En este artículo, quiero compartir mi experiencia al usar esta biblioteca de código abierto en el ejemplo de implementar una tarea con el análisis de
archivos PDF / DOC / DOCX que contienen hojas de vida de especialistas.
Aquí también describiré las etapas de implementación de la herramienta para preparar el conjunto de datos. Entonces será posible entrenar el modelo
BERT en el conjunto de datos recibido como parte de la tarea de reconocer entidades a partir de textos (
Reconocimiento de entidades con
nombre - en adelante
NER ).
Entonces, por dónde empezar. Naturalmente, primero debe instalar y configurar el entorno para ejecutar nuestra herramienta. Lo instalaré en
Windows 10 .
En Habré ya hay varios artículos de los desarrolladores de esta biblioteca, donde solo hay una guía de instalación detallada. Y en este artículo me gustaría unir todo, desde el lanzamiento hasta la capacitación modelo. También indicaré soluciones a algunos de los problemas que encontré al trabajar con esta biblioteca.
IMPORTANTE: al instalar, es importante cumplir con las versiones de todos los productos y componentes, ya que a menudo hay problemas con versiones incompatibles. Esto es especialmente cierto en la biblioteca TensorFlow . Incluso sucede que para algunas tareas, hasta el compromiso necesario en GitHub, debe usarlo. En el caso de DeepPavlov , el cumplimiento de solo la versión compatible es suficiente.
Indicaré las versiones del producto de la configuración de trabajo y las especificaciones de mi computadora portátil en la que comencé el proceso de entrenamiento de la red neuronal. Proporcionaré algunos enlaces que también describen la instalación y configuración de la biblioteca
DeepPavlov de código
abierto .
Enlaces útiles de desarrolladores de DeepPavlov
Versiones de componentes para instalación
- Python 3.6.6 - 3.7
- Visual Studio Community 2017 (opcional)
- Herramientas de compilación de Visual C ++ 14.0.25420.1
- nVIDIA CUDA 10.0.130_411.31_win10
- cuDNN-10.0-windows10-x64-v7.6.5.32
Establecer el entorno para el soporte de GPU
- Instale Python o Visual Studio Community 2017 incluido con Python . En mi instalación, utilicé el segundo método, instalar Visual Studio Community con soporte para Python .
Por supuesto, debe agregar manualmente la ruta a la carpetaC:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64
a la variable del sistema PATH , donde Python está instalado desde Visual Studio, pero esto no es un problema para mí, es importante para mí saber que instalé una versión para Python .
Pero este es mi caso, puedes instalar todo por separado. - El siguiente paso es instalar las herramientas de compilación de Visual C ++ .
- A continuación, instale nVIDIA CUDA .
IMPORTANTE: si la biblioteca nVIDIA CUDA se instaló previamente, debe eliminar todos los componentes instalados previamente de nVIDIA, hasta el controlador de video. Y solo entonces, en una instalación limpia del controlador de video, realice la instalación de nVIDIA CUDA .
- Ahora instale cuDNN para nVIDIA CUDA .
Para hacer esto, debe registrarse para la membresía del Programa de Desarrolladores de NVIDIA (es gratis).

- Descargue la versión cuDNN para CUDA 10.0

- Descomprima el archivo en una carpeta
C:\Users\<_>\Downloads\cuDNN
- Copie todo el contenido de la carpeta .. \ cuDNN a la carpeta donde hemos instalado CUDA
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
- Reinicia la computadora. Opcional, pero lo recomiendo.
Instalar DeepPavlov
- Crea y activa el entorno virtual de Python .
IMPORTANTE: hice esto a través de Visual Studio.
- Para hacer esto, creé un nuevo proyecto para el código de Python existente .

- Seguimos presionando hasta la última ventana, pero en Finalizar aún no hacemos clic. Debe desmarcar " Detectar entornos virtuales "

- Haz clic en Finalizar .
- Ahora necesita crear un entorno virtual.

- Dejamos todo por defecto.

- Abra la carpeta del proyecto en la línea de comando. Y ejecuta el comando:
.\env\Scripts\activate.bat

- Ahora todo está listo para instalar DeepPavlov . Ejecutamos el comando:
pip install deeppavlov
- A continuación, debe instalar TensorFlow 1.14.0 con soporte para GPU . Para hacer esto, ejecute el comando:
pip install tensorflow-gpu==1.14.0
- Casi todo está listo. Solo necesita asegurarse de que TensorFlow utilizará la tarjeta gráfica para los cálculos. Para hacer esto, escribimos un script simple devices.py , los siguientes contenidos:
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
o tensorflow_test.py :
import tensorflow as tf tf.test.is_built_with_cuda() tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None)
- Después de ejecutar devices.py , deberíamos ver algo como lo siguiente:
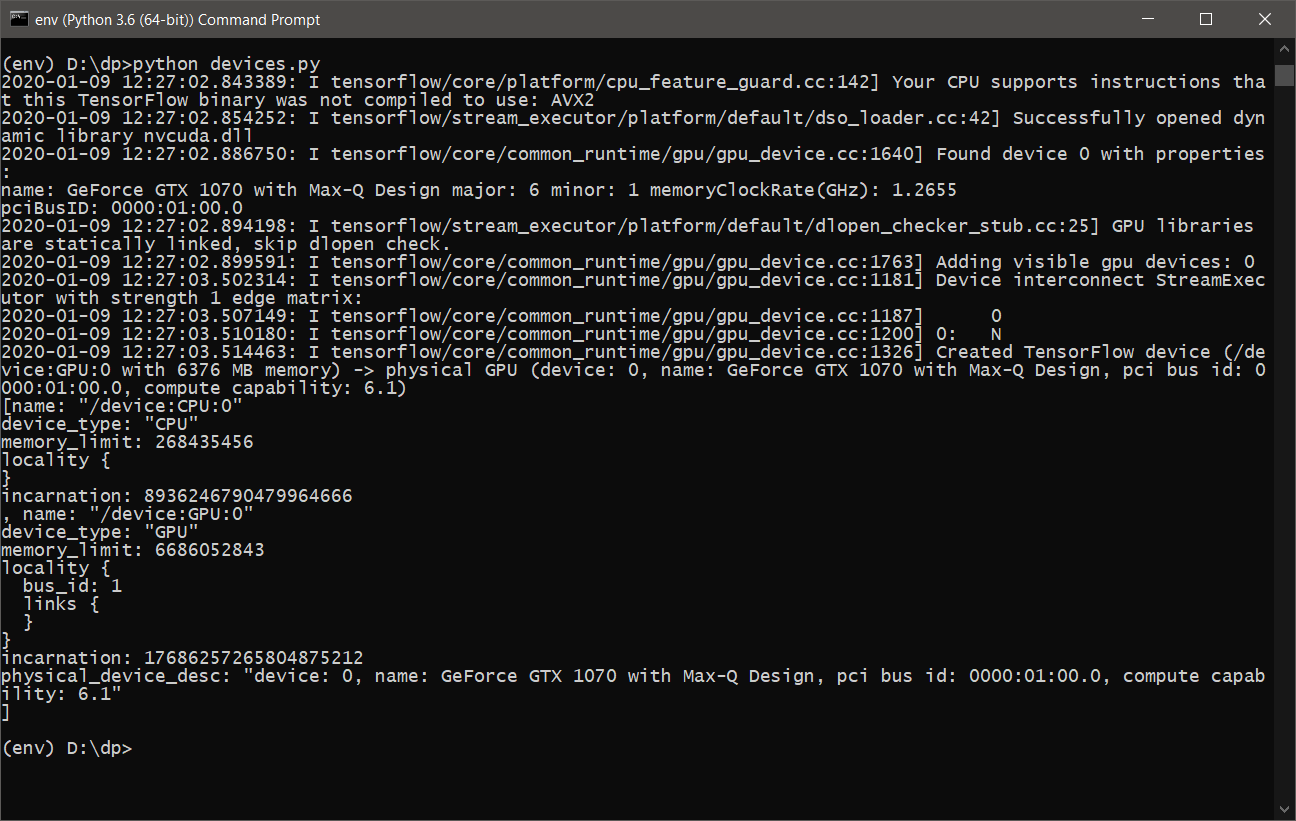
- Ahora está listo para aprender y usar DeepPavlov con soporte para GPU .
DeepPavlov en REST API
Para iniciar e instalar el servicio para la API REST, debe ejecutar los siguientes comandos:
- Instalar en un entorno virtual activo
python -m deeppavlov install ner_ontonotes_bert_mult
- Descargue el modelo ner_ontonotes_bert_mult de los servidores DeepPavlov
python -m deeppavlov download ner_ontonotes_bert_mult
- Ejecutar API REST
python -m deeppavlov riseapi ner_ontonotes_bert_mult -p 5005
Este modelo estará disponible en
http: // localhost: 5005 . Puedes especificar tu puerto.
Todos los modelos se descargarán de forma predeterminada en el camino.
C:\Users\<_>\.deeppavlov
Configurar DeepPavlov para entrenamiento
Antes de comenzar el proceso de aprendizaje, debemos configurar
DeepPavlov para que el proceso de aprendizaje no se "bloquee" con el error de que la memoria de nuestra tarjeta de video está llena. Para esto, tenemos archivos de configuración para cada modelo.
Como en el ejemplo de los desarrolladores, también voy a usar el modelo
ner_ontonotes_bert_mult . Todas las configuraciones predeterminadas para
DeepPavlov se encuentran a lo largo de la ruta:
<_>\env\Lib\site-packages\deeppavlov\configs\ner
En mi caso, el archivo se llamará como el modelo
ner_ontonotes_bert_mult.json .
Para la configuración de mi computadora portátil, tuve que cambiar el valor de
batch_size en el bloque de
tren a 4.

De lo contrario, mi tarjeta de video se "ahogó" después de unos minutos y el proceso de aprendizaje cayó con un error.
Configuración de Nobook
- Modelo: MSI GS-65
- Procesador: Core i7 8750H 2200 MHz
- La cantidad de memoria instalada: 32 GB DDR-4
- Disco Duro: SSD de 512 GB
- Tarjeta de video: GeForce GTX 1070 8192 Mb
Herramienta de preparación de conjunto de datos
Para entrenar el modelo, debe preparar un conjunto de datos. El conjunto de datos consta de tres archivos
train.txt ,
valid.txt ,
test.txt . Con un desglose de los datos en el siguiente porcentaje de tren: 80%, válido y prueba del 10%.
El conjunto de datos para el modelo BERT es el siguiente:
Ivan B-PERSON Ivanov I-PERSON Senior B-WORK_OF_ART Java I-WORK_OF_ART Developer I-WORK_OF_ART IT B-ORG - I-ORG Company I-ORG Key O duties O : 0 Java B-WORK_OF_ART Python B-WORK_OF_ART CSS B-WORK_OF_ART JavaScript B-WORK_OF_ART Russian B-LOC Federation I-LOC . O Petr B-PERSON Petrov I-PERSON Junior B-WORK_OF_ART Web I-WORK_OF_ART Developer I-WORK_OF_ART Boogle B-ORG IO ' O ve O developed O Web B-WORK_OF_ART - O Application O . Skills O : O ReactJS B-WORK_OF_ART Vue B-WORK_OF_ART - I-WORK_OF_ART JS I-WORK_OF_ART HTML B-WORK_OF_ART CSS B-WORK_OF_ART Russian B-LOC Federation I-LOC . O ...
El formato del conjunto de datos es el siguiente:
<_><><_>
IMPORTANTE: después del final de la oración, debe haber un salto de línea. Si la oferta contiene más de 75 tokens, entonces también es necesario poner un salto de línea, de lo contrario, al aprender el modelo, el proceso fallará.
Para preparar el conjunto de datos, escribí una interfaz web donde es posible cargar archivos
DOC / PDF / DOCX a un servidor, analizarlos en texto plano y luego pasar este texto a través de un modelo activo con acceso a la API REST mientras guardo el resultado en una base de datos intermedia. Para esto uso
MongoDB .
Una vez completadas las acciones anteriores, puede proceder a la formación del conjunto de datos para nuestras necesidades.
Para hacer esto, en mi interfaz web escrita, hice un panel separado donde es posible buscar por tokens de conjunto de datos y luego cambiar el tipo de token y el texto del token en sí.
La herramienta también sabe cómo actualizar automáticamente, en base a una lista de palabras, el tipo de token especificado por el usuario a pedido.
En general, la herramienta ayuda a automatizar parte del trabajo, pero aún debe hacer mucho trabajo manual.
También se implementa una interfaz para verificar el resultado y dividir el conjunto de datos en tres archivos.
Entrenamiento DeepPavlov
Entonces llegamos a la parte más interesante. Para el proceso de aprendizaje, primero debe descargar el modelo
ner_ontonotes_bert_mult , si aún no lo ha hecho, debe completar los primeros dos pasos de la sección
DeepPavlov a la API REST anterior.
Antes de comenzar el proceso de aprendizaje, debe completar dos pasos:
- Eliminar completamente la carpeta con el modelo entrenado:
C:\Users\<_>\.deeppavlov\models\ner_ontonotes_bert_mult
Dado que este modelo fue entrenado en un conjunto de datos diferente. - Copie los archivos de conjunto de datos preparados train.txt, valid.txt, test.txt a la carpeta
C:\Users\<_>\.deeppavlov\downloads\ontonotes
Ahora puedes comenzar el proceso de aprendizaje.
Para comenzar a entrenar, puede escribir un script
train.py simple de la siguiente forma:
from deeppavlov import configs, train_model ner_model = train_model(configs.ner.ner_ontonotes_bert_mult, download=False)
o use la línea de comando:
python -m deeppavlov train <_>\env\Lib\site-packages\deeppavlov\configs\ner\ner_ontonotes_bert_mult.json
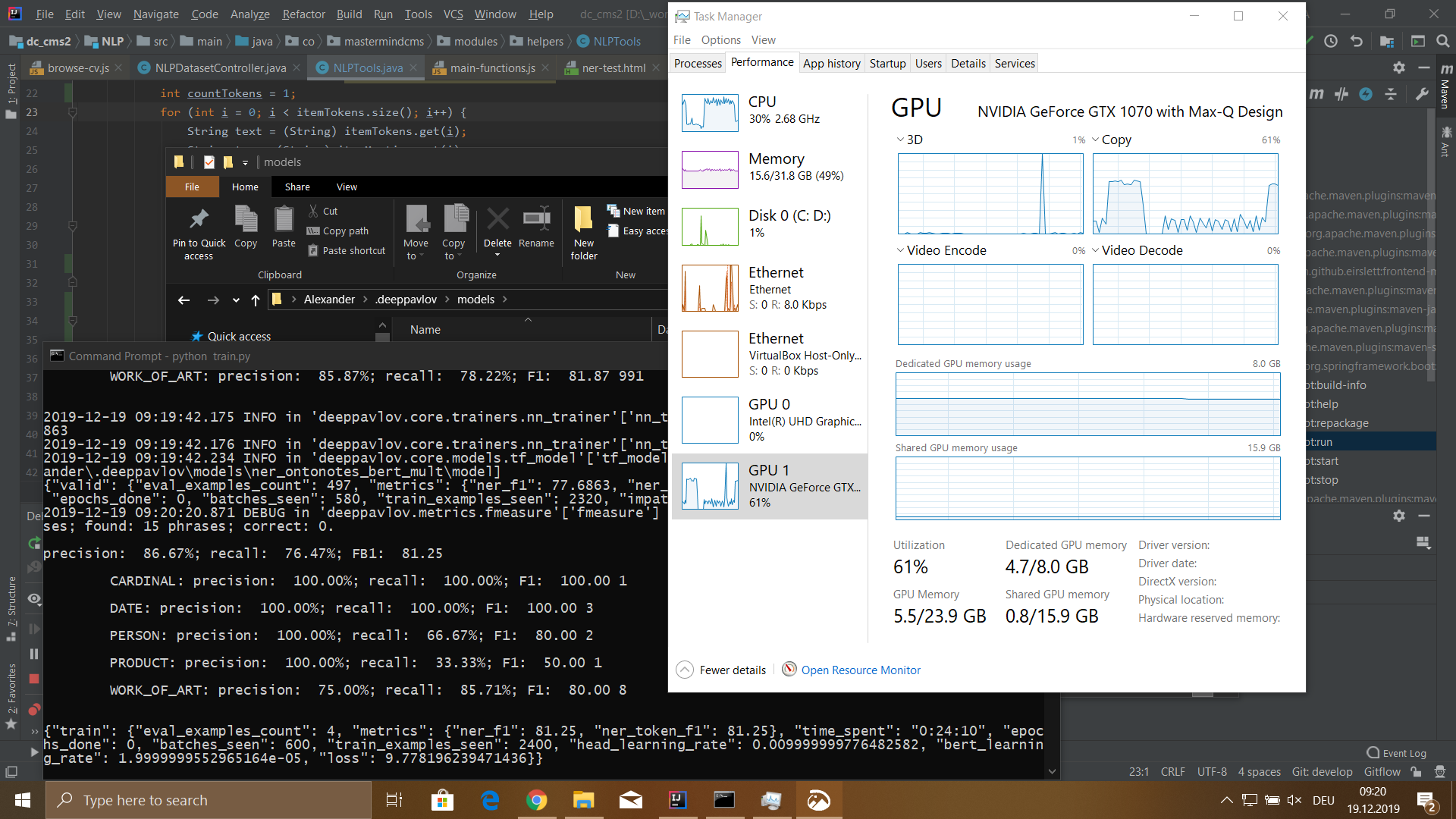
Resultados
Entrené un modelo en un conjunto de datos con un tamaño de 115,540 tokens. Este conjunto de datos se generó a partir de 100 archivos de curriculum vitae de empleados. El proceso de aprendizaje me llevó 5 horas y 18 minutos.
El modelo tenía los siguientes significados:
- precisión: 76,32%;
- retiro del mercado: 72,32%;
- FB1: 74,27;
- pérdida: 5.4907482981681826;
Después de editar varios problemas en la generación automática del conjunto de datos, recibí una
pérdida a continuación. Pero en general, quedé satisfecho con el resultado. Por supuesto, todavía tengo muchas preguntas sobre el uso de esta biblioteca, y lo que describí aquí es solo una gota en el cubo.
Realmente me gustó la biblioteca por su simplicidad y facilidad de uso. Al menos para la tarea
NER . Estaré encantado de hablar sobre otras características de esta biblioteca y espero que alguien encuentre útil el material de este artículo.