Introduccion
Comprender cómo el clasificador descompone el espacio inicial multidimensional de los atributos en muchas clases objetivo es un paso importante para analizar cualquier problema de clasificación y evaluar la solución obtenida mediante el aprendizaje automático.
Los enfoques modernos para visualizar las decisiones de los clasificadores usan principalmente diagramas de dispersión que solo pueden mostrar proyecciones de las muestras de entrenamiento originales, pero no muestran explícitamente los límites reales de la toma de decisiones, o usan un dispositivo clasificador interno (por ejemplo, kNN, SVM, Regresión logística) para el cual es fácil construir una geometría interpretación Este método no es adecuado para la visualización, por ejemplo, de un clasificador de red neuronal.
El artículo "Visualización basada en imágenes de los límites de decisión del clasificador" (Rodrigues et al., 2018) propone un método alternativo eficaz, hermoso y bastante simple para visualizar las soluciones del clasificador, que carece de las desventajas anteriores. A saber, el método es adecuado para clasificadores de cualquier tipo y construye los límites de la toma de decisiones utilizando imágenes con una frecuencia de muestreo arbitraria.
Esta publicación es una breve descripción de las principales ideas y resultados del artículo original.
Descripción del método
La base del método es el muestreo inverso (ing. Upsampling) desde el plano de la imagen  que está representado por un conjunto de píxeles en el espacio de características
que está representado por un conjunto de píxeles en el espacio de características  .
.
El método requiere dos asignaciones  - proyección directa del espacio de características al plano de la imagen y al inverso
- proyección directa del espacio de características al plano de la imagen y al inverso  . Como tales mapeos, se utilizan LAMP (Joia et al. 2011) e iLAMP (Amorim et al. 2012) , respectivamente.
. Como tales mapeos, se utilizan LAMP (Joia et al. 2011) e iLAMP (Amorim et al. 2012) , respectivamente.
Edificio
Para construir una imagen, debe asignar un color a cada píxel. Para esto, para cada píxel  encontrará
encontrará  puntos del hiperespacio fuente donde
puntos del hiperespacio fuente donde  - un parámetro especificado por el usuario. Deja que el píxel ya tiene
- un parámetro especificado por el usuario. Deja que el píxel ya tiene  prototipos reales del conjunto de entrenamiento. Entonces elige uniformemente
prototipos reales del conjunto de entrenamiento. Entonces elige uniformemente  los puntos restantes de la superficie del píxel y encuentre el prototipo para ellos a través de la proyección posterior
los puntos restantes de la superficie del píxel y encuentre el prototipo para ellos a través de la proyección posterior  . Por lo tanto, el color de cada píxel estará determinado por al menos puntos del espacio fuente, y se pintará toda la imagen.
. Por lo tanto, el color de cada píxel estará determinado por al menos puntos del espacio fuente, y se pintará toda la imagen.
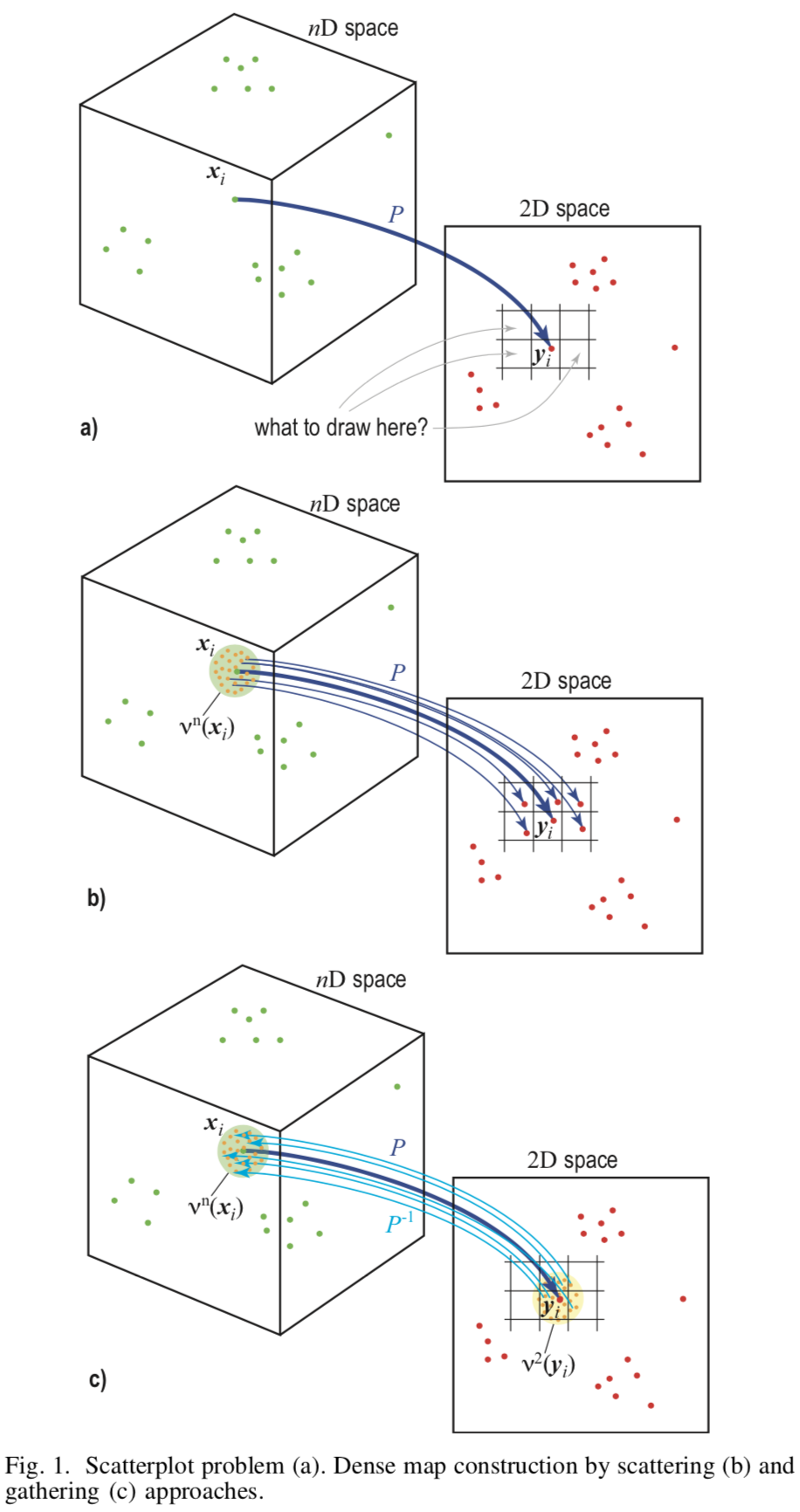
[Fig.1] Ilustración esquemática de diferentes enfoques
Definición de color
Color  cada píxel determinado por un voto mayoritario para las etiquetas de clase de las preimágenes correspondientes.
cada píxel determinado por un voto mayoritario para las etiquetas de clase de las preimágenes correspondientes.
![d (y) = \ text {argmax} _ {k \ in C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]](https://habrastorage.org/getpro/habr/post_images/469/c8d/c50/469c8dc5021ee22be2190d80d4a8f9bd.svg)
donde  - muchas de todas las clases,
- muchas de todas las clases,  - clasificador.
- clasificador.
A cada clase se le asignará un tono (ing. Hue)  - si la proyección tiene puntos de la muestra real y un tono ligeramente cambiado
- si la proyección tiene puntos de la muestra real y un tono ligeramente cambiado  para píxeles en los que solo hay puntos sintéticos.
para píxeles en los que solo hay puntos sintéticos.
Confusión
Definir la mezcla de píxeles (de confusión en inglés)  - como la relación entre el número de etiquetas de la clase predominante y el número total de imágenes inversas de píxeles :
- como la relación entre el número de etiquetas de la clase predominante y el número total de imágenes inversas de píxeles :
![c (y) = \ frac {\ max_ {k \ in C} \ sum_ {y_i \ in y} [f (P ^ {- 1} (y_i)) = k]} {| y |}](https://habrastorage.org/getpro/habr/post_images/62d/5e7/47f/62d5e747f958e587200665af682cbae9.svg)
Alto valor indica la consistencia del clasificador, mientras que un valor bajo indica un acercamiento al límite divisorio. Combinar información codificada en saturación de píxeles  - cuanto mayor es la consistencia, mayor es la saturación.
- cuanto mayor es la consistencia, mayor es la saturación.
Densidad
Aunque se ha generado un mínimo puntos de preimagen para cada píxel, puede haber píxeles para los que hay muchos más puntos reales del conjunto de entrenamiento. Dichos píxeles deben considerarse al renderizar. Para hacer esto, ingrese la densidad de píxeles  como el número de sus puntos de imagen inversa de . Se podría usar esta densidad directamente para determinar el brillo de un píxel como
como el número de sus puntos de imagen inversa de . Se podría usar esta densidad directamente para determinar el brillo de un píxel como  , pero los autores del artículo señalan que esto no da el resultado deseado, porque algunos tonos son obviamente más oscuros que otros. Por lo tanto, se utiliza un ajuste más complicado al mismo tiempo de saturación y brillo a través de un parámetro de densidad normalizado.
, pero los autores del artículo señalan que esto no da el resultado deseado, porque algunos tonos son obviamente más oscuros que otros. Por lo tanto, se utiliza un ajuste más complicado al mismo tiempo de saturación y brillo a través de un parámetro de densidad normalizado.

Entonces si ![\ hat {\ rho} \ en [0, 0.5]](https://habrastorage.org/getpro/habr/post_images/5f3/8f9/0c5/5f38f90c57fe8c26092278e6a36b55c7.svg) - el brillo depende linealmente del parámetro dentro
- el brillo depende linealmente del parámetro dentro ![[V_ {min} = 0.1, V_ {max} = 1]](https://habrastorage.org/getpro/habr/post_images/b1e/ef5/e22/b1eef5e220c553d3c437ee6ddb9f4f08.svg) . En
. En ![\ hat {\ rho} \ en [0.5, 1]](https://habrastorage.org/getpro/habr/post_images/4cc/04d/a79/4cc04da7997da643ef6671babba1ec57.svg) comienza a crecer linealmente la saturación de
comienza a crecer linealmente la saturación de  antes
antes  .
.
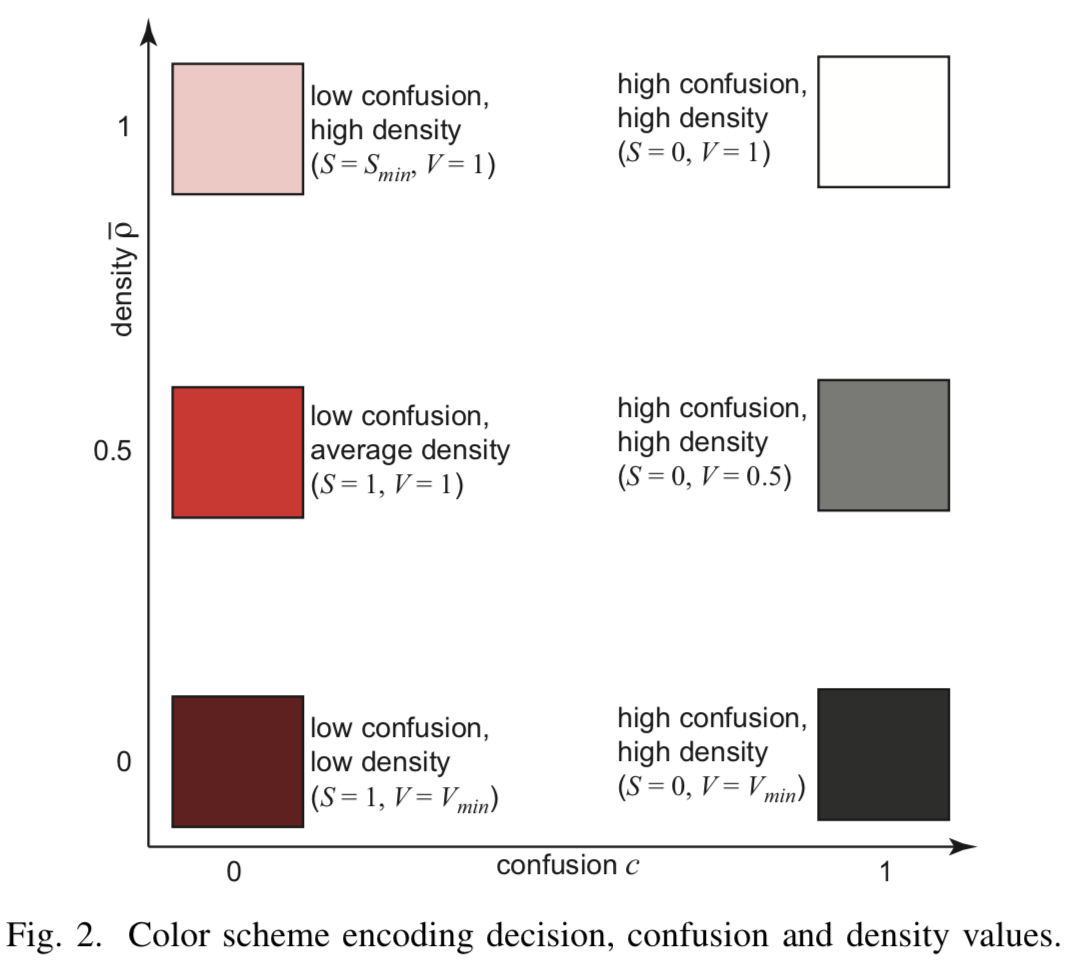
[Fig.2] Codificación de colores
Experimentos y resultados
Para los experimentos, se resolvieron los problemas de clasificación binaria en el conjunto de imágenes digitales MNIST y clasificación multiclase en el conjunto de datos de segmentación de imágenes , que contiene 2310 imágenes divididas en 7 clases. Hay 19 atributos para cada imagen.
Resultados de imágenes con varias configuraciones de resolución  y el número mínimo de prototipos para el clasificador binario LogisticRegression en MNIST se muestran en la figura [3]. Las clases están separadas por una línea recta con alta precisión y el algoritmo de visualización hace un excelente trabajo. Con una resolución creciente, las nubes de los puntos fuente se disuelven casi por completo entre los muchos puntos generados.
y el número mínimo de prototipos para el clasificador binario LogisticRegression en MNIST se muestran en la figura [3]. Las clases están separadas por una línea recta con alta precisión y el algoritmo de visualización hace un excelente trabajo. Con una resolución creciente, las nubes de los puntos fuente se disuelven casi por completo entre los muchos puntos generados.
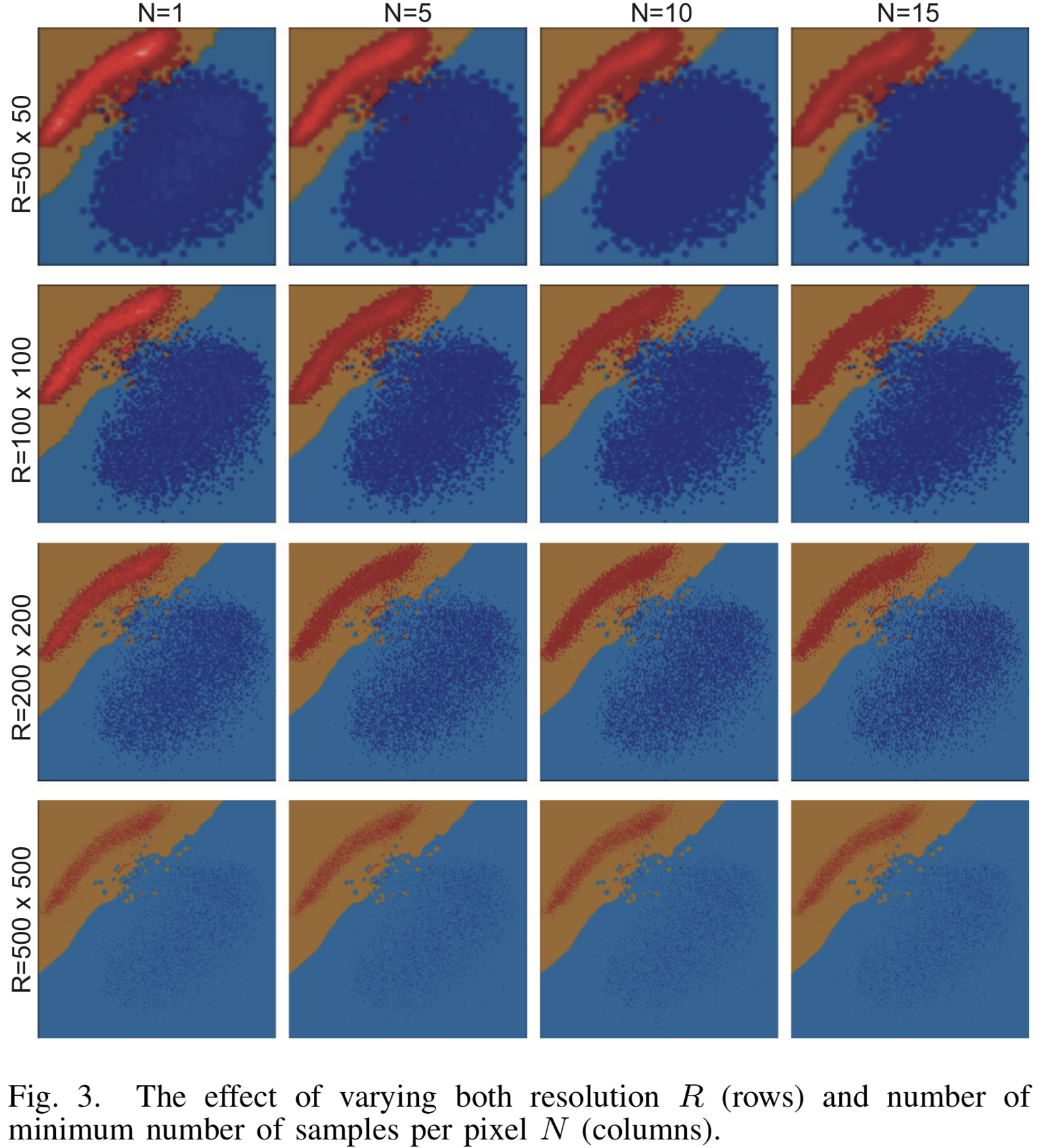
[Fig. 3] El resultado de visualización para varios parámetros de resolución y el número mínimo de muestras N para el clasificador LogisticRegression
Visualización cuando  para tres clasificadores diferentes para la clasificación múltiple en la figura [4]. Las proyecciones de los puntos de partida son muy variadas y no es posible construir límites divisorios explícitos en los lugares donde se acumulan las proyecciones de los casos de prueba. Sin embargo, aparte del grupo principal, se obtuvieron límites de clase explícitos, cuya información no se muestra en proyecciones ordinarias, sino que se obtiene solo con la ayuda de puntos sintéticos.
para tres clasificadores diferentes para la clasificación múltiple en la figura [4]. Las proyecciones de los puntos de partida son muy variadas y no es posible construir límites divisorios explícitos en los lugares donde se acumulan las proyecciones de los casos de prueba. Sin embargo, aparte del grupo principal, se obtuvieron límites de clase explícitos, cuya información no se muestra en proyecciones ordinarias, sino que se obtiene solo con la ayuda de puntos sintéticos.
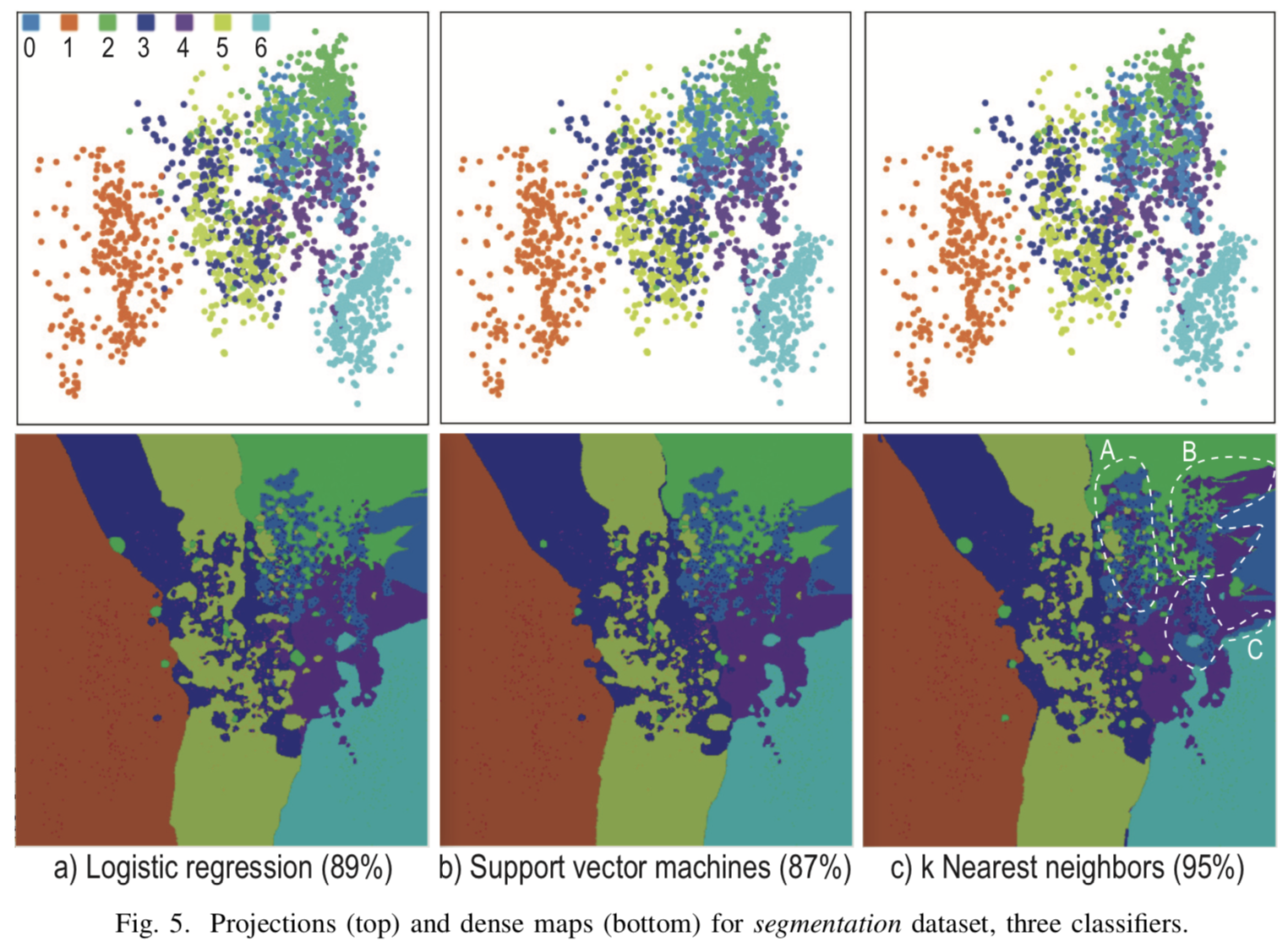
[Fig. 4] El resultado de la visualización de tres clasificadores diferentes para k = 7, R = 500x500, N = 5
Conclusión
La visualización de los límites de clase se puede utilizar en la construcción y depuración de un algoritmo decisivo, en la selección de hiperparámetros, en la lucha contra el reciclaje, para presentar y analizar los resultados.
El método descrito por los autores del artículo original se puede utilizar para cualquier problema de clasificación, donde los datos se pueden representar como un conjunto de signos de una dimensión fija. A diferencia de otros algoritmos de visualización, este enfoque se puede usar para cualquier clasificador arbitrariamente complejo y para conjuntos de datos con un número arbitrario de ejemplos, incluso con uno muy pequeño, porque incluso con pequeños El algoritmo funciona de manera estable, sin perder mucha calidad.