Hola a todos!
Es posible que ya conozca la iniciativa Machine Learning for Social Good (# ml4sg) de la comunidad Open Data Science. Dentro de su marco, los entusiastas usan métodos de aprendizaje automático para resolver problemas socialmente significativos de forma gratuita. Nosotros, el equipo del proyecto Lacmus (#proj_rescuer_la), estamos involucrados en la implementación de soluciones modernas de aprendizaje profundo para encontrar personas que se pierden fuera del área poblada: en el bosque, el campo, etc.

Según estimaciones aproximadas, en Rusia más de cien mil personas desaparecen cada año. La parte tangible de ellos son personas que han perdido su camino lejos de la habitación humana. Afortunadamente, algunos de los que se pierden son elegidos por ellos mismos; los equipos voluntarios de búsqueda y rescate se movilizan para ayudar a otros. El destacamento más famoso es, tal vez, Lisa Alert, pero quiero señalar que él no es el único.
Los principales métodos de búsqueda en este momento, en el siglo XXI, son peinar los alrededores a pie utilizando medios técnicos, que a menudo no son más complicados que una sirena o un faro zumbido. El tema, por supuesto, es relevante y candente, da lugar a muchas ideas para utilizar el progreso científico y tecnológico en la búsqueda de logros; algunos de ellos incluso se materializan en forma de prototipos y se prueban en competiciones especialmente organizadas. Pero el bosque es el bosque, y las condiciones reales de la búsqueda, junto con los recursos materiales limitados, hacen que este problema sea difícil y aún muy lejos de ser una solución completa.
Recientemente, los rescatistas utilizan cada vez más vehículos aéreos no tripulados (UAV) para inspeccionar grandes áreas del territorio, fotografiando el terreno desde una altura de 40-50m. Con una operación de búsqueda y rescate, se obtienen varios miles de fotografías, que hasta la fecha, los voluntarios miran manualmente. Está claro que dicho procesamiento es largo e ineficiente. Después de dos horas de tal trabajo, los voluntarios se cansan y no pueden continuar la búsqueda, y después de todo, la salud y la vida de las personas dependen de su velocidad.
Junto con los equipos de búsqueda y rescate, estamos desarrollando un programa para buscar personas desaparecidas en imágenes tomadas con vehículos aéreos no tripulados. Como especialistas en aprendizaje automático, nos esforzamos por hacer que la búsqueda sea automática y rápida.

Diferencias de soluciones similares
Sería injusto decir que Lacmus es el único proyecto que se desarrolla en esta dirección. Sin embargo, parece que pocas personas se están desarrollando en estrecha cooperación con los equipos de rescate, centrándose en sus necesidades y capacidades urgentes. Hace algún tiempo, se celebró la competencia Odyssey, en la que diferentes equipos compitieron en la formación de la mejor solución para buscar y salvar personas, incluido el uso de vehículos aéreos no tripulados. Al estar en la etapa inicial de desarrollo, asistimos a esta competencia no como participantes, sino como observadores. Al comparar los resultados de la competencia, la información sobre proyectos similares y nuestra experiencia en la comunicación con equipos como Lisa Alert, Owl, Extreme, quiero señalar los problemas inherentes a muchos análogos:
- El costo de implementación. Algunos equipos del concurso Odyssey están desarrollando sus propios drones innovadores y UAV. Pero debe comprender que PSO en Rusia generalmente opera sin fines de lucro, y equipar a los operadores de drones con máquinas con un valor de más de 1,000,000 de rublos es demasiado costoso. Además, no basta con producir un avión, es necesario establecer su mantenimiento. Es difícil para las pequeñas empresas ofrecer soluciones por el mismo dinero que las de los competidores chinos.
- El enfoque comercial de muchas soluciones. Los proyectos empresariales no tienen nada de malo, pero encontrar personas perdidas en el bosque es una tarea bastante específica; no todos los desarrollos comerciales pueden integrarse en él. Puede hacer un dron maravilloso y pegar una neurona que reconozca los cultivos allí, pero es poco probable que un proyecto de este tipo sea útil para encontrar personas en el bosque utilizando equipos de búsqueda de voluntarios: aquí necesita la solución más barata pero efectiva. Las costosas cámaras multicanal no son adecuadas aquí. Solo RGB, solo hardcore. Por las mismas razones, las cámaras termográficas también desaparecen, cuyos modelos baratos tienen una resolución muy baja. (Y en general, las cámaras termográficas son ineficaces aquí, porque una persona congelada en el bosque emite muy poco calor).
- Las arquitecturas de redes neuronales populares utilizadas en las soluciones conocidas (YOLO, SSD, VGG) tienen métricas de buena calidad en conjuntos de datos públicos como ImageNet, pero no funcionan bien en imágenes en nuestro área de dominio bastante específica. (Acerca de la elección de la arquitectura de red neuronal, opciones y características probadas y probadas utilizadas al final, a continuación).
- Casi nadie usa las oportunidades para optimizar modelos para inferencia. En las áreas de búsqueda, a menudo no hay conexión a Internet, por lo que debe procesar las imágenes recibidas localmente. La mayoría de los equipos de rescate usan computadoras portátiles con GPU de baja potencia, o sin ellas, ejecutan redes neuronales en CPU convencionales. Es fácil calcular que si se gasta un promedio de 10 segundos en procesar una sola imagen, se procesarán 1000 imágenes en aproximadamente 3 horas. Aquí, podemos decir que cada segundo es importante.
- Cerramiento de desarrollos existentes. Todas las soluciones que conocemos son cerradas y propietarias. Pero el problema es demasiado complejo para ser resuelto por las fuerzas de un pequeño puñado de personas, y no por todos los que están dispuestos a ayudar. Por lo tanto, estamos desarrollando una solución de código abierto: es extraño pensar que un tema que atrae a tantos voluntarios que trabajan "en el campo" no será igualmente interesante para los especialistas de TI.
- Falta de libertad de distribución. Los PSO voluntarios a menudo no están centralizados, los enfoques de trabajo y las aplicaciones se transfieren de mano en mano, el software con copias con licencia no funcionará aquí. Es por eso que, entre otras cosas, hemos elegido una estrategia de código abierto y distribución abierta para que cualquiera pueda descargar nuestra solución y usarla. ¡Somos para la ciencia abierta y el código abierto!
Preparación de datos
Parecería que si cada operación de búsqueda que usa UAV traiga miles de fotos, la matriz de datos acumulados debería ser enorme: tomar y entrenar. No todo resultó ser tan simple, porque:
- No hay almacenamiento centralizado para datos etiquetados. Las imágenes tomadas durante las operaciones de búsqueda no se usan ni procesan en el futuro.
- Los datos obtenidos están muy desequilibrados. En una toma con la persona encontrada, hay varios miles de fotografías "en blanco". Dado que la información sobre las imágenes escaneadas no se registra en ninguna parte, para encontrar las necesarias entre ellas, es necesario realizar una gran cantidad de trabajo por segunda vez, gracias a los esfuerzos de un pequeño equipo que no tiene "ojos entrenados".
- Cada imagen, en sí misma, también está "desequilibrada": la persona deseada ocupa una pequeña fracción de toda el área de la imagen. Obviamente, una buena red neuronal no solo debería ser capaz de decir que, en su opinión, una persona está presente en la imagen, sino que debe rodear un lugar específico (es decir, realizar la tarea de detectar objetos, no clasificar imágenes). De lo contrario, el operador pasará más tiempo y energía mirándolo, y también puede rechazar por error la foto deseada. Pero para esto, la red neuronal debe aprender de los datos marcados, en fotografías, donde se marca el objeto deseado usando un software especial. Nadie lo hará durante una operación de búsqueda, no antes.
- Las estadísticas sobre las poses en las que se encontraron las personas, la época del año, el tipo de terreno y otras características de las imágenes no se tienen en cuenta. Dichos datos serían muy útiles para crear imágenes de entrenamiento "sintéticas" usando fotografía en escena, editores de fotos o modelos generativos, pero para usar todo esto necesita comprender cómo se ve una fotografía con una persona realmente perdida. Ahora, al reconstruir tales fotografías, uno tiene que confiar en la experiencia subjetiva de los expertos en rescate.
- Además de las dificultades técnicas, son posibles obstáculos legales que imponen restricciones a la propiedad de las imágenes obtenidas. A menudo, nuestras solicitudes de ayuda para recopilar datos permanecen sin respuesta. Debido a la falta de tales datos, problemas legales o pereza común, no está claro.
Por lo tanto, la información valiosa no se utiliza de ninguna manera para entrenar redes neuronales, perdiéndose o muerto en algún lugar en discos y almacenamientos en la nube, en lugar de mejorar el volumen y la calidad de la muestra de entrenamiento. Estamos escribiendo un servicio que permitirá, entre otras cosas, subirnos fotos valiosas (sobre esto también a continuación), pero hay, como siempre, más tareas que personas.
Además, hasta la fecha, la red tiene muy pocos conjuntos de datos buenos (abiertos) con imágenes de UAV. El más adecuado que encontramos es
Stanford Drone Dataset (SDD) . Es una fotografía desde una altura sobre el campus universitario, con objetos marcados de la clase "Peatón" (peatón), junto con ciclistas, autobuses y automóviles. A pesar del ángulo de disparo similar, los peatones fotografiados y el entorno tienen poco en común con lo que sucede en nuestras imágenes. Los experimentos realizados en este conjunto de datos mostraron que las métricas de calidad de los detectores entrenados en él en nuestros datos muestran un resultado bajo. Como resultado, ahora usamos SDD para entrenar la denominada columna vertebral, que extrae atributos de nivel superior, y las capas extremas deben completarse en las imágenes de nuestra área de dominio.
Es por eso que nos comunicamos por primera vez con varios motores de búsqueda y rescatadores durante mucho tiempo, tratando de entender cómo se ve una persona que se perdió en el bosque en una imagen desde arriba. Como resultado, recopilamos estadísticas únicas sobre 24 poses, en las que se encuentran con mayor frecuencia personas desaparecidas. Filmamos y marcamos nuestro propio conjunto de datos: Lacmus Drone Dataset (LaDD), que en la primera versión incluía más de 400 imágenes. El rodaje se llevó a cabo principalmente con la ayuda de DJI Mavic Pro y Phantom desde una altura de 50 a 100 metros, la resolución de las imágenes fue de 3000x4000, el tamaño medio de la persona fue de 50x100 px. Por el momento, ya tenemos la cuarta versión del conjunto de datos con 2 mil imágenes, tanto reales como "simuladas". Continuamos trabajando para reponer el conjunto de datos y la quinta versión está a la vuelta de la esquina.
A medida que reponemos nuestro conjunto de datos, hemos llegado a la necesidad de separar las imágenes por temporada. El hecho es que un modelo entrenado en fotos de invierno muestra mejores resultados que un modelo entrenado en todo el conjunto de datos, ya sea en verano o en primavera por separado. Quizás los letreros sobre un fondo nevado se extraen mejor que sobre hierba ruidosa.

Al mismo tiempo, cuando se entrena solo en imágenes de invierno, aumenta el número de falsos positivos (falsos positivos). Aparentemente, las imágenes de diferentes estaciones son paisajes (dominios) demasiado diferentes y la red neuronal no puede generalizarlos. Esto queda por verse, y hasta ahora vemos dos formas:
- Haga muchas cuadrículas "pequeñas" y apréndalas para diferentes dominios por separado (una para el invierno, otra para el verano ... Además de las estaciones, también puede desglosar por área: por ejemplo, un modelo para la franja central y las llanuras, otro para el sur, etc.) .
- Aumente repetidamente nuestros datos e intente entrenar el modelo a la vez en todos los dominios. Según la solución de un problema similar en un artículo de Yandex, tendemos a probar esta opción en particular. Es difícil recopilar una gran cantidad de fotos reales con personas perdidas por las razones ya descritas, por lo tanto, tal vez, intentemos recrear ejemplos educativos realistas basados en imágenes "vacías" (hay muchas). Por lo tanto, pronto podremos tener GAN.
Proceso de aprendizaje
La naturaleza de nuestras imágenes es significativamente diferente de las imágenes de conjuntos de datos populares como ImageNet, COCO, etc. Dado que las redes neuronales desarrolladas para tales conjuntos podrían ser poco adecuadas para nuestra tarea, fue necesario realizar un estudio de la aplicabilidad de varias arquitecturas. Para hacer esto, tomamos modelos previamente entrenados en ImageNet, los volvimos a capacitar en el Stanford Drone Dataset, después de lo cual "congelamos" la columna vertebral, y el resto de los detectores fueron entrenados directamente en nuestras imágenes. Las mejores métricas se presentan en la tabla:
Además de los números en la tabla anterior, debe prestar atención a tal característica de las imágenes de Lacmus Drone Dataset como un gran desequilibrio de clase: la relación del área de fondo al área del rectángulo (ancla) con el objeto deseado es de varios miles. Al entrenar el detector, esto conlleva dos problemas:
- La mayoría de las regiones con antecedentes no llevan ninguna información útil.
- Las regiones con objetos debido a su pequeño número tampoco contribuyen significativamente al entrenamiento de pesas.
Para evitar estos problemas, se utilizaron varios esquemas de capacitación, configuraciones de red y muestras de capacitación. Una de las arquitecturas de redes neuronales que probamos, RetinaNet, está dirigida precisamente a reducir los efectos negativos de un gran desequilibrio de clase. Los creadores de RetinaNet lo diseñaron para aumentar la precisión de los detectores de una etapa (cubriendo la imagen con una densa red de anclajes de rectángulos predefinidos y luego refinando los que mejor cubren el objeto) en comparación con detectores de dos etapas más lentos pero de mejor calidad (los estudiantes aprenden a encontrar regiones candidatas primero , luego especifique su posición). Desde el punto de vista de los autores del artículo sobre RetinaNet, los detectores de una etapa pierden precisamente debido al desequilibrio causado por una gran cantidad de anclajes vacíos. En el contexto de esta ventaja, nuestra elección se hizo a favor de RetinaNet con la red troncal ResNet50.
La arquitectura de esta red
se introdujo en 2017. La característica principal de RetinaNet, que le permite lidiar con los efectos negativos de los desequilibrios de clase en el entrenamiento, es la función original de
pérdida de pérdida
focal :
Donde
p es la probabilidad estimada del contenido en la región del objeto deseado estimado por el modelo (en pocas palabras, la salida de la red neuronal si se reduce al intervalo [0, 1]).
En otros dominios de dominio, la función de pérdida debería, por regla general, ser resistente a casos atípicos (ejemplos difíciles), que probablemente son valores atípicos; su impacto en el entrenamiento con pesas debe reducirse. En Pérdida focal, por el contrario, la influencia de un fondo que ocurre con frecuencia (inliers, ejemplos fáciles) se reduce, y los objetos raramente vistos tienen la mayor influencia al entrenar pesas RetinaNet. Esto se hace debido a esta parte de la fórmula:
Coeficiente
en el exponente determina el "peso" de ejemplos duros en la función de pérdida total.
Durante el proceso de entrenamiento de RetinaNet, la función de pérdida se calcula para todas las orientaciones consideradas de las áreas candidatas (anclajes), a partir de todos los niveles de escala de imagen. En total, hay aproximadamente 100k áreas para una imagen, lo cual es muy diferente del enfoque de muestreo heurístico (RPN) o de búsqueda de casos raros (OHEM, SSD) con un pequeño número de áreas (aproximadamente 256) para cada minibatch. El valor de pérdida focal se calcula como la suma de los valores de función para todos los anclajes, normalizados por el número de anclajes que contienen los objetos deseados. La normalización se realiza solo en ellos, y no en el número total, ya que la gran mayoría de los anclajes son un fondo fácilmente identificable, con poca contribución a la función de pérdida general.
Estructuralmente, RetinaNet consta de una red troncal y dos definiciones adicionales de subred de clasificación y subred de regresión de caja.
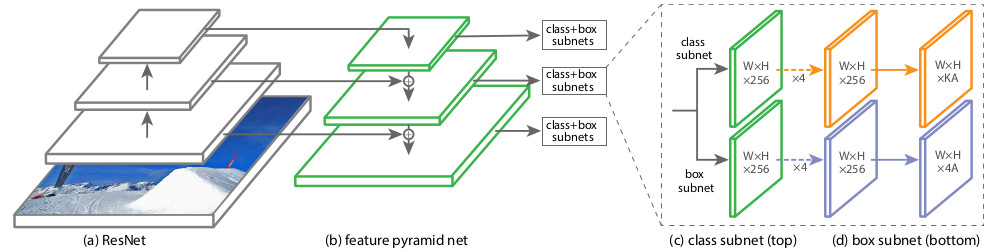
Como columna vertebral, se utiliza la denominada
Red de pirámide de características , FPN, que trabaja sobre una de las redes neuronales convolucionales comúnmente utilizadas (por ejemplo, ResNet50). FPN tiene salidas laterales adicionales de capas ocultas de la red de convolución, formando niveles piramidales con diferentes escalas. Cada nivel se complementa con una "vía de arriba hacia abajo", es decir información de niveles superiores que son más pequeños, pero que contienen información sobre áreas de un área más grande. Parece un aumento artificial (por ejemplo, simplemente repitiendo elementos) de un mapa de características más "minimizado" al tamaño del mapa actual, agregándolos elemento por elemento y transfiriéndolos a los niveles inferiores de la pirámide y a la entrada de las otras subredes (es decir, en la subred de clasificación y Subred de regresión de caja). Esto le permite seleccionar de la imagen original una pirámide de signos a diferentes escalas, en la que se pueden detectar objetos grandes y pequeños. FPN se utiliza en muchas arquitecturas, mejorando la detección de objetos de varios tamaños: RPN, DeepMask, Fast R-CNN, Mask R-CNN, etc.
Puede leer más sobre FPN en el
artículo original.
En nuestra red, como en el original, FPN con 5 niveles numerados con
por
. Nivel
tiene permiso para
veces más pequeño que la imagen de entrada (no entraremos en detalles de qué puntos de ResNet provienen; esto romperá la pierna). Todos los niveles de la pirámide tienen el mismo número de canales C = 256 y el número de anclas A aproximadamente 1000 (dependiendo del tamaño de las imágenes).
Las anclas tienen áreas de [16 x 16] a [256 x 256] para cada nivel de la pirámide desde
antes
en consecuencia, con un paso de desplazamiento (zancadas) [8 - 128] px. Este tamaño le permite analizar objetos pequeños y algunos alrededores. Por ejemplo, una rama, si no tiene en cuenta su realidad circundante, es muy similar a una persona mentirosa.
El FPN original utiliza tres relaciones de aspecto de los anclajes (1: 2, 1: 1, 2: 1); RetinaNet aspect ratio [
]. 9- , / 16 400 px.
Classification Subnet . (Fully ConvNet, FCN), FPN. , :
- (W x H x C)
- 33
- ReLU
- 33 ( ) ,
- -
x A, K — . — Pedestrian.
Box Regression Subnet 4- . , FPN, Classification Subnet. , , (4 ) — :
, , IoU (Intersection over Union) > 0.5.
1, 0. .
( ) forward . 1k , 0,05. , threshold = 0,5.
RetinaNet
towardsdatascience .
, . OpenSource-, Github fizyr:
keras-retinanet , .
, , 20-30 . , :
Y también ...
- Nvidia Jetson
- Corral Edge TPU
tensoflow 1.14 CPU AVX Intel nndl. AVX ( 2012 ) , Core 2 Duo!
Albumentations .
:
Producción
docker
desktop- c , . Nvidia Cuda CuDNN TensorFlow — . , Python . - , . — Docker. web- . , docker-. GUI . GUI , , , , . Docker API, GUI, . , Docker , .
#
. 3 :
dotnext . «! - ! - ? », — ! GUI # AvaloniaUI, 64- Win10, Linux Mac.
AvaloniaUI — , . WPF, , . , 2D- , WPF. , WPF.
, SkiaSharp GTK ( Unix ). X11 . , , (!). .Net Core Bios', AvaloniaUI .
AvaloniaUI , , . , 2019 , . WPF C# — . ( electron), , .
 ...
..., , issue. , ,
,
.
.
@kekekeks . , .NET .
desktop- mlOps- . :
- ;
- , ;
- proporcionar acceso a la nube a los equipos de búsqueda y rescate para que también puedan usar los datos acumulados si es necesario;
La arquitectura general del sistema se parece a esto:
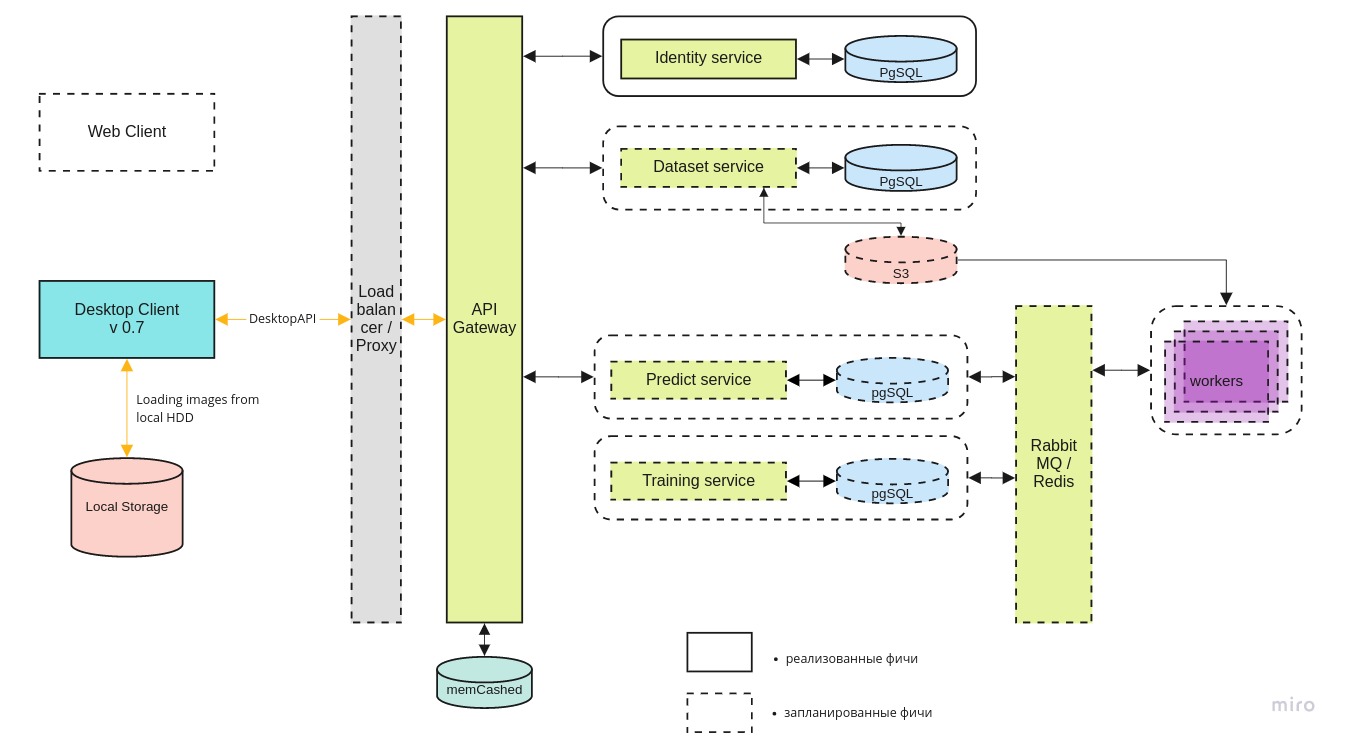 Desktop-client
Desktop-client puede funcionar tanto con la versión local del contenedor docker como con la última versión en el servidor central, a través de la API REST.
El microservicio de
identidad proporciona acceso al servidor solo para usuarios autorizados.
El servicio de
conjunto de datos se utiliza para almacenar tanto las imágenes como su marcado.
El servicio de
predicción le permite procesar rápidamente una gran cantidad de imágenes en presencia de un amplio canal para pilotos.
Se necesita un servicio de
capacitación para probar nuevos modelos y reentrenar los existentes a medida que llegan nuevos datos.
La cola de tareas se gestiona utilizando RabbitMQ / Redis.
Búsqueda de capacidades de GPU
A pesar de que la inferencia de la red neuronal puede funcionar incluso en una computadora portátil simple, se necesita una GPU para entrenar el modelo. Técnicamente, puedes entrenarlo en la CPU, pero en la práctica lleva demasiado tiempo. No todas las personas que vienen al equipo tienen una computadora adecuada para el aprendizaje profundo, por lo que estamos en busca de capacidades de GPU centralizadas.
En este momento estamos negociando con
DTL y esperamos que la cooperación se desarrolle. La singularidad de los servidores DTL GPU es el uso de enfriamiento por inmersión: inmersión de bastidores en un fluido dieléctrico especial. Se ve así:

 (Nota del fotógrafo: el azul no es un resplandor Cherenkov. Es un punto destacado en ellos).
(Nota del fotógrafo: el azul no es un resplandor Cherenkov. Es un punto destacado en ellos).Digresión lírica. "¿Conoces la red neuronal de Beeline?"
Honestamente, realmente no quiero tocar este tema (resbaladizo), pero continúa tocándonos, por lo que es imposible fingir que estamos en el tanque. Sí, sabemos sobre la red neuronal de Beeline. Según los comentarios de los pilotos que cooperaron con nosotros, funciona peor que nuestra versión y solo en plataformas de alta gama. Según los desarrolladores de Beeline, el proyecto está congelado y no se está desarrollando ahora. Desde el punto de vista del sentido común, las noticias en el espíritu de Beeline fueron las primeras en Rusia en desarrollar una red neuronal de este tipo. Pocas personas incluso implementan arquitecturas diseñadas por laboratorios como Facebook Research o Google Brain, y mucho menos crean las suyas. En la mayoría de los casos, se trata de adaptar una biblioteca pública de código abierto a las necesidades de su área temática. Con qué frecuencia se usan las bibliotecas abiertas en el software comercial ruso, todos los que desarrollan este software lo saben. En su mayor parte, ni siquiera hay una violación de la licencia; pero dejar salir los logros del OpenSource internacional en su conjunto su desarrollo y hacer relaciones públicas en voz alta al menos es feo. Parece que también se utilizaron nuestros logros: en particular, en
nuestra gamificación nuestras fotos se
encendieron. Compare con la foto de "invierno" de la sección sobre el conjunto de datos de Lacmus:

Hay otras razones para creer que el asunto no se limitó a los datos aquí.
Lo que es malo para nosotros, en primer lugar, es que la red neuronal Beeline ahora no está torcida hasta la imposibilidad. Cuando se menciona, es imposible entender si realmente se trata de ella, de nuestra aplicación o, en general, de la opción de otra persona. En condiciones de descentralización, poca capacidad de control de JI y un pequeño número de canales de retroalimentación, cualquier información sobre la prevalencia y la calidad del trabajo de Lacmus sería útil, así como sobre desarrollos similares, pero la exageración en torno a Beeline eclipsó todo.
Planeamos continuar monitoreando la situación por ahora, pero nuestra solicitud a la comunidad es, en primer lugar, decir "red neuronal Beeline" solo cuando estén 100% seguros de que es así, y en segundo lugar, leer las licencias de código abierto e indicar honestamente la autoría.
Resumen
Durante el pasado 2019, miembros de la Fundación Lacmus:
- Filmamos y marcamos un conjunto de datos único, cuya última versión incluye más de 2000 imágenes;
- probé varias arquitecturas de redes neuronales diferentes y elegí la más adecuada;
- Seleccionamos los mejores hiperparámetros de la red neuronal y los capacitamos en nuestros propios datos únicos para el reconocimiento más preciso;
- desarrolló una aplicación multiplataforma para operadores de UAV con la capacidad de usar cuando trabaja fuera de línea;
- optimizamos el trabajo de nuestra red neuronal para trabajar en computadoras portátiles económicas y de bajo consumo;
Por el momento, los mejores indicadores de la métrica mAP de la red neuronal LAPMUS son 94%. Nuestro programa está listo para su uso en operaciones de búsqueda y rescate reales y ha sido probado en ejecuciones generales. En áreas abiertas del tipo "campo" y "cortavientos" se encontraron todas las pruebas "perdidas". Ya ahora Lakmus es utilizado por los equipos de rescate y ayuda a encontrar personas.
Y también recibimos el Premio al Proyecto del Año de Open Data Science:

Este año planeamos:
- encuentre un socio para una infraestructura de alojamiento confiable;
- implementar interfaz web y mlOps;
- formar un gran conjunto de datos sintéticos en el motor UE4 o con la ayuda de GAN;
- lanzar una competencia InClass en Kaggle para todos los que quieran actualizar sus habilidades de DL / CV y buscar las mejores soluciones SOTA;
- agregue a nuestra retinanet aún más implementaciones de backbones y variaciones de esta arquitectura;
Realmente carecemos de trabajadores para implementar estos planes, por lo que nos alegraremos con todos independientemente del nivel y la dirección de la capacitación.
Si juntos podemos salvar al menos a una persona más, entonces todos los esfuerzos no serán en vano.
Como ayudar al proyecto
Somos un proyecto OpenSource, ¡y con gusto aceptaremos a todos! Aquí están los enlaces a nuestros repositorios de github:
Si es desarrollador y desea unirse al proyecto, puede escribir a Perevozchikov Georgy Pavlovich,
gosha20777 en todas las redes sociales,
gosha20777@live.ru o unirse al proyecto a través del canal
# ml4sg en ODS (si está allí).
Necesitamos:
- Desarrolladores de ML
- Desarrolladores de C # / go / python;
- Trabajadores de primera línea;
- Beckers
- ¡Solo personas activas de cualquier dirección! ¡Siempre nos alegrará verte!
Si no está involucrado en el desarrollo, también puede ayudar al proyecto:
- Puedes ayudarnos a escribir artículos;
- Puede ayudarnos a escribir documentación de usuario y un wiki (y corregir los errores de gramática allí)))
- Puede permanecer en el rol de gerente de producto y completar tareas en trello;
- Puedes ofrecernos una idea;
- Puedes distribuir esta publicación;
Acerca del equipo
Gerente de proyecto: Georgy Pavlovich Perevozchikov,
gosha20777 .
Una lista incompleta de los involucrados (de hecho, es mucho más grande, si ha sido injustamente olvidado, dígame y agregaremos):
- Los participantes de SAO más activos en el canal #proj_rescuer_la : Kseniia, balezz, ei-grad, Palladdiumm, sharov_am, dartov
- Participantes del proyecto fuera de ODS: Martynova Viktoriya Viktorovna (organización del proyecto, recopilación de datos y etiquetado), Denis Petrovich Shurankov (organización de recopilación de datos), Daria Pavlovna Perevozchikova (etiquetó aproximadamente el 30% de todas las fotos).
- Operadores de vehículos aéreos no tripulados del escuadrón Liza Alert, que ayudaron con las imágenes y la formación del conjunto de datos: Partyzan, Vanteyich, Sevych, California, Tarekon, Evgen, GB.
Un agradecimiento especial:
- Para programadores de AvaloniaUI: el mejor marco .NET: worldbeater , kekekeks , Larymar
- Administradores de SAO para organizar la comunidad más cool: natekin, Sasha, mephistopheies.
Este artículo fue coescrito con
balezz y
gosha20777 habrozhitelami .
¡Todos sean ingeniosos y nunca se pierdan!
 Video demostrativo de trabajo para el postre. Versión alfa pre temprana. Para los que leen hasta el final. Febrero de 2019.
Video demostrativo de trabajo para el postre. Versión alfa pre temprana. Para los que leen hasta el final. Febrero de 2019.