Para dominar completamente Kubernetes, debe conocer las diversas formas de escalar los recursos del clúster: según
los desarrolladores del sistema , esta es una de las principales tareas de Kubernetes. Hemos preparado una revisión de alto nivel de los mecanismos de autoescalado horizontal y vertical y el cambio de tamaño de los clústeres, así como recomendaciones sobre cómo usarlos de manera efectiva.
Un artículo de
Kubernetes Autoscaling 101: Cluster Autoscaler, Horizontal Autoscaler y Vertical Pod Autoscaler fue traducido por un equipo que implementó el
autoescalado en
Kubernetes aaS de Mail.ru.Por qué es importante pensar en escalar
Kubernetes es una herramienta de gestión de recursos y orquestación. Por supuesto, es bueno jugar con funciones geniales de implementación, monitoreo y administración de pod (el módulo pod es un grupo de contenedores que se lanzan en respuesta a una solicitud).
Sin embargo, debe pensar en estos problemas:
- ¿Cómo escalar módulos y aplicaciones?
- ¿Cómo mantener los contenedores operativos y eficientes?
- ¿Cómo responder a los cambios constantes en el código y las cargas de trabajo de los usuarios?
La configuración de clústeres de Kubernetes para equilibrar los recursos y el rendimiento puede ser un desafío; requiere un conocimiento experto de los componentes internos de Kubernetes. La carga de trabajo en su aplicación o servicios puede fluctuar durante el día o incluso una hora, por lo que el equilibrio se representa mejor como un proceso continuo.
Niveles de autoescala de Kubernetes
El autoescalado efectivo requiere coordinación entre dos niveles:
- Nivel de pod, incluyendo horizontal (Horizontal Pod Autoscaler, HPA) y vertical auto-scaling (Vertical Pod Autoscaler, VPA). Esto está escalando los recursos disponibles para sus contenedores.
- El nivel de clúster, que es controlado por Cluster Autoscaler, CA, aumenta o disminuye el número de nodos dentro del clúster.
Módulo de escala automática horizontal (HPA)
Como su nombre indica, HPA escala el número de réplicas de pod. Como desencadenante para cambiar el número de réplicas, la mayoría de los devops usan CPU y carga de memoria. Sin embargo, puede escalar el sistema en función de
métricas personalizadas , su
combinación o incluso
métricas externas .
Flujo de trabajo HPA de alto nivel:
- HPA verifica continuamente los valores métricos especificados durante la instalación con un intervalo predeterminado de 30 segundos.
- HPA intenta aumentar el número de módulos si se alcanza el umbral especificado.
- HPA actualiza el número de réplicas dentro del controlador de implementación / replicación.
- El controlador de implementación / replicación luego implementa todos los módulos complementarios necesarios.
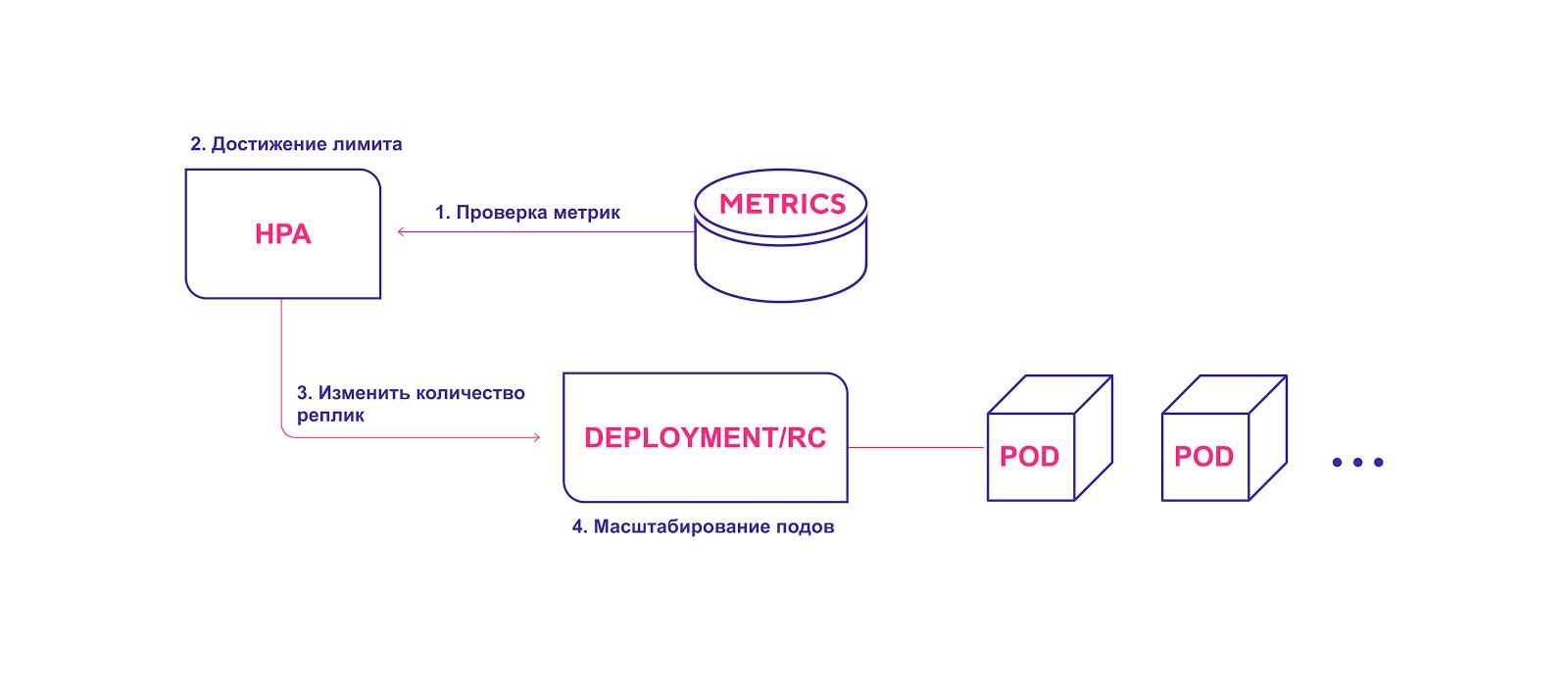 HPA inicia el proceso de implementación del módulo cuando se alcanza el umbral de métricas
HPA inicia el proceso de implementación del módulo cuando se alcanza el umbral de métricasCuando use HPA, considere lo siguiente:
- El intervalo de validación de HPA predeterminado es de 30 segundos. Se configura con el indicador horizontal-pod-autoscaler-sync-period en el administrador del controlador.
- El error relativo predeterminado es 10%.
- Después del último aumento en el número de módulos, HPA espera que las métricas se estabilicen en tres minutos. Este intervalo se establece mediante el indicador horizontal-pod-autoscaler-upscale-delay .
- Después de la última reducción en el número de módulos, el HPA espera estabilizarse durante cinco minutos. Este intervalo se establece mediante el indicador horizontal-pod-autoscaler-downscale-delay .
- HPA funciona mejor con objetos de implementación, no con controladores de replicación. El escalado automático horizontal no es compatible con las actualizaciones continuas, que manipulan directamente los controladores de replicación. Al implementar, el número de réplicas depende directamente de los objetos de implementación.
Autoescalado vertical de vainas
La escala automática vertical (VPA) asigna más (o menos) tiempo de procesador o memoria a los pods existentes. Es adecuado para cápsulas con o sin estado sin estado, pero está destinado principalmente a servicios con estado. Sin embargo, puede aplicar VPA para módulos sin estado si necesita ajustar automáticamente la cantidad de recursos asignados originalmente.
VPA también responde a eventos OOM (sin memoria, sin memoria). Para cambiar el tiempo del procesador y el tamaño de la memoria, se requieren reinicios de pod. Al reiniciar, el VPA respeta el
presupuesto de distribución de pods (PDB ) para garantizar el número mínimo de módulos.
Puede establecer la cantidad mínima y máxima de recursos para cada módulo. Por lo tanto, puede limitar la cantidad máxima de memoria asignada a un límite de 8 GB. Esto es útil si los nodos actuales simplemente no pueden asignar más de 8 GB de memoria por contenedor. Las especificaciones detalladas y los mecanismos operativos se describen en el
wiki oficial de VPA .
Además, VPA tiene una función de recomendación interesante (VPA Recomender). Rastrea la utilización de recursos y los eventos OOM de todos los módulos para ofrecer nuevos valores de memoria y tiempo de procesador basados en un algoritmo inteligente que tenga en cuenta las métricas históricas. También hay una API que toma un descriptor de pod y devuelve los valores de recursos propuestos.
Vale la pena señalar que el Recomendador de VPA no monitorea el "límite" de los recursos. Esto puede hacer que el módulo monopolice los recursos dentro de los nodos. Es mejor establecer un valor límite en el nivel del espacio de nombres para evitar una gran pérdida de memoria o tiempo de procesador.
Esquema de alto nivel de VPA:
- El VPA verifica continuamente los valores métricos especificados durante la instalación con un intervalo predeterminado de 10 segundos.
- Si se alcanza el umbral especificado, el VPA intenta cambiar la cantidad asignada de recursos.
- VPA actualiza la cantidad de recursos dentro del controlador de implementación / replicación.
- Cuando reinicia los módulos, todos los recursos nuevos se aplican a las instancias creadas.
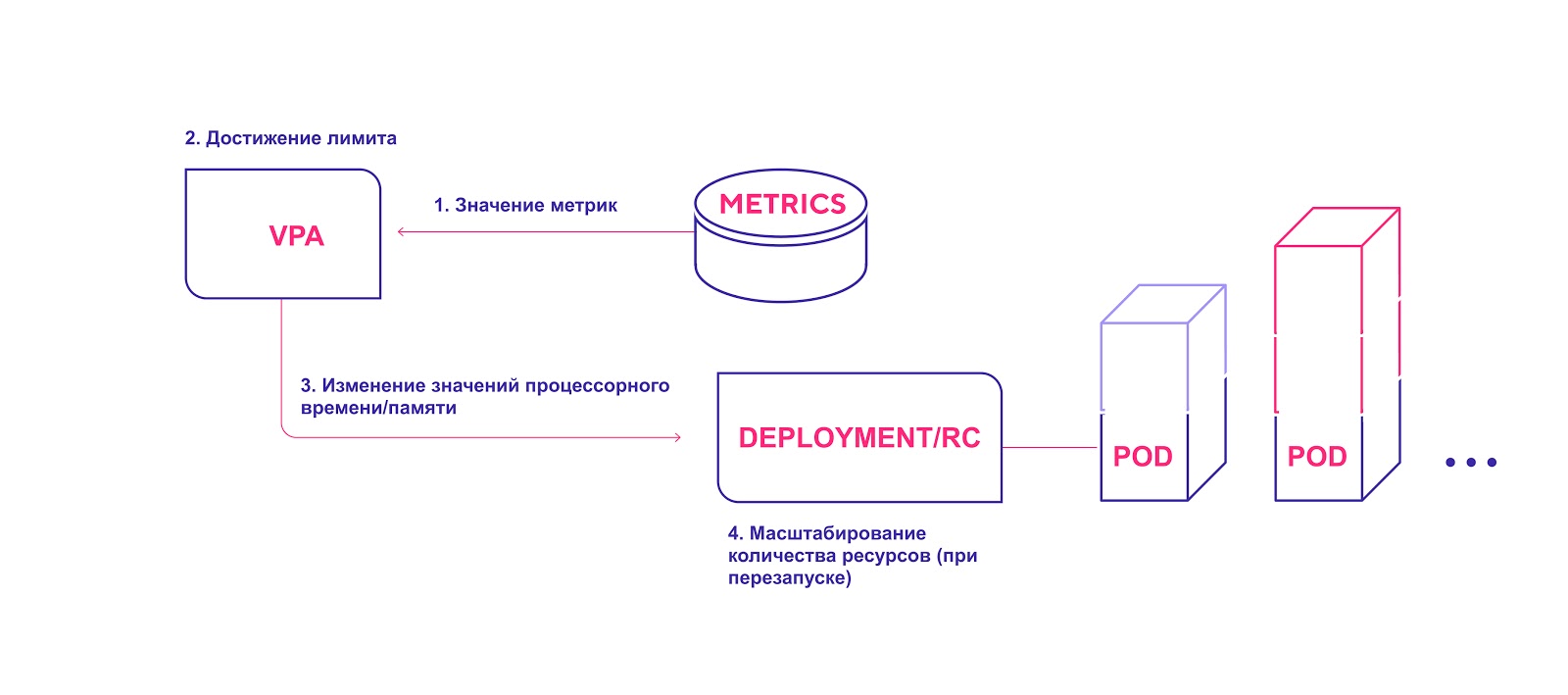 VPA agrega la cantidad requerida de recursos
VPA agrega la cantidad requerida de recursosConsidere los siguientes puntos cuando use VPA:
- El escalado requiere un reinicio obligatorio del pod. Esto es necesario para evitar una operación inestable después de realizar cambios. Para mayor confiabilidad, los módulos se reinician y se distribuyen entre los nodos en función de los recursos recién asignados.
- VPA y HPA aún no son compatibles entre sí y no pueden funcionar en los mismos pods. Si usa ambos mecanismos de escala en el mismo clúster, asegúrese de que la configuración no permita que se activen en los mismos objetos.
- VPA configura las solicitudes de contenedor de recursos en función del uso pasado y actual. No establece límites en el uso de los recursos. Puede haber problemas con el funcionamiento incorrecto de las aplicaciones que comenzarán a aprovechar cada vez más recursos, lo que hará que Kubernetes apague este pod.
- VPA todavía está en una etapa temprana de desarrollo. Esté preparado para que en el futuro cercano el sistema pueda sufrir algunos cambios. Puede leer sobre las limitaciones conocidas y los planes de desarrollo . Entonces, en los planes para implementar el trabajo conjunto de VPA y HPA, así como el despliegue de módulos junto con una política de autoescalado vertical para ellos (por ejemplo, una etiqueta especial 'requiere VPA').
Kubernetes Cluster Auto-Scaling
Cluster Autoscaler (CA) cambia el número de nodos en función del número de pods en espera. El sistema verifica periódicamente los módulos pendientes y aumenta el tamaño del clúster si se requieren más recursos y si el clúster no excede los límites establecidos. La CA interactúa con el proveedor de servicios en la nube, le solicita nodos adicionales o libera a los inactivos. La primera versión pública de CA se introdujo en Kubernetes 1.8.
Esquema de operación de alto nivel CA:
- La CA busca módulos en estado de espera con un intervalo predeterminado de 10 segundos.
- Si uno o varios módulos están en estado de espera debido a la insuficiencia de recursos disponibles en el clúster para su distribución, intenta preparar uno o varios nodos adicionales.
- Cuando el proveedor de servicios en la nube asigna el nodo requerido, se une al clúster y está listo para servir a los módulos de pod.
- El programador de Kubernetes distribuye los módulos pendientes a un nuevo host. Si después de esto, algunos módulos aún permanecen en estado de espera, el proceso se repite y se agregan nuevos nodos al clúster.
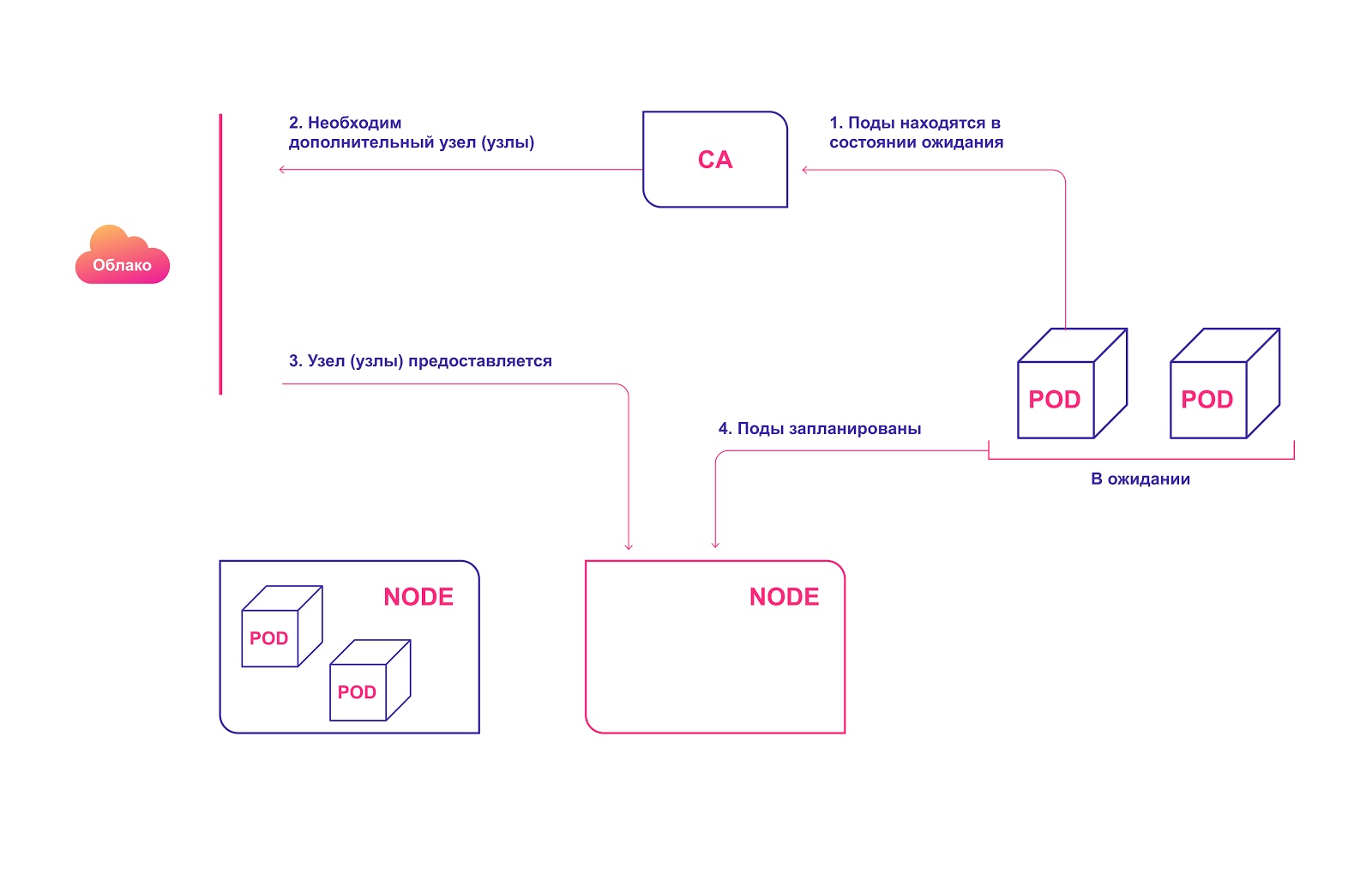 Asignación automática de nodos de clúster en la nube
Asignación automática de nodos de clúster en la nubeConsidere lo siguiente cuando use CA:
- CA garantiza que todos los módulos del clúster tengan un lugar para ejecutarse, independientemente de la carga del procesador. Además, intenta asegurarse de que no haya nodos innecesarios en el clúster.
- La CA registra la necesidad de escalar después de unos 30 segundos.
- Después de que el nodo se vuelve innecesario, CA por defecto espera 10 minutos antes de escalar el sistema.
- En el sistema de autoescala existe el concepto de expansores. Estas son diferentes estrategias para elegir un grupo de nodos a los que se agregarán nuevos.
- Utilice responsablemente la opción cluster-autoscaler.kubernetes.io/safe-to-evict (true) . Si instala muchos pods, o si muchos de ellos están dispersos en todos los nodos, perderá en gran medida la capacidad de reducir el tamaño del clúster.
- Use PodDisruptionBudgets para evitar la eliminación de pods, debido a qué parte de su aplicación puede fallar por completo.
Cómo interactúan los sistemas de autoescala de Kubernetes
Para una armonía perfecta, el autoescalado debe aplicarse tanto a nivel de pod (HPA / VPA) como a nivel de clúster. Relacionan relativamente simplemente entre sí:
- HPA o VPA actualiza réplicas de pod o recursos asignados a pods existentes.
- Si no hay suficientes nodos para el escalado planificado, CA nota la presencia de pods en el estado inactivo.
- CA asigna nuevos nodos.
- Los módulos se distribuyen a nuevos nodos.
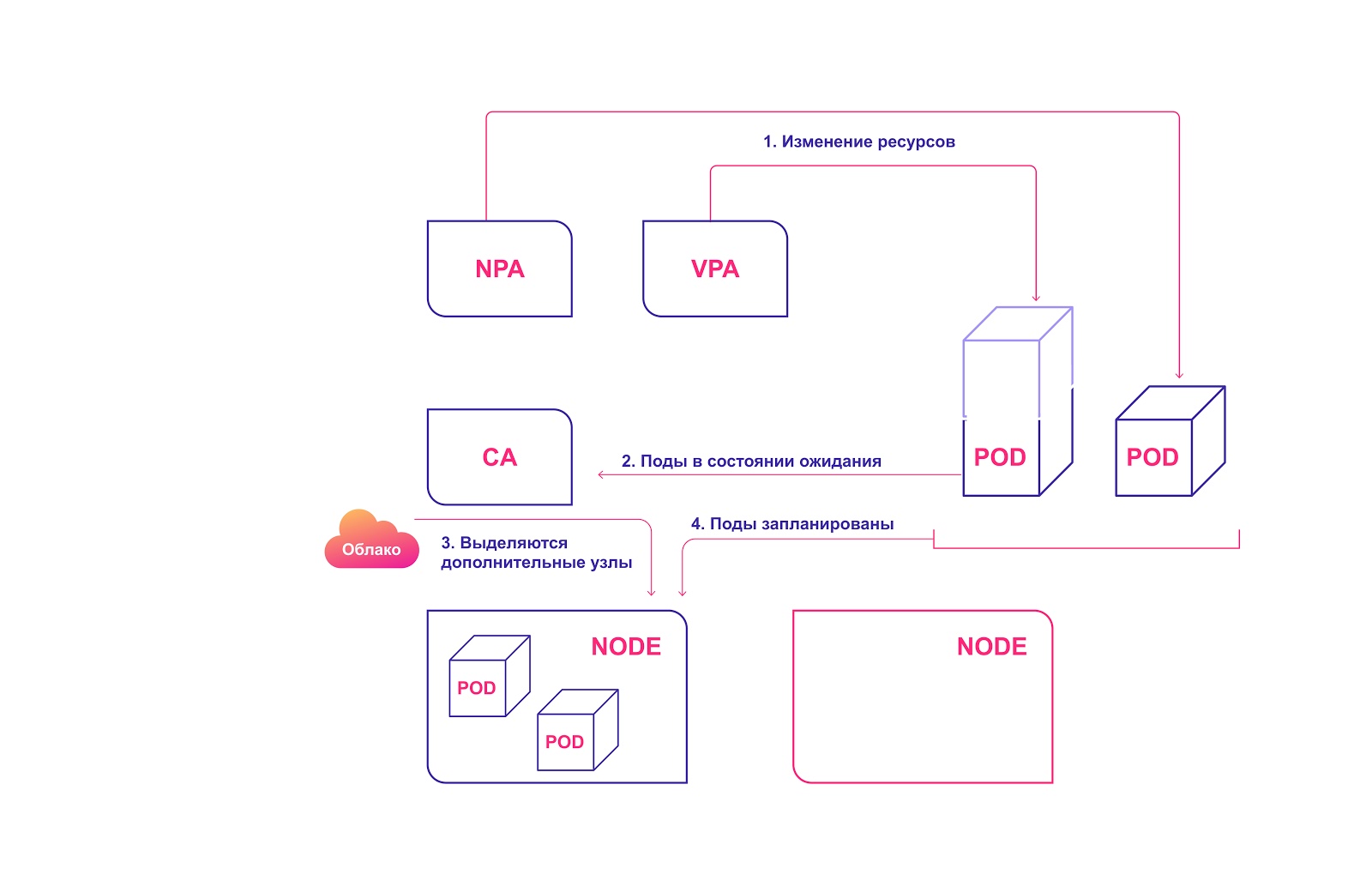 Sistema de escalado colaborativo Kubernetes
Sistema de escalado colaborativo KubernetesErrores comunes de escalado automático de Kubernetes
Hay varios problemas típicos que los desarrolladores encuentran cuando intentan aplicar el autoescalado.
HPA y VPA dependen de métricas y algunos datos históricos. Si se asignan recursos insuficientes, los módulos se colapsarán y no podrán generar métricas. En este caso, el autoescalado nunca tendrá lugar.
La operación de escala en sí es sensible al tiempo. Queremos que los módulos y el clúster se escalen rápidamente, antes de que los usuarios noten cualquier problema o falla. Por lo tanto, se debe tener en cuenta el tiempo de escala promedio de las vainas y el clúster.
Escenario ideal - 4 minutos:
- 30 segundos Actualización de métricas objetivo: 30-60 segundos.
- 30 segundos HPA verifica los valores métricos: 30 segundos.
- Menos de 2 segundos Los módulos de pod se crean y pasan al estado de espera: 1 segundo.
- Menos de 2 segundos CA ve los módulos pendientes y envía llamadas para preparar nodos: 1 segundo.
- 3 minutos El proveedor de la nube asigna nodos. K8s espera hasta que estén listos: hasta 10 minutos (depende de varios factores).
Peor (más realista) escenario: 12 minutos:
- 30 segundos Actualización de métricas objetivo.
- 30 segundos HPA valida valores métricos.
- Menos de 2 segundos Los módulos de pod se crean y pasan al estado de espera.
- Menos de 2 segundos CA ve los módulos pendientes y envía llamadas para preparar nodos.
- 10 minutos El proveedor de la nube asigna nodos. K8s espera hasta que estén listos. El tiempo de espera depende de varios factores, como el retraso del proveedor, el retraso del sistema operativo, el trabajo de las herramientas auxiliares.
No confunda los mecanismos de escala del proveedor de la nube con nuestra CA. Este último funciona dentro del clúster de Kubernetes, mientras que el mecanismo del proveedor de la nube funciona en función de la asignación de nodos. No sabe qué está pasando con sus pods o aplicaciones. Estos sistemas funcionan en paralelo.
Cómo gestionar el escalado en Kubernetes
- Kubernetes es una herramienta de gestión de recursos y orquestación. El clúster y las operaciones de gestión de recursos son un hito clave en el desarrollo de Kubernetes.
- Aprenda la lógica de escalabilidad de pod para HPA y VPA.
- CA debe usarse solo si comprende bien las necesidades de sus vainas y contenedores.
- Para una configuración óptima del clúster, debe comprender cómo funcionan juntos los diversos sistemas de escalado.
- Al evaluar los tiempos de escala, tenga en cuenta los peores y mejores escenarios.