Hace dos años comencé a desarrollar uno mas un generador de código gratuito de OpenAPI Specification v3 a TypeScript ( está disponible en Github ). Inicialmente, me propuse hacer una generación eficiente de tipos de datos primitivos y complejos en TypeScript, teniendo en cuenta varias características del esquema JSON , como oneOf / anyOf / allOf , etc. (La solución nativa de Swagger tuvo algunos problemas con esto). Otra idea era usar esquemas de especificaciones para validación en la parte frontal, posterior y otras partes del sistema.

Ahora el generador de código está relativamente listo, está en la etapa MVP . Tiene mucho de lo que se necesita en términos de generación de tipos de datos, así como una biblioteca experimental para generar servicios front-end (hasta ahora para Angular). En este artículo quiero mostrar los desarrollos y decirles cómo pueden ayudar si usa TypeScript y OpenAPI v3. En el camino, quiero compartir algunas ideas y consideraciones que han surgido en mi proceso de trabajo. Bueno, si está interesado, puede leer la historia de fondo que escondí en el spoiler para no complicar la lectura de la parte técnica.
Contenido
- Antecedentes
- Descripción
- Instalación y uso
- Practica usando un generador de código
- Uso de tipos de datos generados en aplicaciones
- Descomposición de circuitos dentro de la especificación OEA
- Descomposición anidada
- Servicios generados automáticamente para trabajar con la API REST
- ¿Por qué se necesita esto?
- Servicio de generación
- Usar servicios generados
- En lugar de un epílogo
Antecedentes
Expandir para leer (omitir)Todo comenzó hace dos años, luego trabajé en una empresa que desarrollaba una plataforma de minería de datos y fui responsable de la interfaz (principalmente TypeScript + Angular). Las características del proyecto eran estructuras de datos complejas con una gran cantidad de parámetros (30 o más) y no siempre relaciones comerciales obvias entre ellos. La compañía estaba creciendo y el entorno de software estaba experimentando cambios bastante frecuentes. El frontend tenía que estar bien informado sobre los matices, porque algunos cálculos estaban duplicados en el frente y en el backend. Es decir, este fue el caso cuando usar OpenAPI es más que apropiado. Encontré un período en la empresa en el que en cuestión de meses el equipo de desarrollo adquirió una sola especificación, que se convirtió en una base de conocimiento común para el departamento posterior, frontal e incluso central, que estaba oculto detrás del amplio back-end web. La versión de OpenAPI fue elegida "para el crecimiento", entonces todavía bastante joven v3.0
Esto ya no era una especificación en uno o más archivos YML / JSON estáticos, y no el resultado de anotadores , sino una biblioteca completa de componentes, métodos, plantillas y propiedades, organizados de acuerdo con el concepto DDD de la plataforma. La biblioteca se dividió en directorios y archivos, y un recolector especialmente organizado produjo documentos de la OEA para cada área temática. Se creó una forma experimental de flujo de trabajo, que podría describirse como Design-First.
Hay un buen artículo en el blog de la compañía Yandex.Money, que habló sobre Design First
Design First y la especificación general ayudaron a desacralizar el conocimiento, pero se hizo evidente un nuevo problema: mantener la relevancia del código. La especificación describe varias docenas de métodos y docenas (y luego cientos) de entidades. Pero el código tenía que escribirse manualmente: tipos de datos, servicios para trabajar con REST, etc. Uno o dos sprints con historias paralelas cambiaron enormemente la imagen; Agregar complejidad a la fusión de varias historias y el factor humano. La rutina amenazaba con ser significativa, y la solución parecía obvia: necesita generar código. Después de todo, las especificaciones de la OEA ya contenían todo lo necesario para no volver a escribirlo manualmente. Pero no fue tan simple.
La interfaz está al final del ciclo de producción, por lo que sentí cambios más dolorosos que los colegas de otros departamentos. Al diseñar la API REST, el entorno de back-end fue decisivo, e incluso después de la aprobación de "Design First", permaneció la inercia; para el front end, todo parecía menos obvio. De hecho, entendí esto desde el principio, y comencé a sondear el suelo de antemano, cuando apenas se comenzaba a hablar de una especificación "universal". No se habló de escribir su propio generador de código; Solo quería encontrar algo listo.
Estaba decepcionado Hubo dos problemas: la versión 3.0 de la OEA, con el apoyo de la cual, al parecer, nadie tenía prisa, y la calidad de las soluciones en sí mismas; en ese momento (recuerdo, esto fue hace dos años), logré encontrar dos soluciones relativamente listas: de Swagger y de Microsoft (Parece que ). En el primero, el soporte para OAS 3.0 estaba en beta profunda. El segundo funcionó solo con la versión 2.x, pero no hubo pronósticos inequívocos. Por cierto, no pude iniciar el generador de código de Microsoft incluso en un documento de prueba del formato Swagger 2.0. La solución de Swagger funcionó, pero un esquema más o menos complicado con enlaces $ ref se convirtió en un "ERROR" incomprensible, y las dependencias recursivas lo enviaron a un bucle sin fin. Hubo problemas con los tipos primitivos . Además, no entendía bien cómo trabajar con servicios generados automáticamente: parecían estar hechos para mostrar, y su uso real creó más problemas de los que resolvieron (en mi opinión). Y finalmente, la integración del archivo JAR en un CI / CD orientado a NPM fue inconveniente: tuve que descargar manualmente la instantánea necesaria , que parecía pesar 13 megabytes, y hacer algo con ella. En general, me tomé un descanso y decidí ver qué pasa después.
Después de unos cinco meses, surgió nuevamente el problema de la generación de código. Tuve que reescribir y expandir parte de la aplicación web, y al mismo tiempo quería refactorizar los servicios antiguos para trabajar con la API REST y los tipos de datos. Pero la evaluación de la complejidad no fue optimista: de una semana a dos personas, y esto es solo para servicios REST y descripciones de tipos. No diré que me deprimió mucho, pero aún así. Por otro lado, nunca encontré una solución para la generación de código y no esperé, y su implementación difícilmente tomaría menos tiempo. Es decir, no había dudas al respecto: el beneficio es dudoso, los riesgos son grandes. Nadie apoyaría esta idea, y no lo propuse. Mientras tanto, se acercaban las vacaciones de mayo, y la compañía me "debió" varios días por trabajar el fin de semana. Durante dos semanas me escapé de todas las experiencias laborales a Georgia, donde una vez viví durante casi un año.
Entre fiestas y fiestas, necesitaba hacer algo, y decidí escribir mi decisión. Trabajar en cafés de verano cerca de Vake Park fue sorprendentemente productivo, y volví a Peter con un generador de código listo para usar para tipos de datos. Luego, durante otro mes, "terminé" los servicios los fines de semana antes de que estuviera listo para trabajar.
Desde el principio, abrí el generador de código, trabajando en él en mi tiempo libre. Aunque, de hecho, escribió para un borrador de trabajo. No diré que la revisión / ejecución se realizó sin ningún problema; y no diré que fueron significativos. Pero en algún momento noté que dejé de usar la documentación Redoc / Swagger: navegar por el código era más conveniente, siempre que el código esté siempre actualizado y comentado. Pronto, "anoté" mis logros, sin desarrollarlos en absoluto, hasta que un colega (ahora hace seis meses que me fui a otra empresa) me aconsejó que los tomara más en serio (también se le ocurrió el nombre).
No tenía suficiente tiempo libre y me llevó varios meses finalizar en segundo plano: área de juegos , aplicación de prueba, reorganización del proyecto. Ahora estoy listo para recibir comentarios.
Descripción
Por el momento, la solución para la generación de código incluye tres bibliotecas NPM integradas en el @codegena @codegena y ubicadas en un mono-repositorio común:
Instalación y uso
La opción más práctica es usar los scripts NodeJS que se ejecutan desde la CLI. Primero necesitas instalar las dependencias:
npm i @codegena/oapi3ts, @codegena/ng-api-service, @codegena/oapi3ts-cli
Luego, cree un archivo js (por ejemplo, update-typings.js ) con el código:
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings();
Y comience pasando tres parámetros:
node ./update-typings.js --srcPath ./specs/todo-app-spec.json --destPath ./src/lib --separatedFiles true
En destPath se generarán archivos y, de hecho, los contenidos de este directorio en el repositorio del proyecto se crean de la misma manera. Aquí está el script generador , y así es como se ejecuta en los scripts NPM. Sin embargo, si lo desea, puede usarlo incluso en el navegador, como se hace en Playground .
Practica usando un generador de código
A continuación, quiero hablar sobre lo que obtendremos como resultado: cuál es la idea de cómo esto nos ayudará. Una ayuda visual será el código de la aplicación de demostración. Consta de dos partes: un back-end (en el marco NestJS ) y una interfaz (en Angular ). Si lo desea, incluso puede ejecutarlo localmente .
Incluso si no está familiarizado con Angular y / o NestJS, esto no debería causar problemas: la mayoría de los desarrolladores de TypeScript deben entender los ejemplos de código que se proporcionarán.
Aunque la aplicación se simplifica tanto como sea posible (por ejemplo, el back-end almacena datos en una sesión, no en la base de datos), traté de recrear el flujo de datos y las características de la jerarquía de tipos de datos inherentes a la aplicación real. Está listo en un 80-85%, pero el "acabado" puede retrasarse, pero por ahora es más importante hablar sobre lo que ya está allí.
Uso de tipos de datos generados en aplicaciones
Supongamos que tenemos una especificación OpenAPI (por ejemplo, esta ) con la que tenemos que trabajar. No importa si creamos algo desde cero, o si apoyamos, hay una cosa importante con la que es más probable que comencemos: escribir. Comenzaremos a describir los tipos de datos básicos o haremos cambios en ellos. La mayoría de los programadores hacen esto para facilitar su desarrollo futuro. Para que no tenga que revisar la documentación una vez más, tenga en cuenta los listados de parámetros; y puede estar seguro de que el IDE y / o el compilador notarán un error tipográfico.
Nuestra especificación puede o no incluir la sección de componentes . Pero, en cualquier caso, describirá conjuntos de parámetros, solicitudes y respuestas, y podemos usarlo. Considere un ejemplo:
@Controller('group') export class AppController {
Este es un fragmento de controlador para el marco NestJS con parámetros ( RewriteGroupParameters ), cuerpo de solicitud ( RewriteGroupRequest ) y cuerpo de respuesta ( RewriteGroupResponse<T> ) RewriteGroupResponse<T> . Ya en este fragmento de código podemos ver los beneficios de escribir:
- Si confundimos el nombre del parámetro destruido
groupId , especificando groupId en groupId lugar, inmediatamente recibimos un error en el editor.

- Si el método this.appService.rewriteGroup (groupId, body) tiene parámetros escritos, podemos controlar la corrección del parámetro
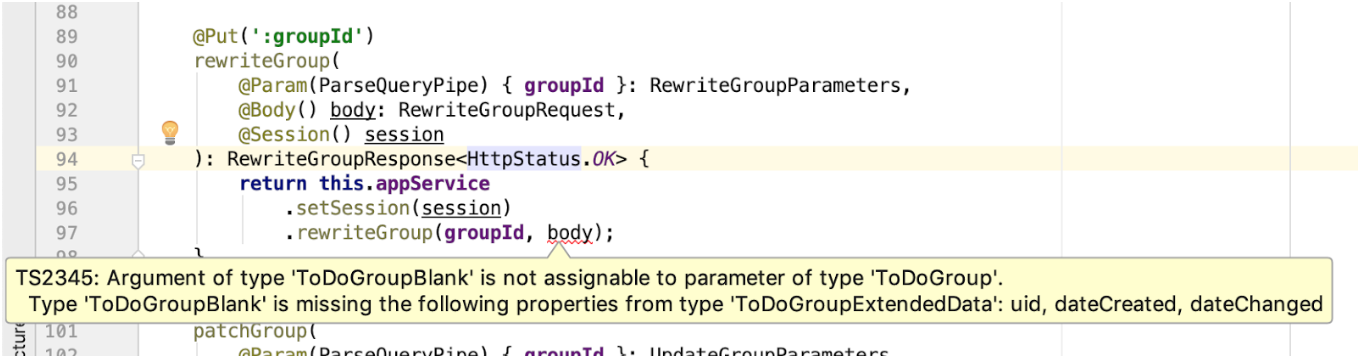
body pasado. Y si el formato de datos de entrada del método del controlador o el método del servicio cambia, lo sabremos de inmediato. Mirando hacia el futuro, noto que el método de entrada del método de servicio tiene un tipo de datos diferente de RewriteGroupRequest , pero en nuestro caso, serán idénticos entre sí. Sin embargo, si de repente se cambia el método de servicio y comienza a aceptar ToDoGroup lugar de ToDoGroupBlank , el IDE y el compilador mostrarán inmediatamente los lugares de discrepancias:
- Del mismo modo, podemos controlar el cumplimiento del resultado devuelto. Si el estado de una respuesta exitosa cambia repentinamente en la especificación y se convierte en
202 lugar de 200 , también lo descubriremos, porque RewriteGroupResponse es un genérico con un tipo enumerado :

Ahora veamos un ejemplo de la aplicación front-end que funciona con otro método API :
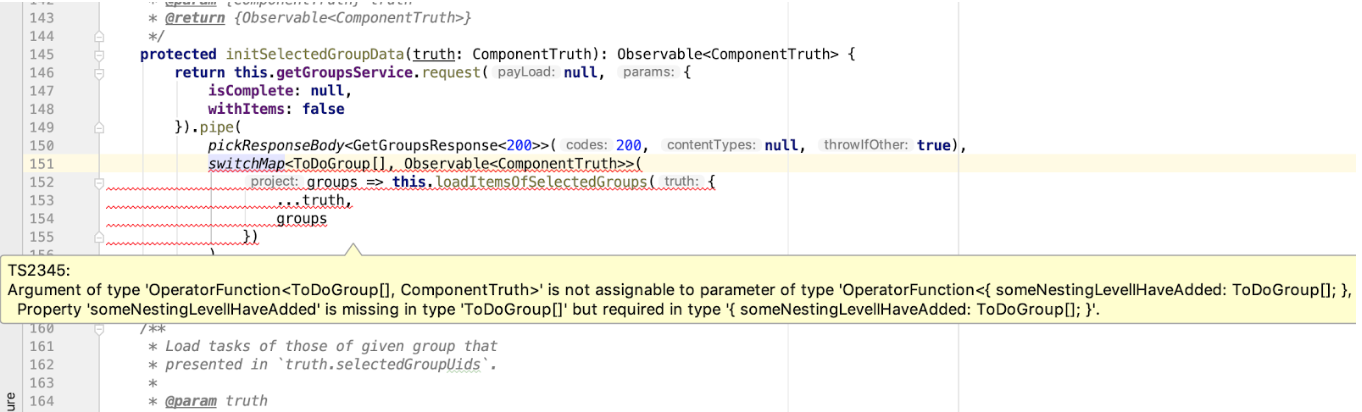
protected initSelectedGroupData(truth: ComponentTruth): Observable<ComponentTruth> { return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) ); }
No nos adelantemos y analicemos el operador pickResponseBody personalizado pickResponseBody , sino que nos centremos en el refinamiento del tipo GetGroupsResponse . Lo usamos en una cadena de operadores RxJS, y el operador que lo sigue tiene un refinamiento de entrada de ToDoGroup[] . Si este código funciona, los tipos de datos indicados se corresponden entre sí. Aquí también podemos controlar la coincidencia de tipos, y si el formato de respuesta en nuestra API cambia repentinamente, esto no escapará a nuestra atención:
Y, por supuesto, también se escriben los parámetros de llamada de this.getGroupsService.request . Pero este es el tema de los servicios generados.
En los ejemplos anteriores, vemos que la tipificación de solicitudes, respuestas y parámetros se puede utilizar en varias partes del sistema: frontend, back-end, etc. Si el backend y el frontend están en el mismo mono-repositorio y tienen un entorno ecológico compatible, pueden usar la misma biblioteca compartida con el código generado. Pero incluso si el backend y el frontend son compatibles con diferentes equipos y no tienen nada en común, excepto la especificación pública de la OEA, aún será más fácil para ellos sincronizar su código.
Descomposición de circuitos dentro de la especificación OEA
Probablemente, en los ejemplos anteriores, prestó atención a las ToDoGroup ToDoGroupBlank , ToDoGroup , con las cuales RewriteGroupResponse y GetGroupsResponse . En realidad, RewriteGroupResponse es solo un alias genérico para ToDoGroup , HttpErrorBadRequest , etc. Es fácil adivinar que tanto ToDoGroup como HttpErrorBadRequest son diagramas de la sección de especificación de componentes.schem a la que hace referencia el punto final rewriteGroup (directamente o a través de intermediarios ):
"responses": { "200": { "description": "Todo group saved", "content": { "application/json": { "schema": { "$ref": "#/components/schemas/ToDoGroup" } } } }, "400": { "$ref": "#/components/responses/errorBadRequest" }, "404": { "$ref": "#/components/responses/errorGroupNotFound" }, "409": { "$ref": "#/components/responses/errorConflict" }, "500": { "$ref": "#/components/responses/errorServer" } }
Esta es la descomposición habitual de las estructuras de datos, y su principio es el mismo que en otros lenguajes de programación. Los componentes, a su vez, también se pueden descomponer: consulte otros componentes (incluso de forma recursiva), use la combinación y otras características del esquema JSON. Pero independientemente de la complejidad, deben convertirse correctamente a descripciones de tipos de datos. Quiero mostrar cómo puede usar la descomposición en OpenAPI y cómo se verá el código generado.
Los componentes en una especificación OAS bien diseñada se superpondrán con el modelo DDD de las aplicaciones que lo utilizan. Pero incluso si la especificación es imperfecta, puede confiar en ella, creando su propio modelo de datos. Esto le dará más control sobre la correspondencia de sus tipos de datos con los tipos de datos de subsistemas integrables.
Dado que nuestra aplicación es una lista de tareas, la esencia principal es la tarea. Es lógico ponerlo en los componentes en primer lugar, porque otras entidades y puntos finales estarán de alguna manera conectados con él. Pero antes de eso necesitas entender dos cosas:
- Describimos no solo la abstracción, sino también las reglas de validación, y cuanto más precisas e inequívocas sean, mejor.
- Al igual que cualquier entidad almacenada en una base de datos, una tarea tiene dos tipos de propiedades: servicio e ingresada por el usuario.
Resulta que, dependiendo del escenario de uso, tenemos dos estructuras de datos: la Tarea que el usuario acaba de crear y la Tarea que ya está almacenada en la base de datos. En el segundo caso, tiene un UID único, fecha de creación, cambio, etc., y estos datos deben asignarse en el back-end. Describí dos entidades ( ToDoTaskBlank y ToDoTask ) de tal manera que la primera es un subconjunto de la segunda:
"components": { "ToDoTaskBlank": { "title": "Base part of data of item in todo's group", "description": "Data about group item needed for creation of it", "properties": { "groupUid": { "description": "An unique id of group that item belongs to", "$ref": "#/components/schemas/Uid" }, "title": { "description": "Short brief of task to be done", "type": "string", "minLength": 3, "maxLength": 64 }, "description": { "description": "Detailed description and context of the task. Allowed using of Common Markdown.", "type": ["string", "null"], "minLength": 10, "maxLength": 1024 }, "isDone": { "description": "Status of task: is done or not", "type": "boolean", "default": "false", "example": false }, "position": { "description": "Position of a task in group. Allows to track changing of state of a concrete item, including changing od position.", "type": "number", "min": 0, "max": 4096, "example": 0 }, "attachments": { "type": "array", "description": "Any material attached to the task: may be screenshots, photos, pdf- or doc- documents on something else", "items": { "$ref": "#/components/schemas/AttachmentMeta" }, "maxItems": 16, "example": [] } }, "required": [ "isDone", "title" ], "example": { "isDone": false, "title": "Book soccer field", "description": "The complainant agreed and recruited more members to play soccer." } }, "ToDoTask": { "title": "Item in todo's group", "description": "Describe data structure of an item in group of tasks", "allOf": [ { "$ref": "#/components/schemas/ToDoTaskBlank" }, { "type": "object", "properties": { "uid": { "description": "An unique id of task", "$ref": "#/components/schemas/Uid", "readOnly": true }, "dateCreated": { "description": "Date/time (ISO) when task was created", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" }, "dateChanged": { "description": "Date/time (ISO) when task was changed last time", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" } }, "required": [ "dateChanged", "dateCreated", "position", "uid" ] } ] } }
En la salida, obtenemos dos interfaces TypeScript, y la primera será heredada por la segunda :
export interface ToDoTaskBlank {
Ahora tenemos las descripciones básicas de la entidad Tarea, y nos referimos a ellas en el código de nuestra aplicación tal como se hizo en la aplicación de demostración :
import { ToDoTask, ToDoTaskBlank, } from '@our-npm-scope/our-generated-lib'; export interface ToDoTaskTeaser extends ToDoTask { isInvalid?: boolean; isJustCreated?: boolean; isPending?: boolean; prevTempUid?: string; }
En este ejemplo, describimos una nueva entidad, agregando a ToDoTask las propiedades que nos faltan en el lado de la aplicación front-end. Es decir, de hecho, ampliamos el modelo de datos resultante teniendo en cuenta los detalles locales. Alrededor de este modelo, un conjunto de herramientas locales y algo así como un DTO primitivo crece gradualmente:
export function downgradeTeaserToTask( taskTeaser: ToDoTaskTeaser ): ToDoTask { const task = { ...taskTeaser }; if (!task.description || !task.description.trim()) { delete task.description; } else { task.description = task.description.trim(); } delete task.isJustCreated; delete task.isPending; delete task.prevTempUid; return task; } export function downgradeTeaserToTaskBlank( taskTeaser: ToDoTaskTeaser ): ToDoTaskBlank { const task = downgradeTeaserToTask(taskTeaser) as any; delete task.dateChanged; delete task.dateCreated; delete task.uid; return task; }
Alguien prefiere hacer que el modelo de datos sea más integral y usar clases. export class ToDoTaskTeaser implements ToDoTask {
Pero esta es una cuestión de estilo, adecuación y cómo se desarrollará la arquitectura de la aplicación. En general, independientemente del enfoque, podemos confiar en un modelo de datos básico y tener más control sobre la conformidad de la escritura. Entonces, si por alguna razón el uid de ToDoTask convierte en un número, sabremos todas las partes del código que requieren actualización:

Descomposición anidada
Así que ahora tenemos la interfaz ToDoTask y podemos hacer referencia a ella. Del mismo modo, describiremos ToDoTaskGroup y ToDoTaskGroupBlank , y contendrán propiedades de los tipos ToDoTask y ToDoTaskBlank , respectivamente. Pero ahora dividiremos el "Grupo de tareas" en dos, no en tres componentes: para mayor claridad, describiremos el delta en ToDoGroupExtendedData . Así que quiero demostrar un enfoque en el que un componente se crea a partir de los otros dos:
"ToDoGroup": { "allOf": [ { "$ref": "#/components/schemas/ToDoGroupBlank" }, { "$ref": "#/components/schemas/ToDoGroupExtendedData" } ] }
Después de comenzar la generación del código, obtenemos una construcción TypeScript ligeramente diferente:
export type ToDoGroup = ToDoGroupBlank &
Como ToDoGroup no tiene su propio "cuerpo", el generador de código prefirió convertirlo en una unión de interfaces. Sin embargo, si agrega la tercera parte con su propio esquema (anónimo), el resultado será una interfaz con dos antepasados (pero es mejor no hacerlo). Y ToDoGroupBlank que la propiedad de items de la interfaz ToDoGroupBlank escribe como una matriz de ToDoTaskBlank y se redefine en ToDoGroupBlank en ToDoTask . Por lo tanto, el generador de código puede transferir los matices de descomposición bastante complejos del esquema JSON a TypeScipt.
import { ToDoTaskBlank } from './to-do-task-blank'; export interface ToDoGroupBlank {
import { ToDoTask } from './to-do-task'; export interface ToDoGroupExtendedData {
Bueno y, por supuesto, en ToDoTask / ToDoTaskBlank también podemos usar la descomposición. Es posible que haya notado que la propiedad de attachments se describe como una matriz de elementos de tipo AttachmentMeta . Y este componente se describe de la siguiente manera:
"AttachmentMeta": { "description": "Common meta data model of any type of attachment", "oneOf": [ {"$ref": "#/components/schemas/AttachmentMetaImage"}, {"$ref": "#/components/schemas/AttachmentMetaDocument"}, {"$ref": "#/components/schemas/ExternalResource"} ] }
Es decir, este componente se refiere a otros componentes. Como no tiene su propio esquema, el generador de código no lo convierte en un tipo de datos separado para no multiplicar entidades, sino que convierte una descripción anónima del tipo enumerado:
attachments?: Array< | AttachmentMetaImage
Al mismo tiempo, para los componentes AttachmentMetaImage y AttachmentMetaDocument , se describen interfaces no anónimas que se importan en los archivos que las utilizan:
import { AttachmentMetaDocument } from './attachment-meta-document'; import { AttachmentMetaImage } from './attachment-meta-image';
Pero incluso en AttachmentMetaImage, podemos encontrar un enlace a otra interfaz ImageOptions renderizada, que se usa dos veces, incluso dentro de una interfaz anónima (el resultado de la conversión de propiedades adicionales ):
import { ImageOptions } from './image-options'; export interface AttachmentMetaImage {
Por lo tanto, en base a las ToDoGroup ToDoTask o ToDoGroup , en realidad integramos varias entidades y una cadena de sus conexiones comerciales en nuestro código, lo que nos da más control sobre los cambios en el sistema que van más allá de nuestro código. Por supuesto, esto no tiene sentido en todos los casos. Pero si usa OpenAPI, entonces puede tener una pequeña bonificación más, además de la documentación real.
Servicios generados automáticamente para trabajar con la API REST
¿Por qué se necesita esto?
Si tomamos una aplicación front-end estadística promedio que funciona con una API REST más o menos compleja, una parte considerable de su código serán servicios (o simplemente funciones) para acceder a la API. Incluirán:
- Asignaciones de URL y parámetros
- Validación de parámetros, solicitud y respuesta.
- Extracción de datos y manejo de emergencias
Es desagradable que, en muchos sentidos, esto sea típico y no contenga ninguna lógica única. Supongamos un ejemplo: como esquema general, se puede construir el trabajo con la API:
Un ejemplo esquemático simplificado de trabajar con la API REST import _ from 'lodash'; import { Observable, fromFetch, throwError } from 'rxjs'; import { switchMap } from 'rxjs/operators';
Puede utilizar una abstracción de alto nivel para trabajar con REST; en función de la pila utilizada, puede ser: Axios , Angular HttpClient o cualquier otra solución similar. Pero lo más probable es que básicamente su código coincida con este ejemplo. Es casi seguro que incluirá:
- Servicios o funciones para acceder a puntos finales específicos (función
getTasksFromServer en nuestro ejemplo) - Piezas de código que procesan el resultado (función
getRemainedTasks )
En una aplicación del mundo real, este código será más complicado: la especificación de la aplicación de demostración describe 5-6 opciones de respuesta . A menudo, la API REST está diseñada de tal manera que cada estado de respuesta del servidor debe manejarse en consecuencia. Pero incluso la comprobación de los datos de entrada tiende a ser más difícil durante el desarrollo de la aplicación: cuanto más tiempo demore en admitir y procesar revisiones de errores, más querrá saber sobre los cuellos de botella en la circulación de datos en la aplicación.
Pueden producirse errores en cada nodo de acoplamiento de partes de software, cuya detección inoportuna (así como la búsqueda de problemas difíciles de diagnosticar) puede ser muy costosa para las empresas. Por lo tanto, habrá verificaciones de aclaraciones adicionales. A medida que crece la base del código, y el número de casos cubiertos, también lo hace la complejidad de realizar cambios. Pero el negocio es un cambio constante y no hay forma de evitarlo. Por lo tanto, debemos preocuparnos por cómo haremos cambios por adelantado.
Volviendo al tema de OpenAPI, observamos que en las especificaciones de la OEA puede haber suficiente información para:
- Describa todos los puntos finales necesarios en forma de funciones o servicios.
- URL
— . , , / — 5, 10 200, . , , : , , , RxJS- pickResponseBody , , - ; tapResponse , side-effect (tap) HTTP-. , - . , , .
, — -, . , , , "" / API "-" "" . - , "" ( ), .
, REST API Angular. , , /. . , , . , , .. .
" " . Angular-, update-typings.js :
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings(); cliApp.createServices('angular');
, Angular- API . , - - , . , RewriteGroupService . ApiService , , , -:
, JSON Schema , . , , :
import { schema as domainSchema } from './schema.b4c655ec1635af1be28bd6';
, schema.b4c655ec1635af1be28bd6.ts , , .
, Angular-.
Angular-ApiModule :
import { ApiModule, API_ERROR_HANDLER } from '@codegena/ng-api-service'; import { CreateGroupItemService, GetGroupsService, GetGroupItemsService, UpdateFewItemsService } from '@codegena/todo-app-scheme'; @NgModule({ imports: [ ApiModule, // ... ], providers: [ RewriteGroupService, { provide: API_ERROR_HANDLER, useClass: ApiErrorHandlerService }, // ... ], // ... }) export class TodoAppModule { }
, [])( https://angular.io/guide/dependency-injection ):
@Injectable() export class TodoTasksStore { constructor( protected createGroupItemService: CreateGroupItemService, protected getGroupsService: GetGroupsService, protected getGroupItemsService: GetGroupItemsService, protected updateFewItemsService: UpdateFewItemsService ) {} }
— , request , :
return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) );
request Observable<HttpResponse<R> | HttpEvent<R>> , , . , , . , , , . RxJS- pickResponseBody .
, , , . API, . . , :
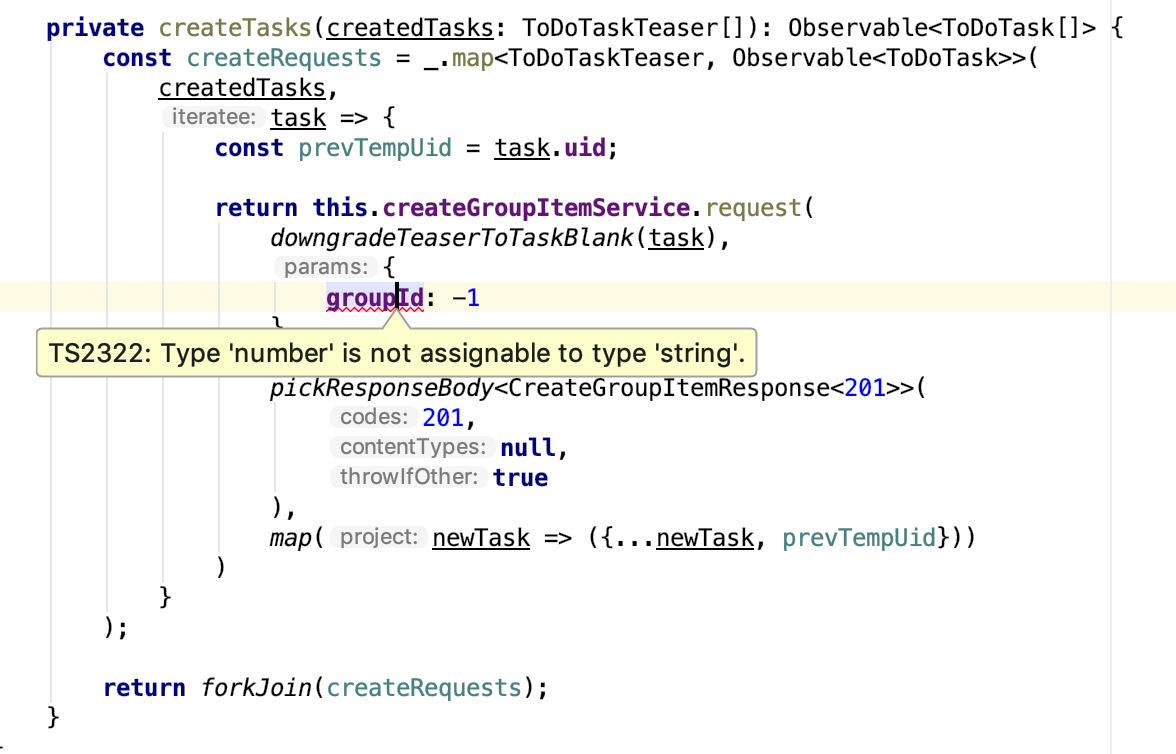
. JSON Schema . , "" - . , Sentry Kibana , . . , , .
, . , :)
En lugar de un epílogo
, . -, " " — . , , , .
— , - / ( ). , — .
.