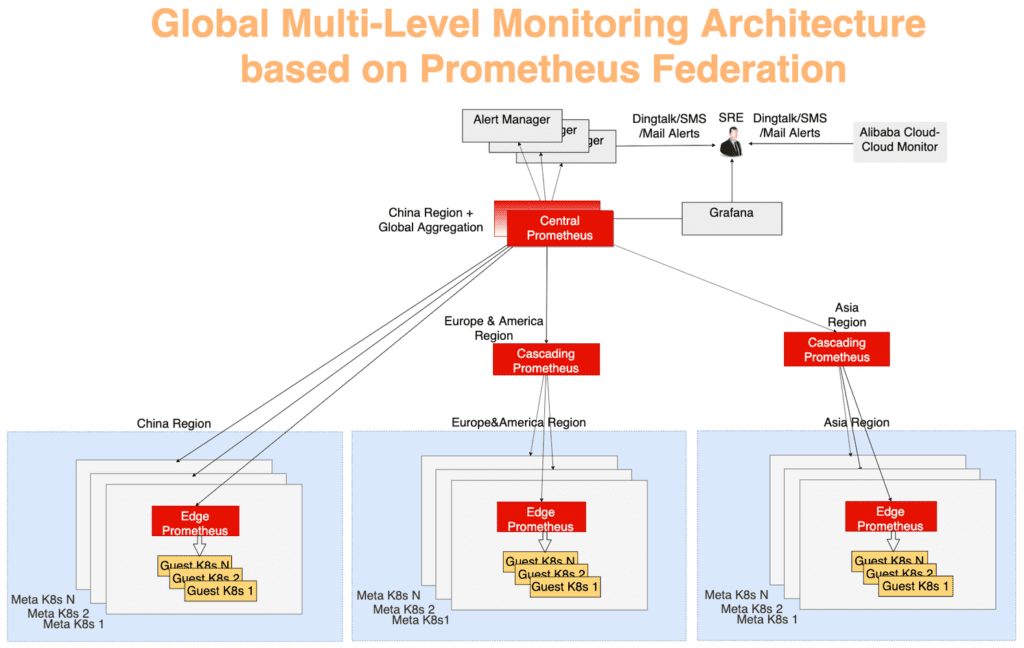 Fig. 10. Arquitectura global de monitoreo de múltiples niveles basada en el mecanismo de federación Prometheus
Fig. 10. Arquitectura global de monitoreo de múltiples niveles basada en el mecanismo de federación PrometheusResumen
Las soluciones en la nube basadas en Kubernetes continúan transformando nuestra industria. Alibaba Cloud Container Service proporciona alojamiento seguro, confiable y de alto rendimiento; este es uno de los mejores servicios de alojamiento en la nube de Kubernetes. El equipo de Alibaba Cloud cree firmemente en los principios de Open Source y la comunidad de código abierto. Definitivamente continuaremos compartiendo nuestro conocimiento en el campo de operación y administración de tecnologías en la nube.