- Entrada
- Conexión a la biblioteca
- Donde clase
- Unirse a clase
- Consulta de clase
╔═══╗╔═══╗╔═══╗╔═══╗╔╗─╔╗────╔═══╗╔══╗╔═══╗ ║╔══╝║╔═╗║║╔══╝║╔══╝║╚═╝║────║╔═╗║╚╗╔╝║╔══╝ ║║╔═╗║╚═╝║║╚══╗║╚══╗║╔╗─║────║╚═╝║─║║─║║╔═╗ ║║╚╗║║╔╗╔╝║╔══╝║╔══╝║║╚╗║────║╔══╝─║║─║║╚╗║ ║╚═╝║║║║║─║╚══╗║╚══╗║║─║║────║║───╔╝╚╗║╚═╝║ ╚═══╝╚╝╚╝─╚═══╝╚═══╝╚╝─╚╝────╚╝───╚══╝╚═══╝ 5HHHG HH HHHHHHH 9HHHA HHHHHHHH5 HHHHHHHHHHHHHHHHHH 9HHHHH5 5HHHHHHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHHHHHHH ;HHHHHHHHHHHHHHHHHHHHHHHHHHA H2 HHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHHHH9 HHHHHHHHHHHHHHHHHHHHHHH AHHHHHHHHHHHHHHHHHHHHHH HHHHHHHHHHHHHHHHHHHHH9 iHS HHHHHHHHHHHHHHHHHHHHHHhh HHHHHHHHHHHHHHHHHH AA HHHHHHHHHHHHHH3 &H Hi HS Hr & H& H& Hi
Entrada
Quiero contarles sobre el desarrollo de mi pequeña biblioteca en php. ¿Qué tareas resuelve ella? ¿Por qué decidí escribirlo y por qué podría serle útil? Bueno, intenta responder estas preguntas.
GreenPig (en adelante GP ) es un pequeño asistente de base de datos que puede complementar la funcionalidad de cualquier framework php que use.
Como cualquier herramienta GP , está afilada para resolver ciertos problemas. Le resultará útil si prefiere escribir consultas de la base de datos en sql puro y no utiliza el registro activo y otras tecnologías similares. Por ejemplo, tenemos una base de datos Oracle en el trabajo y, a menudo, las consultas ocupan varias pantallas con docenas de combinaciones, todavía se utilizan funciones plsql, union all, etc. etc., por lo que no queda nada más que hacer que escribir consultas en sql puro.
Pero con este enfoque, surge la pregunta: ¿cómo generar dónde parte de la consulta SQL cuando los usuarios buscan información? GP está dirigido, en primer lugar, a una compilación conveniente mediante php en caso de una solicitud de cualquier complejidad.
Pero, ¿qué me llevó a escribir esta biblioteca (excepto, por supuesto, para obtener una experiencia interesante)? Estas son tres cosas:
Primero, la necesidad de obtener no una respuesta plana estándar de la base de datos, sino una matriz anidada similar a un árbol.
Aquí hay un ejemplo de una muestra de base de datos estándar: [ [0] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [1] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [2] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ], [3] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [4] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [5] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [6] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [7] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [8] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [9] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 10 ['name'] => ' ' ['value'] => 5 ], [10] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 8 ['name'] => ' ()' ['value'] => 0.12 ], [11] => [ ['id'] => 4 ['type'] => 'phone' ['val_id'] => 9 ['name'] => ' ' ['value'] => 1 ], [12] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [13] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [14] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ], [15] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 1 ['name'] => ' ()' ['value'] => 790 ], [16] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 2 ['name'] => ' ' ['value'] => 24 ], [17] => [ ['id'] => 1 ['type'] => 'car' ['val_id'] => 3 ['name'] => ' ' ['value'] => 75 ] ]
Para obtener una matriz en forma de árbol, necesitamos llevar el resultado a la forma deseada nosotros mismos, o realizar N consultas en la base de datos para cada producto. ¿Y si necesitamos paginación, e incluso con clasificación? GP es capaz de resolver estos problemas. Aquí hay un ejemplo de una muestra con GP :
[ [1] => [ ['prod_type'] => 'car' ['properties'] => [ [1] => [ ['name'] => ' ()' ['value'] => 790 ] [2] => [ ['name'] => ' ' ['value'] => 24 ] [3] => [ ['name'] => ' ' ['value'] => 75 ] ] ] [4] => [ ['prod_type'] => 'phone' ['properties'] => [ [10] => [ ['name'] => ' ' ['value'] => 5 ] [8] => [ ['name'] => ' ()' ['value'] => 0.12 ] [9] => [ ['name'] => ' ' ['value'] => 1 ] ] ] ]
Y, por supuesto, al mismo tiempo conveniente paginación y clasificación: ->pagination(1, 10)->sort('id') .
La segunda razón no es tan frecuente, pero sin embargo ocurre (y en mi caso esta es la razón principal). Si algunas entidades se almacenan en la base de datos, y las propiedades de estas entidades son dinámicas y establecidas por los usuarios, cuando necesite buscar entidades por sus propiedades, tendrá que agregar (unir) la misma tabla con los valores de las propiedades (tantas veces como se usen). propiedades al buscar). Por lo tanto, el GP lo ayudará a conectar todas las tablas y generar la consulta where con casi una función. Hacia el final del artículo analizaré este caso en detalle.
Y finalmente, todo esto debería funcionar tanto para la base de datos Oracle como para mySql. También hay una serie de características descritas en la documentación.
Es posible que haya inventado otra bicicleta, pero busqué concienzudamente y no encontré una solución adecuada para mí. Si conoce una biblioteca que resuelve estos problemas, escriba los comentarios.
Antes de proceder directamente a un examen de la propia biblioteca y a ejemplos, diré que solo habrá la esencia, sin explicaciones detalladas. Si te interesa cómo funciona el GP , puedes mirar la documentación , en ella intenté explicar todo en detalle.
Conexión a la biblioteca
La biblioteca se puede instalar a través del compositor: el composer require falbin/green-pig-dao
Luego debe escribir una fábrica a través de la cual utilizará esta biblioteca.
Donde clase
Con esta clase, puede componer la parte where de la consulta sql de cualquier complejidad.
Parte atómica de la solicitud
Considere la parte atómica más pequeña de una consulta. Se describe mediante una matriz: [, , ]
Ejemplo: ['name', 'like', '%%']
- El primer elemento de la matriz es solo una cadena, insertada en la consulta sql sin cambios y, por lo tanto, puede escribir funciones sql en ella. Ejemplo:
['LOWER(name)', 'like', '%%'] - El segundo elemento también es una cadena insertada en sql sin cambios entre dos operandos. Puede tomar los siguientes valores: =,>, <,> =, <=, <>, like, not like, between, not between, in, not in .
- El tercer elemento de la matriz puede ser numérico o tipo cadena. Donde la clase sustituirá automáticamente el alias generado en la consulta sql.
- Elemento de matriz con clave sql. A veces es necesario que el valor se inserte en el código sql sin cambios. Por ejemplo, para aplicar funciones. Esto se puede lograr especificando 'sql' como la clave (para el tercer elemento). Ejemplo:
['LOWER(name)', 'like', 'sql' => "LOWER('$name')"] - Un elemento de matriz con la clave de vinculación es una matriz para almacenar enlaces. El ejemplo anterior es incorrecto desde un punto de vista de seguridad. No puede insertar variables en sql: es demasiada inyección. Por lo tanto, en este caso, deberá especificar alias usted mismo, por ejemplo:
['LOWER(name)', 'like', 'sql' => "LOWER(:name)", 'bind'=> ['name' => $name] ] - El operador in puede escribirse así:
['curse', 'not in', [1, 3, 5]] . La clase Where convierte dicha entrada en el siguiente código sql: curse not in (:al_where_jCgWfr95kh, :al_where_mCqefr95kh, :al_where_jCfgfr9Gkh) - La declaración between se puede escribir así:
['curse', ' between', 1, 5] . La clase Where convierte dicha entrada en el siguiente código sql: curse between :al_where_Pi4CRr4xNn and :al_where_WiPPS4NKiG
Pero tenga cuidado, si los elementos tercero y cuarto de la matriz son cadenas, entonces se aplica una lógica especial. En este caso, se cree que la selección es de un rango de fechas y, por lo tanto, se utiliza la función sql de convertir una cadena a una fecha. La función de convertir a una fecha (mySql y Oracle tienen diferentes) y sus parámetros se toman de una variedad de configuraciones (más en la documentación). La matriz ['build_date', 'between', '01.01.2016', '01.01.2019'] se convertirá en sql: build_date between TO_DATE(:al_where_fkD7nZg5lU, 'dd.mm.yyyy hh24:mi::ss') and TO_DATE(:al_where_LdyVRznPF8, 'dd.mm.yyyy hh24:mi::ss')
Consultas complicadas
Creemos una instancia de la clase a través de la fábrica: $wh = GP::where();
Para indicar la conexión lógica entre las "partes atómicas" de la solicitud, debe usar las linkAnd() o linkOr() . Un ejemplo:
Cuando se usan las funciones linkAnd / linkOr, todos los datos se almacenan dentro de una instancia de la clase Where - $ wh. Además, todas las "partes atómicas" indicadas en la función están entre corchetes .
SQL de cualquier complejidad se puede describir mediante tres funciones: linkAnd(), linkOr(), getRaw() . Considere un ejemplo:
La clase Where tiene una variable privada que almacena la expresión sin formato. Los linkAnd() y linkOr() sobrescriben esta variable, por lo tanto, al construir una expresión lógica, los métodos se anidan juntos y la variable con la expresión sin procesar contiene datos obtenidos del último método ejecutado.
ÚNETE a la clase
Join es una clase que genera un fragmento de unión de código sql. $jn = GP::leftJoin('coursework', 'student_id', 's.id') una instancia de la clase a través de la fábrica: $jn = GP::leftJoin('coursework', 'student_id', 's.id') , donde:
- el curso es la mesa a la que nos uniremos
- student_id : una columna con una clave externa de la tabla de cursos .
- s.id : la columna de la tabla con la que se debe escribir join junto con el alias de la tabla (en este caso, el alias de la tabla es s).
Sql generada: left JOIN coursework coursework_joM9YuTTfW ON coursework_joM9YuTTfW.student_id = s.id
Al crear una instancia de la clase, ya describimos la condición para unir tablas, pero puede ser necesario aclarar y expandir la condición. Las funciones linkAnd / linkOr lo ayudarán a hacer esto: $jn->linkAnd(['semester_number', '>', 2])
Sql generada: inner JOIN coursework coursework_Nd1n5T7c0r ON coursework_Nd1n5T7c0r.student_id = s.id and (semester_number > :al_where_M1kEcHzZyy)
Si hay varias tablas para unir, puede combinarlas en una clase: CollectionJoin .
Consulta de clase
Esta es la clase principal para trabajar con la base de datos, a través de ella hay una selección, registro, actualización y eliminación de datos. También puede realizar cierto procesamiento de datos obtenidos de la base de datos.
Considere un ejemplo típico.
Creemos una instancia de la clase a través de la fábrica: $qr = GP::query();
Ahora configuraremos la plantilla sql, sustituiremos los valores necesarios para el escenario dado en la plantilla sql y diremos que queremos obtener un registro, y específicamente los datos de la columna average_mark .
$rez = $qr->sql("select /*select*/ from student s inner join mark m on s.id = m.student_id inner join lesson l on l.id = m.lesson_id /*where*/ /*group*/") ->sqlPart('/*select*/', 's.name, avg(m.mark) average_mark', []) ->whereAnd('/*where*/', ['s.id', '=', 1]) ->sqlPart('/*group*/', 'group by s.name', []) ->one('average_mark');
Resultado: 3,16666666666666666666666666666666666667
Selección desde una base de datos con parámetros anidados
Sobre todo, no tuve la oportunidad de obtener una selección de la base de datos en una vista de árbol, con propiedades adjuntas. Por lo tanto, la biblioteca GP tiene esa oportunidad, y la profundidad de anidamiento no está limitada.
La forma más fácil de considerar el principio de funcionamiento se basa en un ejemplo. Para su consideración, tomamos el siguiente esquema de base de datos:

Contenido de la tabla:
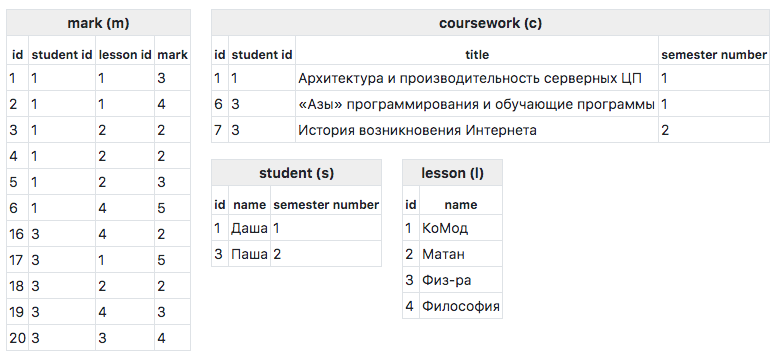
A menudo, al consultar una base de datos, desea obtener una respuesta similar a un árbol, no plana. Por ejemplo, ejecutando esta consulta:
SELECT s.id, s.name, c.id title_id, c.title FROM student s INNER JOIN coursework c ON c. student_id = s.id WHERE s.id = 3
Obtenemos un resultado plano:
[ 0 => [ 'id' => 3, 'name' => '', 'title_id' => 6, 'title' => '«» ', ], 1=> [ 'id' => 3, 'name' => '', 'title_id' => 7, 'title' => ' ' ] ]
Usando GP, puede obtener este resultado:
[ 3 => [ 'name' => '', 'courseworks' => [ 6 => ['title' => '«» '], 7 => ['title' => ' '] ] ] ]
Para lograr este resultado, debe pasar una matriz con opciones a all funciones (la función devuelve todas las líneas de consulta):
all([ 'id'=> 'pk', 'name' => 'name', 'courseworks' => [ 'title_id' => 'pk', 'title' => 'title' ] ])
La matriz $option en el agregador de funciones ( $option , $ rawData) y todas ( $options ) se crean de acuerdo con las siguientes reglas:
- Teclas de matriz : nombres de columna. Elementos de matriz : nuevos nombres para columnas, puede ingresar el nombre anterior.
- Hay una palabra reservada para los valores de la matriz:
pk . Dice que los datos se agruparán por esta columna (la clave de matriz es el nombre de la columna). - En cada nivel solo debe haber un
pk . - En la matriz agregada (resultante), los valores de la columna declarada por
pk se utilizarán como claves. - Si es necesario colocar parte de las columnas un nivel más bajo, se utilizará un nombre nuevo e inventado como clave de matriz, y se utilizará como valor una matriz construida de acuerdo con las reglas descritas anteriormente.
Considere un ejemplo más complejo. Supongamos que necesitamos que todos los estudiantes tengan el nombre de sus cursos y todas las calificaciones en todas las materias. Nos gustaría recibirlo no en forma plana, sino en forma de árbol, sin duplicados. A continuación se muestra la consulta deseada a la base de datos y el resultado.
SELECT s.id student_id, s.name student_name, s.semester_number, c.id coursework_id, c.semester_number coursework_semester, c.title coursework_title, l.id lesson_id, l.name lesson, m.id mark_id, m.mark FROM student s LEFT JOIN coursework c ON c.student_id = s.id LEFT JOIN mark m ON m.student_id = s.id LEFT JOIN lesson l ON l.id = m.lesson_id ORDER BY s.id, c.id, l.id, m.id
El resultado no nos conviene:
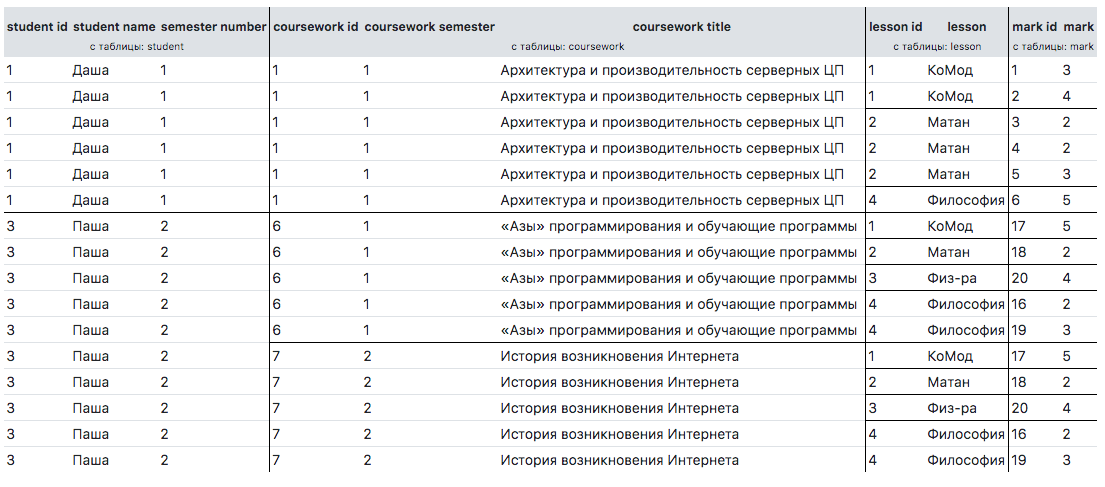
Para lograr la tarea, debe escribir la siguiente matriz $option :
$option = [ 'student_id' => 'pk', 'student_name' => 'name', 'courseworks' => [ 'coursework_semester' => 'pk', 'coursework_title' => 'title' ], 'lessons' => [ 'lesson_id' => 'pk', 'lesson' => 'lesson', 'marks' => [ 'mark_id' => 'pk', 'mark' => 'mark' ] ] ];
Consulta de base de datos:
La función del aggregator puede procesar cualquier matriz con una estructura similar al resultado de una consulta a la base de datos, de acuerdo con las reglas descritas en la $option .
La variable $result contiene los siguientes datos:
[ 1 => [ 'name' => '', 'courseworks' => [ 1 => ['title' => ' '], ], 'lessons' => [ 1 => [ 'lesson' => '', 'marks' => [ 1 => ['mark' => 3], 2 => ['mark' => 4] ] ], 2 => [ 'lesson' => '', 'marks' => [ 3 => ['mark' => 2], 4 => ['mark' => 2], 5 => ['mark' => 3] ] ], 4 => [ 'lesson' => '', 'marks' => [ 6 => ['mark' => 5] ] ] ] ], 3 => [ 'name' => '', 'courseworks' => [ 1 => ['title' => '«» '], 2 => ['title' => ' '] ], 'lessons' => [ 1 => [ 'lesson' => '', 'marks' => [ 17 => ['mark' => 5] ] ], 2 => [ 'lesson' => '', 'marks' => [ 18 => ['mark' => 2] ] ], 3 => [ 'lesson' => '-', 'marks' => [ 20 => ['mark' => 4] ] ], 4 => [ 'lesson' => '', 'marks' => [ 16 => ['mark' => 2], 19 => ['mark' => 3] ] ], ] ] ]
Por cierto, con la paginación con consulta agregada, solo se consideran los datos principales y más básicos. En el ejemplo anterior, solo habrá 2 líneas para la paginación.
Unión múltiple contigo mismo en el nombre de la búsqueda
Como escribí anteriormente, la tarea principal de mi biblioteca es simplificar la generación de las partes where para consultas seleccionadas. Entonces, ¿en qué caso es posible que necesitemos unirnos repetidamente a la misma tabla para consultar dónde? Una de las opciones es cuando tenemos un determinado producto cuyas propiedades no se conocen de antemano y serán agregadas por los usuarios, y debemos tener la oportunidad de buscar productos por estas propiedades dinámicas. La forma más fácil de explicar con un ejemplo simplificado.
Supongamos que tenemos una tienda en línea que vende componentes informáticos, y no tenemos una variedad estricta, y periódicamente compraremos uno u otro componente. Pero nos gustaría describir todos nuestros productos como una entidad única y buscar todos los productos. Entonces, qué entidades se pueden distinguir desde el punto de vista de la lógica empresarial:
- Producto. La entidad más importante en torno a la cual se construye todo.
- Tipo de producto. Esto se puede representar como la propiedad raíz para todas las demás propiedades del producto. Por ejemplo, en nuestra pequeña tienda es solo: RAM, SSD y HDD.
- Propiedades del producto En nuestra implementación, cualquier propiedad puede aplicarse a cualquier tipo de producto, la elección queda en la conciencia del gerente. En nuestra tienda, los gerentes hicieron solo 3 propiedades: tamaño de memoria, factor de forma y DDR.
- El valor de los bienes. El valor que el comprador generará en la búsqueda.
Toda la lógica comercial descrita anteriormente se refleja en detalle en la imagen a continuación.
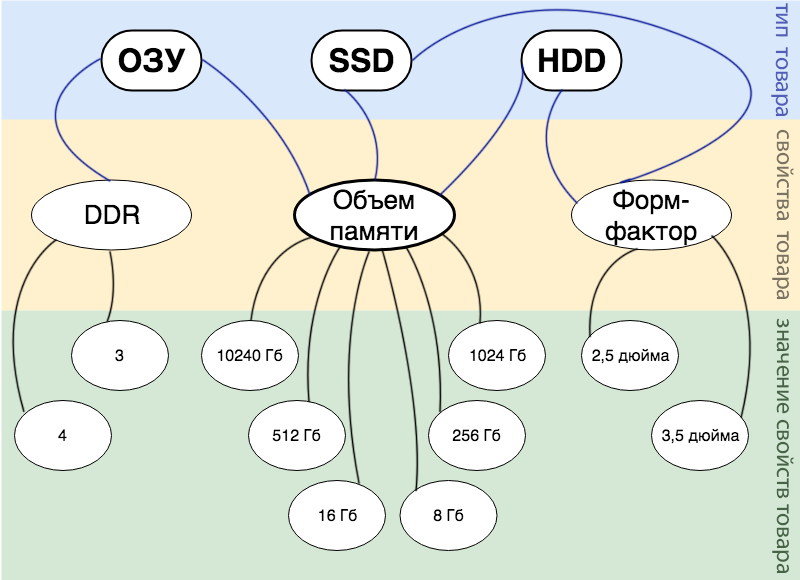
Por ejemplo, tenemos un producto: 16 GB DDR 3 RAM . En el diagrama, esto se puede mostrar de la siguiente manera:
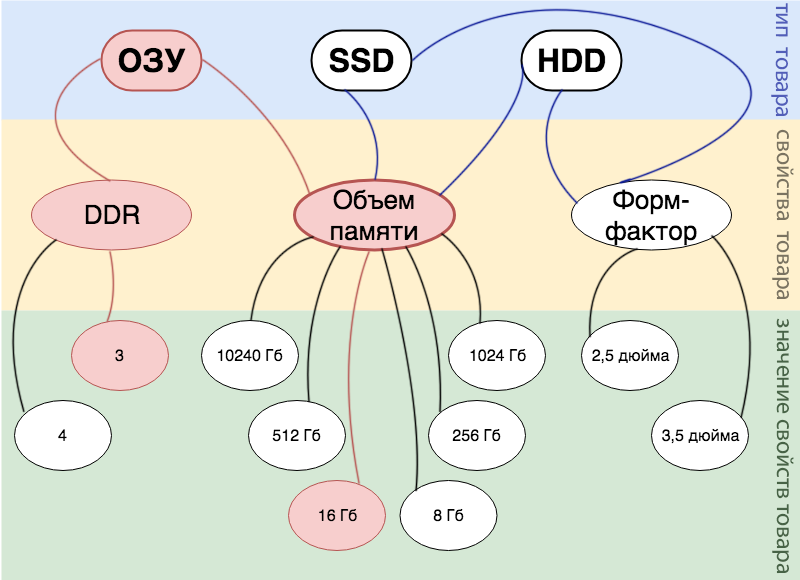
La estructura y los datos de la base de datos son claramente visibles en la siguiente figura:
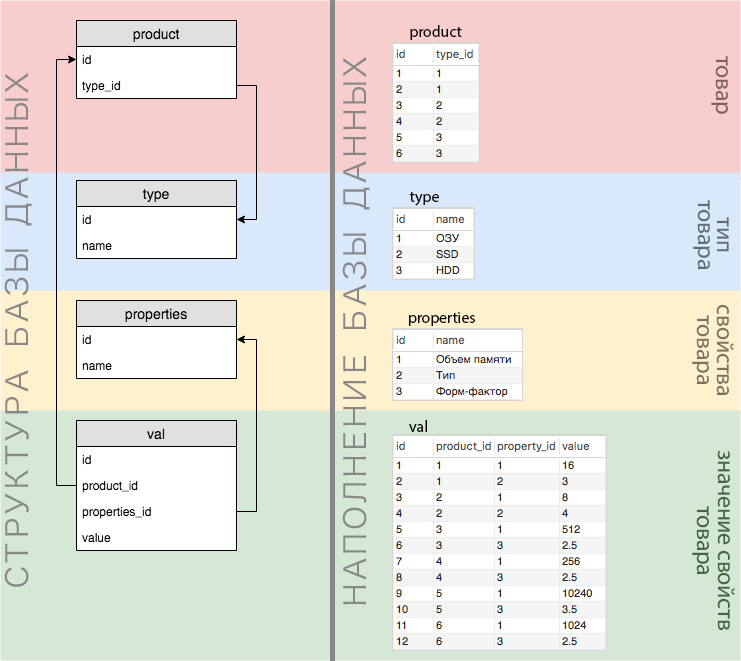
Como vemos en el diagrama, todos los valores de todas las propiedades se almacenan en una tabla de valores (por cierto, en nuestra versión simplificada, todas las propiedades tienen valores numéricos). Por lo tanto, si queremos buscar simultáneamente varias propiedades con un grupo de AND, obtenemos una selección vacía.
Por ejemplo, un comprador está buscando productos adecuados para tal solicitud: la cantidad de memoria debe ser superior a 10 GB y el factor de forma debe ser de 2,5 pulgadas . Si escribimos sql como se muestra a continuación, obtenemos una selección vacía:
select * from product p inner join val v on v.product_id = p.id where (v.property_id = 1 and v.value > 10) AND (v.property_id = 3 and v.value = 2.5)
Dado que los valores de todas las propiedades se almacenan en una tabla, para buscar varias propiedades, debe unir el valor de la tabla para cada propiedad que se buscará. Pero hay un matiz, unir tablas de unión "horizontalmente" (a la palabra unión todas las uniones "verticalmente"), el siguiente es un ejemplo:

Este resultado no nos conviene, nos gustaría ver todos los valores en una columna. Para hacer esto, debe unirse a la tabla val 1 veces más que las propiedades por las cuales se realiza la búsqueda.

Estamos cerca de generar automáticamente consultas SQL. Veamos la función.
whereWithJoin ($aliasJoin, $options, $aliasWhere, $where) , que hará todo el trabajo:
- $ aliasJoin : un alias en la plantilla base, en lugar del cual se sustituye la parte sql con combinaciones.
- $ options : una matriz con descripciones de las reglas para generar la parte de unión.
- $ aliasWhere : un alias en la plantilla base, que sustituye la parte where sql en su lugar.
- $ where es una instancia de la clase Where.
Veamos un ejemplo: whereWithJoin('/*join*/', $options, '/*where*/', $wh) .
Primero, cree la variable $ options : $options = ['v' => ['val', 'product_id', 'p.id']];
v es el alias de la tabla. Si el alias dado se encuentra en $ wh , entonces una nueva tabla val se conectará mediante join (donde product_id es la clave externa de la tabla val , y p.id es la clave principal para la tabla con el alias p ), se generará un nuevo alias y este alias. reemplazará v en donde.
$ wh es una instancia de la clase Where. Formulamos la misma solicitud: la memoria debe tener más de 10 GB y el factor de forma debe ser de 2.5 pulgadas.
$wh->linkAnd([ $wh->linkAnd([ ['v.property_id', '=', 1], ['v.value', '>', 10] ])->getRaw(),
Al crear una solicitud where, es necesario ajustar la parte con la propiedad id y su valor entre paréntesis, esto le dice a la función whereWithJoin() que el alias de la tabla será el mismo en esta parte.
$qr->sql("select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id /*join*/ /*where*/") ->whereWithJoin('/*join*/', $options, '/*where*/', $wh)
Examinamos el sql generado, los enlaces y el tiempo de ejecución de la consulta: $qr->debugInfo() :
[ [ 'type' => 'info', 'sql' => 'select p.id, t.name type_name, pr.id prop_id, pr.name prop_name, v.id val_id, v.value from product p inner join type t on t.id = p.type_id inner join val v on v.product_id = p.id inner join properties pr on pr.id = v.property_id inner JOIN val val_mIQWpnHhdQ ON val_mIQWpnHhdQ.product_id = p.id inner JOIN val val_J0uveMpwEM ON val_J0uveMpwEM.product_id = p.id WHERE ( val_mIQWpnHhdQ.property_id = :al_where_leV5QlmOZN and val_mIQWpnHhdQ.value > :al_where_ycleYAswIw ) and ( val_J0uveMpwEM.property_id = :al_where_dinxDraTOE and val_J0uveMpwEM.value = :al_where_wZJhUqs74i )', 'binds' => [ 'al_where_leV5QlmOZN' => 1, 'al_where_ycleYAswIw' => 10, 'al_where_dinxDraTOE' => 3, 'al_where_wZJhUqs74i' => 2.5 ], 'timeQuery' => 0.0384588241577 ] ]
$qr->rawData() :
[ [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 5, 'value' => 512 ], [ 'id' => 3, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 6, 'value' => 2.5 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 7, 'value' => 256 ], [ 'id' => 4, 'type_name' => 'SSD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 8, 'value' => 2.5 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 1, 'prop_name' => ' ', 'val_id' => 11, 'value' => 1024 ], [ 'id' => 6, 'type_name' => 'HDD', 'prop_id' => 3, 'prop_name' => '-', 'val_id' => 12, 'value' => 2.5 ] ]
$qr->aggregateData() :
[ 3 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 5 => ['val' => 512] ] ], 3 => [ 'name' => '-', 'values' => [ 6 => ['val' => 2.5] ] ] ] ], 4 => [ 'type' => 'SSD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 7 => ['val' => 256] ] ], 3 => [ 'name' => '-', 'values' => [ 8 => ['val' => 2.5] ] ] ] ], 6 => [ 'type' => 'HDD', 'properties' => [ 1 => [ 'name' => ' ', 'values' => [ 11 => ['val' => 1024] ] ], 3 => [ 'name' => '-', 'values' => [ 12 => ['val' => 2.5] ] ] ] ] ]
, , whereWithJoin() , .
whereWithJoin() , , n , m . n m 1 id . , AND .
GitHub .