Durante mucho tiempo, muchas personas han estado utilizando o buscando activamente el modelo de almacenamiento y publicación de
documentación como código , esto significa aplicar las mismas reglas, herramientas y procedimientos a la documentación que al código del programa, por ejemplo, almacenarlo en el repositorio, ejecutar pruebas, compilar y publicar en CI / CD. Este enfoque le permite mantener actualizada la documentación con el código, la versión y realizar un seguimiento de los cambios utilizando herramientas de desarrollo conocidas.
Sin embargo, al mismo tiempo, muchas empresas también han tenido wikis durante años, en los que otros equipos y empleados, por ejemplo, gerentes de proyectos, tienen acceso a la documentación. ¿Qué sucede si desea llevar el almacenamiento y la publicación a una sola vista, es decir, junto con los muelles de publicación HTML en Confluence? En este artículo, daré una descripción general de las soluciones para la tarea de publicar documentos desde el repositorio en Confluence.
He estado
utilizando activamente una solución durante mucho tiempo en el equipo de desarrollo de interfaz (paquete RST-Sphinx + sphinxcontribbuilder), y presentaré las otras como una alternativa, diré de inmediato que no las he probado en la práctica, solo estudié la configuración.
Sphinx doc + sphinxcontribbuilder
Sphinx (que no debe confundirse con el índice de búsqueda del mismo nombre) es un generador de documentación escrito en Python y utilizado activamente por la comunidad; también funciona bastante bien en otros entornos.
No nos detendremos en configurarlo en detalle, solo haré una reserva para que pueda generar HTML estático, man, pdf y otros formatos, y para un ensamblaje y publicación correctos en el repositorio debe haber archivos index.rst (diseño de la página principal), conf.py (archivo de configuración) y Makefile (un archivo que describe el proceso de generación de formatos, aquí es bastante posible coserlo en la ventana acoplable y ejecutar el comando
sphinx-build allí).
Fuera de la caja, Sphinx puede generar muelles a partir del diseño liviano * .rst (RestructuredText), pero agregamos la capacidad de escribir en Markdown (sabor CommonMark) para aquellos desarrolladores que se sienten más cómodos (la extensión
m2r que convierte MD a RST nos ayudó) .
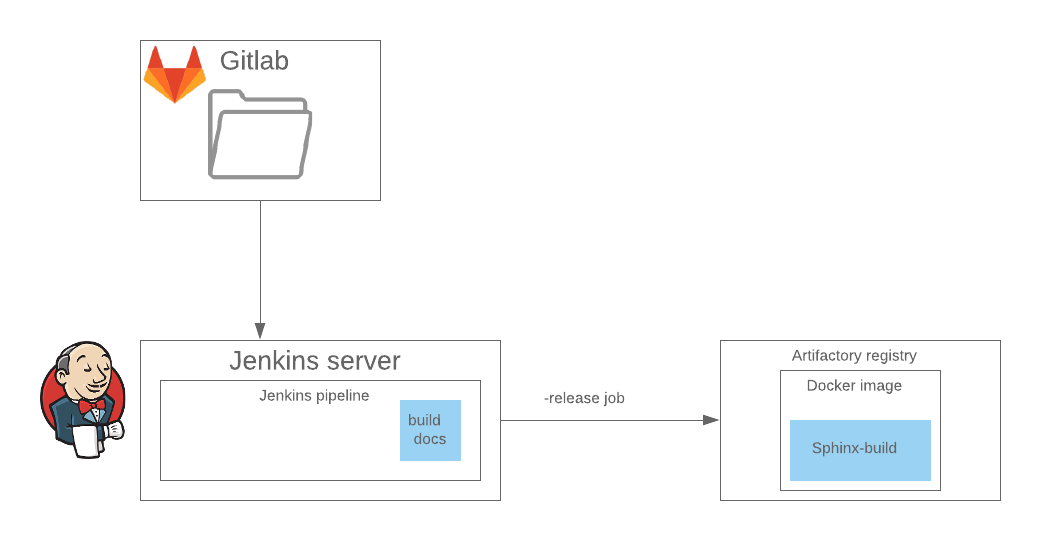
Ya hemos configurado todo el entorno para Sphinx, y el ensamblaje de la documentación está cosido en una etapa separada en la
tubería de Jenkins, por lo que seguimos adelante y utilizamos la extensión
sphinxcontrib.confluencebuilder , que puede recopilar muelles en el formato nativo para Confluence y luego publicarlos. La confluencia en este caso es uno de los formatos de salida de documentación, junto con HTML.

Para que esto funcione, debe conectar las extensiones en conf.py, a continuación se muestra el fragmento de configuración.
extensions = [ 'sphinxcontrib.confluencebuilder', 'm2r' ] templates_path = ['_templates'] source_suffix = ['.rst', '.md'] master_doc = 'index' exclude_patterns = [ u'docs/warning-plate.rst', u'FEATURE.md', u'CHANGELOG.md', u'builder/README.md' ]
Y luego configura la extensión, tiene un conjunto de configuraciones:
confluence_publish = True
El punto importante es que incluso si la página (fuente en .rst) no se especifica en toc y no se agrega a exclude_patterns, aún se publicará, pero fuera de la jerarquía.
Los nombres de las páginas en Confluence corresponderán al primer título de la página, por ejemplo, si tiene el encabezado Example en el archivo example.rst, subrayado con signos de igual, se convertirá en el nombre de la página en Confluence.
La regla de higiene, que es bastante obvia, pero aún así: cree un bot con datos de autorización para los que publicará documentos, se pueden transferir como variables de entorno en la composición de la ventana acoplable, que se utilizan en las tuberías.
Por supuesto, hay dificultades. En primer lugar, no toda la sintaxis RST es compatible para su publicación en Confluence (□ ° □ °) ╯︵ ┻━┻), esto es inconveniente si desea recopilar HTML y Confluence de una fuente. Las directivas de contenedor, hlist no son compatibles, casi todos los atributos de directiva, por ejemplo, resaltar líneas en código de bloque, numeración en la tabla de contenido, alinear y ancho para listtable.
La lista de lo que se admite es bastante buena .
De los agradables, los incluidos son compatibles, esto le permite reutilizar fragmentos de contenido entre diferentes documentos, autodoc para ensamblar documentación a partir de código, matemática para fórmulas matemáticas, dibujar tickets y filtros de jira (para esto también deberá registrar un servidor Jira en la configuración), encabezados numerados y mucho otro, literalmente el 3 de enero lanzó una
gran actualización .
Por cierto, el soporte de Jira apareció en el multiconvertidor de Pandoc, a partir de la
versión 2.7.3 Pandoc admitió el marcado de wiki de confluencia correspondiente.
Para esas macros y elementos de Confluence que no son compatibles, hay un truco sucio. RST tiene una directiva
... raw :: , y tiene un atributo de confluencia, acepta marcado de conf, si realmente necesita algún tipo de macro, puede copiarlo en el modo de edición de la página en Confluence (el modo de código fuente está disponible con el icono <>) y pegue su código "crudo" allí. Pero no te enseñé esto.
.. raw:: confluence <ac:structured-macro ac:macro-id="c38bab13-b51e-4129-85ef-737eab8a1c47" ac:name="status" ac:schema-version=^_^quot quot^_^> <ac:parameter ac:name="colour">Green</ac:parameter> <ac:parameter ac:name="title">Is used</ac:parameter> </ac:structured-macro>
El resultado es el siguiente:

¿Por qué necesitábamos configurar la publicación desde el repositorio local a la página de prueba, y no inmediatamente para "pinchar"? El hecho es que cuando publica todas las páginas se vuelven a publicar cada vez y muele los cambios realizados manualmente o los comentarios en la línea (en línea). Por lo tanto, cuando el documento está en progreso, decidimos publicarlo en una página separada, como el modo de desarrollo, para agregar versiones publicadas a la revisión y recopilar comentarios.
En CI, la publicación se implementa como una etapa separada en la canalización de Jenkins, dentro de esta etapa se lanza la imagen del acoplador en el registro remoto, que implementa sphinx-build con la configuración deseada. Es mejor omitir este paso de inmediato.
pipeline { agent { label "${AGENT_LABEL}" } stage("Documentation") { steps { ansiColor('xterm') { withCredentials([usernamePassword( credentialsId: "${DOCUMENTATION_BOT}", usernameVariable: 'CONFLUENCE_USERNAME', passwordVariable: 'CONFLUENCE_PASSWORD' )]) { sh "docker-compose -p $COMPOSE_ID run sphinx-doc confluence" } }} }
Dentro del escenario,
se lanza la
confluencia docker-compose -p release-branch-name run sphinx-doc . Jenkinsfile, a su vez, describe las dependencias y el entorno en el que se realizará el paso, el proceso de ensamblar y actualizar la información en el destino. De las pruebas hasta ahora solo hay una verificación de sintaxis de .md y .rst con doc8 y markdownlinter.
Otro matiz: cada vez que publica una subred de página, Sphinx actualiza todo el árbol, cada página. Es decir, incluso si el contenido no ha cambiado, se crea un cambio, si tiene notificaciones configuradas en el canal, se obstruirá con muchas notificaciones.
Algunas formas más
Foliant con confluencia como backend
Herramienta de documentación foliante con Mkdocs y muchos preprocesadores bajo el capó y el backend en forma de Confluence. Puede
leer más aquí , pero en resumen, usa pandoc para convertir md a HTML, y luego lo publica en Confluence. Solo necesita configurar el backend e instalar pandoc en el entorno como una dependencia.
Diferencias favorables con respecto a la primera solución: puede restaurar comentarios en línea en los mismos lugares que estaban antes de que se publicara la página, le permite crear páginas configurándolas en la configuración, editar sus nombres y también insertar contenido en una página existente, para esto necesita configurar manualmente Anclaje foliante en la página en confluencia.
Funciona solo con la fuente en Markdown.
Metro
Una herramienta múltiple que publica una amplia variedad de formatos de origen en Confluence, desde Google Docs hasta Salesforce Quip, y también en Markdown.
Para publicar, debe colocar el archivo manifest.json en la carpeta donde se encuentran sus archivos .md, especifique la carpeta que contiene, el archivo que desea publicar, para cada archivo especifique la identificación de la página de confluencia. El título de la página será el primer encabezado del archivo (#). Esta herramienta tiene algunas perversiones con el marcado Markdown, así que mira los
muelles . Los archivos adjuntos y las imágenes deben colocarse en la misma carpeta, y la herramienta también le permite especificar el uso de la tabla de contenido directamente en la configuración.
Gema md2conf
Ruby gem
md2conf , convierte Markdown a nativo para Confluence XHTML. Luego puede escribir la tarea Rake, que a su vez se puede llamar a través de Gitlab CI / Jenkins para presionar para dominar, luego extraer la API Confluence para publicar la página. Para no traerle el entorno Ruby, envuelva las dependencias de esta gema en un contenedor.
Aquí se describe cómo enviar solicitudes a la API de Confluence.
Funciona solo con la fuente en Markdown.
De encontrado en Github
De hecho, ya se han realizado varios scripts o herramientas cli en la comunidad, pero solo experimenté con md2conf, todos están divididos en dos grupos.
Aquellos que solo convierten formatos (md, asciidoc, primero -> confluencia / xhtml):El más considerado de ellos que vi es este (https://github.com/rogerwelin/markdown2confluence-server), el autor escribió inmediatamente Dockerfile, que plantea la herramienta cli como un servidor REST, luego puede enviarle un paquete de solicitudes de conversión .
Y aquellos que implementan de inmediato las solicitudes a la API de Confluence , solo necesita especificar la clave API en la configuración:
Elija cualquiera de las opciones (según el lenguaje de marcado y la pila) y recopile su canalización según las tareas que enfrenta.
PD: si comparte en los comentarios otras soluciones encontradas para el problema, le estaré muy agradecido.
Y si quieres hablar más sobre estos temas conmigo, ven a KnowledgeConf 2020 el 18 de mayo.