Hola Habr
Aquí accidentalmente obtuve el código Haskell más rápido que un código C ++ similar. A veces, en un 40%.
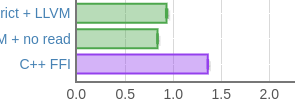
(tiempo de ejecución, menos es mejor, C ++ está por debajo)
Lo curioso es que recopilé el código de Haskell a través del backend LLVM, pero lo comparé con GCC. Si se compara con el sonido metálico (que parece ser más lógico), entonces todo se vuelve aún peor para las ventajas: por alguna razón, en esta tarea, el sonido metálico pierde GCC un par de veces, y la diferencia no es del 40%, sino aproximadamente tres veces. Sin embargo, una pequeña modificación del código C ++ cambiará esto.
Todo comenzó con el hecho de que para uno de mis proyectos (que, naturalmente, se realiza en Haskell, y sobre el que escribiré pronto), era necesario calcular de manera rápida y eficiente la distancia de Levenshtein entre dos líneas. La distancia de Levenshtein es una métrica que dice cuántos caracteres necesita eliminar, agregar o reemplazar en una línea para que sea igual a otra línea. Conté las distancias entre líneas bastante grandes (decenas de miles de caracteres en escala), por lo que la eficiencia era realmente importante.
Y luego me resultó interesante lo rápido que puedo tomar esta distancia en general (gastando una cantidad razonable de tiempo optimizando, por supuesto), así que bosquejé la opción en C ++ y tomé su tiempo para trabajar como una especie de ideal por el que debería esforzarme. Sin embargo, como ya está claro, se superó el ideal.
¿Veamos cómo se puede lograr esto?

Como beneficio adicional, una comparación con algunos otros idiomas. Spoilers
- Nim es más lento que el compilador de C hace veinte años.
- C # es cinco veces más lento que Java, que está completamente en el nivel Rust.
- Ir al ras con C.
- PHP es más rápido que python (que justifica la segunda parte del encabezado).
Sobre la distancia de LevenshteinEncontrar la distancia de Levenshtein es solo una de esas tareas que está diseñada simplemente para la programación dinámica. La solución clásica es construir una matriz de tamaño  (donde
(donde  y
y  - la longitud de las líneas) y su relleno línea por línea de arriba a abajo. Por desgracia, si las filas tienen un tamaño ridículo del orden de diez kilobytes, entonces dicha matriz engullirá 0.5-1 gigabytes, lo que no es muy agradable. Sin embargo, si observa detenidamente, notará que en cada momento usamos solo dos líneas (la actual para llenar y la anterior), por lo tanto, solo podemos almacenarlas.
- la longitud de las líneas) y su relleno línea por línea de arriba a abajo. Por desgracia, si las filas tienen un tamaño ridículo del orden de diez kilobytes, entonces dicha matriz engullirá 0.5-1 gigabytes, lo que no es muy agradable. Sin embargo, si observa detenidamente, notará que en cada momento usamos solo dos líneas (la actual para llenar y la anterior), por lo tanto, solo podemos almacenarlas.
De hecho, puede sobrevivir con una línea, pero será bueno para nosotros con dos.
Benchmarking
Mediremos el rendimiento de dos maneras.
En primer lugar, hay un paquete de criterios maravilloso que ayuda a comparar correctamente , ejecutando el código muchas veces, calculando todo tipo de desviaciones estándar y otras estadísticas.
, . s1, s2, s3, 20000 'a', — 20000 'b', s1 s2 s1 s3 (, 0 20000).
— , ( — +RTS -sstderr). , : . , — , , . , , .
, criterion' .
?
: ? : .
, L2-, L1 . ? , :
- 20000 : 40 ( , L1 !).
- 20000 8- , 160 — 320 ( 4- , 160 , L1).
/ L2?
20000 , (20 ), (160 ), ( 160 ). , ( ) : (20 + 160)×20000 L2, 3.6 . , , , Haswell L2 50 /, 0.1 , 0.2 . .
, , , , L1, .
C++:
#include <algorithm>
#include <iostream>
#include <numeric>
#include <vector>
#include <string>
size_t lev_dist(const std::string& s1, const std::string& s2)
{
const auto m = s1.size();
const auto n = s2.size();
std::vector<int64_t> v0;
v0.resize(n + 1);
std::iota(v0.begin(), v0.end(), 0);
auto v1 = v0;
for (size_t i = 0; i < m; ++i)
{
v1[0] = i + 1;
for (size_t j = 0; j < n; ++j)
{
auto delCost = v0[j + 1] + 1;
auto insCost = v1[j] + 1;
auto substCost = s1[i] == s2[j] ? v0[j] : (v0[j] + 1);
v1[j + 1] = std::min({ delCost, insCost, substCost });
}
std::swap(v0, v1);
}
return v0[n];
}
int main()
{
std::string s1(20000, 'a');
std::string s2(20000, 'a');
std::string s3(20000, 'b');
std::cout << lev_dist(s1, s2) << std::endl;
std::cout << lev_dist(s1, s3) << std::endl;
}
— 1.356 (Core i7 4770, ). gcc 9.2, — -O3 -march=native.
, clang (9.0.1, , ) : 2.6-2.7 .
— 1.3 .
( , Data.Vector, ), . Data.Vector.constructN:
import qualified Data.ByteString as BS
import qualified Data.Vector.Unboxed as V
import Data.List
levenshteinDistance :: BS.ByteString -> BS.ByteString -> Int
levenshteinDistance s1 s2 = foldl' outer (V.generate (n + 1) id) [0 .. m - 1] V.! n
where
m = BS.length s1
n = BS.length s2
outer v0 i = V.constructN (n + 1) ctr
where
s1char = s1 `BS.index` i
ctr v1 | V.length v1 == 0 = i + 1
ctr v1 = min (substCost + substCostBase) $ 1 + min delCost insCost
where
j = V.length v1
delCost = v0 V.! j
insCost = v1 V.! (j - 1)
substCostBase = v0 V.! (j - 1)
substCost = if s1char == s2 `BS.index` (j - 1) then 0 else 1
, , , ( ).
? 5.5 . - .
?
, , .
-, . {-# LANGUAGE Strict #-} . , bang patterns, .
, 3.4 . , .
-, GHC (NCG — Native CodeGen), LLVM? {-# OPTIONS_GHC -fllvm #-} . ? 2.1 . -! , , , clang.
: (, , operator[]). V.! V.unsafeIndex, BS.index BS.unsafeIndex.
import qualified Data.ByteString as BS
import qualified Data.ByteString.Unsafe as BS
import qualified Data.Vector.Unboxed as V
import Data.List
levenshteinDistance :: BS.ByteString -> BS.ByteString -> Int
levenshteinDistance s1 s2 = foldl' outer (V.generate (n + 1) id) [0 .. m - 1] V.! n
where
m = BS.length s1
n = BS.length s2
outer v0 i = V.constructN (n + 1) ctr
where
s1char = s1 `BS.unsafeIndex` i
ctr v1 | V.length v1 == 0 = i + 1
ctr v1 = min (substCost + substCostBase) $ 1 + min delCost insCost
where
j = V.length v1
delCost = v0 `V.unsafeIndex` j
insCost = v1 `V.unsafeIndex` (j - 1)
substCostBase = v0 `V.unsafeIndex` (j - 1)
substCost = if s1char == s2 `BS.unsafeIndex` (j - 1) then 0 else 1
, : , - .
, ( ) 4.2 ( 5.5 «» ).
?
{-# LANGUAGE Strict #-} 2.5 ( 3.4 «» ).
LLVM 1.6 ( 2.1 ). clang!
, :
- -C++-, - .
- , ( , 20000 , C++-). , , GC
- « » , 20% NCG. — , .
- LLVM- 0.5 . ? LLVM , ? ?
Data.Array.ST:
import qualified Data.Array.Base as A(unsafeRead, unsafeWrite)
import qualified Data.Array.ST as A
import qualified Data.ByteString.Char8 as BS
import Control.Monad
import Control.Monad.ST
levenshteinDistance :: BS.ByteString -> BS.ByteString -> Int
levenshteinDistance s1 s2 = runST $ do
v0Init <- A.newListArray (0, n) [0..]
v1Init <- A.newArray_ (0, n)
forM_ [0 .. m - 1] $ \i -> do
let (v0, v1) | even i = (v0Init, v1Init)
| otherwise = (v1Init, v0Init)
loop i v0 v1
A.unsafeRead (if even m then v0Init else v1Init) n
where
m = BS.length s1
n = BS.length s2
loop :: Int -> A.STUArray s Int Int -> A.STUArray s Int Int -> ST s ()
loop i v0 v1 = do
A.unsafeWrite v1 0 (i + 1)
let s1char = s1 `BS.index` i
forM_ [0..n - 1] $ \j -> do
delCost <- v0 `A.unsafeRead` (j + 1)
insCost <- v1 `A.unsafeRead` j
substCostBase <- v0 `A.unsafeRead` j
let substCost = if s1char == s2 `BS.index` j then 0 else 1
A.unsafeWrite v1 (j + 1) $ min (substCost + substCostBase) $ 1 + min delCost insCost
( Data.Array.ST) (Data.Vector.Mutable unboxed-) , . ( ) . «» unsafeRead/unsafeWrite.
?
5.9 . . , ! , , … , .
, GC: 2-3 2-3 ( +RTS -sstderr) Data.Vector. , , — GC , , .
?
4.1 . LLVM 0.4 , 3.7 .
, , .
.
, GHC , , . forM_ :
import qualified Data.Array.Base as A(unsafeRead, unsafeWrite)
import qualified Data.Array.ST as A
import qualified Data.ByteString.Char8 as BS
import Control.Monad.ST
levenshteinDistance :: BS.ByteString -> BS.ByteString -> Int
levenshteinDistance s1 s2 = runST $ do
v0Init <- A.newListArray (0, n) [0..]
v1Init <- A.newArray_ (0, n)
loop 0 v0Init v1Init
A.unsafeRead (if even m then v0Init else v1Init) n
where
m = BS.length s1
n = BS.length s2
loop :: Int -> A.STUArray s Int Int -> A.STUArray s Int Int -> ST s ()
loop i v0 v1 | i == m = pure ()
| otherwise = do
A.unsafeWrite v1 0 (i + 1)
let s1char = s1 `BS.index` i
let go j | j == n = pure ()
| otherwise = do
delCost <- v0 `A.unsafeRead` (j + 1)
insCost <- v1 `A.unsafeRead` j
substCostBase <- v0 `A.unsafeRead` j
let substCost = if s1char == s2 `BS.index` j then 0 else 1
A.unsafeWrite v1 (j + 1) $ min (substCost + substCostBase) $ 1 + min delCost insCost
go (j + 1)
go 0
loop (i + 1) v1 v0
— 4.3 . 1.7 — . , , GHC forM_ , .
LLVM.
0.96 . ? C++? - ?

0.96 .
.
( , ).
BS.index BS.unsafeIndex 0.04 , 0.92 .
, , . , v1[j+1] j- . , ?
{-# LANGUAGE Strict #-}
{-# OPTIONS_GHC -fllvm #-}
import qualified Data.Array.Base as A(unsafeRead, unsafeWrite)
import qualified Data.Array.ST as A
import qualified Data.ByteString as BS
import qualified Data.ByteString.Unsafe as BS
import Control.Monad.ST
levenshteinDistance :: BS.ByteString -> BS.ByteString -> Int
levenshteinDistance s1 s2 = runST $ do
v0Init <- A.newListArray (0, n) [0..]
v1Init <- A.newArray_ (0, n)
loop 0 v0Init v1Init
A.unsafeRead (if even m then v0Init else v1Init) n
where
m = BS.length s1
n = BS.length s2
loop :: Int -> A.STUArray s Int Int -> A.STUArray s Int Int -> ST s ()
loop i v0 v1 | i == m = pure ()
| otherwise = do
A.unsafeWrite v1 0 (i + 1)
let s1char = s1 `BS.unsafeIndex` i
let go j prev | j == n = pure ()
| otherwise = do
delCost <- v0 `A.unsafeRead` (j + 1)
substCostBase <- v0 `A.unsafeRead` j
let substCost = if s1char == s2 `BS.unsafeIndex` j then 0 else 1
let res = min (substCost + substCostBase) $ 1 + min delCost prev
A.unsafeWrite v1 (j + 1) res
go (j + 1) res
go 0 (i + 1)
loop (i + 1) v1 v0
0.09 , 0.83 . .
, C++ .
, ( , , ). .
. C++- — 1.36 , ( 100%).
i7-6700, :
, Haskell Haswell, Skylake. , , Haskell- C++.
criterion
criterion (, JavaScript , ).
Haswell (i7 4770):
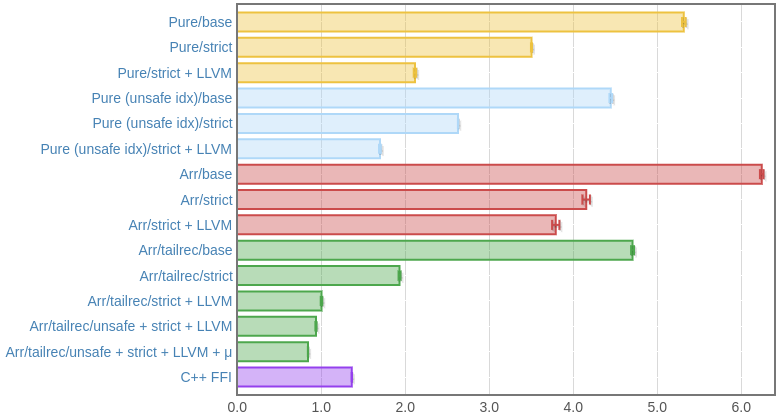
Skylake (i7 6700):
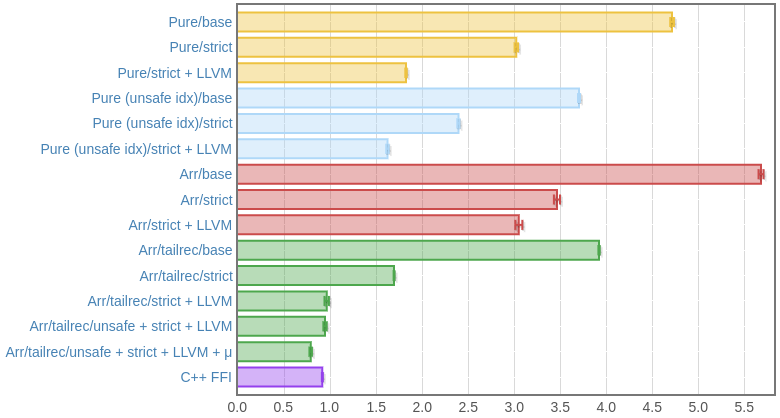
C++-, FFI. - «» C++- FFI, , FFI ( , ByteString).
- , C++ .
- (, ) .
- . GHC, , , , . .
- LLVM . , LLVM , , .
- — . , ( «» ) .
, Data.Array.ST , , , .
?
- , - , . , , C++-. , . , ( ).
- .
Data.ByteString.Char8 , , Data.ByteString. - GHC . , , .
GHC 8.6 (Stackage LTS 14.16). GHC 8.8 ( nightly- Stackage), , NCG, LLVM. . - , , . , .
unsafe , -, — , . - , — . , , ( ) .
- . , , Haswell Skylake, , C++- - . , Ryzen, AMD.
— . - C++- , , - ( — LLVM IR, ).
- , ,
std::min . , : gcc , 1.4-1.5 , clang — 0.84 , GHC.
, std::min -, , . - , , . , -, C++- . , , (. ) , .
.
, . — , .
— ( C++), . XRevan86 — , , .
15 , 20, 20 .
( Java C#) — .
C++- . (, std::min std::vector/std::string ), C main', . , «out of scope of this work».
- 2000- (BCC 5.5) . .
:
- nim' Borland C++ Compiler, 2000- . .
- Java C# - , Java ,
javac -g:none LevDist.java && java LevDist. , - . , , JIT-friendly-, , , JIT . - , clang C++-, -.
- C# .NET Core , XRevan86, . , .
- . , ?
- ( , ++) . — out of scope.
- C++. ,
std::min({ delCost, insCost, substCost }) std::min(substCost, std::min(delCost, insCost)), gcc 1.440 , clang — 0.840 (, ). , clang initializer lists , gcc , , , .
, , .
, , , C++, .
:
C#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
static long
lev_dist (const char *s1, unsigned long m
const char *s2, unsigned long n)
{
unsigned long m, n;
unsigned long i, j;
long *v0, *v1;
long ret, *temp;
/* Edge cases. */
if (m == 0) {
return n;
} else if (n == 0) {
return m;
}
v0 = malloc (sizeof (long) * (n + 1));
v1 = malloc (sizeof (long) * (n + 1));
if (v0 == NULL || v1 == NULL) {
fprintf (stderr, "failed to allocate memory\n");
exit (-1);
}
for (i = 0; i <= n; ++i) {
v0[i] = i;
}
memcpy (v1, v0, sizeof(long) * (n + 1));
for (i = 0; i < m; ++i) {
v1[0] = i + 1;
for (j = 0; j < n; ++j) {
const long subst_cost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1);
const long del_cost = v0[j + 1] + 1;
const long ins_cost = v1[j] + 1;
#if !defined(__GNUC__) || defined(__llvm__)
if (subst_cost < del_cost) {
v1[j + 1] = subst_cost;
} else {
v1[j + 1] = del_cost;
}
#else
v1[j + 1] = (subst_cost < del_cost) ? subst_cost : del_cost;
#endif
if (ins_cost < v1[j + 1]) {
v1[j + 1] = ins_cost;
}
}
temp = v0;
v0 = v1;
v1 = temp;
}
ret = v0[n];
free (v0);
free (v1);
return ret;
}
int
main ()
{
const int len = 15000;
int i;
char s1[15001], s2[15001], s3[15001];
clock_t start_time, exec_time;
for (i = 0; i < len; ++i) {
s1[i] = 'a';
s2[i] = 'a';
s3[i] = 'b';
}
s1[len] = s2[len] = s3[len] = '\0';
start_time = clock ();
printf ("%ld\n", lev_dist (s1, 15000, s2, 15000));
printf ("%ld\n", lev_dist (s1, 15000, s3, 15000));
exec_time = clock () - start_time;
fprintf (stderr,
"Finished in %.3fs\n",
((double) exec_time) / CLOCKS_PER_SEC);
return 0;
}
Crystaldef lev_dist(s1 : String, s2 : String) : Int
m = s1.bytesize
n = s2.bytesize
# Edge cases.
return n if m == 0
return m if n == 0
v0 = (Slice.new(n + 1) { |i| i }).to_unsafe
v1 = (Slice.new(n + 1) { |i| i }).to_unsafe
ca1, ca2 = s1.bytes, s2.bytes
ca1.each_with_index do |c1, i|
v1[0] = i + 1
ca2.each_with_index do |c2, j|
subst_cost = (c1 == c2) ? v0[j] : (v0[j] + 1)
del_cost = v0[j + 1] + 1
ins_cost = v1[j] + 1
# [del_cost, ins_cost, subst_cost].min is slow.
min_cost = (subst_cost < del_cost) ? subst_cost : del_cost
if ins_cost < min_cost
min_cost = ins_cost
end
v1[j + 1] = min_cost
end
v0, v1 = v1, v0
end
return v0[n]
end
s1 = "a" * 15_000
s2 = s1
s3 = "b" * 15_000
exec_time = -Time.monotonic.to_f
puts lev_dist(s1, s2)
puts lev_dist(s1, s3)
exec_time += Time.monotonic.to_f
STDERR.puts "Finished in #{"%.3f" % exec_time}s"
C#using System;
using System.Diagnostics;
using System.Linq;
using System.Text;
public class Program
{
public static Int32 LevDist(string s1, string s2)
{
var ca1 = Encoding.UTF8.GetBytes(s1);
var ca2 = Encoding.UTF8.GetBytes(s2);
return LevDist(ca1, ca2);
}
public static Int32 LevDist(byte[] s1, byte[] s2)
{
var m = s1.Length;
var n = s2.Length;
// Edge cases.
if (m == 0)
{
return n;
}
else if (n == 0)
{
return m;
}
Int32[] v0 = Enumerable.Range(0, n + 1).ToArray();
var v1 = new Int32[n + 1];
v0.CopyTo(v1, 0);
for (var i = 0; i < m; ++i)
{
v1[0] = i + 1;
for (var j = 0; j < n; ++j)
{
var substCost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1);
var delCost = v0[j + 1] + 1;
var insCost = v1[j] + 1;
v1[j + 1] = Math.Min(substCost, delCost);
if (insCost < v1[j + 1])
{
v1[j + 1] = insCost;
}
}
var temp = v0;
v0 = v1;
v1 = temp;
}
return v0[n];
}
public static int Main()
{
string s1 = new String('a', 15000);
string s2 = s1;
string s3 = new String('b', 15000);
Stopwatch execTimer = new Stopwatch();
execTimer.Start();
Console.WriteLine(LevDist(s1, s2));
Console.WriteLine(LevDist(s1, s3));
execTimer.Stop();
double execTime = execTimer.ElapsedMilliseconds / 1000.0;
Console.WriteLine($"Finished in {execTime:0.000}s");
return 0;
}
}
Dmodule main;
import core.time;
import std.stdio;
import std.algorithm : swap;
import std.array : array;
import std.range : iota, replicate;
long levDist(ref const string s1,
ref const string s2) pure nothrow @trusted
{
const auto m = s1.length;
const auto n = s2.length;
if (m == 0)
{
return n;
}
else if (n == 0)
{
return m;
}
long[] v0 = iota(0, long(n) + 1).array;
long[] v1 = v0.dup;
size_t i = 0;
foreach (ref c1; s1)
{
v1[0] = i + 1;
size_t j = 0;
foreach (ref c2; s2)
{
const auto substCost = (c1 == c2) ? v0[j] : (v0[j] + 1);
const auto delCost = v0[j + 1] + 1;
const auto insCost = v1[j] + 1;
// min(substCost, delCost, insCost) is slow.
v1[j + 1] = (substCost < delCost) ? substCost : delCost;
if (insCost < v1[j + 1])
{
v1[j + 1] = insCost;
}
++j;
}
swap(v0, v1);
++i;
}
return v0[n];
}
void main(string[] args)
{
string s1 = "a".replicate(15000);
string s2 = s1;
string s3 = "b".replicate(15000);
auto startTime = MonoTime.currTime;
writeln(levDist(s1, s2));
writeln(levDist(s1, s3));
auto endTime = MonoTime.currTime;
auto execTime = (endTime - startTime).total!"msecs" / 1000.0;
stderr.writefln("Finished in %.3fs", execTime);
}
Gopackage main
import (
"bytes"
"fmt"
"os"
"time"
)
func levDist(s1, s2 []byte) int {
m := len(s1)
n := len(s2)
// Edge cases.
if m == 0 {
return n
} else if n == 0 {
return m
}
root := make([]int, (n+1)*2)
v0 := root[:n+1]
v1 := root[n+1:]
for i, _ := range v0 {
v0[i] = i
}
copy(v1, v0)
for i, c1 := range s1 {
v1[0] = i + 1
for j, c2 := range s2 {
substCost := v0[j]
if c1 != c2 {
substCost++
}
delCost := v0[j+1] + 1
insCost := v1[j] + 1
if substCost < delCost {
v1[j+1] = substCost
} else {
v1[j+1] = delCost
}
if insCost < v1[j+1] {
v1[j+1] = insCost
}
}
v0, v1 = v1, v0
}
return v0[n]
}
func main() {
s1 := bytes.Repeat([]byte("a"), 15000)
s2 := s1
s3 := bytes.Repeat([]byte("b"), 15000)
startTime := time.Now()
fmt.Println(levDist(s1, s2))
fmt.Println(levDist(s1, s3))
execTime := time.Now().Sub(startTime).Seconds()
fmt.Fprintf(os.Stderr, "Finished in %.3fs\n", execTime)
}
Rustuse std::cmp::min;
use std::time::Instant;
fn lev_dist(s1: &str, s2: &str) -> i32 {
let m = s1.len();
let n = s2.len();
// Edge cases.
if m == 0 {
return n as i32;
} else if n == 0 {
return m as i32;
}
let mut v0: Vec<i32> = (0..).take(n + 1).collect();
let mut v1 = v0.to_vec();
for (i, c1) in s1.bytes().enumerate() {
unsafe {
*v1.get_unchecked_mut(0) = i as i32 + 1;
for (j, c2) in s2.bytes().enumerate() {
let mut subst_cost = *v0.get_unchecked(j);
if c1 != c2 {
subst_cost += 1;
}
let del_cost = *v0.get_unchecked(j + 1) + 1;
let ins_cost = *v1.get_unchecked(j) + 1;
let mut min_cost = min(subst_cost, del_cost);
if ins_cost < min_cost {
min_cost = ins_cost;
}
*v1.get_unchecked_mut(j + 1) = min_cost;
}
}
std::mem::swap(&mut v0, &mut v1);
}
return v0[n];
}
fn main() {
let s1 = "a".repeat(15000);
let s2 = &s1;
let s3 = "b".repeat(15000);
let start_time = Instant::now();
println!("{}", lev_dist(&s1, &s2));
println!("{}", lev_dist(&s1, &s3));
let exec_time = start_time.elapsed().as_millis() as f64 / 1000.0;
eprintln!("Finished in {:.3}s", exec_time);
}
Zigconst std = @import("std");
const time = std.time;
const Allocator = std.mem.Allocator;
pub fn lev_dist(allocator: *Allocator, s1: []const u8, s2: []const u8) !i32 {
@setRuntimeSafety(false);
const m = s1.len;
const n = s2.len;
// Edge cases.
if (m == 0) {
return @intCast(i32, n);
} else if (n == 0) {
return @intCast(i32, m);
}
var root = try allocator.alloc(i32, (n + 1) * 2);
defer allocator.free(root);
var v0 = root[0..(n + 1)];
var v1 = root[(n + 1)..];
for (v0) |*it, i| {
it.* = @intCast(i32, i);
}
std.mem.copy(i32, v1, v0);
for (s1) |c1, i| {
v1[0] = @intCast(i32, i) + 1;
for (s2) |c2, j| {
const subst_cost = if (c1 == c2) v0[j] else (v0[j] + 1);
const del_cost = v0[j + 1] + 1;
const ins_cost = v1[j] + 1;
// std.mem.min(i32, [_]i32{subst_cost, del_cost, ins_cost}) is slow.
v1[j + 1] = if (subst_cost < del_cost) subst_cost else del_cost;
if (ins_cost < v1[j + 1]) {
v1[j + 1] = ins_cost;
}
}
std.mem.swap([]i32, &v0, &v1);
}
return v0[n];
}
pub fn main() !void {
const allocator = std.heap.page_allocator;
const stdout = &(try std.io.getStdOut()).outStream().stream;
const s1 = [_]u8{'a'} ** 15000;
const s2 = s1;
const s3 = [_]u8{'b'} ** 15000;
var exec_timer = try time.Timer.start();
try stdout.print("{}\n", try lev_dist(allocator, s1, s2));
try stdout.print("{}\n", try lev_dist(allocator, s1, s3));
const exec_time = @intToFloat(f64, exec_timer.read()) / time.ns_per_s;
std.debug.warn("Finished in {d:.3}s\n", exec_time);
}
Pascalprogram main(output);
uses
sysutils, dateutils;
function levDist(const s1: AnsiString; const s2: AnsiString): longint;
var
m, n: NativeUint;
i, j: NativeUint;
c1, c2: AnsiChar;
v0, v1, temp: array of longint;
substCost, delCost, insCost: longint;
begin
m := length(s1);
n := length(s2);
// Edge cases.
if m = 0 then
exit(n)
else if n = 0 then
exit(m);
setLength(v0, n+1);
for i := 0 to n do
v0[i] := i;
v1 := copy(v0, 0, n+1);
i := 0;
for c1 in s1 do
begin
j := 0;
v1[0] := i + 1;
for c2 in s2 do
begin
substCost := v0[j];
if c1 <> c2 then
inc(substCost);
delCost := v0[j+1] + 1;
insCost := v1[j] + 1;
if substCost < delCost then
v1[j+1] := substCost
else
v1[j+1] := delCost;
if insCost < v1[j+1] then
v1[j+1] := insCost;
inc(j);
end;
temp := v0;
v0 := v1;
v1 := temp;
inc(i);
end;
exit(v0[n]);
end;
var
i: integer;
s1, s2, s3: AnsiString;
startTime, execTime: TDateTime;
begin
s1 := '';
s3 := '';
for i := 1 to 15000 do
begin
s1 := s1 + 'a';
s3 := s3 + 'b';
end;
s2 := s1;
startTime := now;
writeln(levDist(s1, s2));
writeln(levDist(s1, s3));
execTime := secondSpan(startTime, now);
writeln(stderr, format('Finished in %.3fs', [execTime]));
end.
Nimimport strformat, strutils, times
{.push checks: off.}
func levDist(s1, s2: string): int32 =
let m = s1.len
let n = s2.len
# Edge cases.
if m == 0: return int32(n)
elif n == 0: return int32(m)
var v0 = newSeq[int32](n + 1)
for i, _ in v0:
v0[i] = int32(i)
var v1 = v0
for i, c1 in s1:
v1[0] = int32(i) + 1
for j, c2 in s2:
let delCost = v0[j + 1] + 1
let insCost = v1[j] + 1
var substCost = v0[j]
if c1 != c2:
inc(substCost)
# min([substCost, delCost, insCost]) is slow.
v1[j + 1] = min(substCost, delCost)
if insCost < v1[j + 1]:
v1[j + 1] = insCost
swap(v0, v1)
result = v0[n]
{.pop.}
let s1 = repeat("a", 15000)
let s2 = s1
let s3 = repeat("b", 15000)
let startTime = cpuTime()
echo levDist(s1, s2)
echo levDist(s1, s3)
let execTime = cpuTime() - startTime;
stderr.write &"Finished in {execTime:.3f}s\n";
Javaimport java.util.Arrays;
import java.util.stream.LongStream;
import java.lang.Math;
public class LevDist
{
public static long levDist(String s1, String s2)
{
return levDist(s1.getBytes(), s2.getBytes());
}
public static long levDist(byte[] s1, byte[] s2)
{
int m = s1.length;
int n = s2.length;
// Edge cases.
if (m == 0) {
return n;
} else if (n == 0) {
return m;
}
long[] v0 = LongStream.range(0, n + 1).toArray();
long[] v1 = v0.clone();
int i = 0, j;
for (byte c1 : s1) {
v1[0] = i + 1;
j = 0;
for (byte c2 : s2) {
long substCost = (c1 == c2) ? v0[j] : (v0[j] + 1);
long delCost = v0[j + 1] + 1;
long insCost = v1[j] + 1;
v1[j + 1] = Math.min(substCost, delCost);
if (insCost < v1[j + 1]) {
v1[j + 1] = insCost;
}
++j;
}
long[] temp = v0;
v0 = v1;
v1 = temp;
++i;
}
return v0[n];
}
public static void main(String[] args)
{
byte[] s1 = new byte[15000];
byte[] s2 = s1;
byte[] s3 = new byte[15000];
Arrays.fill(s1, (byte) 'a');
Arrays.fill(s3, (byte) 'b');
long execTime = -System.nanoTime();
System.out.println(levDist(s1, s2));
System.out.println(levDist(s1, s3));
execTime += System.nanoTime();
System.err.printf("Finished in %.3fs%n", execTime / 1000000000.0);
}
}
:
- , V8 — JS-. .
- - (, ∞).
- Python . Pypy , - Julia.
- Octave , , .
- Raku , . 12 , .
Julia#!/usr/bin/env julia
using Base: @pure, stderr
using Printf
@pure function lev_dist(s1::AbstractString, s2::AbstractString)::Int32
m, n = sizeof(s1), sizeof(s2)
m == 0 && return n
n == 0 && return m
ca1, ca2 = codeunits(s1), codeunits(s2)
v0::Vector{Int32} = collect(0:n)
v1 = copy(v0)
@inbounds begin
for (i, c1) in enumerate(ca1)
v1[1] = i
for (j, c2) in enumerate(ca2)
subst_cost = v0[j] + ((c1 === c2) ? 0 : 1)
del_cost = v0[j + 1] + 1
ins_cost = v1[j] + 1
v1[j + 1] = min(subst_cost, del_cost, ins_cost)
end
v0, v1 = v1, v0
end
end
return v0[n + 1]
end
let
s1 = 'a'^15000
s2 = s1
s3 = 'b'^15000
exec_time = @elapsed begin
println(lev_dist(s1, s2))
println(lev_dist(s1, s3))
end
@printf(stderr, "Finished in %.3fs\n", exec_time)
end
JSfunction stringToByteArray(s) {
let a = [];
for (let c of s) {
c = c.charCodeAt(0);
do {
a.unshift(c & 0xFF);
c >>= 8;
} while (c !== 0);
}
return a;
}
function levDist(s1, s2) {
if (typeof s1 === "string" || s1 instanceof String) {
s1 = stringToByteArray(s1);
}
if (typeof s2 === "string" || s2 instanceof String) {
s2 = stringToByteArray(s2);
}
const m = s1.length;
const n = s2.length;
// Edge cases.
if (m == 0) {
return n;
} else if (n == 0) {
return m;
}
let v0 = [];
for (let i = 0; i <= n; ++i) {
v0[i] = i;
}
let v1 = v0.slice();
for (let i = 0; i < m; ++i) {
v1[0] = i + 1;
for (let j = 0; j < n; ++j) {
const substCost = v0[j] + ((s1[i] === s2[j]) ? 0 : 1);
const delCost = v0[j + 1] + 1;
const insCost = v1[j] + 1;
// Math.min(substCost, delCost, insCost) is slow.
v1[j + 1] = (substCost < delCost) ? substCost : delCost;
if (insCost < v1[j + 1]) {
v1[j + 1] = insCost;
}
}
[v0, v1] = [v1, v0];
}
return v0[n];
}
var s1 = new Uint8Array(15000);
var s2 = s1;
var s3 = new Uint8Array(s1.length);
for (let i = 0; i < s1.length; ++i) {
s1[i] = "a".charCodeAt(0);
s3[i] = "b".charCodeAt(0);
}
var execTime = -Date.now();
console.log(levDist(s1, s2));
console.log(levDist(s1, s3));
execTime += Date.now();
console.log(`Finished in ${(execTime / 1000).toFixed(3)}s`);
Python#!/usr/bin/env python3
import sys
import time
from typing import AnyStr
def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
if isinstance(s1, str): s1 = s1.encode()
if isinstance(s2, str): s2 = s2.encode()
m = len(s1)
n = len(s2)
# Edge cases.
if m == 0: return n
elif n == 0: return m
v0 = list(range(0, n + 1))
v1 = v0[:]
for i, c1 in enumerate(s1):
v1[0] = i + 1
for j, c2 in enumerate(s2):
subst_cost = v0[j] if c1 == c2 else (v0[j] + 1)
del_cost = v0[j + 1] + 1
ins_cost = v1[j] + 1
# min(subst_cost, del_cost, ins_cost) is slow.
min_cost = subst_cost if subst_cost < del_cost else del_cost
if ins_cost < min_cost:
min_cost = ins_cost
v1[j + 1] = min_cost
v0, v1 = v1, v0
return v0[n]
if __name__ == "__main__":
s1 = b"a" * 15_000
s2 = s1
s3 = b"b" * 15_000
exec_time = -time.monotonic()
print(lev_dist(s1, s2))
print(lev_dist(s1, s3))
exec_time += time.monotonic()
print(f"Finished in {exec_time:.3f}s", file=sys.stderr)
Lua#!/usr/bin/env lua
function levDist (s1, s2)
local m = s1:len()
local n = s2:len()
-- Edge cases
if m == 0 then return n end
if n == 0 then return m end
local ct1, ct2 = {}, {}
for i = 1, #s1 do
ct1[i] = s1:sub(i, i)
end
for i = 1, #s2 do
ct2[i] = s2:sub(i, i)
end
local v0, v1 = {}, {}
for i = 1, n + 1 do
v0[i] = i - 1
v1[i] = i - 1
end
local minCost, substCost, delCost, insCost
for i, c1 in pairs(ct1) do
v1[1] = i
for j, c2 in pairs(ct2) do
substCost = (c1 == c2) and v0[j] or (v0[j] + 1)
delCost = v0[j + 1] + 1
insCost = v1[j] + 1
-- math.min(substCost, delCost, insCost) is slow.
minCost = (substCost < delCost) and substCost or delCost
if insCost < minCost then
minCost = insCost
end
v1[j + 1] = minCost
end
v0, v1 = v1, v0
end
return v0[n + 1]
end
s1 = string.rep("a", 15000)
s2 = s1
s3 = string.rep("b", 15000)
execTime = -os.clock()
print(levDist(s1, s2))
print(levDist(s1, s3))
execTime = execTime + os.clock()
io.stderr:write(string.format("Finished in %.3fs\n", execTime))
PHP#!/usr/bin/env php
<?php
function lev_dist(string $s1, string $s2): int
{
$m = strlen($s1);
$n = strlen($s2);
// Edge cases.
if ($m == 0) {
return $n;
} elseif ($n == 0) {
return $m;
}
$ca1 = $ca2 = [];
for ($i = 0; $i < $m; ++$i) {
$ca1[] = ord($s1[$i]);
}
for ($i = 0; $i < $n; ++$i) {
$ca2[] = ord($s2[$i]);
}
$v0 = range(0, $n + 1);
$v1 = $v0;
foreach ($ca1 as $i => $c1) {
$v1[0] = $i + 1;
foreach ($ca2 as $j => $c2) {
$subst_cost = ($c1 == $c2) ? $v0[$j] : ($v0[$j] + 1);
$del_cost = $v0[$j + 1] + 1;
$ins_cost = $v1[$j] + 1;
// min($subst_cost, $del_cost, $ins_cost) is slow.
$min_cost = ($subst_cost < $del_cost) ? $subst_cost : $del_cost;
if ($ins_cost < $min_cost) {
$min_cost = $ins_cost;
}
$v1[$j + 1] = $min_cost;
}
[$v0, $v1] = [$v1, $v0];
}
return $v0[$n];
}
$s1 = str_repeat('a', 15000);
$s2 = $s1;
$s3 = str_repeat('b', 15000);
$exec_time = -hrtime(true);
echo lev_dist($s1, $s2), "\n";
echo lev_dist($s1, $s3), "\n";
$exec_time += hrtime(true);
fprintf(STDERR, "Finished in %.3fs\n", $exec_time / 1000000000);
HHVM#!/usr/bin/env hhvm
function lev_dist(string $s1, string $s2): int {
$m = \strlen($s1);
$n = \strlen($s2);
// Edge cases.
if ($m == 0) {
return $n;
} else if ($n == 0) {
return $m;
}
$ca1 = $ca2 = vec[];
for ($i = 0; $i < $m; ++$i) {
$ca1[] = \ord($s1[$i]);
}
for ($i = 0; $i < $n; ++$i) {
$ca2[] = \ord($s2[$i]);
}
$v0 = vec(\range(0, $n + 1));
$v1 = $v0;
foreach ($ca1 as $i => $c1) {
$v1[0] = $i + 1;
foreach ($ca2 as $j => $c2) {
$subst_cost = ($c1 == $c2) ? $v0[$j] : ($v0[$j] + 1);
$del_cost = $v0[$j + 1] + 1;
$ins_cost = $v1[$j] + 1;
// \min($subst_cost, $del_cost, $ins_cost) is slow.
$min_cost = ($subst_cost < $del_cost) ? $subst_cost : $del_cost;
if ($ins_cost < $min_cost) {
$min_cost = $ins_cost;
}
$v1[$j + 1] = $min_cost;
}
list($v0, $v1) = vec[$v1, $v0];
}
return $v0[$n];
}
<<__EntryPoint>>
function main(): void {
$s1 = \str_repeat('a', 15000);
$s2 = $s1;
$s3 = \str_repeat('b', 15000);
$exec_time = -\clock_gettime_ns(\CLOCK_MONOTONIC);
echo lev_dist($s1, $s2), "\n";
echo lev_dist($s1, $s3), "\n";
$exec_time += \clock_gettime_ns(\CLOCK_MONOTONIC);
\fprintf(\STDERR, "Finished in %.3fs\n", $exec_time / 1000000000);
}
NQP#!/usr/bin/env nqp
use nqp;
sub str-to-byte-array(str $s) {
my @a;
for nqp::split('', $s) -> $c {
$c := nqp::ord($c);
repeat {
my uint8 $b := $c +& 0xFF;
@a.unshift($b);
$c := nqp::bitshiftr_i($c, 8);
} while $c != 0;
}
return @a;
}
sub lev-dist(str $s1, str $s2) {
my @ca1 := str-to-byte-array($s1);
my @ca2 := str-to-byte-array($s2);
my $m := nqp::elems(@ca1);
my $n := nqp::elems(@ca2);
# Edge cases.
return $n if $m == 0;
return $m if $n == 0;
my @v0[$n + 1];
my @v1[$n + 1];
my int $i := 0;
while $i <= $n {
@v0[$i] := $i;
@v1[$i] := $i;
++$i;
}
$i := 0;
for @ca1 -> $c1 {
@v1[0] := $i + 1;
my int $j := 0;
for @ca2 -> $c2 {
my int $subst-cost := @v0[$j] + (($c1 == $c2) ?? 0 !! 1);
my int $del-cost := @v0[$j + 1] + 1;
my int $ins-cost := @v1[$j] + 1;
my int $min-cost := ($subst-cost < $del-cost) ?? $subst-cost !! $del-cost;
if $ins-cost < $min-cost {
$min-cost := $ins-cost;
}
@v1[$j + 1] := $min-cost;
++$j;
}
my @temp := @v0;
@v0 := @v1;
@v1 := @temp;
++$i;
}
return @v0[$n];
}
sub MAIN(*@ARGS) {
my str $s1 := nqp::x('a', 15_000);
my str $s2 := $s1;
my str $s3 := nqp::x('b', 15_000);
my num $start-time := nqp::time_n();
say(lev-dist($s1, $s2));
say(lev-dist($s1, $s3));
my num $exec-time := nqp::sub_n(nqp::time_n(), $start-time);
stderr().print(nqp::sprintf("Finished in %.3fs\n", [$exec-time]));
}
Ruby#!/usr/bin/env ruby
# encoding: utf-8
def lev_dist(s1, s2)
m = s1.bytesize
n = s2.bytesize
# Edge cases.
return n if m == 0
return m if n == 0
v0 = (0..n).to_a
v1 = v0.dup
ca1, ca2 = s1.bytes, s2.bytes
ca1.each_with_index do |c1, i|
v1[0] = i + 1
ca2.each_with_index do |c2, j|
subst_cost = (c1 == c2) ? v0[j] : (v0[j] + 1)
del_cost = v0[j + 1] + 1
ins_cost = v1[j] + 1
# [del_cost, ins_cost, subst_cost].min is slow.
min_cost = (subst_cost < del_cost) ? subst_cost : del_cost
if ins_cost < min_cost
min_cost = ins_cost
end
v1[j + 1] = min_cost
end
v0, v1 = v1, v0
end
return v0[n]
end
s1 = "a" * 15_000
s2 = s1
s3 = "b" * 15_000
exec_time = -Process.clock_gettime(Process::CLOCK_MONOTONIC)
puts lev_dist(s1, s2)
puts lev_dist(s1, s3)
exec_time += Process.clock_gettime(Process::CLOCK_MONOTONIC)
STDERR.puts "Finished in #{"%.3f" % exec_time}s"
Raku#!/usr/bin/env raku
=encoding utf8;
use v6;
multi lev-dist(Str:D $s1, Str:D $s2 --> Int:D) {
my $ca1 := buf8.new($s1.encode);
my $ca2 := buf8.new($s2.encode);
return lev-dist($ca1, $ca2);
}
multi lev-dist(buf8:D $s1, buf8:D $s2 --> Int:D) {
my $m := $s1.bytes;
my $n := $s2.bytes;
# Edge cases.
return $n if $m == 0;
return $m if $n == 0;
my @ca1 = $s1.list;
my @ca2 = $s2.list;
my @v0[$n + 1] = 0..$n;
my @v1[$n + 1] = 0..$n;
for @ca1.kv -> $i, $c1 {
@v1[0] = $i + 1;
for @ca2.kv -> $j, $c2 {
my $subst-cost := @v0[$j] + (($c1 == $c2) ?? 0 !! 1);
my $del-cost := @v0[$j + 1] + 1;
my $ins-cost := @v1[$j] + 1;
# min($subst-cost, $del-cost, $ins-cost) is slow.
my $min-cost := ($subst-cost < $del-cost) ?? $subst-cost !! $del-cost;
if $ins-cost < $min-cost {
$min-cost = $ins-cost;
}
@v1[$j + 1] = $min-cost;
}
my @temp := @v0;
@v0 := @v1;
@v1 := @temp;
}
return @v0[$n];
}
sub MAIN() {
my $s1 := 'a' x 15_000;
my $s2 := $s1;
my $s3 := 'b' x 15_000;
my $start-time := now;
say(lev-dist($s1, $s2));
say(lev-dist($s1, $s3));
my $exec-time := now - $start-time;
note(sprintf("Finished in %.3fs", $exec-time));
}
Octave#!/usr/bin/env octave
1;
function retval = lev_dist (s1, s2)
if (!isvector (s1) || iscell (s1) || !isvector (s2) || iscell (s2))
error ("lev_dist: Incompatible types in assignment");
endif
m = length (s1);
n = length (s2);
if (m == 0)
retval = n;
elseif (n == 0)
retval = m;
else
v0 = [0:n];
v1 = v0;
for i = 1:m
v1(1) = i;
for j = 1:n
subst_cost = v0(j) + (s1(i) != s2(j));
del_cost = v0(j + 1) + 1;
ins_cost = v1(j) + 1;
# min ([subst_cost, del_cost, ins_cost]) is slow.
if (subst_cost < del_cost)
min_cost = subst_cost;
else
min_cost = del_cost;
endif
if (ins_cost < min_cost)
min_cost = ins_cost;
endif
v1(j + 1) = min_cost;
endfor
[v0, v1] = deal (v1, v0);
endfor
retval = v0(n + 1);
endif
endfunction
function main ()
s1 = repmat (["a"], 15_000, 1);
s2 = s1;
s3 = repmat (["b"], 15_000, 1);
tic ();
printf ("%d\n", lev_dist (s1, s2));
printf ("%d\n", lev_dist (s1, s3));
exec_time = toc ();
fprintf (stderr, "Finished in %.3fs\n", exec_time);
endfunction
main ();
Python c JIT- Numba .
()
, , . , . , ( - MKL), , , FFI.
.
?
- SML MLton (, , ).
- Idris 2 uniqueness types. , ( unsafe, ).
.
UPD: std::min, , , C++. , , (clang).
UPD2: . , ldc2 C, gcc ( ) , clang ( 0.877 0.855 ).