Esto ni siquiera es una broma, parece que esta imagen en particular refleja con mayor precisión la esencia de estas bases de datos, y al final quedará claro por qué:

Según el ranking DB-Engines, las dos bases de columnas NoSQL más populares son Cassandra (en adelante CS) y HBase (HB).
Por voluntad del destino, nuestro equipo de gestión de carga de datos en Sberbank ha
estado trabajando estrechamente con HB durante
mucho tiempo . Durante este tiempo, estudiamos sus fortalezas y debilidades bastante bien y aprendimos a cocinarlo. Sin embargo, la presencia de una alternativa en forma de CS todo el tiempo me hizo atormentarme con dudas: ¿tomamos la decisión correcta? Además, los resultados de la
comparación llevada a cabo por DataStax dijeron que CS fácilmente derrota a HB con una puntuación casi aplastante. Por otro lado, DataStax es una persona interesada, y no debe decir nada aquí. Además, una cantidad bastante pequeña de información sobre las condiciones de prueba era vergonzosa, por lo que decidimos averiguar por nuestra cuenta quién es el rey de BigData NoSql, y los resultados fueron muy interesantes.
Sin embargo, antes de pasar a los resultados de las pruebas realizadas, es necesario describir los aspectos esenciales de las configuraciones del entorno. El hecho es que CS se puede usar en modo de tolerancia de pérdida de datos. Es decir Esto es cuando solo un servidor (nodo) es responsable de los datos de una determinada clave, y si se cae por alguna razón, el valor de esta clave se perderá. Para muchas tareas esto no es crítico, pero para el sector bancario esta es la excepción más que la regla. En nuestro caso, es importante tener varias copias de datos para un almacenamiento confiable.
Por lo tanto, solo se consideró el modo CS de triple replicación, es decir, La creación de casos se realizó con los siguientes parámetros:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3};
Además, hay dos formas de garantizar el nivel de consistencia requerido. Regla general:
NW + NR> RF
Esto significa que el número de confirmaciones de los nodos al escribir (NW) más el número de confirmaciones de los nodos al leer (NR) debe ser mayor que el factor de replicación. En nuestro caso, RF = 3, por lo que las siguientes opciones son adecuadas:
2 + 2> 3
3 + 1> 3
Dado que es fundamental para nosotros mantener los datos lo más confiables posible, se eligió un esquema 3 + 1. Además, HB funciona de manera similar, es decir Tal comparación sería más honesta.
Cabe señalar que DataStax hizo lo contrario en su investigación, establecieron RF = 1 para CS y HB (para este último al cambiar la configuración de HDFS). Este es un aspecto realmente importante, porque el impacto en el rendimiento de CS en este caso es enorme. Por ejemplo, la siguiente imagen muestra el aumento de tiempo requerido para cargar datos en CS:
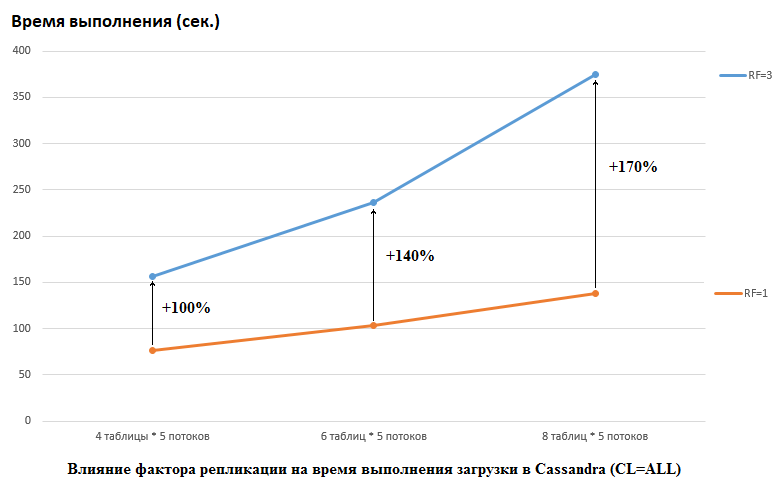
Aquí vemos lo siguiente: mientras más hilos de la competencia escriben datos, más tiempo demora. Esto es natural, pero es importante que la degradación del rendimiento para RF = 3 sea significativamente mayor. En otras palabras, si escribimos en 4 tablas en cada una de las 5 transmisiones (un total de 20), entonces RF = 3 pierde aproximadamente 2 veces (150 segundos RF = 3 frente a 75 para RF = 1). Pero si aumentamos la carga al cargar datos en 8 tablas en cada una de las 5 transmisiones (un total de 40), perder RF = 3 ya es 2,7 veces (375 segundos frente a 138).
Quizás en parte este es el secreto de la prueba exitosa de DataStax para la prueba de carga CS, porque para HB en nuestro stand, cambiar el factor de replicación de 2 a 3 no tuvo ningún efecto. Es decir Los discos no son el cuello de botella para HB para nuestra configuración. Sin embargo, hay muchas otras trampas, porque debe tenerse en cuenta que nuestra versión de HB fue ligeramente parcheada y oscurecida, los entornos son completamente diferentes, etc. También vale la pena señalar que tal vez simplemente no sé cómo preparar CS correctamente y hay algunas formas más efectivas de trabajar con él y espero en los comentarios que descubramos. Pero lo primero es lo primero.
Todas las pruebas se realizaron en un clúster de hierro que consta de 4 servidores, cada uno en una configuración:
CPU: Xeon E5-2680 v4 @ 2.40GHz 64 hilos.
Discos: 12 unidades de disco duro SATA
versión de Java: 1.8.0_111
Versión CS: 3.11.5
Parámetros cassandra.ymlnum_tokens: 256
hinted_handoff_enabled: true
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
directorio_consejos: / data10 / cassandra / consejos
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
autenticador: AllowAllAuthenticator
autorizador: AllowAllAuthorizer
role_manager: CassandraRoleManager
roles_validity_in_ms: 2000
permisos_validez_en_ms: 2000
credentials_validity_in_ms: 2000
particionador: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
- / data1 / cassandra / data # cada directorio dataN es una unidad separada
- / data2 / cassandra / data
- / data3 / cassandra / data
- / data4 / cassandra / data
- / data5 / cassandra / data
- / data6 / cassandra / data
- / data7 / cassandra / data
- / data8 / cassandra / data
commit_directory: / data9 / cassandra / commitlog
cdc_enabled: false
disk_failure_policy: stop
commit_failure_policy: detener
ready_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
directorio_cachés_ guardados: / data10 / cassandra / salva_cachés
commitlog_sync: periódico
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parámetros:
- semillas: "*, *"
concurrent_reads: 256 # intentó 64 - no se notó diferencia
concurrent_writes: 256 # intentó 64 - no se notó ninguna diferencia
concurrent_counter_writes: 256 # intentó 64 - no se notó ninguna diferencia
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # intentó 16 GB - fue más lento
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: false
trickle_fsync_interval_in_kb: 10240
puerto_almacenamiento: 7000
ssl_storage_port: 7001
listen_address: *
broadcast_address: *
listen_on_broadcast_address: verdadero
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: true
native_transport_port: 9042
start_rpc: verdadero
rpc_address: *
rpc_port: 9160
rpc_keepalive: verdadero
rpc_server_type: sincronización
thrift_framed_transport_size_in_mb: 15
incremental_backups: falso
snapshot_before_compaction: false
auto_snapshot: true
column_index_size_in_kb: 64
column_index_cache_size_in_kb: 2
concurrent_compactors: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: falso
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
opciones_encriptación_servidor:
cifrado internode: ninguno
opciones_cifrado_cliente:
habilitado: falso
internode_compression: dc
inter_dc_tcp_nodelay: falso
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
opciones_encriptación_de_datos_transparentes:
habilitado: falso
tombstone_warn_threshold: 1000
Tombstone_failure_threshold: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: false
enable_materialized_views: true
enable_sasi_indexes: true
Configuración de GC:
### Configuración de CMS-XX: + UseParNewGC
-XX: + UseConcMarkSweepGC
-XX: + CMSParallelRemarkEnabled
-XX: SurvivorRatio = 8
-XX: MaxTenuringThreshold = 1
-XX: CMSInitiatingOccupancyFraction = 75
-XX: + UseCMSInitiatingOccupancyOnly
-XX: CMSWaitDuration = 10000
-XX: + CMSParallelInitialMarkEnabled
-XX: + CMSEdenChunksRecordAlways
-XX: + CMSClassUnloadingEnabled
La memoria jvm.options se asignó a 16 Gb (aún se intentó 32 Gb, no se notó ninguna diferencia).
La creación de tablas fue realizada por el comando:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};
Versión HB: 1.2.0-cdh5.14.2 (en la clase org.apache.hadoop.hbase.regionserver.HRegion excluimos MetricsRegion que condujo a GC con más de 1000 regiones en RegionServer)
Opciones de HBase no predeterminadaszookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 minuto (s)
hbase.client.scanner.timeout.period: 2 minuto (s)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 minuto (s)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 hora (s)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 día (s)
Fragmento de configuración avanzada del servicio HBase (válvula de seguridad) para hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Opciones de configuración de Java para HBase RegionServer:
-XX: + UseParNewGC -XX: + UseConcMarkSweepGC -XX: CMSInitiatingOccupancyFraction = 70 -XX: + CMSParallelRemarkEnabled -XX: ReservedCodeCacheSize = 256m
hbase.snapshot.master.timeoutMillis: 2 minuto (s)
hbase.snapshot.region.timeout: 2 minuto (s)
hbase.snapshot.master.timeout.millis: 2 minuto (s)
Tamaño máximo de registro del servidor REST de HBase: 100 MiB
HBase REST Server Máximo de copias de seguridad de archivos de registro: 5
Tamaño máximo de registro del servidor HBase Thrift: 100 MiB
HBase Thrift Server Respaldos máximos de archivos de registro: 5
Tamaño de registro maestro máximo: 100 MiB
Master Máximo de copias de seguridad de archivos de registro: 5
Tamaño de registro máximo de RegionServer: 100 MiB
Registros de archivos de registro máximos de RegionServer: 5
Ventana de detección de maestro activo de HBase: 4 minuto (s)
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 milisegundos (s)
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Descriptores máximos de archivos de proceso: 180,000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Hilos Mover Región: 6
Tamaño de almacenamiento dinámico Java del cliente en bytes: 1 GiB
Grupo predeterminado del servidor REST de HBase: 3 GiB
Grupo predeterminado del servidor HBase Thrift: 3 GiB
Tamaño de almacenamiento dinámico de Java de HBase Master en bytes: 16 GiB
Tamaño de almacenamiento dinámico de Java de HBase RegionServer en bytes: 32 GiB
+ ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Crear tablas:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns: t1 UniformSplit -c 64 -f cf
alter 'ns: t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}Hay un punto importante: la descripción de DataStax no dice cuántas regiones se usaron para crear las tablas HB, aunque esto es crítico para grandes volúmenes. Por lo tanto, para las pruebas, se eligió el número = 64, que permite almacenar hasta 640 GB, es decir, Mesa de tamaño mediano.
En el momento de la prueba, HBase tenía 22 mil tablas y 67 mil regiones (esto sería mortal para la versión 1.2.0, si no fuera por el parche mencionado anteriormente).
Ahora para el código. Como no estaba claro qué configuraciones son más ventajosas para una base de datos particular, las pruebas se llevaron a cabo en varias combinaciones. Es decir En algunas pruebas, la carga fue simultáneamente a 4 tablas (se utilizaron los 4 nodos para la conexión). En otras pruebas, trabajaron con 8 tablas diferentes. En algunos casos, el tamaño del lote era 100, en otros 200 (parámetro del lote - ver el código a continuación). El tamaño de los datos para el valor es de 10 bytes o 100 bytes (tamaño de datos). En total, se escribieron y restaron 5 millones de registros cada vez en cada tabla. Al mismo tiempo, se escribieron / leyeron 5 secuencias en cada tabla (el número de secuencia es thNum), cada una de las cuales utilizó su propio rango de claves (cuenta = 1 millón):
if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("BEGIN BATCH "); for (int i = 0; i < batch; i++) { String value = RandomStringUtils.random(dataSize, true, true); sb.append("INSERT INTO ") .append(tableName) .append("(id, title) ") .append("VALUES (") .append(key) .append(", '") .append(value) .append("');"); key++; } sb.append("APPLY BATCH;"); final String query = sb.toString(); session.execute(query); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN ("); for (int i = 0; i < batch; i++) { sb = sb.append(key); if (i+1 < batch) sb.append(","); key++; } sb = sb.append(");"); final String query = sb.toString(); ResultSet rs = session.execute(query); } }
En consecuencia, se proporcionó una funcionalidad similar para HB:
Configuration conf = getConf(); HTable table = new HTable(conf, keyspace + ":" + tableName); table.setAutoFlush(false, false); List<Get> lGet = new ArrayList<>(); List<Put> lPut = new ArrayList<>(); byte[] cf = Bytes.toBytes("cf"); byte[] qf = Bytes.toBytes("value"); if (opType.equals("insert")) { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lPut.clear(); for (int i = 0; i < batch; i++) { Put p = new Put(makeHbaseRowKey(key)); String value = RandomStringUtils.random(dataSize, true, true); p.addColumn(cf, qf, value.getBytes()); lPut.add(p); key++; } table.put(lPut); table.flushCommits(); } } else { for (Long key = count * thNum; key < count * (thNum + 1); key += 0) { lGet.clear(); for (int i = 0; i < batch; i++) { Get g = new Get(makeHbaseRowKey(key)); lGet.add(g); key++; } Result[] rs = table.get(lGet); } }
Dado que el cliente debe ocuparse de la distribución uniforme de los datos en HB, la función de salazón clave se veía así:
public static byte[] makeHbaseRowKey(long key) { byte[] nonSaltedRowKey = Bytes.toBytes(key); CRC32 crc32 = new CRC32(); crc32.update(nonSaltedRowKey); long crc32Value = crc32.getValue(); byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7); return ArrayUtils.addAll(salt, nonSaltedRowKey); }
Ahora los más interesantes son los resultados:

Lo mismo que un gráfico:
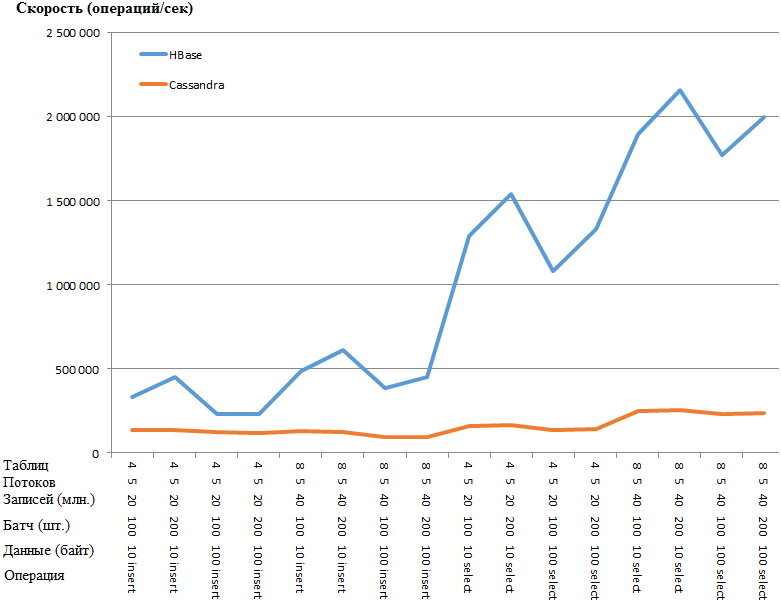
La ventaja de HB es tan sorprendente que existe la sospecha de algún tipo de cuello de botella en la configuración de CS. Sin embargo, la búsqueda en Google y la torsión de los parámetros más obvios (como concurrent_writes o memtable_heap_space_in_mb) no dieron aceleración. Al mismo tiempo, los registros están limpios, no juren por nada.
Los datos se distribuyen de manera uniforme en los nodos, las estadísticas de todos los nodos son aproximadamente las mismas.
Aquí están las estadísticas en la tabla con uno de los nodosKeyspace: ks
Leer cuenta: 9383707
Latencia de lectura: 0.04287025042448576 ms
Cuenta de escritura: 15462012
Latencia de escritura: 0.1350068438699957 ms
Lavados pendientes: 0
Tabla: t1
Cuenta de tabla: 16
Espacio utilizado (en vivo): 148.59 MiB
Espacio utilizado (total): 148.59 MiB
Espacio utilizado por las instantáneas (total): 0 bytes
Memoria de almacenamiento dinámico utilizada (total): 5,17 MiB
Relación de compresión SSTable: 0.5720989576459437
Número de particiones (estimado): 3970323
Recuento celular memorable: 0
Tamaño de datos memorables: 0 bytes
Memoria de almacenamiento dinámico no utilizable: 0 bytes
Recuento de conmutadores memorables: 5
Cuenta de lectura local: 2346045
Latencia de lectura local: NaN ms
Recuento de escritura local: 3865503
Latencia de escritura local: NaN ms
Rubores pendientes: 0
Porcentaje reparado: 0.0
Filtro de Bloom falsos positivos: 25
Relación falsa del filtro Bloom: 0.00000
Espacio de filtro de Bloom utilizado: 4.57 MiB
Bloom filtro de memoria de montón utilizada: 4.57 MiB
Resumen del índice de la memoria del montón utilizada: 590.02 KiB
Metadatos de compresión de la memoria del montón utilizada: 19.45 KiB
Bytes mínimos de partición compactada: 36
Bytes máximos de partición compactada: 42
Bytes medios de partición compactada: 42
Promedio de células vivas por corte (últimos cinco minutos): NaN
Máximo de células vivas por segmento (últimos cinco minutos): 0
Promedio de lápidas por rebanada (últimos cinco minutos): NaN
Lápidas máximas por rebanada (últimos cinco minutos): 0
Mutaciones descartadas: 0 bytes
Un intento de reducir el tamaño del lote (hasta el envío uno por uno) no tuvo efecto, solo empeoró. De hecho, es posible que este sea realmente el máximo rendimiento para CS, ya que los resultados obtenidos en CS son similares a los obtenidos para DataStax: alrededor de cientos de miles de operaciones por segundo. Además, si observa la utilización de los recursos, verá que CS usa mucha más CPU y discos:
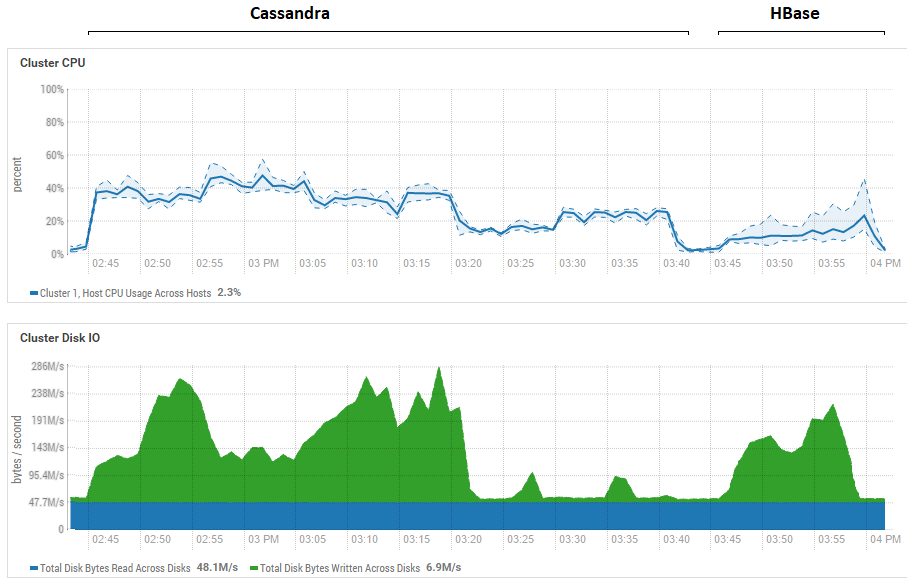 La figura muestra la utilización durante la ejecución de todas las pruebas seguidas para ambas bases de datos.
La figura muestra la utilización durante la ejecución de todas las pruebas seguidas para ambas bases de datos.En cuanto a los poderosos beneficios de lectura de HB. Se puede ver que para ambas bases de datos, la utilización del disco durante la lectura es extremadamente baja (las pruebas de lectura son la parte final del ciclo de prueba para cada base de datos, por ejemplo, para CS de 15:20 a 15:40). En el caso de HB, la razón es clara: la mayoría de los datos se cuelgan en la memoria, en el memstore, y algunos se almacenaron en caché en la caché de bloques. En cuanto a CS, no está muy claro cómo funciona, sin embargo, la utilización del disco tampoco es visible, pero por si acaso, se hizo un intento de activar el caché row_cache_size_in_mb = 2048 y establecer el almacenamiento en caché = {'keys': 'ALL', 'rows_per_partition': ' 2,000,000 '}, pero eso lo empeoró aún más.
También vale una vez más decir un punto significativo sobre el número de regiones en HB. En nuestro caso, se indicó el valor 64. Si lo reduce y lo iguala a, por ejemplo, 4, entonces, al leer, la velocidad se reduce 2 veces. La razón es que memstore se atascará más rápido y los archivos se enjuagarán con más frecuencia y, al leerlo, necesitará procesar más archivos, lo cual es una operación bastante complicada para HB. En condiciones reales, esto puede tratarse pensando en la estrategia de preplit y compactificación, en particular, utilizamos una utilidad de fabricación propia que recolecta basura y comprime HFiles constantemente en segundo plano. Es posible que para las pruebas DataStax, generalmente se asignara 1 región por tabla (lo cual no es correcto) y esto aclararía un poco por qué HB perdió tanto en sus pruebas de lectura.
Las conclusiones preliminares de esto son las siguientes. Asumiendo que no se cometieron errores graves durante las pruebas, Cassandra es como un coloso con pies de arcilla. Más precisamente, mientras se balancea sobre una pierna, como en la imagen al comienzo del artículo, muestra resultados relativamente buenos, pero cuando pelea en las mismas condiciones, pierde directamente. Al mismo tiempo, teniendo en cuenta la baja utilización de la CPU en nuestro hardware, aprendimos a plantar dos HB de RegionServer por host y, por lo tanto, duplicamos la productividad. Es decir Teniendo en cuenta la utilización de recursos, la situación de CS es aún más deplorable.
Por supuesto, estas pruebas son bastante sintéticas y la cantidad de datos que se utilizó aquí es relativamente modesta. Es posible que al cambiar a terabytes, la situación sea diferente, pero si para HB podemos cargar terabytes, entonces para CS esto resultó ser problemático. A menudo arrojó una OperationTimedOutException incluso con estos volúmenes, aunque los parámetros de expectativa de respuesta ya aumentaron varias veces en comparación con los predeterminados.
Espero que mediante esfuerzos conjuntos encontremos los cuellos de botella de CS y si logramos acelerarlo, entonces definitivamente agregaré información sobre los resultados finales al final de la publicación.
UPD: Las siguientes pautas se aplicaron en la configuración de CS:
disk_optimization_strategy: spinning
MAX_HEAP_SIZE = "32G"
HEAP_NEWSIZE = "3200M"
-Xms32G
-Xmx32G
-XX: + UseG1GC
-XX: G1RSetUpdatingPauseTimePercent = 5
-XX: MaxGCPauseMillis = 500
-XX: InitiatingHeapOccupancyPercent = 70
-XX: ParallelGCThreads = 32
-XX: ConcGCThreads = 8En cuanto a la configuración del sistema operativo, este es un procedimiento bastante largo y complicado (obtener root, reiniciar servidores, etc.), por lo que estas recomendaciones no se aplicaron. Por otro lado, ambas bases de datos están en igualdad de condiciones, por lo que todo es justo.
En la parte del código, se crea un conector para todos los hilos que escriben en la tabla:
connector = new CassandraConnector(); connector.connect(node, null, CL); session = connector.getSession(); session.getCluster().getConfiguration().getSocketOptions().setConnectTimeoutMillis(120000); KeyspaceRepository sr = new KeyspaceRepository(session); sr.useKeyspace(keyspace); prepared = session.prepare("insert into " + tableName + " (id, title) values (?, ?)");
Los datos se enviaron por enlace:
for (Long key = count * thNum; key < count * (thNum + 1); key++) { String value = RandomStringUtils.random(dataSize, true, true); session.execute(prepared.bind(key, value)); }
Esto no tuvo un impacto significativo en el rendimiento de grabación. Para mayor fiabilidad, lancé la carga con la herramienta YCSB, absolutamente el mismo resultado. A continuación se muestran las estadísticas para un hilo (de 4):
2020-01-18 14: 41: 53: 180 315 segundos: 10,000,000 operaciones; 21589.1 operaciones actuales / seg; [LIMPIEZA: Cuenta = 100, Máx = 2236415, Mín = 1, Promedio = 22356.39, 90 = 4, 99 = 24, 99.9 = 2236415, 99.99 = 2236415] [INSERTAR: Cuenta = 119551, Máx = 174463, Mín = 273, Promedio = 2582.71, 90 = 3491, 99 = 16767, 99.9 = 99711, 99.99 = 171263]
[GENERAL], RunTime (ms), 315539
[GENERAL], rendimiento (ops / seg), 31691.803548848162
[TOTAL_GCS_PS_Scavenge], Cuenta, 161
[TOTAL_GC_TIME_PS_Scavenge], Tiempo (ms), 2433
[TOTAL_GC_TIME _% _ PS_Scavenge], Tiempo (%), 0.7710615803434757
[TOTAL_GCS_PS_MarkSweep], recuento, 0
[TOTAL_GC_TIME_PS_MarkSweep], Tiempo (ms), 0
[TOTAL_GC_TIME _% _ PS_MarkSweep], Tiempo (%), 0.0
[TOTAL_GCs], recuento, 161
[TOTAL_GC_TIME], tiempo (ms), 2433
[TOTAL_GC_TIME_%], Tiempo (%), 0.7710615803434757
[INSERTAR], Operaciones, 10,000,000
[INSERTAR], Promedio de latencia (us), 3114.2427012
[INSERTAR], MinLatency (nosotros), 269
[INSERTAR], MaxLatency (nosotros), 609279
[INSERTAR], 95thPercentileLatency (us), 5007
[INSERTAR], 99thPercentileLatency (nosotros), 33439
[INSERTAR], Retorno = OK, 10000000
Aquí puede ver que la velocidad de una transmisión es de aproximadamente 32 mil registros por segundo, 4 transmisiones funcionaron, resulta 128 mil. Parece que no hay nada más que exprimir en la configuración actual del subsistema de disco.
Sobre leer más interesante. Gracias al consejo de camaradas, pudo acelerar radicalmente. La lectura se realizó no en 5 secuencias, sino en 100. Un aumento a 200 no produjo un efecto. También agregado al constructor:
.withLoadBalancingPolicy (nuevo TokenAwarePolicy (DCAwareRoundRobinPolicy.builder (). build ()))
Como resultado, si antes la prueba mostraba 159 644 operaciones (5 transmisiones, 4 tablas, 100 lotes), ahora:
100 hilos, 4 tablas, lote = 1 (individualmente): 301969 operaciones
100 hilos, 4 tablas, lote = 10: 447 608 operaciones
100 hilos, 4 tablas, lote = 100: 625 655 operaciones
Como los resultados son mejores con lotes, realicé pruebas similares * con HB:
 * Dado que cuando se trabajaba en 400 subprocesos, la función RandomStringUtils, que se usaba anteriormente, cargaba la CPU en un 100%, fue reemplazada por un generador más rápido.
* Dado que cuando se trabajaba en 400 subprocesos, la función RandomStringUtils, que se usaba anteriormente, cargaba la CPU en un 100%, fue reemplazada por un generador más rápido.Por lo tanto, un aumento en el número de subprocesos al cargar datos da un pequeño aumento en el rendimiento de HB.
En cuanto a la lectura, aquí están los resultados de varias opciones. A pedido de
0x62ash , el comando flush se ejecutó antes de leer, y también se ofrecen otras opciones para comparar:
Memstore: lectura de memoria, es decir antes de enjuagar al disco.
HFile + zip: lectura de archivos comprimidos por el algoritmo GZ.
HFile + upzip: lee archivos sin compresión.
Una característica interesante es notable: los archivos pequeños (consulte el campo "Datos", donde se escriben 10 bytes) se procesan más lentamente, especialmente si están comprimidos. Obviamente, esto solo es posible hasta cierto tamaño, obviamente, un archivo de 5 GB no se procesará más rápido que 10 MB, pero indica claramente que en todas estas pruebas todavía no hay un campo arado para investigar varias configuraciones.
Por interés, corregí el código YCSB para trabajar con lotes HB de 100 piezas para medir la latencia y más. A continuación se muestra el resultado del trabajo de 4 copias que escribieron en sus tablas, cada una con 100 hilos. Resultó lo siguiente:
Una operación = 100 registros[GENERAL], RunTime (ms), 1165415
[GENERAL], Rendimiento (ops / seg), 858.06343662987
[TOTAL_GCS_PS_Scavenge], Cuenta, 798
[TOTAL_GC_TIME_PS_Scavenge], Tiempo (ms), 7346
[TOTAL_GC_TIME _% _ PS_Scavenge], Tiempo (%), 0.6303334005483026
[TOTAL_GCS_PS_MarkSweep], cuenta, 1
[TOTAL_GC_TIME_PS_MarkSweep], Tiempo (ms), 74
[TOTAL_GC_TIME _% _ PS_MarkSweep], Tiempo (%), 0.006349669431061038
[TOTAL_GCs], recuento, 799
[TOTAL_GC_TIME], tiempo (ms), 7420
[TOTAL_GC_TIME_%], Tiempo (%), 0.6366830699793635
[INSERTAR], Operaciones, 1,000,000
[INSERTAR], Latencia promedio (us), 115893.891644
[INSERTAR], MinLatency (nosotros), 14528
[INSERTAR], MaxLatency (nosotros), 1470463
[INSERTAR], 95thPercentileLatency (us), 248319
[INSERTAR], 99thPercentileLatency (nosotros), 445951
[INSERTAR], Retorno = OK, 1,000,000
20/01/19 13:19:16 INFO client.ConnectionManager $ HConnectionImplementation: Closing zookeeper sessionid = 0x36f98ad0a4ad8cc
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Sesión: 0x36f98ad0a4ad8cc cerrado
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread cerrado
[GENERAL], RunTime (ms), 1165806
[GENERAL], Rendimiento (ops / seg), 857.7756504941646
[TOTAL_GCS_PS_Scavenge], Cuenta, 776
[TOTAL_GC_TIME_PS_Scavenge], Tiempo (ms), 7517
[TOTAL_GC_TIME _% _ PS_Scavenge], Tiempo (%), 0.6447899564764635
[TOTAL_GCS_PS_MarkSweep], cuenta, 1
[TOTAL_GC_TIME_PS_MarkSweep], Tiempo (ms), 63
[TOTAL_GC_TIME _% _ PS_MarkSweep], Tiempo (%), 0.005403986598113236
[TOTAL_GCs], cuenta, 777
[TOTAL_GC_TIME], tiempo (ms), 7580
[TOTAL_GC_TIME_%], Tiempo (%), 0.6501939430745767
[INSERTAR], Operaciones, 1,000,000
[INSERTAR], Latencia promedio (EE. UU.), 116042.207936
[INSERTAR], MinLatency (nosotros), 14056
[INSERTAR], MaxLatency (nosotros), 1462271
[INSERTAR], 95thPercentileLatency (us), 250239
[INSERTAR], 99thPercentileLatency (nosotros), 446719
[INSERTAR], Retorno = OK, 1,000,000
20/01/19 13:19:16 INFO client.ConnectionManager $ HConnectionImplementation: Closing zookeeper sessionid = 0x26f98ad07b6d67e
20/01/19 13:19:16 INFO zookeeper.ZooKeeper: Sesión: 0x26f98ad07b6d67e cerrado
20/01/19 13:19:16 INFO zookeeper.ClientCnxn: EventThread cerrado
[GENERAL], RunTime (ms), 1165999
[GENERAL], rendimiento (ops / seg), 857.63366863951
[TOTAL_GCS_PS_Scavenge], recuento, 818
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7557
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6481137633908777
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 79
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.006775305982252128
[TOTAL_GCs], Count, 819
[TOTAL_GC_TIME], Time(ms), 7636
[TOTAL_GC_TIME_%], Time(%), 0.6548890693731299
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116172.212864
[INSERT], MinLatency(us), 7952
[INSERT], MaxLatency(us), 1458175
[INSERT], 95thPercentileLatency(us), 250879
[INSERT], 99thPercentileLatency(us), 446463
[INSERT], Return=OK, 1000000
20/01/19 13:19:17 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x36f98ad0a4ad8cd
20/01/19 13:19:17 INFO zookeeper.ZooKeeper: Session: 0x36f98ad0a4ad8cd closed
20/01/19 13:19:17 INFO zookeeper.ClientCnxn: EventThread shut down
[OVERALL], RunTime(ms), 1166860
[OVERALL], Throughput(ops/sec), 857.000839860823
[TOTAL_GCS_PS_Scavenge], Count, 707
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 7239
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.6203829079752499
[TOTAL_GCS_PS_MarkSweep], Count, 1
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 67
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0057419056270675145
[TOTAL_GCs], Count, 708
[TOTAL_GC_TIME], Time(ms), 7306
[TOTAL_GC_TIME_%], Time(%), 0.6261248136023173
[INSERT], Operations, 1000000
[INSERT], AverageLatency(us), 116230.849308
[INSERT], MinLatency(us), 7352
[INSERT], MaxLatency(us), 1443839
[INSERT], 95thPercentileLatency(us), 250623
[INSERT], 99thPercentileLatency(us), 447487
[INSERT], Return=OK, 1000000
Resulta que si CS AverageLatency (us) tiene un registro de 3114, entonces HB AverageLatency (us) = 1162 (recuerde que 1 operación = 100 registros y, por lo tanto, debe dividirse).En general, se obtiene esta conclusión: bajo condiciones dadas, hay una ventaja significativa de HBase. Sin embargo, no se puede descartar que el SSD y el ajuste cuidadoso del sistema operativo cambien radicalmente la imagen. También debe comprender que mucho depende de los escenarios de uso, puede resultar fácilmente que si no toma 4 tablas, sino 400 y trabaja con terabytes, el equilibrio de fuerzas se desarrollará de una manera completamente diferente. Como decían los clásicos: la práctica es el criterio de la verdad. Tienes que intentarlo. Por un lado, ScyllaDB ahora tiene sentido verificar, por lo que debe continuar ...