¡Hola a todos los que eligieron el camino de ML-Samurai!
Introducción
En este artículo, consideramos el método de máquina de vectores de soporte ( Eng. SVM, Support Vector Machine ) para el problema de clasificación. Se presentará la idea principal del algoritmo, se analizará el resultado de establecer sus pesos y una implementación de bricolaje simple. En el ejemplo de un conjunto de datos Iris Se demostrará el funcionamiento del algoritmo escrito con datos separables / inseparables linealmente en el espacio. R2 y visualización de entrenamiento / pronóstico. Además, se anunciarán los pros y los contras del algoritmo, sus modificaciones.

Figura 1. Foto de código abierto de una flor de iris
El problema a resolver:
Resolveremos el problema de la clasificación binaria (cuando solo hay dos clases). Primero, el algoritmo se entrena en objetos del conjunto de entrenamiento, para el cual las etiquetas de clase se conocen de antemano. Además, el algoritmo ya entrenado predice la etiqueta de clase para cada objeto de la muestra diferida / de prueba. Las etiquetas de clase pueden tomar valores Y = \ {- 1, +1 \}Y = \ {- 1, +1 \} . Objeto - vector con signos N x=(x1,x2,...,xn) en el espacio Rn . Al aprender, el algoritmo debe construir una función F(x)=y que toma un argumento x - un objeto del espacio Rn y le da la etiqueta de clase y .
Palabras generales sobre el algoritmo:
La tarea de clasificación se relaciona con la enseñanza con un maestro. SVM es un algoritmo de aprendizaje con un profesor. Visualmente, se pueden encontrar muchos algoritmos de aprendizaje automático en este artículo de primer nivel (consulte la sección "Mapa del mundo del aprendizaje automático"). Cabe agregar que SVM también se puede usar para problemas de regresión, pero el clasificador SVM se analizará en este artículo.
El objetivo principal de SVM como clasificador es encontrar la ecuación de un hiperplano de separación
w1x1+w2x2+...+wnxn+w0=0 en el espacio Rn , que dividiría las dos clases de una manera óptima. Vista general de la transformación. F facilidad x a la etiqueta de clase Y : F(x)=signo(wTx−b) . Recordaremos que hemos designado w=(w1,w2,...,wn),b=−w0 . Después de configurar los pesos del algoritmo w y b (entrenamiento), todos los objetos que caen en un lado del hiperplano construido se predecirán como la primera clase, y los objetos que caen en el otro lado, la segunda clase.
Función interior signo() Existe una combinación lineal de características del objeto con los pesos del algoritmo, por lo que SVM se refiere a algoritmos lineales. Un hiperplano divisor se puede construir de diferentes maneras, pero en pesos SVM w y b están configurados para que los objetos de clase se encuentren lo más lejos posible del hiperplano de separación. En otras palabras, el algoritmo maximiza la brecha ( margen inglés ) entre el hiperplano y los objetos de clase que están más cerca de él. Dichos objetos se denominan vectores de soporte (ver Fig. 2). De ahí el nombre del algoritmo.

Figura 2. SVM (la base de la figura de aquí )
Una salida detallada de las reglas de ajuste de escala SVM:
Para mantener el hiperplano divisor lo más lejos posible de los puntos de muestra, el ancho de la tira debe ser máximo. Vector w Es el vector director del hiperplano divisor. En lo sucesivo, denotamos el producto escalar de dos vectores como langlea,b rangle o aTb . Busquemos la proyección del vector cuyos extremos serán los vectores de soporte de diferentes clases en el vector de dirección del hiperplano. Esta proyección mostrará el ancho de la tira divisoria (ver Fig. 3):

Figura 3. La salida de las reglas para establecer las escalas (la base de la figura de aquí )
langle(x+−x−),w/ Arrowvertw Arrowvert rangle=( langlex+,w rangle− langlex−,w rangle)/ Arrowvertw Arrowvert=((b+1)−(b−1))/ Arrowvertw Arrowvert=2/ Arrowvertw Arrowvert
2/ Arrowvertw Arrowvert rightarrowmax
Arrowvertw Arrowvert rightarrowmin
(wTw)/2 rightarrowmin
El margen del objeto x desde el límite de la clase es el valor M=y(wTx−b) . El algoritmo comete un error en el objeto si y solo si la sangría M negativo (cuando y y (wTx−b) diferentes personajes) Si M∈(0,1) , entonces el objeto cae dentro de la franja divisoria. Si M>1 , entonces el objeto x se clasifica correctamente y se encuentra a cierta distancia de la franja divisoria. Anotamos esta conexión:
y(wTx−b) geqslant1
El sistema resultante es la configuración SVM predeterminada con SVM de margen duro , cuando no se permite que ningún objeto ingrese a la banda de separación. Se resuelve analíticamente a través del teorema de Kuhn-Tucker. El problema resultante es equivalente al problema dual de encontrar el punto de silla de la función Lagrange.
$$ display $$ \ left \ {\ begin {array} {ll} (w ^ Tw) / 2 \ rightarrow min & \ textrm {} \\ y (w ^ Tx-b) \ geqslant 1 & \ textrm {} \ end {array} \ right. $$ display $$
Todo esto es bueno siempre y cuando nuestras clases sean linealmente separables. Para que el algoritmo pueda funcionar con datos inseparables linealmente, transformemos un poco nuestro sistema. Deje que el algoritmo cometa errores en los objetos de entrenamiento, pero al mismo tiempo trate de mantener menos errores. Introducimos un conjunto de variables adicionales. xii>0 caracterizando la magnitud del error en cada objeto xi . Introducimos una penalización por el error total en el funcional minimizado:
$$ display $$ \ left \ {\ begin {array} {ll} (w ^ Tw) / 2 + \ alpha \ sum \ xi _i \ rightarrow min & \ textrm {} \\ y (w ^ Tx_i-b) \ geqslant 1 - \ xi _i & \ textrm {} \\ \ xi _i \ geqslant0 & \ textrm {} \ end {array} \ right. $$ display $$
Consideraremos el número de errores de algoritmo (cuando M <0). Llámalo pena . Entonces la penalización para todos los objetos será igual a la cantidad de multas para cada objeto. xi donde [Mi<0] - función umbral (ver Fig. 4):
Penalización= sum[Mi<0]
$$ display $$ [M_i <0] = \ left \ {\ begin {array} {ll} 1 & \ textrm {if} M_i <0 \\ 0 & \ textrm {if} M_i \ geqslant 0 \ end {array} \ right. $$ display $$
A continuación, hacemos que la penalización sea sensible a la magnitud del error y al mismo tiempo introducimos una penalización por acercar el objeto al límite de la clase:
Penalización= sum[Mi<0] leqslant sum(1−Mi)+= summax(0,1−Mi)
Al agregar a la expresión de penalización el término alpha(wTw)/2 obtenemos la clásica función de pérdida de SVM con espacio libre ( SVM de margen suave ) para un objeto:
Q=max(0,1−Mi)+ alpha(wTw)/2
Q=max(0,1−ywTx)+ alpha(wTw)/2
Q - función de pérdida, también es una función de pérdida. Eso es lo que minimizaremos con la ayuda del descenso de gradiente en la implementación de las manos. Derivamos las reglas para cambiar los pesos, donde eta - paso de descenso:
w=w− eta bigtriangledownQ
$$ display $$ \ bigtriangledown Q = \ left \ {\ begin {array} {ll} \ alpha w-yx & \ textrm {if} yw ^ Tx <1 \\ \ alpha w & \ textrm {if} yw ^ Tx \ geqslant 1 \ end {array} \ right. $$ display $$
Posibles preguntas en las entrevistas (basadas en hechos reales):
Después de preguntas generales sobre SVM: ¿Por qué Hinge_loss maximiza el espacio libre? - Primero, recuerde que un hiperplano cambia su posición cuando cambian los pesos w y b . Los pesos del algoritmo comienzan a cambiar cuando los gradientes de la función de pérdida no son iguales a cero (por lo general dicen: "flujo de gradientes"). Por lo tanto, seleccionamos especialmente dicha función de pérdida, en la que los gradientes comienzan a fluir en el momento adecuado. Pérdidadebisagra se ve así: H=max(0,1−y(wTx)) . Recuerda que la autorización m=y(wTx) . Cuando la brecha m lo suficientemente grande ( 1 o más) expresión (1m) se vuelve menor que cero y H=0 (por lo tanto, los gradientes no fluyen y el peso del algoritmo no cambia de ninguna manera). Si la brecha m es suficientemente pequeña (por ejemplo, cuando un objeto cae en la banda de separación y / o negativo (si el pronóstico de clasificación es incorrecto), Hinge_loss se vuelve positivo ( H>0 ), los gradientes comienzan a fluir y los pesos del algoritmo cambian. Resumiendo: los gradientes fluyen en dos casos: cuando el objeto de muestra cayó dentro de la banda de separación y cuando el objeto está clasificado incorrectamente.
Para verificar el nivel de un idioma extranjero, son posibles preguntas similares: ¿Cuáles son las similitudes y diferencias entre LogisticRegression y SVM? - En primer lugar, hablaremos de similitudes: ambos algoritmos son algoritmos de clasificación lineal en el aprendizaje supervisado. Algunas similitudes están en sus argumentos de las funciones de pérdida: log(1+exp(−y(wTx))) para logreg y max(0,1−y(wTx)) para SVM (mira la imagen 4). Ambos algoritmos podemos configurarlos usando el descenso de gradiente. A continuación, hablemos de las diferencias: la etiqueta de clase de devolución SVM del objeto a diferencia de LogReg, que devuelve la probabilidad de pertenencia a la clase. SVM no puede funcionar con etiquetas de clase \ {0,1 \}\ {0,1 \} (sin renombrar clases) a diferencia de LogReg (FinReg pérdida de pérdida para \ {0,1 \}\ {0,1 \} : −ylog(p)−(1−y)log(1−p) donde y - etiqueta de clase real, p - retorno del algoritmo, probabilidad de pertenecer al objeto x a clase \ {1 \}\ {1 \} ) Más que eso, podemos resolver el problema SVM de margen duro sin descenso de gradiente. La tarea de buscar vectores de soporte se reduce al punto de silla de búsqueda en la función Lagrange; esta tarea se refiere únicamente a la programación cuadrática.
Código de la función de pérdida:import numpy as np import matplotlib.pyplot as plt %matplotlib inline xx = np.linspace(-4,3,100000) plt.plot(xx, [(x<0).astype(int) for x in xx], linewidth=2, label='1 if M<0, else 0') plt.plot(xx, [np.log2(1+2.76**(-x)) for x in xx], linewidth=4, label='logistic = log(1+e^-M)') plt.plot(xx, [np.max(np.array([0,1-x])) for x in xx], linewidth=4, label='hinge = max(0,1-M)') plt.title('Loss = F(Margin)') plt.grid() plt.legend(prop={'size': 14});

Figura 4. Funciones de pérdida
Implementación simple de SVM clásico de margen blando:
Atencion Encontrará un enlace al código completo al final del artículo. A continuación hay bloques de código sacados de contexto. Algunos bloques solo pueden iniciarse después de resolver los bloques anteriores. Debajo de muchos bloques, se colocarán imágenes que muestran cómo funciona el código colocado encima.
Primero, recortaremos las bibliotecas necesarias y la función de dibujo de línea: import numpy as np import warnings warnings.filterwarnings('ignore') import matplotlib.pyplot as plt import matplotlib.lines as mlines plt.rcParams['figure.figsize'] = (8,6) %matplotlib inline from sklearn.datasets import load_iris from sklearn.decomposition import PCA from sklearn.model_selection import train_test_split def newline(p1, p2, color=None):
Código de implementación de Python para SVM de margen suave: def add_bias_feature(a): a_extended = np.zeros((a.shape[0],a.shape[1]+1)) a_extended[:,:-1] = a a_extended[:,-1] = int(1) return a_extended class CustomSVM(object): __class__ = "CustomSVM" __doc__ = """ This is an implementation of the SVM classification algorithm Note that it works only for binary classification ############################################################# ###################### PARAMETERS ###################### ############################################################# etha: float(default - 0.01) Learning rate, gradient step alpha: float, (default - 0.1) Regularization parameter in 0.5*alpha*||w||^2 epochs: int, (default - 200) Number of epochs of training ############################################################# ############################################################# ############################################################# """ def __init__(self, etha=0.01, alpha=0.1, epochs=200): self._epochs = epochs self._etha = etha self._alpha = alpha self._w = None self.history_w = [] self.train_errors = None self.val_errors = None self.train_loss = None self.val_loss = None def fit(self, X_train, Y_train, X_val, Y_val, verbose=False):
Consideramos en detalle el funcionamiento de cada bloque de líneas:
1) cree una función add_bias_feature (a) , que extiende automáticamente el vector de objetos, agregando el número 1 al final de cada vector, esto es necesario para "olvidarse" del término libre b. Expresión wTx−b equivalente a la expresión w1x1+w2x2+...+wnxn+w0∗1 . Suponemos condicionalmente que la unidad es el último componente del vector para todos los vectores x, y w0=−b . Ahora configurando los pesos w y w0 Produciremos al mismo tiempo.
Código de función de extensión de vector de característica: def add_bias_feature(a): a_extended = np.zeros((a.shape[0],a.shape[1]+1)) a_extended[:,:-1] = a a_extended[:,-1] = int(1) return a_extended
2) luego describiremos el clasificador mismo. Tiene las funciones de inicializar init () , aprender fit () , predecir predic () , encontrar la pérdida de la función hinge_loss () y encontrar la pérdida total de la función del algoritmo clásico con un espacio suave soft_margin_loss () .
3) tras la inicialización, se introducen 3 hiperparámetros: _etha - paso de descenso de gradiente ( eta ), _alpha - coeficiente de velocidad de reducción de peso proporcional (antes del término cuadrático en la función de pérdida alpha ), _epochs - el número de eras de entrenamiento.
Código de función de inicialización: def __init__(self, etha=0.01, alpha=0.1, epochs=200): self._epochs = epochs self._etha = etha self._alpha = alpha self._w = None self.history_w = [] self.train_errors = None self.val_errors = None self.train_loss = None self.val_loss = None
4) durante el entrenamiento para cada era de la muestra de entrenamiento (X_train, Y_train) tomaremos un elemento de la muestra, calcularemos el espacio entre este elemento y la posición del hiperplano en un momento dado. Además, dependiendo del tamaño de esta brecha, cambiaremos el peso del algoritmo usando el gradiente de la función de pérdida Q . Al mismo tiempo, calcularemos el valor de esta función para cada época y cuántas veces cambiamos los pesos por época. Antes de comenzar la capacitación, nos aseguraremos de que no hayan entrado realmente más de dos etiquetas de clase diferentes en la función de aprendizaje. Antes de configurar la balanza, se inicializa utilizando la distribución normal.
Código de función de aprendizaje: def fit(self, X_train, Y_train, X_val, Y_val, verbose=False):
Comprobación del funcionamiento del algoritmo escrito:
Verifique que nuestro algoritmo escrito funcione en algún tipo de conjunto de datos de juguetes. Tome el conjunto de datos de Iris. Nosotros prepararemos los datos. Denote las clases 1 y 2 como +1 y clase 0 como −1 . Usando el algoritmo PCA (explicación y aplicación aquí ), reducimos de manera óptima el espacio de 4 atributos a 2 con una pérdida mínima de datos (nos será más fácil observar el entrenamiento y el resultado). A continuación, nos dividiremos en una muestra de capacitación (entrenamiento) y una demorada (validación). Vamos a entrenar en la muestra de entrenamiento, predecir y verificar el diferido. Elegimos los factores de aprendizaje para que disminuya la función de pérdida. Durante el entrenamiento, veremos la función de pérdida del entrenamiento y el muestreo retrasado.
Bloque de preparación de datos: Unidad de inicialización y formación: 
El bloque de visualización de la tira divisoria resultante: d = {-1:'green', 1:'red'} plt.scatter(X_train[:,0], X_train[:,1], c=[d[y] for y in Y_train]) newline([0,-svm._w[2]/svm._w[1]],[-svm._w[2]/svm._w[0],0], 'blue')

Bloque de visualización de pronóstico: 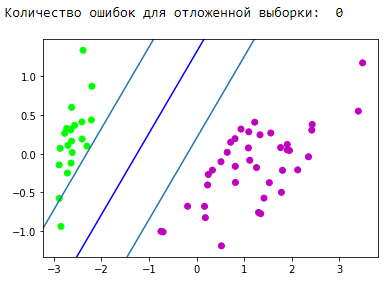
Genial Nuestro algoritmo maneja datos linealmente separables. Ahora separe las clases 0 y 1 de la clase 2:
Bloque de preparación de datos: Unidad de inicialización y formación: 
El bloque de visualización de la tira divisoria resultante: d = {-1:'green', 1:'red'} plt.scatter(X_train[:,0], X_train[:,1], c=[d[y] for y in Y_train]) newline([0,-svm._w[2]/svm._w[1]],[-svm._w[2]/svm._w[0],0], 'blue')
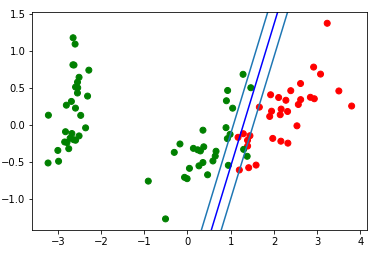
Veamos el gif, que mostrará cómo la línea divisoria cambió su posición durante el entrenamiento (solo 500 cuadros para cambiar de peso. Los primeros 300 seguidos. Las siguientes 200 piezas por cada 130 cuadros):
Código de creación de animación: import matplotlib.animation as animation from matplotlib.animation import PillowWriter def one_image(w, X, Y): axes = plt.gca() axes.set_xlim([-4,4]) axes.set_ylim([-1.5,1.5]) d1 = {-1:'green', 1:'red'} im = plt.scatter(X[:,0], X[:,1], c=[d1[y] for y in Y]) im = newline([0,-w[2]/w[1]],[-w[2]/w[0],0], 'blue')

Bloque de visualización de pronóstico: 
Enderezar espacios
Es importante comprender que en problemas reales no habrá un caso simple con datos separables linealmente. Para trabajar con dichos datos, se propuso la idea de moverse a otro espacio, donde los datos serán linealmente separables. Tal espacio se llama rectificador. La rectificación de espacios y núcleos no se verá afectada en este artículo. Puede encontrar la teoría matemática más completa en la sinopsis 14,15,16 de E. Sokolov y en las conferencias de K.V. Vorontsov .
Usando SVM desde sklearn:
De hecho, casi todos los algoritmos clásicos de aprendizaje automático están escritos para usted. Pongamos un ejemplo del código, tomaremos el algoritmo de la biblioteca sklearn .
Ejemplo de código from sklearn import svm from sklearn.metrics import recall_score C = 1.0
Pros y contras de SVM clásico:
Pros:
- funciona bien con grandes espacios de características;
- funciona bien con datos pequeños;
- Por lo tanto, el algoritmo encuentra maximiza la banda divisoria, que, como un airbag, puede reducir la cantidad de errores de clasificación;
- dado que el algoritmo se reduce a resolver el problema de programación cuadrática en un dominio convexo, dicho problema siempre tiene una solución única (el hiperplano de separación con ciertos hiperparámetros del algoritmo es siempre el mismo).
Contras:
- largo tiempo de entrenamiento (para grandes conjuntos de datos);
- inestabilidad del ruido: los valores atípicos en los datos de entrenamiento se convierten en objetos intrusos de referencia y afectan directamente la construcción de un hiperplano de separación;
- no se describen métodos generales para construir núcleos y rectificar espacios que sean más adecuados para un problema particular en el caso de la separabilidad lineal de clases. Seleccionar transformaciones de datos útiles es un arte.
Aplicación SVM:
La elección de uno u otro algoritmo de aprendizaje automático depende directamente de la información obtenida durante la extracción de datos. Pero en términos generales, se pueden distinguir las siguientes tareas:
- tareas con un pequeño conjunto de datos;
- tareas de clasificación de texto. SVM proporciona una buena línea de base ([preprocesamiento] + [TF-iDF] + [SVM]), la precisión del pronóstico resultante está al nivel de algunas redes neuronales convolucionales / recurrentes (recomiendo probar este método usted mismo para consolidar el material). Aquí se da un excelente ejemplo , "Parte 3. Un ejemplo de uno de los trucos que enseñamos" ;
- para muchas tareas con datos estructurados, el enlace [ingeniería de características] + [SVM] + [kernel] "todavía está lleno";
- Dado que la pérdida de la bisagra se considera bastante rápida, se puede encontrar en Vowpal Wabbit (por defecto).
Modificaciones de algoritmos:
Hay varias adiciones y modificaciones al método de vector de soporte, destinadas a eliminar ciertas desventajas:
- Máquina de vectores de relevancia (RVM)
- SVM de 1 norma (LASSO SVM)
- SVM doblemente regularizado (SVM ElasticNet)
- Máquina de características de soporte (SFM)
- Máquina de características de relevancia (RFM)
Fuentes adicionales en SVM:
- Conferencias de texto por K.V. Vorontsov
- Resúmenes de E. Sokolov - 14.15.16
- Fuente genial de Alexandre Kowalczyk
- En un habr hay 2 artículos dedicados a svm:
- En el github, puedo resaltar 2 implementaciones SVM geniales en los siguientes enlaces:
Conclusión
¡Muchas gracias por su atención! Agradecería cualquier comentario, retroalimentación y consejos.
Encontrará el código completo de este artículo en mi github .
ps Gracias yorko por consejos sobre suavizar esquinas. Gracias a Aleksey Sizykh, un departamento de física y tecnología que invirtió parcialmente en código.