Durante mucho tiempo iba a escribir un artículo sobre numba y sobre cómo comparar su velocidad con si. Artículo de Haskell " Más rápido que C ++; más lento que PHP "empujó a la acción. En los comentarios a este artículo, mencionaron la biblioteca numba y que mágicamente puede aproximar la velocidad de ejecución del código en python a la velocidad en s. En este artículo, después de una breve revisión sobre numba (parte 1), un análisis un poco más detallado de esta situación ( parte 2 ).

La principal desventaja de una pitón se considera su velocidad. Python overclocking con un éxito variable comenzó casi desde los primeros días de su existencia: shedskin , psyco , unden shallow , perkeet , theano , nuitka , pythran , cython , pypy , numba .
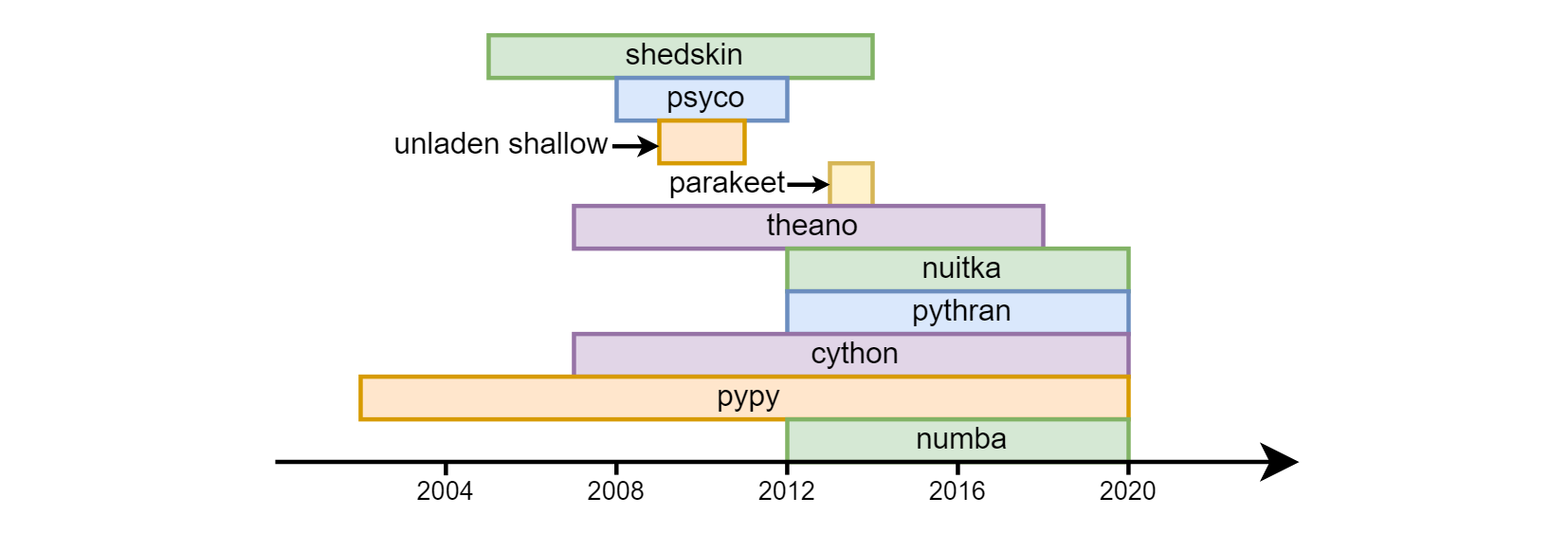
Hasta la fecha, los tres últimos son los más solicitados. Cython (no debe confundirse con cpython): es semánticamente bastante diferente de Python normal. De hecho, este es un lenguaje separado, un híbrido de C y python. En cuanto a pypy (una implementación alternativa del traductor de python usando la compilación numba ) y numba (una biblioteca para compilar código en llvm), fueron de diferentes maneras. pypy inicialmente declaró soporte para todas las construcciones de python. En numba, procedieron del hecho de que la mayoría de las veces requiere cálculos matemáticos vinculados a la CPU, respectivamente, identificaron la parte del lenguaje asociado con los cálculos y comenzaron a overclockearlo, aumentando gradualmente la "cobertura" (por ejemplo, hasta hace poco no había soporte de línea , ahora ella ha aparecido). En consecuencia, no todo el programa está overclockeado en numba , sino funciones separadas , esto le permite combinar alta velocidad y compatibilidad con versiones anteriores con bibliotecas que numba (todavía) no admite. Numpy es compatible (con restricciones menores) tanto en pypy como en numba .
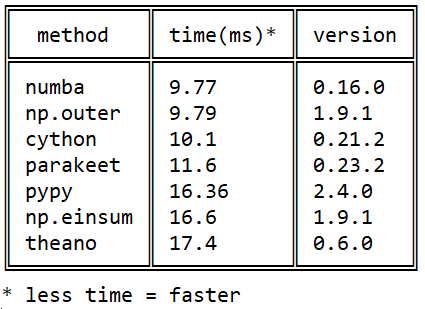 Mi conocimiento de Numba comenzó en 2015 con esta pregunta sobre stackoverflow sobre la velocidad de la multiplicación de matrices en python: producto externo eficiente en python
Mi conocimiento de Numba comenzó en 2015 con esta pregunta sobre stackoverflow sobre la velocidad de la multiplicación de matrices en python: producto externo eficiente en python
Desde entonces, se han producido muchos eventos en cada una de las bibliotecas, pero la imagen con respecto a numba / cython / pypy no pypy cambiado numba : numba supera a cython mediante el uso de instrucciones de procesador nativas ( cython no puede cython ) y pypy debido a una ejecución más eficiente del código de bytes llvm .
Numba es útil para mí en el trabajo (procesamiento de imágenes hiperespectrales) y en la enseñanza (integración numérica, resolución de ecuaciones diferenciales).
como configurar
Hace un par de años hubo problemas con la instalación, ahora todo se resolvió: se instala igualmente bien a través de pip install numba y conda install numba . llvm se aprieta e instala automáticamente.
como acelerar
Para acelerar una función, debe ingresar al decorador njit antes de definirla:
from numba import njit @njit def f(n): s = 0. for i in range(n): s += sqrt(i) return s
Aceleración de 40 veces.
La raíz es necesaria, porque de lo contrario numba reconocerá la suma de la progresión aritmética (!) Y la calculará en tiempo constante.
jit vs njit
Anteriormente, solo el modo @jit (no @njit ) era relevante. El punto es que en este modo puede usar operaciones no compatibles con numba: la numba a alta velocidad alcanza la primera operación, luego se ralentiza y hasta el final de la ejecución de la función continúa a la velocidad habitual de Python, incluso si no se encuentra nada más "prohibido" en la función ( el llamado modo de objeto), que obviamente es irracional. Ahora @jit abandonando gradualmente @jit , siempre se recomienda usar @njit (o en forma completa @jit(nopython=True) ): en este modo, la numba jura con excepciones en esos lugares; es mejor reescribirlos para no perder velocidad.
que puede acelerar
En las funciones overclockeadas, solo se puede usar parte de la funcionalidad de python y numba. Todos los operadores, funciones y clases se dividen en dos partes con respecto a la numba: las que la numba "entiende" y las que "no entiende".
Hay dos listas de este tipo en la documentación de numba (con ejemplos):
- Un subconjunto de la funcionalidad de Python familiar para adormecer y
- Un subconjunto del numpy funcional familiar para adormecer.
De lo notable en estas listas:
- numba "entiende" las listas de Python con adiciones rápidas (O (1)) al final que numpy "no entiende" (aunque solo las homogéneas de elementos del mismo tipo),
- Las matrices de Numpy que no están en la base de Python. Comprende también
- tuplas: pueden, como una pitón normal, contener elementos de diferentes tipos.
- diccionarios: numba tiene su propia implementación de un diccionario escrito. Todas las claves deben ser del mismo tipo, exactamente como los valores. Python dict no se puede pasar a numba, pero numba
numba.typed.Dict se puede crear en python y transferir a / desde numba (mientras que en python funciona un poco más lento que python). - recientemente str y bytes, sin embargo, solo como parámetros de entrada no se pueden crear (¿todavía?).
Ella no entiende ninguna otra biblioteca (en particular, scipy y pandas) en absoluto.
Pero incluso ese subconjunto del lenguaje que entiende es suficiente para overclockear la mayor parte del código para aplicaciones científicas en las que la numba se centra principalmente.
importante!
De las funciones overclockeadas, solo se pueden llamar overclockeadas, no overclockeadas.
(aunque las funciones overclockeadas pueden llamarse desde overclockeadas y no overclockeadas).
globales
En las funciones overclockeadas, las variables globales se convierten en constantes: su valor se fija en el momento en que se compila la función ( ejemplo ). => No utilice variables globales en funciones overclockeadas (excepto para constantes).
firmas
En el número de cada función, se asignan uno o varios tipos de argumentos de entrada y salida, es decir firmas Cuando se llama por primera vez a la función, se genera la firma y el código de función binario correspondiente se compila automáticamente. Cuando se inicia con otros tipos de argumentos, se crearán nuevas firmas y nuevos binarios (se conservan los antiguos). Por lo tanto, se produce la "salida al modo" en términos de velocidad de ejecución para cada firma, comenzando desde la segunda ejecución con este tipo de argumentos. Entonces tampoco
- "Calentar el caché" iniciando con pequeños tamaños de matrices de entrada, o
- especifique el argumento
@jit(cache=True) para guardar el código compilado en el disco con su carga automática durante los siguientes lanzamientos de programas (aunque en la práctica hoy en día este primer lanzamiento sigue siendo un poco más lento que los posteriores, pero más rápido que sin cache=True ) .
Hay una tercera vía. Las firmas se pueden configurar manualmente:
from numba import int16, int32 @njit(int32(int16, int16)) def f(x, y): return x + y >>> f.signatures [(int16, int16)]
Cuando ejecuta una función con la firma especificada en el decorador, la primera ejecución será rápida: la compilación se producirá en el momento en que Python vea la definición de la función, y no en el primer inicio. Puede haber varias firmas, el orden de su secuencia es importante.
Advertencia: este último método no es seguro para el futuro. Los autores de numba advierten que la sintaxis para especificar tipos puede cambiar en el futuro, @jit / @njit sin firmas es una opción más segura a este respecto.
f.signatures comienzan a mostrar firmas solo cuando el pitón se entera de ellas, es decir, después de la primera llamada a la función, o si se configuran manualmente.
Además de f.signatures firmas se pueden ver a través de f.inspect_types() ; además de los tipos de parámetros de entrada, esta función mostrará los tipos de parámetros de salida y los tipos de todas las variables locales.
Además de los tipos de parámetros de entrada y salida, es posible especificar manualmente los tipos de variables locales:
from numba import int16, int32 @njit(int32(int16, int16), locals={'z': int32}) def f(x, y): z = y + 10 return x + z
int
En numba, los enteros no tienen aritmética larga como en python "simple", pero hay tipos estándar de varios anchos desde int8 hasta int64 ( tabla de tipos en la documentación). También hay tipos int_ (así como float_ ), que le dan a la numba la oportunidad de elegir el ancho de campo óptimo (desde su punto de vista).
clases
Generalmente hay soporte para las clases (@jitclass), pero hasta ahora es experimental, por lo que es mejor evitar usarlas por el momento (en este momento, en mi experiencia, es mucho más lento con ellas que sin ellas).
tipos personalizados
Numba admite una cierta alternativa a las clases de matrices estructuradas numpy o, en otras palabras, tipos de letra personalizados. Funcionan a la misma velocidad que las matrices numpy regulares, son un poco más convenientes para indexar (por ejemplo, a['y2'] más legible que a[3] ). Curiosamente, en numba, a diferencia de numpy, se permite un a.y2 más conciso junto con la sintaxis habitual a['y2'] . Pero en general, su apoyo en numba deja mucho que desear, y algunas operaciones, incluso obvias en numpy, con ellos en numba se registran de manera bastante trivial.
GPU
Es capaz de ejecutar código overclockeado en la GPU, y en contraste con el mismo, por ejemplo, pycuda o pytorch, no solo en nvidia, sino también en tarjetas amd'shnyh. Con esto, hasta ahora se ha tratado poco. Aquí hay un artículo sobre la comparación de Habre 2016 del rendimiento de los cálculos de GPU en Python y C. Allí, se obtuvo una velocidad comparable a la de C.
compilación anticipada
Hay un modo de compilación normal (es decir, no jit) ( documentación ) en la numba, pero este modo no es el principal, no lo entendí.
paralelización automática
Algunas tareas (por ejemplo, multiplicar una matriz por un número) están paralelas de forma natural. Pero hay tareas cuya implementación no puede ser paralela. Con el decorador @njit(parallel=True) numba analiza el código de la función overclockeada, encuentra esas secciones, cada una de las cuales no puede ser paralelizada por sí misma, y las ejecuta simultáneamente en diferentes núcleos de CPU ( documentación ). Anteriormente, solo podía paralelizar funciones manualmente usando @vectorize ( documentación ), que requería cambios de código.
En la práctica, se ve así: agregue parallel=True , mida la velocidad, si tenemos suerte y resultó más rápido, lo dejamos, más lento, lo eliminamos. (** Actualización Como se señaló en el comentario a la segunda parte del artículo, esta bandera tiene muchos errores abiertos)
Lanzamiento de GIL
Las funciones decoradas con @jit(nogil=True) y que se ejecutan en diferentes hilos se pueden ejecutar en paralelo. Para evitar condiciones de carrera, debe usar la sincronización de subprocesos.
la documentación
Numbe aún carece de documentación sensata. Ella es, pero no todo está en ella.
optimización
Hay algo de imprevisibilidad al optimizar el código manualmente: el código no pitónico a menudo se ejecuta más rápido que el pitónico.
Para aquellos interesados en el tema, puedo recomendar un video de una clase magistral de numba de la conferencia scipy 2017 (hay códigos fuente en el github). Es realmente largo y parcialmente desactualizado (por ejemplo, las líneas ya son compatibles), pero ayuda a tener una idea general: hay, en particular, acerca de pythonic / unpythonic, jit (paralelo = True), etc.
En la segunda parte, consideraremos el uso de numba usando el código del artículo mencionado al principio del artículo.