
Más recientemente, hablamos sobre cómo implementar aplicaciones escritas en el cartucho de Tarantool . Pero la operación no termina en la implementación, por lo que hoy actualizaremos nuestra aplicación y entenderemos cómo administrar la topología, la división y la autorización, así como cambiar la configuración de roles.
Inquisitivo por favor corte!
Donde paramos
La última vez configuramos la siguiente topología:
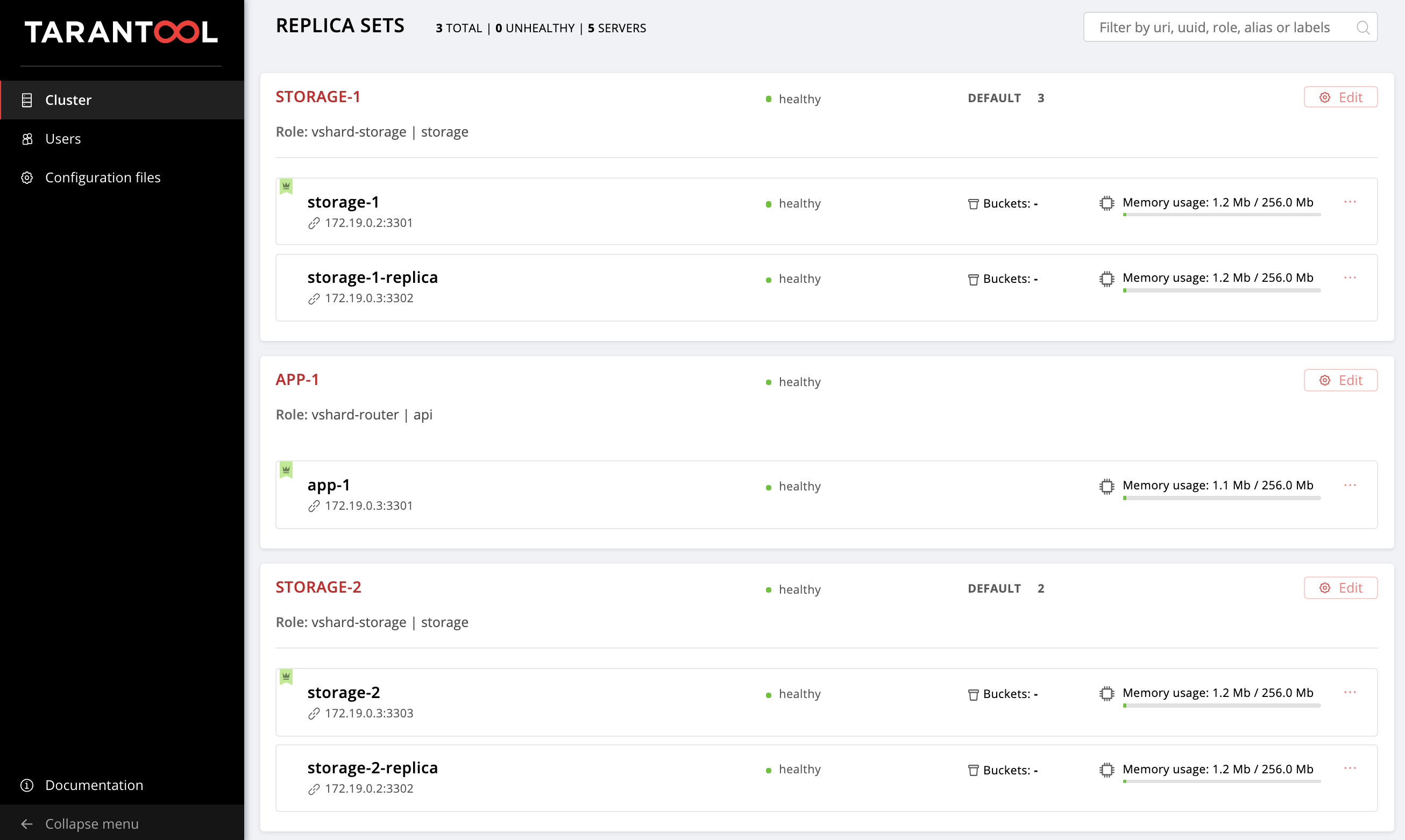
El repositorio de ejemplo logró cambiar un poco, aparecieron nuevos archivos allí, getting-started-app-2.0.0-0.rpm y hosts.updated.2.yml . No tiene que extraer la nueva versión, solo puede descargar el paquete desde el enlace , y hosts.updated.2.yml solo hosts.updated.2.yml necesario para que pueda mirar allí en caso de dificultades con el cambio del inventario actual.
Si ha completado todos los pasos de la parte anterior de este tutorial, ahora en su hosts.yml hosts.yml hay una configuración de clúster con dos réplicas de storage (en el repositorio esto es hosts.updated.yml ).
Eleva nuestras máquinas virtuales:
$ vagrant up
Instale la nueva versión del cartucho de Tarantool de rol Ansible (se las arregló para cambiar, por supuesto, para mejor):
$ ansible-galaxy install tarantool.cartridge,1.0.2
Entonces, la configuración actual del clúster:
--- all: vars: # common cluster variables cartridge_app_name: getting-started-app cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package cartridge_cluster_cookie: app-default-cookie # cluster cookie # common ssh options ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no' # INSTANCES hosts: storage-1: config: advertise_uri: '172.19.0.2:3301' http_port: 8181 app-1: config: advertise_uri: '172.19.0.3:3301' http_port: 8182 storage-1-replica: config: advertise_uri: '172.19.0.3:3302' http_port: 8183 storage-2: config: advertise_uri: '172.19.0.3:3303' http_port: 8184 storage-2-replica: config: advertise_uri: '172.19.0.2:3302' http_port: 8185 children: # GROUP INSTANCES BY MACHINES host1: vars: # first machine connection options ansible_host: 172.19.0.2 ansible_user: vagrant hosts: # instances to be started on the first machine storage-1: storage-2-replica: host2: vars: # second machine connection options ansible_host: 172.19.0.3 ansible_user: vagrant hosts: # instances to be started on the second machine app-1: storage-1-replica: storage-2: # GROUP INSTANCES BY REPLICA SETS replicaset_app_1: vars: # replica set configuration replicaset_alias: app-1 failover_priority: - app-1 # leader roles: - 'api' hosts: # replica set instances app-1: replicaset_storage_1: vars: # replica set configuration replicaset_alias: storage-1 weight: 3 failover_priority: - storage-1 # leader - storage-1-replica roles: - 'storage' hosts: # replica set instances storage-1: storage-1-replica: replicaset_storage_2: vars: # replicaset configuration replicaset_alias: storage-2 weight: 2 failover_priority: - storage-2 - storage-2-replica roles: - 'storage' hosts: # replicaset instances storage-2: storage-2-replica:
Vaya a http: // localhost: 8181 / admin / cluster / dashboard y asegúrese de que su clúster esté en el estado correcto.
Todo es igual que la última vez: cambiaremos gradualmente este archivo y observaremos cómo cambia el clúster. Siempre puede ver la versión final en hosts.updated.2.yml
¡Así que aquí vamos!
Actualizando la aplicación
Para comenzar, vamos a actualizar nuestra aplicación. Asegúrese de tener el archivo getting-started-app-2.0.0-0.rpm en el directorio actual (si no, descárguelo del repositorio).
Especifique la ruta a la nueva versión del paquete:
--- all: vars: cartridge_app_name: getting-started-app cartridge_package_path: ./getting-started-app-2.0.0-0.rpm # <== cartridge_enable_tarantool_repo: false # <==
Especificamos cartridge_enable_tarantool_repo: false para que el rol no conecte el repositorio con el paquete Tarantool, que ya instalamos la última vez. Esto acelerará ligeramente el proceso de implementación, pero no es absolutamente necesario.
Inicie el libro de jugadas con la etiqueta de cartridge-instances :
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-instances
Y comprobamos que el paquete ha sido actualizado:
$ vagrant ssh vm1 [vagrant@svm1 ~]$ sudo yum list installed | grep getting-started-app
Verifique que la versión se haya convertido en 2.0.0 :
getting-started-app.x86_64 2.0.0-0 installed
Ahora puede experimentar con seguridad con la nueva versión de la aplicación.
Activar fragmentación
Activemos el fragmentación para que podamos tomar el control de storage réplicas de storage más adelante. Esto se hace de manera muy simple. Agregue la variable cartridge_bootstrap_vshard sección all.vars :
--- all: vars: ... cartridge_cluster_cookie: app-default-cookie # cluster cookie cartridge_bootstrap_vshard: true # <== ... hosts: ... children: ...
Lanzamos:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Tenga en cuenta que especificamos la etiqueta de cartridge-config para ejecutar solo las tareas que están involucradas en la configuración del clúster.
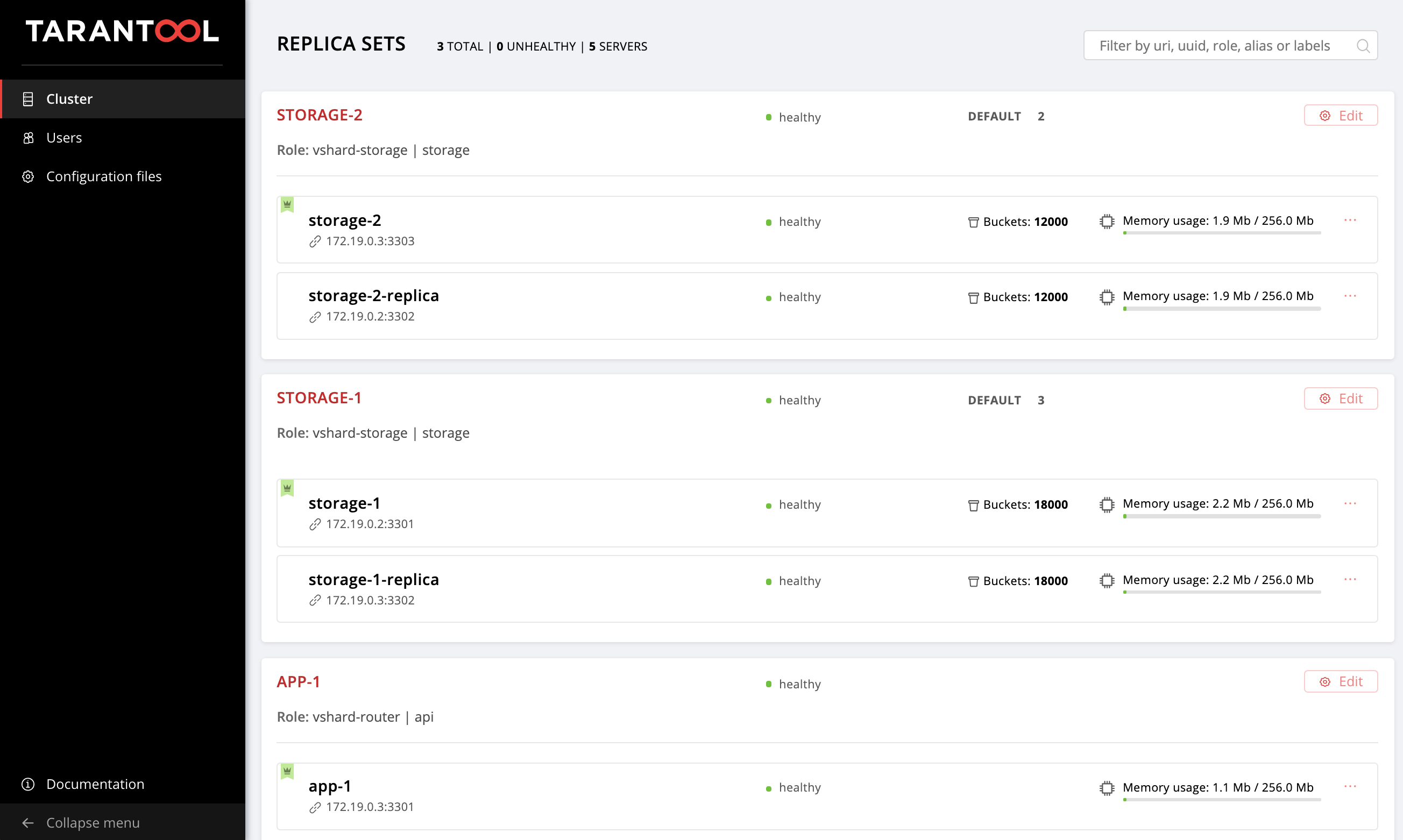
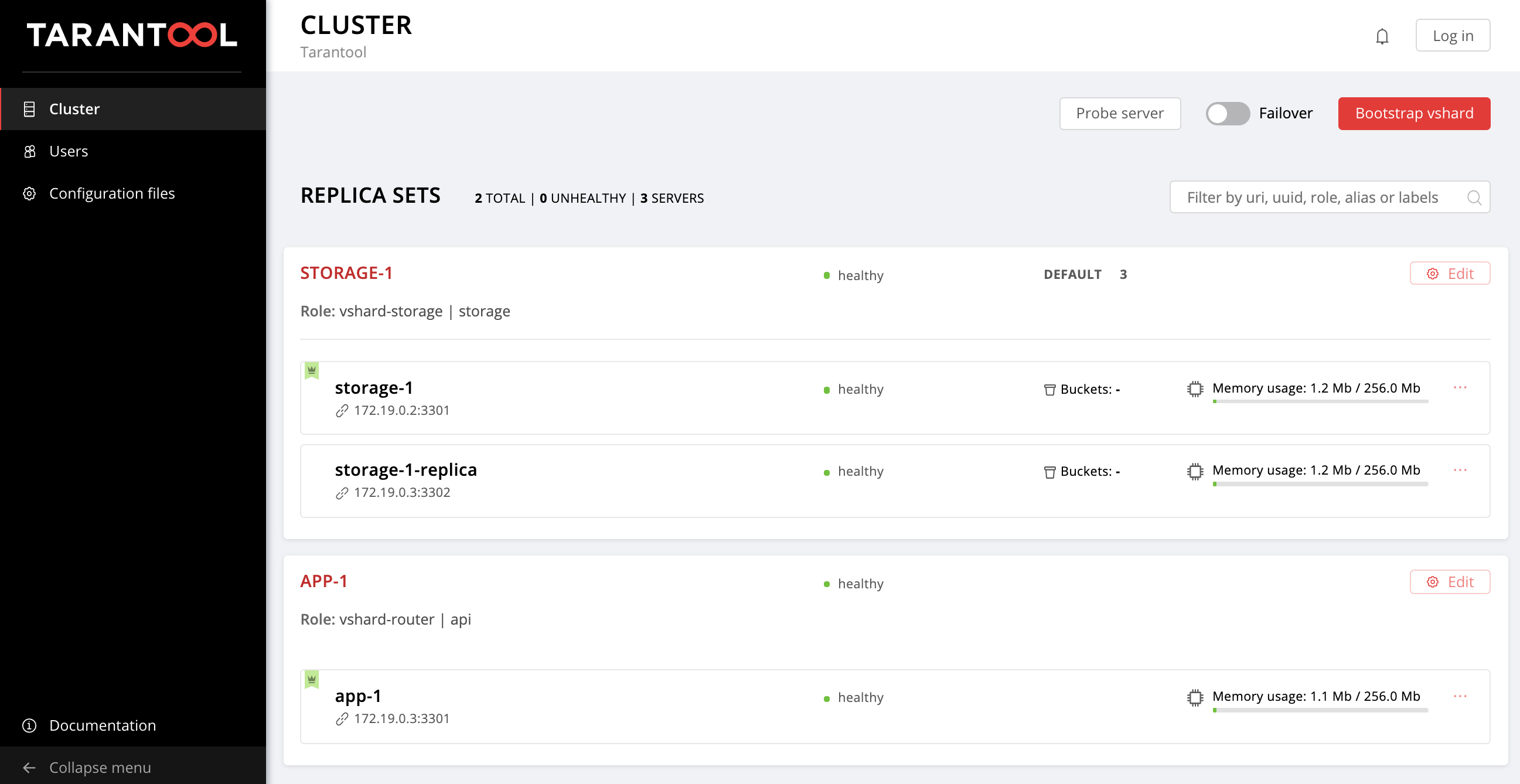
Abra la interfaz de usuario web http: // localhost: 8181 / admin / cluster / dashboard y vea que nuestros depósitos se distribuyen a través de conjuntos de réplica de almacenamiento en una proporción de 2:3 (especificamos dichos pesos para nuestros conjuntos de réplica, ¿recuerda?):
Active la conmutación por error automática
Y ahora activaremos el modo de conmutación por error automática para que podamos descubrir qué es y cómo funciona un poco más tarde.
Agregue el indicador de cartridge_failover a la configuración:
--- all: vars: ... cartridge_cluster_cookie: app-default-cookie # cluster cookie cartridge_bootstrap_vshard: true cartridge_failover: true # <== ... hosts: ... children: ...
Nuevamente comenzamos las tareas de administración del clúster:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Después de completar con éxito el libro de jugadas, puede ir a la interfaz de usuario web y asegurarse de que el interruptor de Failover en la esquina superior derecha esté activado. Para desactivar el modo de conmutación por error automática, simplemente cambie el valor de cartridge_failover a false y vuelva a ejecutar el libro de jugadas.
Es hora de averiguar qué tipo de régimen es este y por qué lo activamos.
Nos ocupamos de la conmutación por error
Probablemente haya notado la variable failover_priority que especificamos para cada conjunto de réplicas. Veamos de qué se trata.
El cartucho de Tarantool proporciona un modo de conmutación por error automático. Cada conjunto de réplicas tiene un líder, la instancia en la que se está grabando. Si algo le sucede al líder, uno de los comentarios tomará su papel. Cual? Echemos un vistazo más de cerca al conjunto de réplicas storage-2 :
--- all: ... children: ... replicaset_storage_2: vars: ... failover_priority: - storage-2 - storage-2-replica
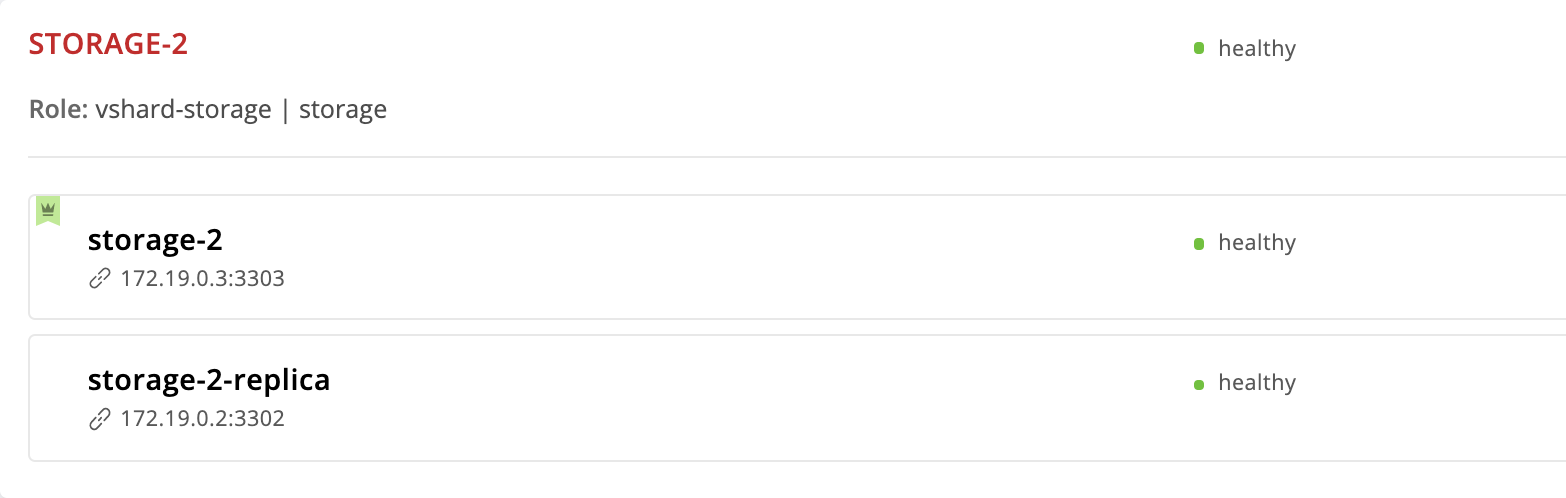
La instancia de storage-2 que especificamos primero en failover_priority . En la interfaz de usuario web, aparece primero en la lista de instancias de conjunto de réplicas y está marcado con una corona verde. Este es el líder: la primera instancia especificada en failover_priority :
Ahora veamos qué sucede si algo le sucede al líder del conjunto de réplicas. Entramos en la máquina virtual y detenemos la instancia de storage-2 :
$ vagrant ssh vm2 [vagrant@vm2 ~]$ sudo systemctl stop getting-started-app@storage-2
Volver a la interfaz de usuario web:

La corona en la instancia de storage-2 volvió roja; esto significa que el líder designado no es saludable. Pero la storage-2-replica tiene una corona verde: esta instancia asumió las responsabilidades de liderazgo hasta que el storage-2 regrese al servicio. Esta es una conmutación por error automática en acción.
Revivamos el storage-2 :
$ vagrant ssh vm2 [vagrant@vm2 ~]$ sudo systemctl start getting-started-app@storage-2
Todo volvió al punto de partida:
Cambiemos el orden de las instancias en la prioridad de la conmutación por error. Haremos que la instancia de storage-2-replica líder, y eliminaremos el storage-2 de la lista en general:
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration ... failover_priority: - storage-2-replica # <== ...
Ejecute cartridge-replicasets para instancias desde el grupo replicaset_storage_2 :
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Vamos a http: // localhost: 8181 / admin / cluster / dashboard y vemos que el líder ha cambiado:
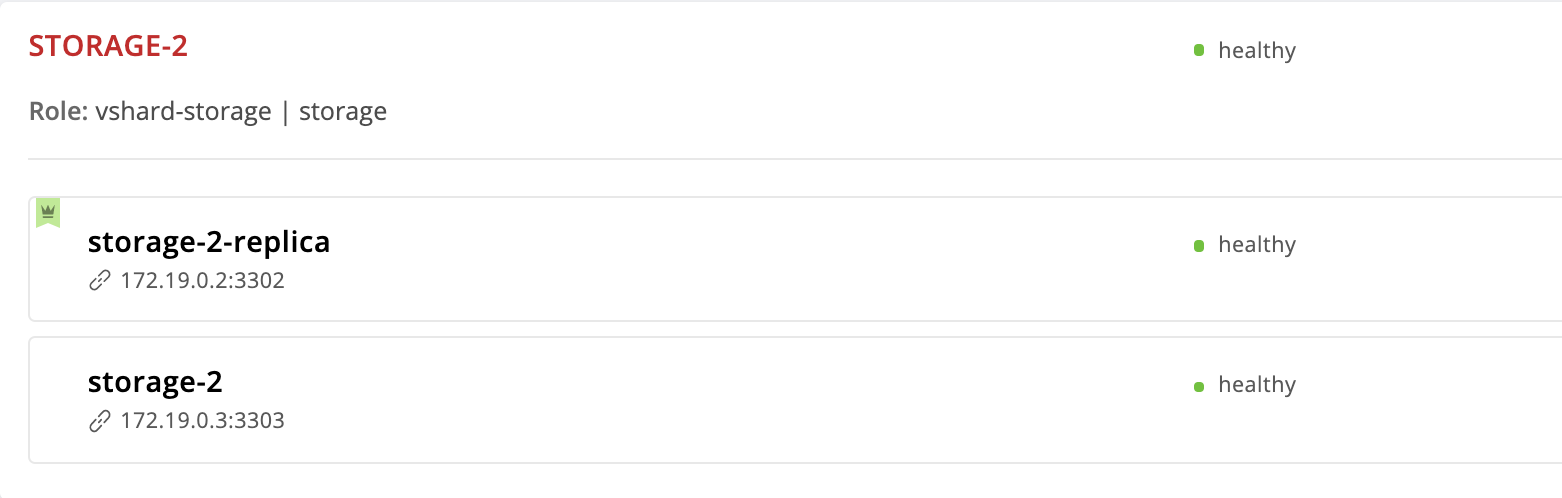
Pero eliminamos la instancia de storage-2 de la configuración, ¿por qué todavía está aquí? El hecho es que Cartridge, al recibir un nuevo valor de failover_priority organiza las instancias de la siguiente manera: la primera instancia de la lista se convierte en líder, el resto de las instancias indicadas siguen. Las instancias no mencionadas en failover_priority se ordenarán por UUID y se agregarán al final.
Instancia de exilio
Pero, ¿qué sucede si queremos excluir la instancia de la topología? Todo es muy simple: debes pasarle la bandera expelled . Excluyamos la instancia de storage-2-replica . Él es el líder ahora, por lo que Cartridge no nos permitirá hacer esto. Pero no tenemos miedo a las dificultades, y aún intentamos:
--- all: vars: ... hosts: storage-2-replica: config: advertise_uri: '172.19.0.2:3302' http_port: 8185 expelled: true # <== ...
Especificamos la cartridge-replicasets , ya que expulsar una instancia es un cambio de topología:
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Ejecute el libro de jugadas y vea el error:

Como acabamos de ver, Cartridge no justifica arrojar al líder actual del conjunto de réplicas fuera de la topología. Esto es bastante lógico, ya que la replicación es asíncrona, la exclusión de un líder puede conducir a la pérdida de datos. Necesitamos especificar otro líder y solo después de eso excluir la instancia. El rol primero aplicará la nueva configuración del conjunto de réplicas y luego se ocupará de la excepción. Por lo tanto, cambiamos failover_priority y ejecutamos nuevamente el libro de jugadas:
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration ... failover_priority: - storage-2 # <== ...
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
¡Voila, la instancia de storage-2-replica ha desaparecido de la topología!

Tenga en cuenta que el exilio de la instancia es verdaderamente final e irrevocable. Después de eliminar la instancia de la topología, nuestra función ansible detendrá el servicio systemd y eliminará todos los archivos de esta instancia.

Si de repente cambia de opinión y decide que el conjunto storage-2 réplicas storage-2 todavía necesita una segunda instancia, no podrá restaurarlo. Cartridge recuerda el UUID de todas las instancias que han abandonado la topología y no permitirá que el exilio regrese. Puede generar una nueva instancia con el mismo nombre y configuración, pero obviamente tendrá un UUID diferente, por lo que Cartridge le permitirá unirse.
Eliminando Replicaset
Ya hemos descubierto que no se nos permitirá expulsar al líder del conjunto de réplicas. Pero, ¿qué pasa si queremos eliminar el replicaet de storage-2 forma permanente? Hay, por supuesto, una salida.
Para no perder datos, primero debemos transferir todos los storage-1 al storage-1 , para esto establecemos el peso del réplica de storage-2 a 0 :
--- all: vars: ... hosts: ... children: ... replicaset_storage_2: vars: # replicaset configuration replicaset_alias: storage-2 weight: 0 # <== ... ...
Lanzamiento de gestión de topología:
$ ansible-playbook -i hosts.yml playbook.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets
Abra la interfaz de usuario web http: // localhost: 8181 / admin / cluster / dashboard y observe cómo fluyen todos los storage-1 en el storage-1 :

Configuramos el líder de storage-2 a la bandera expulsada y nos despedimos de este conjunto de réplicas:
--- all: vars: ... hosts: ... storage-2: config: advertise_uri: '172.19.0.3:3303' http_port: 8184 expelled: true # <== ...
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-replicasets
Tenga en cuenta que esta vez no especificamos la opción de limit , ya que al menos una instancia de todas para las cuales lanzamos el libro de jugadas no debe marcarse como expelled .
Entonces volvimos a la topología original:
Iniciar sesión
Propongo distraerme de la gestión de conjuntos de réplicas y pensar en la seguridad. Ahora, cualquier usuario no autorizado puede administrar el clúster a través de la interfaz de usuario web. De acuerdo, parece más o menos.
Cartridge brinda la capacidad de conectar su propio módulo de autorización, como LDAP (o lo que sea que tenga allí), y usarlo para administrar usuarios y su acceso a la aplicación. Pero usaremos el módulo de autorización incorporado, que Cartridge usa de manera predeterminada. Este módulo le permite realizar operaciones básicas con los usuarios (eliminar, agregar, editar) e implementa la función de verificación de contraseña.
Tenga en cuenta que nuestra función ansible requiere la autorización del backend para implementar todas estas funciones.
Entonces, pasamos de la teoría a la práctica. Primero, haga que la autorización sea obligatoria, configure los parámetros de la sesión y agregue un nuevo usuario:
--- all: vars: ... # authorization cartridge_auth: # <== enabled: true # enable authorization cookie_max_age: 1000 cookie_renew_age: 100 users: # cartridge users to set up - username: dokshina password: cartridge-rullez fullname: Elizaveta Dokshina email: dokshina@example.com # deleted: true # uncomment to delete user ...
La gestión de autorización se realiza como parte de las tareas de cartridge-config , indicamos esta etiqueta:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
En http: // localhost: 8181 / admin / cluster / dashboard nos espera una sorpresa:
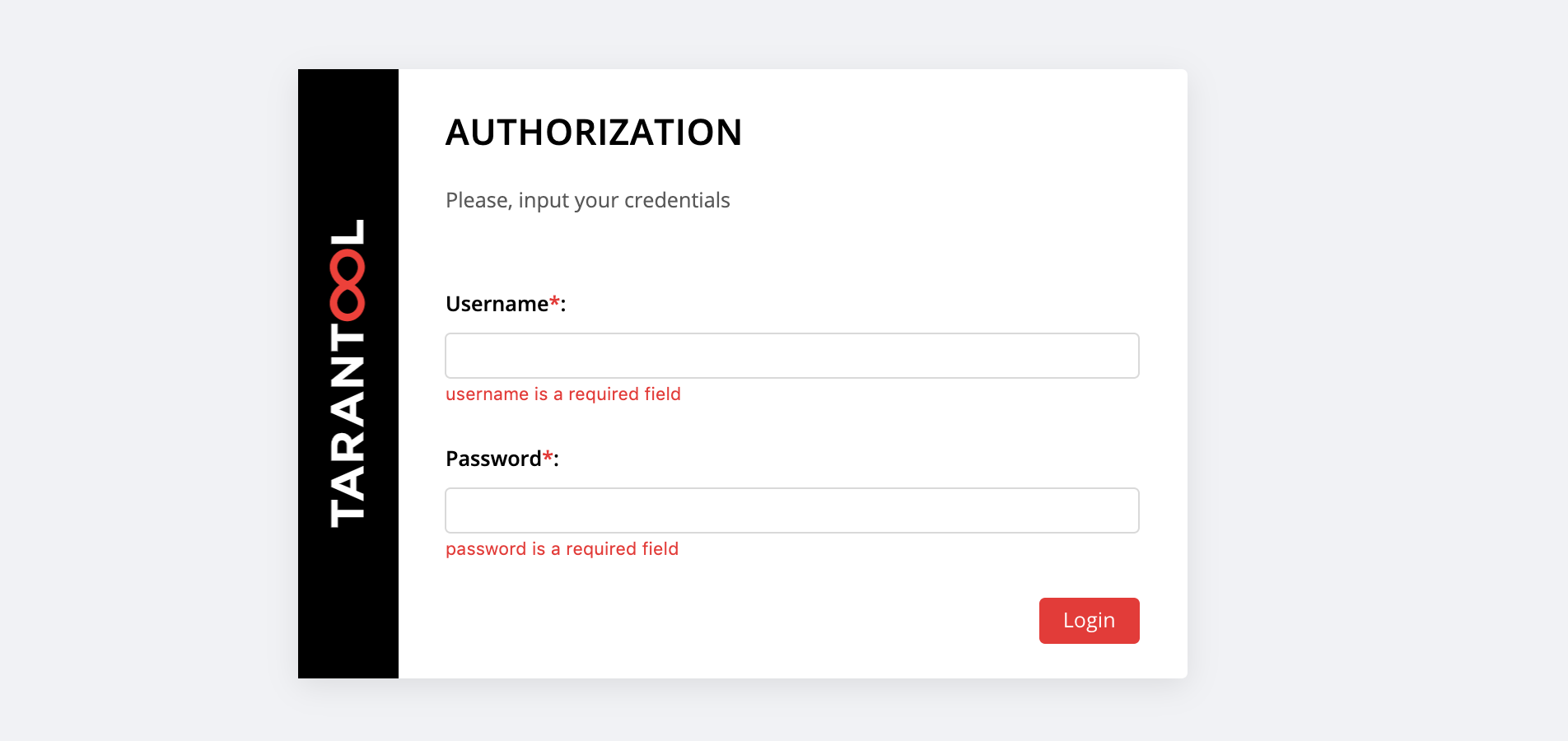
Puede iniciar sesión con el username y la password nuestro nuevo usuario o iniciar sesión como admin , el usuario predeterminado. Su contraseña es cookie de clúster, especificamos este valor en la variable cartridge_cluster_cookie (esta es app-default-cookie , no puede mirar).
Después de un inicio de sesión exitoso, abra la pestaña Users para asegurarse de que todo salió bien:

Experimente agregando nuevos usuarios y cambiando su configuración. Para eliminar un usuario, especifique el indicador deleted: true para él. Cartridge no utiliza los valores de email y nombre fullname ninguna manera, pero puede especificarlos por conveniencia.
Configuración de la aplicación
Recordemos cómo comenzó todo.
Hemos implementado una pequeña aplicación que almacena datos sobre clientes y sus cuentas bancarias. Como recordará, esta aplicación tiene 2 roles: api y storage . El rol de storage maneja el almacenamiento de datos e implementa el fragmentado utilizando el rol vshard-storage . El segundo rol, api , implementa un servidor HTTP con una API para la gestión de datos, además, dentro está conectado otro rol estándar, vshard-router , que controla el fragmentación.
Entonces, hacemos la primera solicitud a la API de la aplicación. Agregar un nuevo cliente:
$ curl -X POST -H "Content-Type: application/json" \ -d '{"customer_id":1, "name":"Elizaveta", "accounts":[{"account_id": 1}]}' \ http://localhost:8182/storage/customers/create
En respuesta, obtenemos algo como esto:
{"info":"Successfully created"}
Tenga en cuenta que en la URL especificamos el puerto de instancia app-1 , 8082 , porque implementa esta API.
Ahora vamos a actualizar el saldo de nuestro nuevo usuario:
$ curl -X POST -H "Content-Type: application/json" \ -d "{\"account_id\": 1, \"amount\": \"1000\"}" \ http://localhost:8182/storage/customers/1/update_balance
En la respuesta vemos el saldo actualizado:
{"balance":"1000.00"}
¡Genial, todo funciona! La API está implementada, Cartridge se dedica a compartir datos, ya hemos configurado la prioridad de conmutación por error para casos de emergencia e incluso hemos habilitado la autorización. Es hora de hacer la configuración de la aplicación.
La configuración actual del clúster se almacena en un archivo de configuración distribuido. Cada instancia mantiene una copia de este archivo, y Cartridge asegura su sincronización entre todos los nodos del clúster. Podemos especificar la configuración de los roles de nuestra aplicación en este archivo, y Cartridge se encargará de distribuir la nueva configuración en todas las instancias.
Veamos el contenido actual de este archivo. Vaya a la Cofiguration files y haga clic en el botón Download :

En el config.yml config.yml descargado config.yml encontramos una tabla vacía. No es de extrañar, porque todavía no hemos especificado ningún parámetro:
--- [] ...
De hecho, el archivo de configuración de nuestro clúster no está vacío, almacena la topología actual, la configuración de autorización y la configuración de fragmentación. Pero Cartridge no será tan fácil compartir esta información, está destinada para uso interno y, por lo tanto, está almacenada en secciones ocultas del sistema, que no podemos editar.
Cada rol de aplicación puede usar una o más secciones de configuración. La descarga de una nueva configuración ocurre en dos etapas: primero, todos los roles verifican que están listos para aceptar nuevos parámetros. Si no hay objeción, se aplican los cambios, si alguien está en contra, se produce una reversión.
Volvamos a nuestra aplicación. La función de api utiliza la sección de max-balance , donde el saldo máximo permitido se almacena en una cuenta de cliente. Configuremos esta sección, pero, por supuesto, no de forma manual, sino con nuestro rol Ansible.
Entonces, ahora la configuración de la aplicación (o más bien, parte de ella disponible para nosotros) es una tabla vacía. Agregue una sección de max-balance con un valor de 100000 . Escribimos la variable cartridge_app_config en nuestro archivo de inventario:
--- all: vars: ... # cluster-wide config cartridge_app_config: # <== max-balance: # section name body: 1000000 # section body # deleted: true # uncomment to delete section max-balance ...
Especificamos el nombre de la sección, max-balance , y su contenido, body . El contenido de una sección puede ser no solo un número, también puede ser una tabla o una fila, dependiendo de cómo se escriba el rol y qué tipo de valor desee usar.
Lanzamos:
$ ansible-playbook -i hosts.yml playbook.yml \ --tags cartridge-config
Y comprobamos que el saldo máximo permitido realmente ha cambiado:
$ curl -X POST -H "Content-Type: application/json" \ -d "{\"account_id\": 1, \"amount\": \"1000001\"}" \ http://localhost:8182/storage/customers/1/update_balance
En respuesta, recibimos un error, como queríamos:
{"info":"Error","error":"Maximum is 1000000"}
Puede volver a descargar el archivo de configuración en la pestaña Configuraion files para asegurarse de que aparezca una nueva sección allí:
--- max-balance: 1000000 ...
Intente agregar nuevas secciones a la configuración de la aplicación, cambie su contenido o elimínelas por completo (para esto debe establecer el indicador deleted: true en la sección).
Puede encontrar cómo usar una configuración distribuida en roles en la documentación del cartucho de Tarantool.
Recuerde llamar al vagrant halt para detener las vagrant halt cuando termine de trabajar con ellas.
En conclusión
La última vez, aprendimos cómo implementar aplicaciones distribuidas de cartuchos de Tarantool usando un rol especial de Ansible. Hoy actualizamos la aplicación y también dominamos la administración de la topología, el fragmentación, la autorización y la configuración de la aplicación.
No se detenga allí, aprenda diferentes enfoques para escribir libros de jugadas Ansible y use sus aplicaciones con la máxima comodidad.
Si algo no funciona para usted o si tiene ideas sobre cómo mejorar nuestro papel responsable, no dude en comenzar un boleto . ¡Siempre le ayudaremos a resolver su problema y estaremos encantados de recibir ofertas interesantes!