 Toma de una de las investigaciones en línea de Bellingcat
Toma de una de las investigaciones en línea de BellingcatLa agencia internacional Bellingcat ha publicado
varios consejos para identificar personas y ubicaciones geográficas en fotografías utilizando la función "Búsqueda de imágenes" en los motores de búsqueda.
Resultó que en esta relación no hay igual que el motor de búsqueda ruso
Yandex. Imágenes " . Según un ejemplo, el motor encuentra fotografías de esta cara en una configuración e iluminación completamente diferentes, lo que indica un reconocimiento facial avanzado. Los expertos admiten que Google y otras compañías no tienen nada de eso. Por lo tanto, Yandex puede ser llamado el líder indiscutible en la búsqueda inversa de imágenes.
La guía publicada explica los métodos básicos de las investigaciones en línea, con un enfoque en la identificación de personas y direcciones.
Busque fotos similares por modelo de rostro en Yandex, Google y Bing.

En el primer ejemplo, Yandex encontró numerosas fotografías de la persona deseada de varias fuentes (entre los mejores resultados, solo se presentaron extraños en solo dos casos), y los resultados difieren de la imagen original, pero muestran a la misma persona. Google no encontró nada en absoluto, y en los resultados de búsqueda de Bing solo hubo un resultado con la misma persona (quinta imagen, segunda línea).
Los expertos de Bellingcat usan constantemente Yandex en las investigaciones y no expresan una paranoia particular sobre su origen ruso. Esta es la primera herramienta a la que recurren en el trabajo. En segundo lugar está Bing, donde en la búsqueda hay varias funciones únicas, como resaltar un área específica de la imagen para la búsqueda.
Google es adecuado para la búsqueda inversa más simple. Por ejemplo, identificar personas famosas en fotografías, buscar la fuente de imágenes, determinar el autor de una obra de arte, etc. Sin embargo, si desea encontrar imágenes similares (no copias exactas), se sentirá decepcionado.
Por ejemplo, cuando busca a una persona
que intentó atacar a un periodista de la BBC en un mitin de Trump, Google encuentra la fuente de la imagen recortada, pero no puede encontrar ninguna imagen adicional de él o alguien al menos un poco similar.


Aunque Google realmente no ayudó a encontrar otras instancias de la cara de esta persona o personas similares a él, todavía encontró la versión original sin recortar de la foto de la que se tomó la captura de pantalla.
Prueba
Para probar varios métodos y mecanismos para buscar imágenes inversas, los especialistas de Bellingcat tomaron varias imágenes que representan varios tipos de estudios, incluidas fotografías originales (previamente no cargadas en Internet) y procesadas. Señalan que ahora la búsqueda puede no funcionar como lo hizo durante las pruebas, porque después de la publicación del artículo, los motores de búsqueda ya han indexado estas fotos y las han integrado en sus resultados.
Las fotos de prueba incluyen una serie de diferentes regiones geográficas con materiales de origen en Europa Occidental, Europa Oriental, América del Sur, Sudeste de Asia y los Estados Unidos. En cada una de estas fotos, los objetos individuales en la imagen se resaltan para verificar las fortalezas y debilidades de cada motor de búsqueda.
Una de las fotos de prueba: Palacio Olisov en Nizhny Novgorod, Rusia (original, no subido previamente a la red):

Por separado: SUV blanco en Nizhny Novgorod:

Por separado: trailer en Nizhny Novgorod:

En un edificio en Nizhny Novgorod, como en otras fotografías, Yandex mostró los mejores resultados. Los reporteros de Bellingcat dicen que sus resultados son tan impresionantes que a veces parecen una especie de magia negra, aunque no sin errores.
En este caso, Yandex reconoció fácilmente este edificio. Encontró fotografías tomadas desde el mismo ángulo, y también encontró desde otros ángulos, incluyendo 90 ° en sentido antihorario (ver las dos primeras imágenes en la tercera fila) desde el punto de vista de la imagen original.

Yandex también reconoció fácilmente el SUV blanco en el primer plano de la foto como el Nissan Juke.
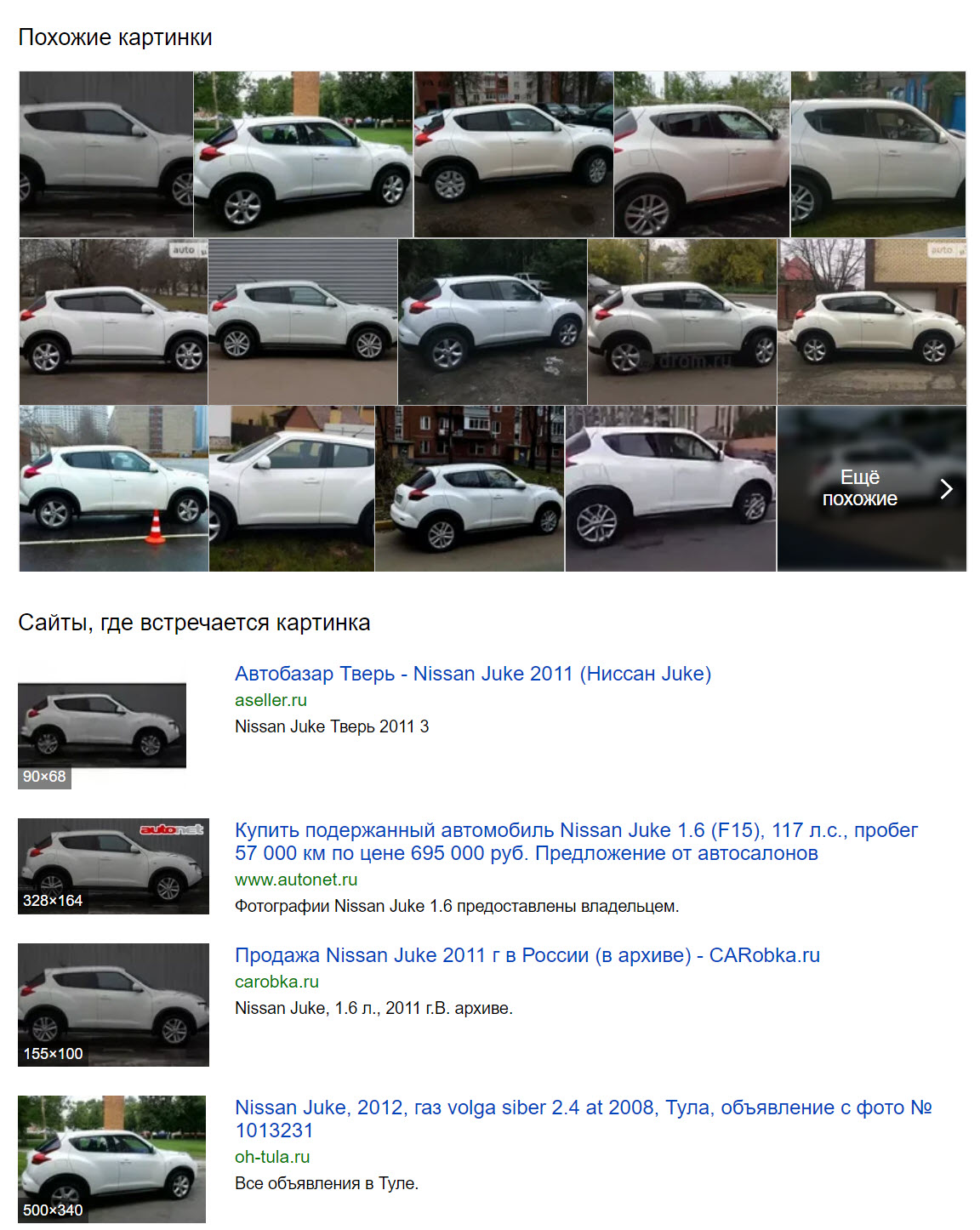
Finalmente, en la búsqueda aislada más compleja de esta imagen, Yandex no pudo identificar el discreto remolque gris frente al edificio. Algunos resultados tienen el mismo aspecto que en la imagen original, pero ninguno de ellos es cierto.

En comparación con estos resultados, mostrar Google y Bing parece ridículo, aunque Google clasificó correctamente el tráiler como un
tráiler de viaje .
Si la búsqueda de imágenes falla, los trucos simples ayudan en algunos casos:
- imagen especular de la foto;
- el uso de filtros de color;
- Eliminar elementos innecesarios del marco que pueden dificultar la búsqueda
Herramientas auxiliares
Además de la búsqueda de imágenes estándar, Bellingcat recomienda varias herramientas de soporte para realizar investigaciones en línea.
En primer lugar, existen herramientas especializadas para procesar ciertos tipos de fotos. Por ejemplo,
la aplicación
Merlin Bird ID de Cornell Lab identifica con extrema precisión el tipo de ave en una fotografía o sugiere opciones.
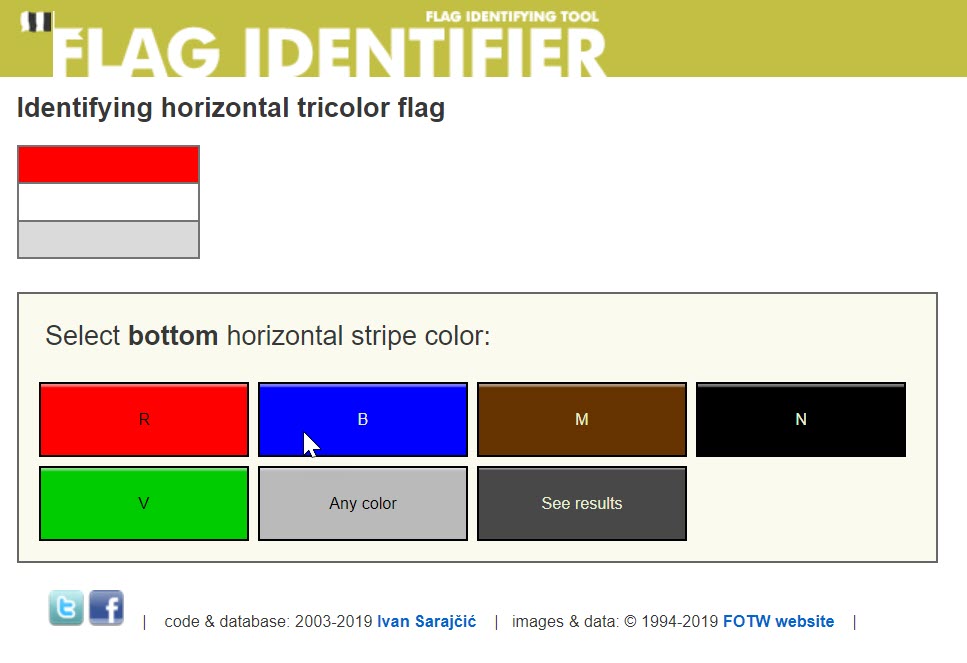
O
FlagID , donde puede ingresar manualmente información sobre la bandera y averiguar su origen.
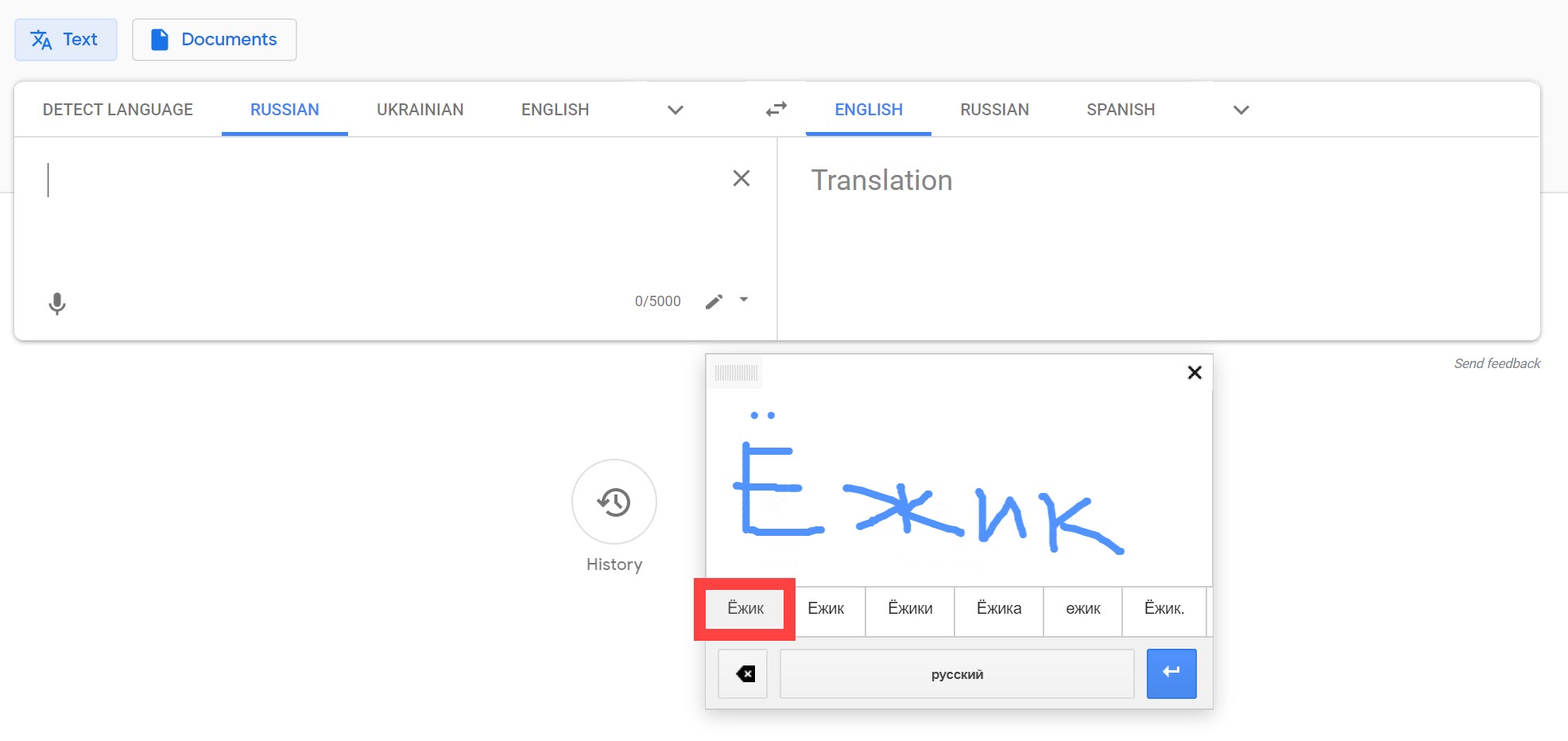
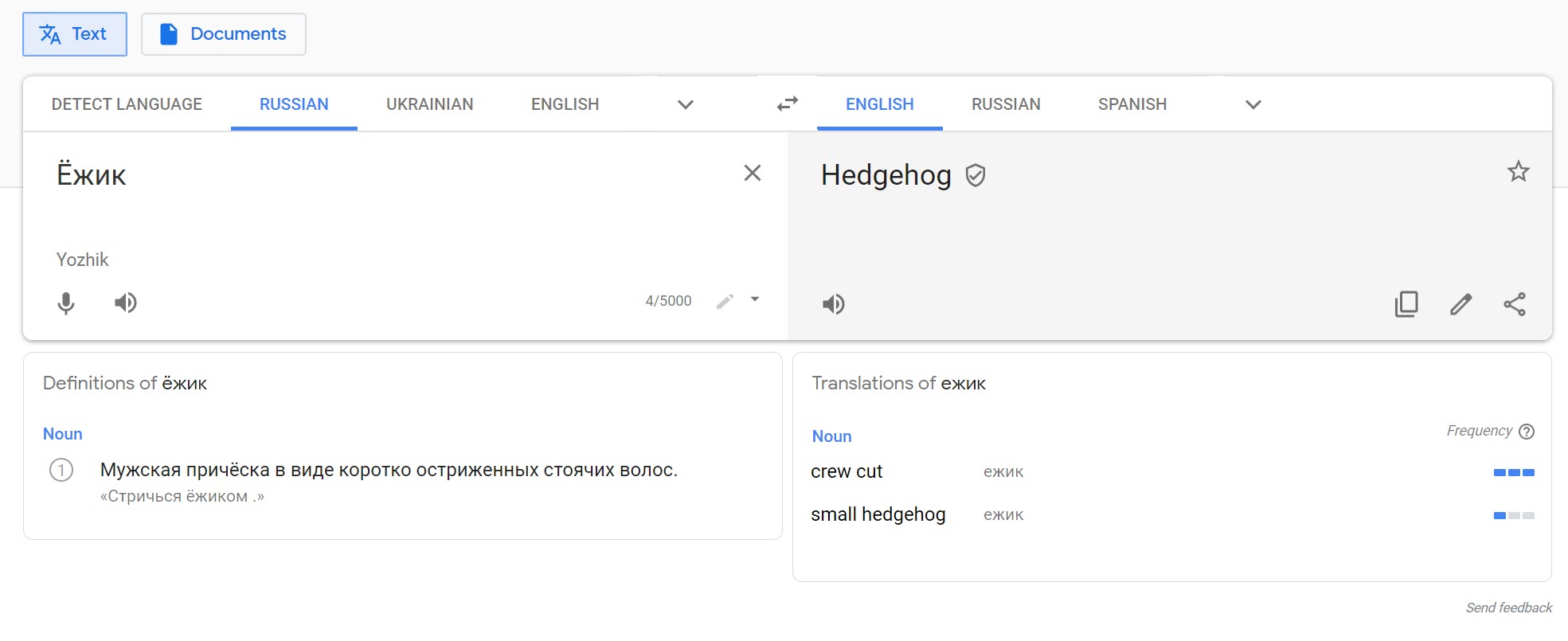
Si la fotografía contiene caracteres de un idioma desconocido, puede repetirlos manualmente con la herramienta de escritura a mano Google Translate.

Pixelización y desenfoque
Como se describe en detalle en
este hilo de Twitter , puede pixelar o desenfocar los elementos de una foto para engañar a un motor de búsqueda, y centrarse solo en el fondo. En esta foto de la portavoz Rudi Giuliani, la imagen exacta no permite entender dónde se tomó la foto.
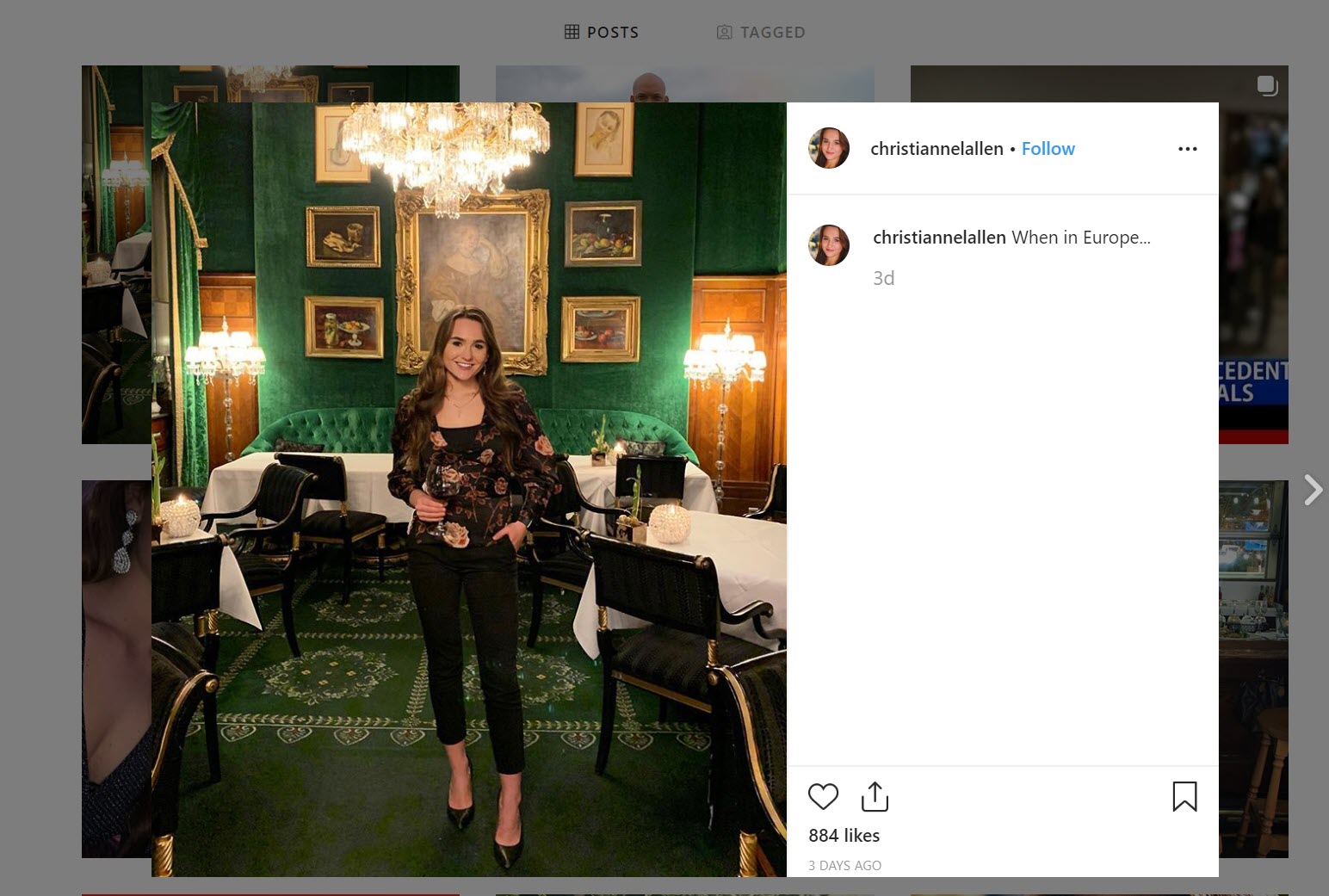
Pero si difumina / pixela a una mujer en el medio de la imagen, Yandex puede analizar otros elementos de la imagen: sillas, pinturas, candelabros, alfombras, patrones de paredes, etc.

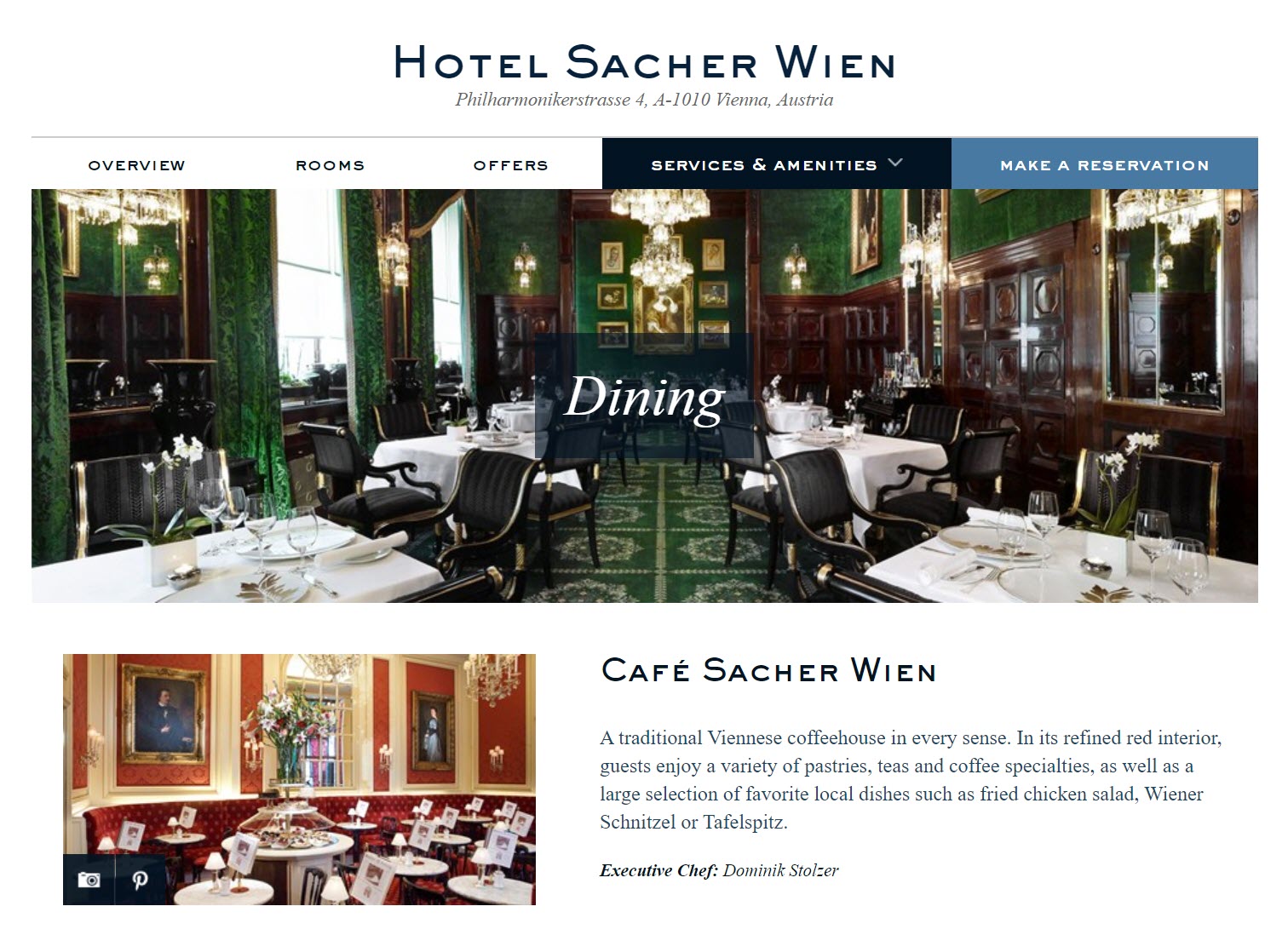
Después de eso, Yandex sabe exactamente dónde se tomó la imagen: este es un hotel popular en Viena.

Los investigadores de Bellingcat concluyen que los motores de búsqueda de imágenes inversas han avanzado significativamente en la última década, y el progreso continúa a un ritmo rápido.
Un gran crecimiento en la base de búsqueda contribuye al progreso. Las grandes compañías de Internet lograron convencer a los usuarios de que coloquen archivos de fotos personales en su alojamiento, en los que se capacita la Inteligencia Artificial:
Para este propósito, Google Photos y Yandex.Disk ofrecen un almacenamiento de fotos gratuito en cantidades ilimitadas. Esta es una cantidad interminable de material para el aprendizaje automático.
Predicen que pronto un programa público de reconocimiento facial comenzará a funcionar en Facebook o Instagram, lo que infligirá un duro golpe a la privacidad en Internet, pero también aumentará la efectividad de las investigaciones digitales.
