HighLoad ++ Moscú 2018, Salón del Congreso. 9 de noviembre, 15:00
Resúmenes y presentación:
http://www.highload.ru/moscow/2018/abstracts/4066Yuri Nasretdinov (VKontakte): el informe contará sobre la experiencia de implementar ClickHouse en nuestra empresa: por qué lo necesitamos, cuánto almacenamos datos, cómo los escribimos, etc.

Recursos adicionales:
Uso de Clickhouse como sustituto de ELK, Big Query y TimescaleDB Yuri Nasretdinov: - ¡Hola a todos! Mi nombre es Yuri Nasretdinov, como ya me presentaron. Yo trabajo en VKontakte. Hablaré sobre cómo insertamos datos en "ClickHouse" de nuestra flota de servidores (decenas de miles).
¿Qué son los registros y por qué recogerlos?
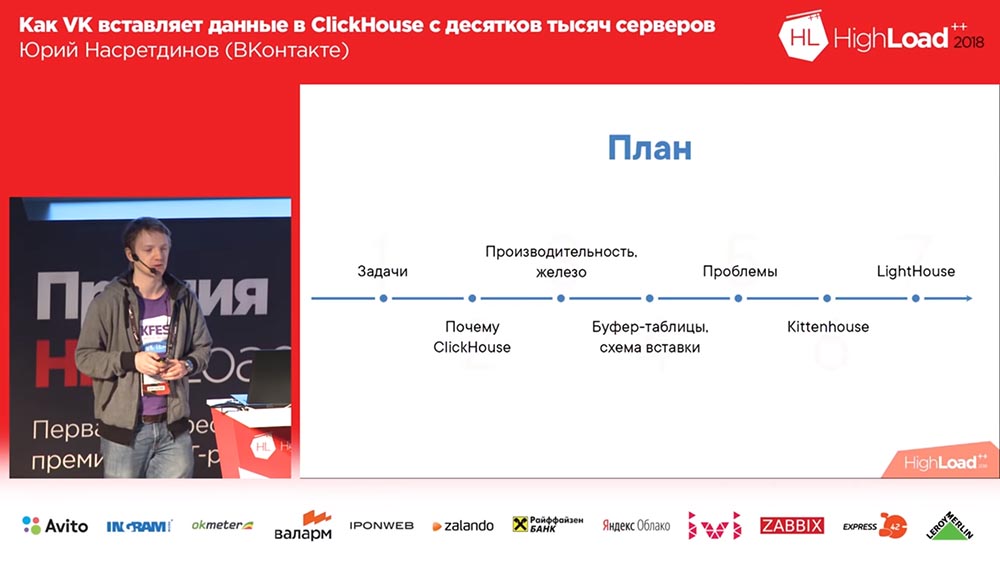
De qué hablaremos: qué hicimos, por qué necesitábamos "ClickHouse", respectivamente, por qué lo elegimos, qué tipo de rendimiento puede obtener aproximadamente sin configurar nada específicamente. Te contaré más sobre las tablas de búfer, sobre los problemas que tuvimos con ellas y sobre nuestras soluciones que desarrollamos a partir de código abierto: KittenHouse y Lighthouse.
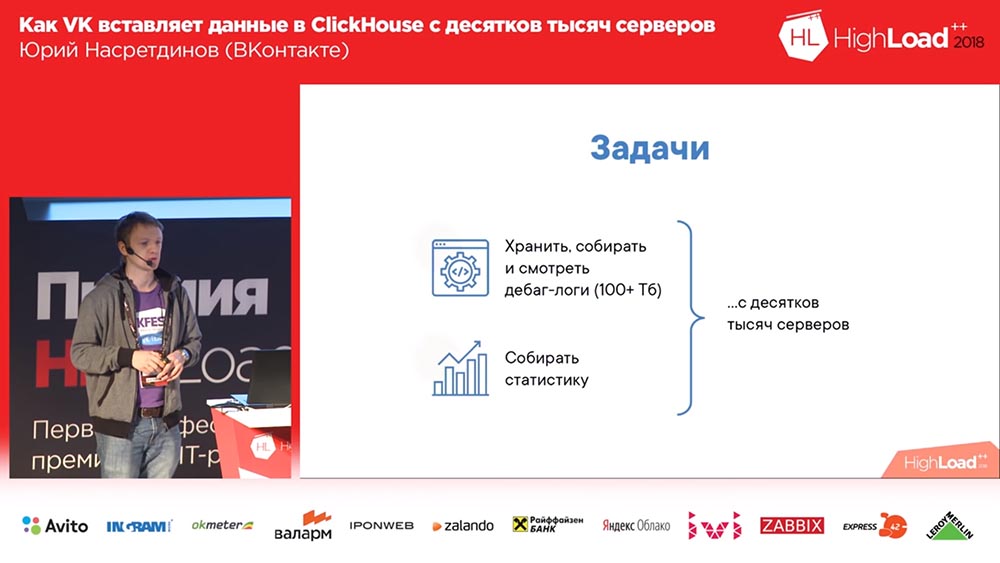
¿Por qué teníamos que hacer algo? (En VKontakte todo siempre está bien, ¿verdad?). Queríamos recopilar registros de depuración (y había cientos de terabytes de datos allí), tal vez, de alguna manera, es más conveniente leer las estadísticas; y tenemos decenas de miles de servidores desde los cuales se debe hacer todo esto.
¿Por qué decidimos? Probablemente teníamos soluciones para almacenar registros. Aquí, hay un “Backend VK” público. Recomiendo suscribirse a él.

¿Qué son los registros? Este es un motor que devuelve matrices vacías. Los motores en "VK" son lo que otros llaman microservicios. Y esa pegatina está sonriendo (bastantes me gusta). ¿Cómo es eso? Bueno, escucha!

¿Qué se puede usar para almacenar registros en general? Es imposible no mencionar el Khadup. Luego, por ejemplo, Rsyslog (almacenamiento en los archivos de estos registros). LSD ¿Quién sabe qué es el LSD? No, no este LSD. Los archivos se almacenan, respectivamente, también. Bueno, ClickHouse es una versión extraña de algún tipo.
Clickhouse y competidores: requisitos y oportunidades
Que queremos Queremos que no necesitemos tomar un baño de vapor especial con la operación, de modo que funcione de manera preferible, con una configuración mínima. Queremos escribir mucho y escribir rápido. Y queremos conservarlo todos los meses, años, es decir, durante mucho tiempo. Es posible que queramos resolver algún tipo de problema con el que se nos presentaron, dijeron: "Algo no funciona aquí para nosotros", esto fue hace 3 meses), y queremos poder verlo hace 3 meses. ". Compresión de datos, es comprensible por qué será una ventaja, porque se reduce la cantidad de espacio que está ocupado.

Y tenemos un requisito tan interesante: a veces escribimos la salida de algunos comandos (por ejemplo, registros), puede ser más de 4 kilobytes con bastante calma. Y si esto funciona en UDP, entonces no necesita gastar ... no tendrá ninguna "sobrecarga" para la conexión, y para una gran cantidad de servidores esto será una ventaja.

Veamos qué nos ofrece el código abierto. En primer lugar, tenemos un motor de registros: este es nuestro motor; Básicamente lo sabe todo, incluso las líneas largas pueden escribir. Bueno, no comprime los datos de forma transparente: podemos comprimir grandes columnas nosotros mismos si queremos ... nosotros, por supuesto, no queremos (si es posible). El único problema es que solo puede regalar lo que está guardado en su memoria; el resto, para leer, necesita obtener el binlog de este motor y, en consecuencia, lleva bastante tiempo.

¿Cuáles son las otras opciones? Por ejemplo, Khadup. Facilidad de uso ... ¿Quién cree que Hadoup es fácil de configurar? Con la grabación, por supuesto, no hay problemas. Con la lectura, a veces surgen preguntas. En principio, diría que probablemente no, especialmente para los registros. Almacenamiento a largo plazo, por supuesto, sí, compresión de datos, sí, líneas largas, está claro que puede escribir. Pero para grabar desde una gran cantidad de servidores ... De todos modos, ¡debemos hacer algo nosotros mismos!
Rsyslog. De hecho, lo usamos como reserva, de modo que sería posible leer un binlog sin volcar, pero no podía escribir en líneas largas, en principio, no podía escribir más de 4 kilobytes. La compresión de datos debe hacerse de la misma manera. La lectura pasará de los archivos.

Luego está el desarrollo "malo" de LSD. Lo mismo es esencialmente lo mismo que "Rsyslog": admite líneas largas, pero no sabe cómo usar UDP y, de hecho, debido a esto, desafortunadamente, hay muchas cosas para reescribir allí. El LSD necesita ser rehecho para que pueda grabar de decenas de miles de servidores.

Oh aqui! Una opción divertida es ElasticSearch. Bueno, como decirlo? Todo está bien con la lectura, es decir, él lee rápidamente, pero no muy bien con la escritura. En primer lugar, si comprime los datos, es muy débil. Lo más probable es que una búsqueda completa requiera estructuras de datos más voluminosas que el volumen original. Es difícil de explotar, a menudo surgen problemas con él. Y, de nuevo, una entrada en el "Elastic": todos debemos hacerlo nosotros mismos.

Aquí ClickHouse: la opción ideal, por supuesto. Lo único es que grabar de decenas de miles de servidores es un problema. Pero ella es al menos una, podemos tratar de resolverlo de alguna manera. Y el resto del informe trata sobre este problema. ¿Qué rendimiento general de ClickHouse puede esperar?
¿Cómo vamos a incrustar? MergeTree
¿Cuántos de ustedes no han escuchado sobre ClickHouse, no lo saben? ¿Necesitas decirlo, no es necesario? Muy rapido La inserción es de 1-2 gigabits por segundo, las ráfagas de hasta 10 gigabits por segundo pueden soportar esta configuración: hay dos Xeons de 6 núcleos (es decir, ni siquiera los más potentes), 256 gigabytes de RAM, 20 terabytes por RAID (nadie configurado, configuración predeterminada). Alexey Milovidov, el desarrollador de ClickHouse, probablemente llorando, porque no configuramos nada (todo nos funcionó así). En consecuencia, se puede obtener una velocidad de exploración de, por ejemplo, aproximadamente 6 mil millones de filas por segundo si los datos están bien comprimidos. Si desea% en una línea de texto, 100 millones de líneas por segundo, es decir, parece que muy rápido.

¿Cómo vamos a incrustar? Bueno, lo sabes en "VK" - en PHP. Nosotros, de cada trabajador PHP, pegaremos HTTP en "ClickHouse", en la placa MergeTree para cada entrada. ¿Quién ve el problema en este circuito? Por alguna razón, no todos levantaron la mano. Vamos a decirte
En primer lugar, hay muchos servidores; en consecuencia, habrá muchas conexiones (malas). Luego, en MergeTree es mejor insertar datos no más de una vez por segundo. ¿Y quién sabe por qué? De acuerdo, bien. Te contaré un poco más sobre esto. Otra pregunta interesante es que, por así decirlo, no estamos haciendo análisis, no necesitamos enriquecer los datos, no necesitamos servidores intermedios, queremos incrustar directamente en "ClickHouse" (preferiblemente, cuanto más recto, mejor).

En consecuencia, ¿cómo se implementa la inserción en MergeTree? ¿Por qué es mejor insertarlo no más de una vez por segundo o menos? El hecho es que "ClickHouse" es una base de datos columnar y clasifica los datos en orden ascendente de la clave primaria, y cuando inserta, la cantidad de archivos se crea al menos por la cantidad de columnas en las que los datos se ordenan en orden ascendente de la clave primaria (se crea un directorio separado, un conjunto de archivos en el disco para cada inserción). Luego va la siguiente inserción, y en el fondo se fusionan en una "partición" más grande. Dado que los datos están ordenados, puede "hacer malabarismos" con dos archivos ordenados sin mucho consumo de memoria.
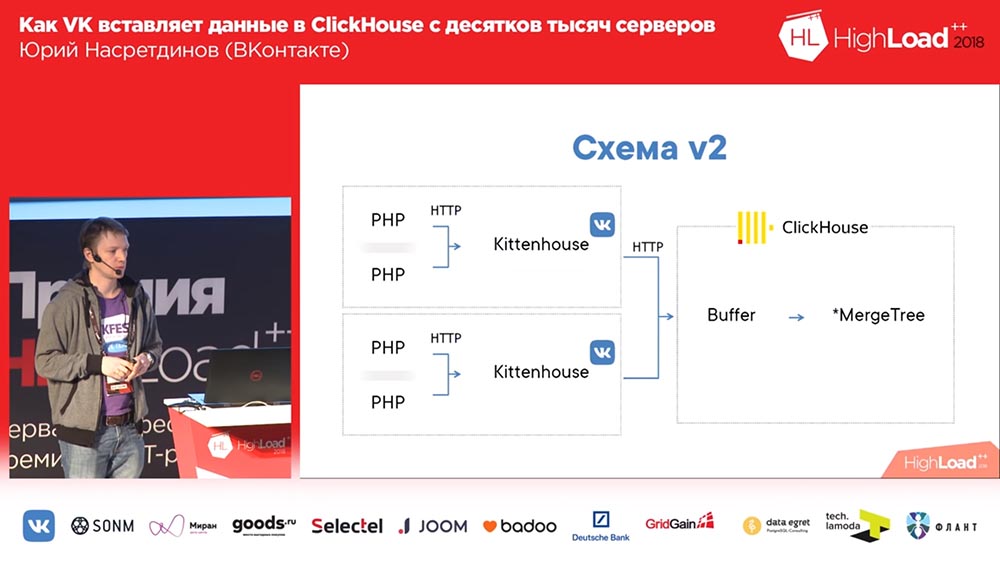
Pero, como puede imaginar, si escribe 10 archivos para cada inserción, entonces "ClickHouse" terminará rápidamente (o su servidor), por lo tanto, se recomienda insertar en paquetes grandes. En consecuencia, nunca lanzamos el primer esquema en producción. Inmediatamente lanzamos uno que tiene el número 2 aquí:

Imagine aquí que hay alrededor de mil servidores en los que lanzamos, solo hay PHP. Y en cada servidor está nuestro agente local, al que llamamos "Kittenhouse", que mantiene una conexión con "ClickHouse" e inserta datos cada pocos segundos. No inserta datos en MergeTree, sino en la tabla de cola, que sirve para no insertar directamente en MergeTree de inmediato.
Trabajar con tablas de amortiguamiento
Que es esto Las tablas de búfer son una pieza de memoria aleatoria (es decir, a menudo puede insertarlas en ella). Consisten en varias piezas, y cada una de las piezas funciona como un búfer independiente, y se limpian de forma independiente (si tiene muchas piezas en el búfer, habrá muchas inserciones por segundo). Puede leer desde estas tablas, luego lee la unión del contenido del búfer y la tabla principal, pero en ese momento el registro está bloqueado, por lo que es mejor no leer desde allí. Y las tablas de almacenamiento intermedio muestran un QPS muy bueno, es decir, hasta 3 mil QPS no tendrá ningún problema con la inserción. Está claro que si la energía se perdió en el servidor, entonces los datos se pueden perder, ya que solo se almacenaron en la memoria.

Al mismo tiempo, ALTER complica el esquema con el búfer, ya que primero debe descartar la tabla del búfer anterior con el esquema anterior (los datos no se perderán al mismo tiempo, ya que se eliminarán antes de eliminar la tabla). Luego "altera" la tabla que necesita y crea la tabla de búfer nuevamente. En consecuencia, aunque no hay una tabla de búfer, sus datos no fluyen a ningún lado, pero incluso puede localmente en el disco.

¿Qué es Kittenhouse y cómo funciona?
¿Qué es KittenHouse? Este es un proxy. Adivina qué idioma? Recopilé los temas más exagerados en mi informe: esto es "Clickhouse", vaya, tal vez pueda recordar algo más. Sí, está escrito en Go, porque realmente no sé cómo escribir en C, no quiero saberlo.

En consecuencia, mantiene una conexión con cada servidor, puede escribir en la memoria. Por ejemplo, si escribimos registros de errores en “Clickhouse”, entonces si “Clickhouse” no tiene tiempo para insertar datos (después de todo, si se escriben demasiados), entonces no nos hinchamos de memoria, simplemente tiramos el resto. Porque, si escribimos varios gigabits por segundo de errores, entonces, probablemente, podemos arrojar algunos. Kittenhouse sabe cómo. Además, sabe cómo entregar de manera confiable, es decir, escribe en un disco en la máquina local y de vez en cuando (allí, una vez en un par de segundos) intenta entregar datos de este archivo. Y al principio usamos el formato de valores habitual, no un formato binario, formato de texto (como en SQL normal).

Pero entonces esto sucedió. Usamos una entrega confiable, escribimos registros, luego decidimos (era un clúster de prueba condicionalmente) ... Lo apagaron durante unas horas y lo levantaron, y la inserción comenzó desde miles de servidores; resultó que Klickhouse todavía tenía un "hilo en conexión ”: en consecuencia, en mil conexiones, la inserción activa conduce a un promedio de carga en el servidor de aproximadamente mil quinientos. Sorprendentemente, el servidor aceptó solicitudes, pero estos datos se insertaron después de un tiempo; pero fue muy difícil para el servidor repararlo ...
Añadir nginx
Dicha solución para el hilo por modelo de conexión es nginx. Ponemos nginx frente a Clickhouse, al mismo tiempo establecemos el equilibrio en dos réplicas (hemos aumentado la velocidad de inserción en 2 veces, aunque no el hecho de que debería ser así) y limitamos el número de conexiones a Clickhouse, a la corriente ascendente y, en consecuencia, a más que en 50 compuestos, parece que no tiene sentido insertarlo.

Luego nos dimos cuenta de que, en general, este esquema tiene inconvenientes, porque tenemos un nginx aquí. En consecuencia, si este nginx se establece, a pesar de la presencia de réplicas, perdemos datos o, al menos, no escribimos en ningún lado. Por lo tanto, hicimos nuestro equilibrio de carga. También nos dimos cuenta de que "Clickhouse" es adecuado para registros, y el "demonio" también comenzó a escribir sus propios registros en "Clickhouse" también, muy conveniente, para ser sincero. Todavía lo usamos para otros "demonios".

Luego descubrieron un problema tan interesante: si utiliza una forma no bastante estándar para insertar en modo SQL, entonces se forza un analizador basado en SQL AST completo, que es bastante lento. En consecuencia, agregamos configuraciones para que esto nunca suceda. Hicimos equilibrios de carga, controles de salud, de modo que si uno muere, todavía dejamos datos. Hemos obtenido suficientes tablas para que necesitemos diferentes grupos de "Clickhouse". Y comenzamos a pensar en otros usos; por ejemplo, queríamos escribir registros desde módulos nginx, y no pueden comunicarse usando nuestro RPC. Bueno, me gustaría enseñarles de alguna manera cómo enviar, por ejemplo, a través de UDP para recibir eventos en localhost y luego enviarlos al "Clickhouse".
Un paso de la decision
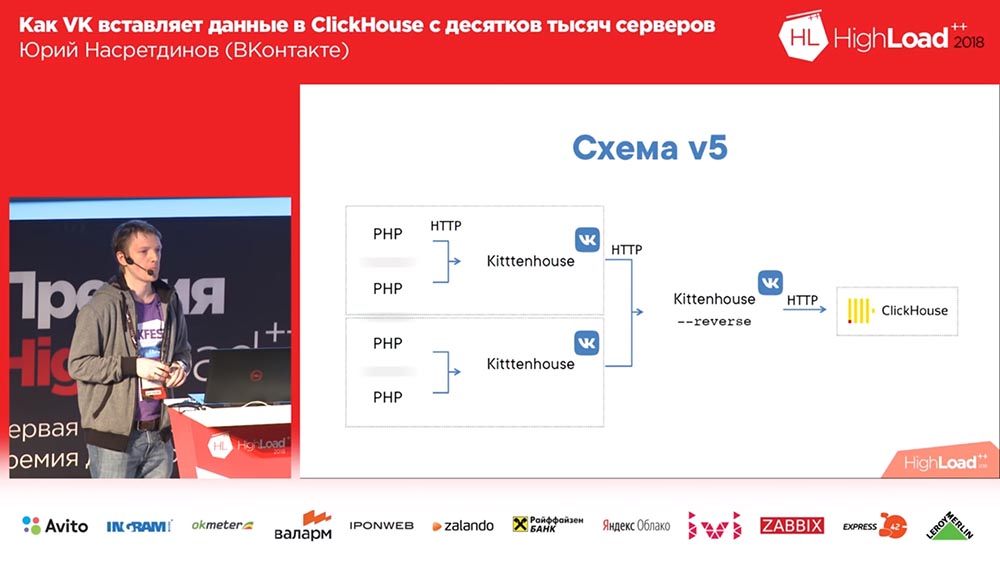
El esquema final comenzó a verse así (la cuarta versión de este esquema): en cada servidor frente a Clickhouse hay nginx (en el mismo servidor, además) y simplemente envía solicitudes al host local con un límite en el número de conexiones de 50 piezas. Y ahora este esquema ya estaba funcionando, era bastante bueno con él.

Vivimos así durante aproximadamente un mes. Todos estaban felices, agregando tablas, agregando, agregando ... En general, resultó que la forma en que agregamos tablas de almacenamiento intermedio no era muy óptima (digamos). Hicimos 16 piezas en cada mesa y un intervalo de flash durante un par de segundos; Teníamos 20 mesas y 8 insertos por segundo fueron a cada mesa, y en ese momento comenzó el "Clickhouse" ... los registros comenzaron a quedar en blanco. Ni siquiera pasaron ... Nginx tenía una cosa tan interesante por defecto que si las conexiones terminaban en el flujo ascendente, entonces solo da "502" a todas las solicitudes nuevas.

Y aquí, a nosotros (acabo de mirar los registros en el mismo "Clickhouse" que miré) en algún lugar alrededor del medio por ciento de las solicitudes falla. En consecuencia, la utilización del disco fue alta, hubo muchas fusiones. Bueno, que he hecho? Naturalmente, no comencé a entender por qué la conexión y el flujo ascendente están terminando.
Reemplazar nginx con proxy inverso
Decidí que necesitamos administrar esto nosotros mismos, no se lo dé a nginx, nginx no sabe qué tablas están en el "Clickhouse", y reemplacé nginx con un proxy inverso, que también escribí.
Que esta haciendo el Funciona sobre la base de la biblioteca fasthttp "goosh", es decir, rápido, casi tan rápido como nginx. Lo siento, Igor, si estás aquí (nota: Igor Sysoev es un programador ruso que creó el servidor web nginx). Puede entender qué tipo de consultas es (INSERTAR o SELECCIONAR), respectivamente, mantiene diferentes grupos de conexiones para diferentes tipos de consultas.

En consecuencia, incluso si no tenemos tiempo para completar las solicitudes, las "selecciones" pasarán, y viceversa. Y agrupa los datos en tablas de búfer, con un búfer pequeño: si hubo errores, errores de sintaxis, etc., de modo que influyeron ligeramente en el resto de los datos, porque cuando insertamos simplemente en las tablas de búfer, teníamos " bachi ", y todos los errores de sintaxis afectaron solo a esta pequeña pieza; y aquí ya afectarán al búfer grande. Pequeño es 1 megabyte, es decir, no tan pequeño.

Insertar una sincronización y esencialmente reemplazar nginx hace esencialmente lo mismo que nginx hizo antes: Kittenhouse no necesita ser cambiado localmente para esto. Y dado que utiliza fasthttp, es muy rápido: puede realizar más de 100 mil solicitudes por segundo de inserciones individuales a través de servidores proxy inversos. Teóricamente, puede insertar una línea en un proxy inverso de kittenhouse, pero ciertamente no lo hacemos.

El esquema comenzó a verse así: Kittenhouse, un proxy inverso, agrupa muchas solicitudes en tablas y, a su vez, las tablas de búfer las insertan en las principales.
Asesino - solución temporal, gatito - permanente
Hubo un problema tan interesante ... ¿Alguno de ustedes ha usado fasthttp? ¿Quién usó fasthttp con las solicitudes POST? Probablemente, de hecho, no valía la pena hacerlo, porque almacena el cuerpo de la solicitud de forma predeterminada, y hemos establecido el tamaño del búfer de 16 megabytes. El inserto dejó de estar a tiempo en algún momento, y de todas las decenas de miles de servidores comenzaron a llegar fragmentos de 16 megabytes, y todos se almacenaron en la memoria intermedia antes de ser entregados a Clickhouse. En consecuencia, se acabó la memoria, vino el Asesino sin memoria, mató al proxy inverso (o "Clickhouse", que en teoría podría "comer" más que el proxy inverso). El ciclo se repitió. No es un problema muy agradable. Aunque nos encontramos con esto solo después de unos meses de operación.
Que hice Nuevamente, no me gusta entender qué sucedió exactamente. Me parece bastante obvio que no hay necesidad de almacenar en la memoria intermedia. No pude remendar fasthttp, aunque lo intenté. Pero encontré una forma de hacerlo para que no hubiera necesidad de parchear nada, y se me ocurrió mi propio método en HTTP: lo llamé KITTEN. Bueno, es lógico: "VK", "Gatito" ... ¿De qué otra manera? ...

Si llega una solicitud al servidor con el método Kitten, entonces el servidor debe responder "miau" lógicamente. Si responde a esto, entonces se cree que comprende este protocolo, y luego intercepto la conexión (existe un método de este tipo), y la conexión entra en modo "sin procesar". ¿Por qué necesito esto? Quiero controlar cómo se produce la lectura de las conexiones TCP. TCP tiene una propiedad maravillosa: si nadie lee desde ese lado, entonces el registro comienza a esperar, y la memoria no se gasta especialmente en esto.
Entonces leí en alguna parte de 50 clientes a la vez (de cincuenta porque cincuenta ciertamente debería ser suficiente, incluso si proviene de otro DC) ... El consumo ha disminuido con este enfoque al menos 20 veces, pero honestamente , No pude medir exactamente cuánto, porque ya no tiene sentido (ya se ha convertido en el nivel de error). El protocolo es binario, es decir, hay un nombre de tabla y datos; no hay encabezados http, por lo que no utilicé un socket web (no necesito comunicarme con los navegadores, hice un protocolo que se adapta a nuestras necesidades). Y con él todo estaba bien.
La mesa de amortiguamiento es triste
Recientemente, encontramos otra característica interesante de las tablas de búfer. Y este problema ya es mucho más doloroso que el resto.
Imagine esta situación: ya ha utilizado Clickhouse activamente, tiene docenas de servidores de Clickhouse y tiene algunas solicitudes que se leen durante mucho tiempo (por ejemplo, más de 60 segundos); y usted viene y hace Alter en ese momento ... Y hasta que las "selecciones" que comenzaron antes de "Alter" no estén incluidas en esta tabla, "Alter" no se inicia, probablemente algunas características de cómo funciona el "Clickhouse" este lugar Tal vez esto se puede arreglar? O no?
, , , . , , , «» ( – , , ), … , «» ( - «» ) – , - : ( , ), «» , - , . , «», – .

(, ) – «» query_thread_log. , - . 840 (100 ). , (, , , ) «» (inserts). , «» – «» . , – , . Por qué , ! .

, ? «». .
«KitttenHouse»
, ? . ! : , , - . , .

, «», – , (, - ) , , – .

? . , , 10 , – -, , . , , , , – , «», 100 - – , , , . , . , .
, , . : , - , , , read only . ? . – - , - … ( , «», ClickHouse) ? ? , . . : , . , . .
. . , - ?.. «»? - … «»? , , . , . , .

– . , . , : , , ( ), – , .

Sequel Pro, «», . : «, -?» ? 2018-? , «» (MySQL) , «», ! «», – , .
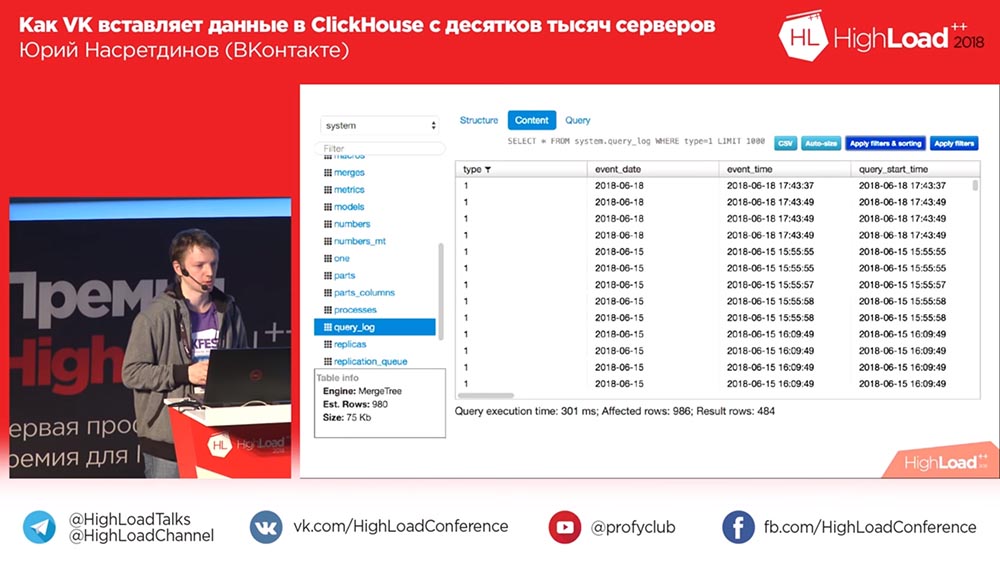
, , , , , , , , affected rows ( ), . .
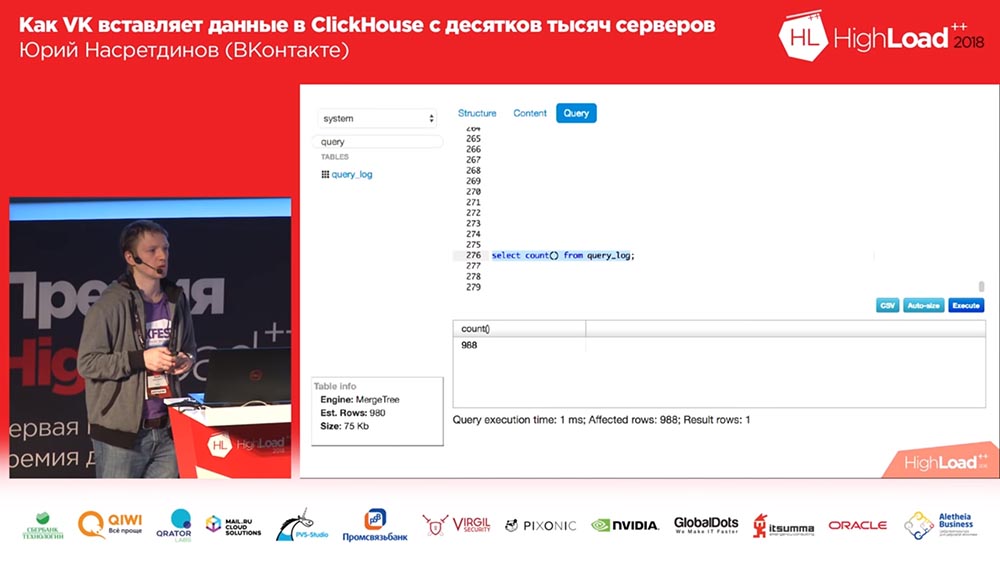
. «», . - - . .
«»
, «», , . , , – . , … , , .

TCP? , «» UDP. TCP… , , : «, ! , UDP». , TCP . , , – - ; , .
«» «» HighLoad Siberia, « »… , … , , . - , - , – , ( , , ).
. Muchas gracias
Nuestro github está aquí . Con "Clickhouse" tu cabello será suave y sedoso. Presentador: - Amigos, y ahora preguntas. Inmediatamente después de presentar la carta de agradecimiento y su informe sobre VHS.Yuri Nasretdinov (en adelante, la ONU): - ¿Y cómo podría grabar mi informe sobre VHS si acaba de terminar?
Presentador: - Amigos, y ahora preguntas. Inmediatamente después de presentar la carta de agradecimiento y su informe sobre VHS.Yuri Nasretdinov (en adelante, la ONU): - ¿Y cómo podría grabar mi informe sobre VHS si acaba de terminar? Anfitrión: “¡Usted tampoco puede determinar completamente cómo funcionará o no funcionará el“ Clickhouse ”! Amigos, ¡5 minutos para preguntas!
Anfitrión: “¡Usted tampoco puede determinar completamente cómo funcionará o no funcionará el“ Clickhouse ”! Amigos, ¡5 minutos para preguntas!Preguntas
Pregunta de la audiencia (en adelante - H): - Buenas tardes. Muchas gracias por el informe. Tengo dos preguntas Comenzaré con una frívola: ¿el número de letras t en el nombre "Kittenhouse" en los esquemas (3, 4, 7 ...) afecta la satisfacción de los gatos?
ONU: ¿La cantidad de qué?
Z: - Las letras t. Hay tres t, en algún lugar tres t.
ONU: - ¿Realmente he corregido esto? ¡Pues claro que sí! Estos son productos diferentes: acabo de mentirte todo este tiempo. De acuerdo, estoy bromeando, no lo hace. Ah, aqui! No, es lo mismo, estoy sellado.
 Z:
Z: Gracias. La segunda pregunta es seria. Según tengo entendido, en "Clickhouse" las tablas de búfer viven exclusivamente en la memoria, no están almacenadas en el disco y, en consecuencia, no son persistentes.
ONU: Sí.
Z: - Y al mismo tiempo, en su cliente se realiza el almacenamiento en búfer en el disco, lo que implica cierta garantía de entrega de estos mismos registros. Pero en Clickhouse, esto no está garantizado. Explicar cómo se lleva a cabo la garantía, ¿por qué? .. Este mecanismo es más detallado
ONU: - Sí, en teoría no hay contradicciones, porque puedes detectar un millón de formas diferentes en realidad cuando cae el "Clickhouse". Si el "Clickhouse" se bloquea (si no se completa correctamente), puede, más o menos, rebobinar un poco el registro que escribió y comenzar desde el momento en que todo estuvo bien. Rebobinemos hace un minuto, es decir, se cree que mostró todo en un minuto.
Z: - Es decir, Kittenhouse mantiene la ventana más larga y, en caso de una caída, ¿puede reconocerla y desenrollarla?
ONU: - Pero esto es en teoría. En la práctica, no hacemos esto, y la entrega confiable es de cero a infinito veces. Pero en promedio uno. Estamos satisfechos de que si el "Clickhouse" falla por algún motivo o los servidores se "reinician", entonces perdemos un poco. En todos los demás casos, no pasará nada.
Z: Hola. Desde el principio me pareció que realmente usarías UDP desde el comienzo del informe. Tienes http, todo eso ... Y la mayoría de los problemas que describiste, según tengo entendido, fueron causados por esta solución particular ...
ONU: - ¿Qué usamos TCP?
Z: - De hecho, sí.
ONU: - No.
Z: - Fue con fasthttp que tuviste problemas, con la conexión tuviste problemas. Si acaba de utilizar UDP, se ahorraría tiempo. Bueno, habría problemas con mensajes largos u otra cosa ...
ONU: - ¿Con qué?
 Z:
Z: - Con mensajes largos, ya que puede no encajar en la MTU, algo más ... Bueno, allí pueden surgir sus problemas. La pregunta es: ¿por qué no es UDP?
ONU: - Creo que los autores que desarrollaron TCP / IP son mucho más inteligentes que yo y saben cómo serializar mejor los paquetes (para que funcionen), al mismo tiempo ajustar la ventana de envío, no sobrecargar la red y dar retroalimentación sobre qué lee, sin contar desde el otro lado ... Todos estos problemas, en mi opinión, también estarían en UDP, solo que tendría que escribir aún más código del que ya escribí para implementar lo mismo y lo más probable es que sea malo. Ni siquiera me gusta escribir en C, no como allí ...
Z: - ¡Solo conveniente! Enviado bien y no esperes nada, tienes absolutamente asíncrono. Un aviso regresó que todo está bien, eso significa que ha llegado; no vino, significa malo.
ONU: - Necesito tanto eso como otro. Necesito poder enviar ambos con una garantía de entrega y sin una garantía de entrega. Estos son dos escenarios diferentes. Algunos registros no necesito perder o no perder dentro de lo razonable.
Z: - No me tomaré el tiempo. Esto debería discutirse más tiempo. Gracias
Presentador: - ¿Quién tiene preguntas - bolígrafos en el cielo!
 Z:
Z: Hola, soy Sasha. En algún lugar en el medio del informe, había una sensación de que era posible, además de TCP, usar una solución preparada, algún tipo de Kafka.
ONU: "Bueno ... te dije que no quiero usar servidores intermedios, porque ... para Kafka, resulta que tenemos diez mil hosts; de hecho, tenemos más: decenas de miles de hosts. Con Kafka, sin ningún poder, también puede doler. Además, lo más importante, todavía da "latencia", da los hosts adicionales que necesita tener. Y no quiero tenerlos, quiero ...
Z: - Pero al final resultó de todos modos.
ONU: - ¡No, no hay anfitriones! Todo funciona en los hosts de Clickhouse.
Z: - Pero, ¿qué pasa con el Kittenhouse, al contrario de lo cual es - dónde vive?
 ONU:
ONU: - En el host de Klickhouse, no escribe nada en el disco.
Z: - Bueno, digamos.
Presentador: - ¿Te satisface? ¿Podemos dar un salario?
Z: Sí, sí. De hecho, hay muchas muletas para obtener lo mismo, y ahora, la respuesta anterior sobre el tema de TCP contradice, en mi opinión, esta situación. Se siente como si pudieras hacer todo sobre tu rodilla en mucho menos tiempo.
ONU: - ¿Y por qué no quería usar "Kafka", porque había muchas quejas en el telegrama "Clickhouse" en Telegram que, por ejemplo, se perdieron mensajes de "Kafka". No de Kafka en sí, sino en la integración de Kafka y Klikhaus; o algo no se conectó allí. En términos generales, sería necesario que Kafka escribiera en ese momento para el cliente. No creo que se obtenga una solución más simple y confiable.
Z: - Dime, ¿por qué no intentaste algunas líneas o algún autobús tan común? ¿Ya que dice que fue posible con usted asincrónicamente conducir a través de la cola los registros mismos y también obtener asincrónicamente a través de la cola en respuesta?
 ONU:
ONU: - ¿Sugiere qué colas podrían usarse?
Z: - Cualquiera, incluso sin una garantía de que van en orden. Cualquier Redis, RMQ ...
UN: - Tengo la sensación de que Redis probablemente no podrá extraer ese volumen de inserción incluso en un host (en el sentido de varios servidores) que extrae Clickhouse. No puedo confirmar esto con ninguna evidencia (no lo comparé), pero me parece que Redis no es la mejor solución aquí. En principio, puede considerar este sistema como una cola de mensajes improvisada, pero que es solo para "Clickhouse"
Presentador: - Yuri, muchas gracias. Propongo finalizar las preguntas y respuestas sobre esto y decir cuál de las personas que hicieron la pregunta nos dará un libro.
ONU: - Me gustaría darle un libro a la primera persona que hizo una pregunta.
Presentador: - ¡Genial! Genial Genial Muchas gracias
Un poco de publicidad :)
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos
VPS basado en la nube para desarrolladores desde $ 4.99 , un
análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?