Este artículo discutirá el proyecto nginx-log-collector , que leerá los registros nginx y los enviará al clúster Clickhouse. Por lo general, para los registros, utilice ElasticSearch. Clickhouse requiere menos recursos (espacio en disco, RAM, CPU). Clickhouse registra datos más rápido. Clickhouse comprime los datos, lo que hace que los datos del disco sean aún más compactos. Los beneficios de Clickhouse son visibles en 2 diapositivas del informe Cómo VK inserta datos en ClickHouse desde decenas de miles de servidores.


Para ver el análisis de registro, cree un panel de control para Grafana.
A quién le importa, bienvenido al gato.
Instale nginx, grafana de la manera estándar.
Instale el clúster de clickhouse usando ansible-playbook por Denis Proskurin .
Crear bases de datos y tablas en Clickhouse
Este archivo describe consultas SQL para crear bases de datos y tablas para nginx-log-collector en Clickhouse.
Realizamos cada solicitud a su vez en cada servidor del clúster de Clickhouse.
Nota importante. En esta línea, logs_cluster debe reemplazarse por el nombre del clúster del archivo clickhouse_remote_servers.xml entre "remote_servers" y "shard".
ENGINE = Distributed('logs_cluster', 'nginx', 'access_log_shard', rand())
Instalación y configuración de nginx-log-collector-rpm
Nginx-log-collector no tiene rpm. Aquí https://github.com/patsevanton/nginx-log-collector-rpm crea rpm para ello. Las rpm se recogerán usando Fedora Copr
Instale el paquete rpm nginx-log-collector-rpm
yum -y install yum-plugin-copr yum copr enable antonpatsev/nginx-log-collector-rpm yum -y install nginx-log-collector systemctl start nginx-log-collector
Edite la configuración /etc/nginx-log-collector/config.yaml:
....... upload: table: nginx.access_log dsn: http://ip---clickhouse:8123/ - tag: "nginx_error:" format: error # access | error buffer_size: 1048576 upload: table: nginx.error_log dsn: http://ip---clickhouse:8123/
Configuración de Nginx
Configuración general de nginx:
user nginx; worker_processes auto;
El host virtual es uno:
vhost1.conf:
upstream backend { server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; server ip----stub_http_server:8080; } server { listen 80; server_name vhost1; location / { proxy_pass http://backend; } }
Agregue hosts virtuales al archivo / etc / hosts:
ip----nginx vhost1
Emulador de servidor HTTP
Como un emulador de servidor HTTP usaremos nodejs-stub-server de Maxim Ignatenko
Nodejs-stub-server no tiene rpm. Aquí https://github.com/patsevanton/nodejs-stub-server crea rpm para ello. Las rpm se recogerán usando Fedora Copr
Instale el paquete nodejs-stub-server en nginx rpm ascendente
yum -y install yum-plugin-copr yum copr enable antonpatsev/nodejs-stub-server yum -y install stub_http_server systemctl start stub_http_server
Prueba de carga
Pruebas realizadas con el benchmark Apache.
Instalarlo:
yum install -y httpd-tools
Comenzamos a probar usando el benchmark Apache de 5 servidores diferentes:
while true; do ab -H "User-Agent: 1server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 2server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 3server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 4server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done while true; do ab -H "User-Agent: 5server" -c 10 -n 10 -t 10 http://vhost1/; sleep 1; done
Configuración de Grafana
En el sitio web oficial de Grafana no encontrará un tablero de instrumentos.
Por lo tanto, lo entregaremos.
Puedes encontrar mi tablero guardado aquí .
También necesita crear una variable de tabla con el contenido de nginx.access_log .
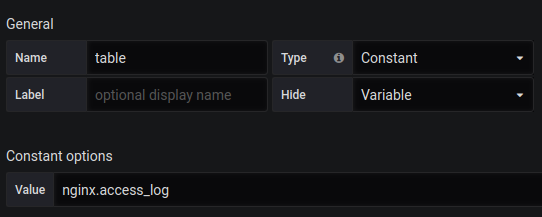
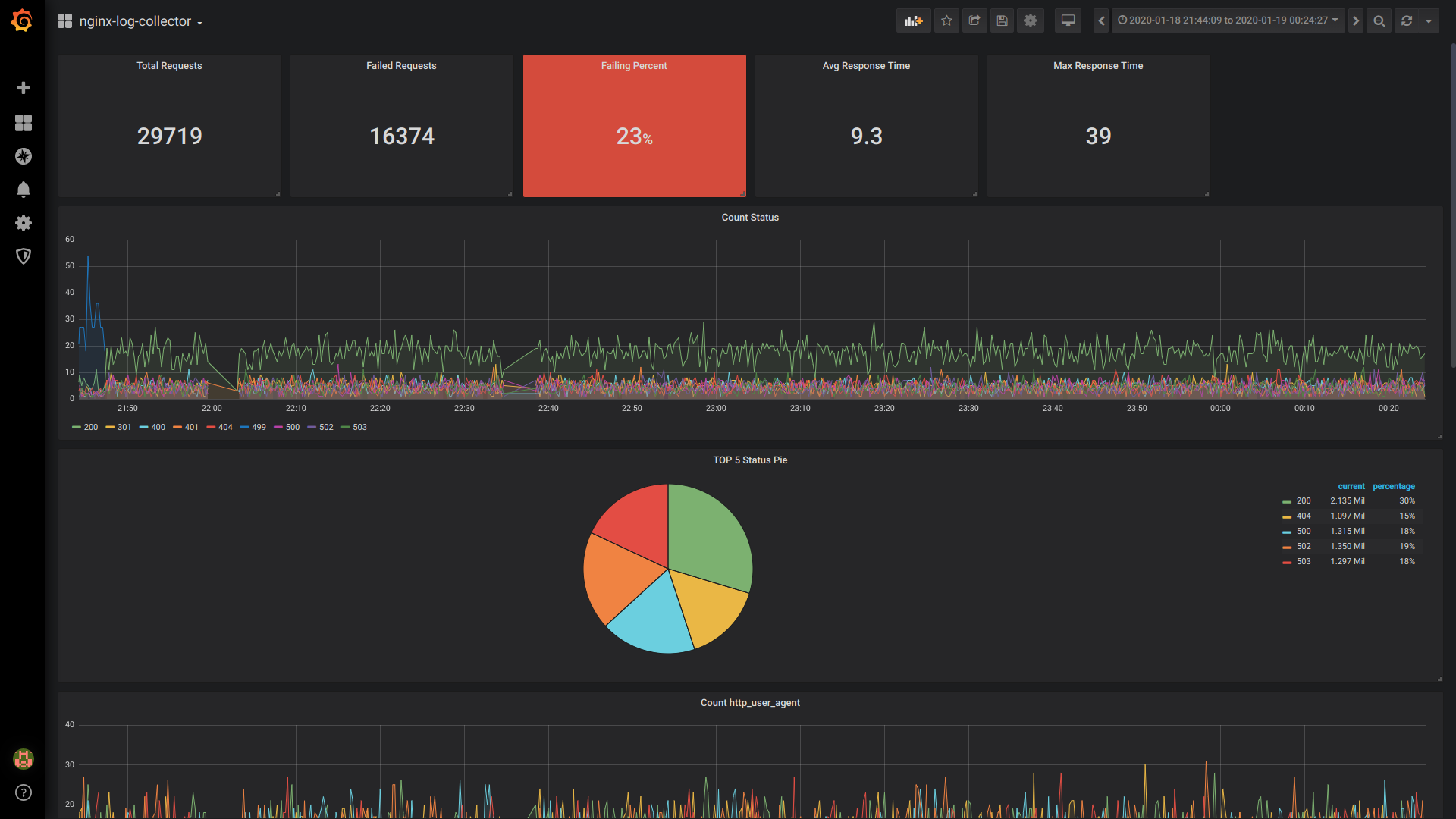
Solicitudes totales de Singlestat:
SELECT 1 as t, count(*) as c FROM $table WHERE $timeFilter GROUP BY t
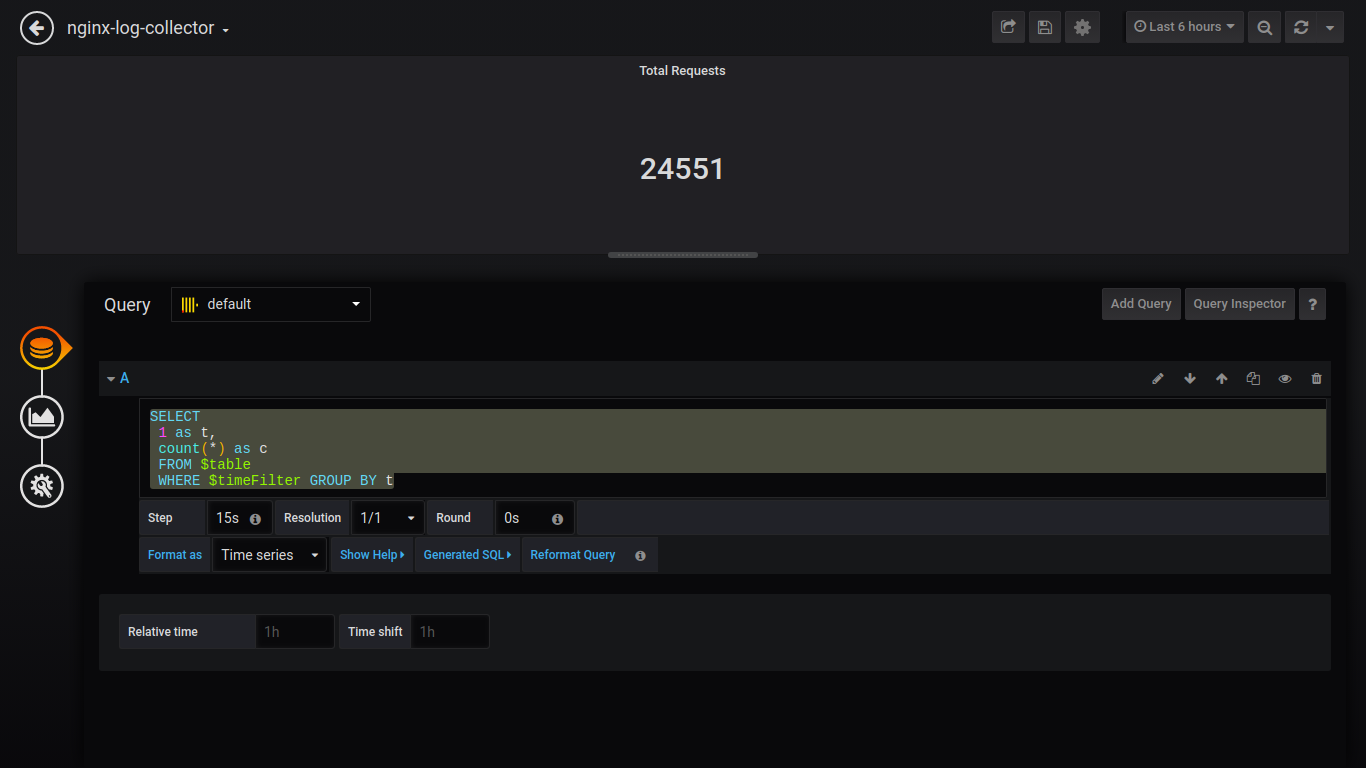
Solicitudes fallidas de Singlestat:
SELECT 1 as t, count(*) as c FROM $table WHERE $timeFilter AND status NOT IN (200, 201, 401) GROUP BY t
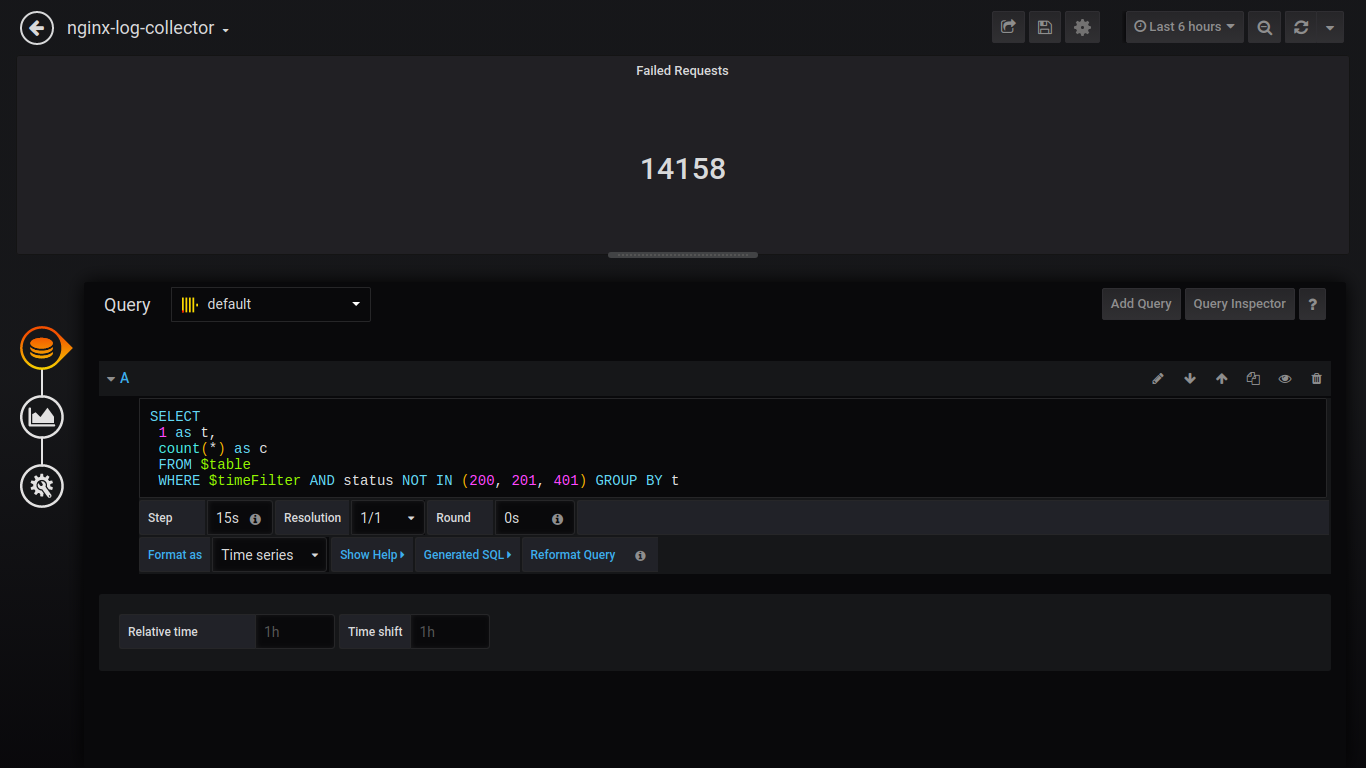
Porcentaje de fallo de Singlestat:
SELECT 1 as t, (sum(status = 500 or status = 499)/sum(status = 200 or status = 201 or status = 401))*100 FROM $table WHERE $timeFilter GROUP BY t
Tiempo de respuesta promedio de Singlestat:
SELECT 1, avg(request_time) FROM $table WHERE $timeFilter GROUP BY 1
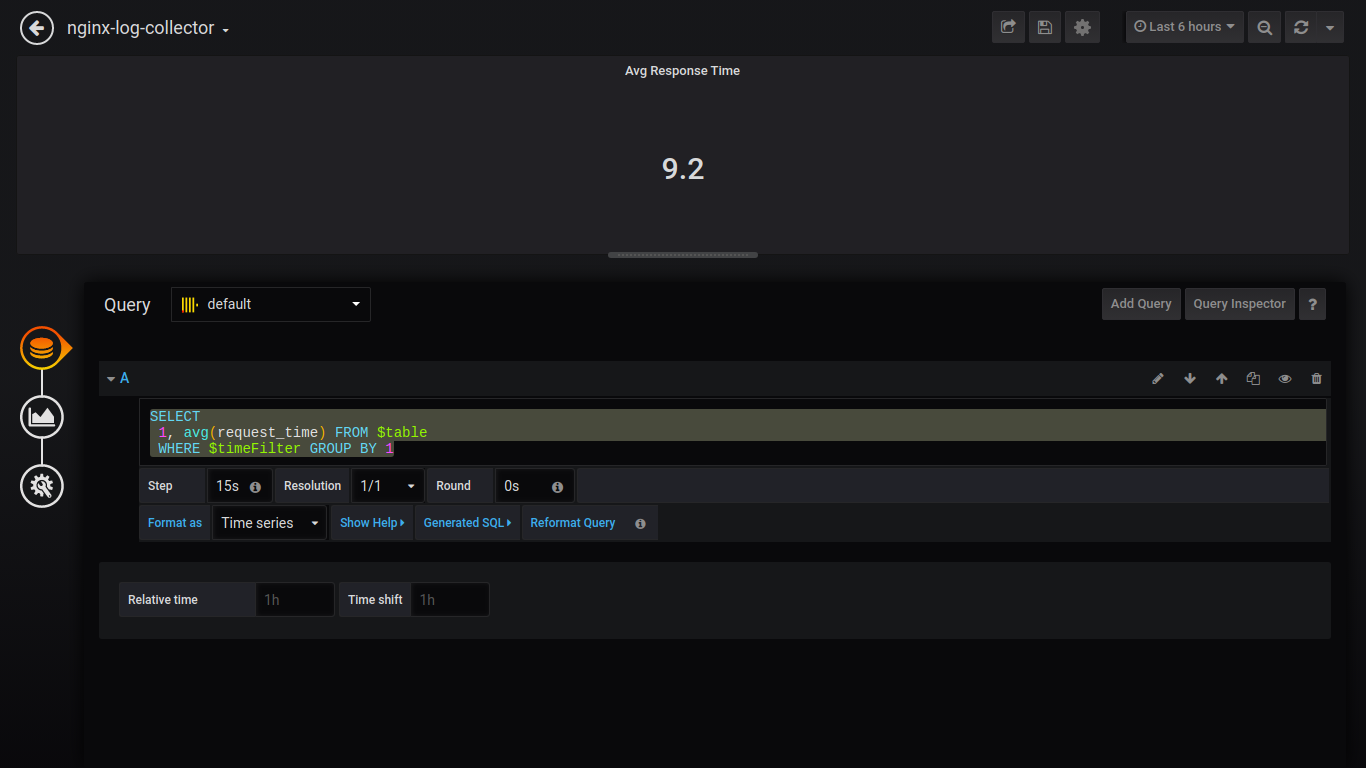
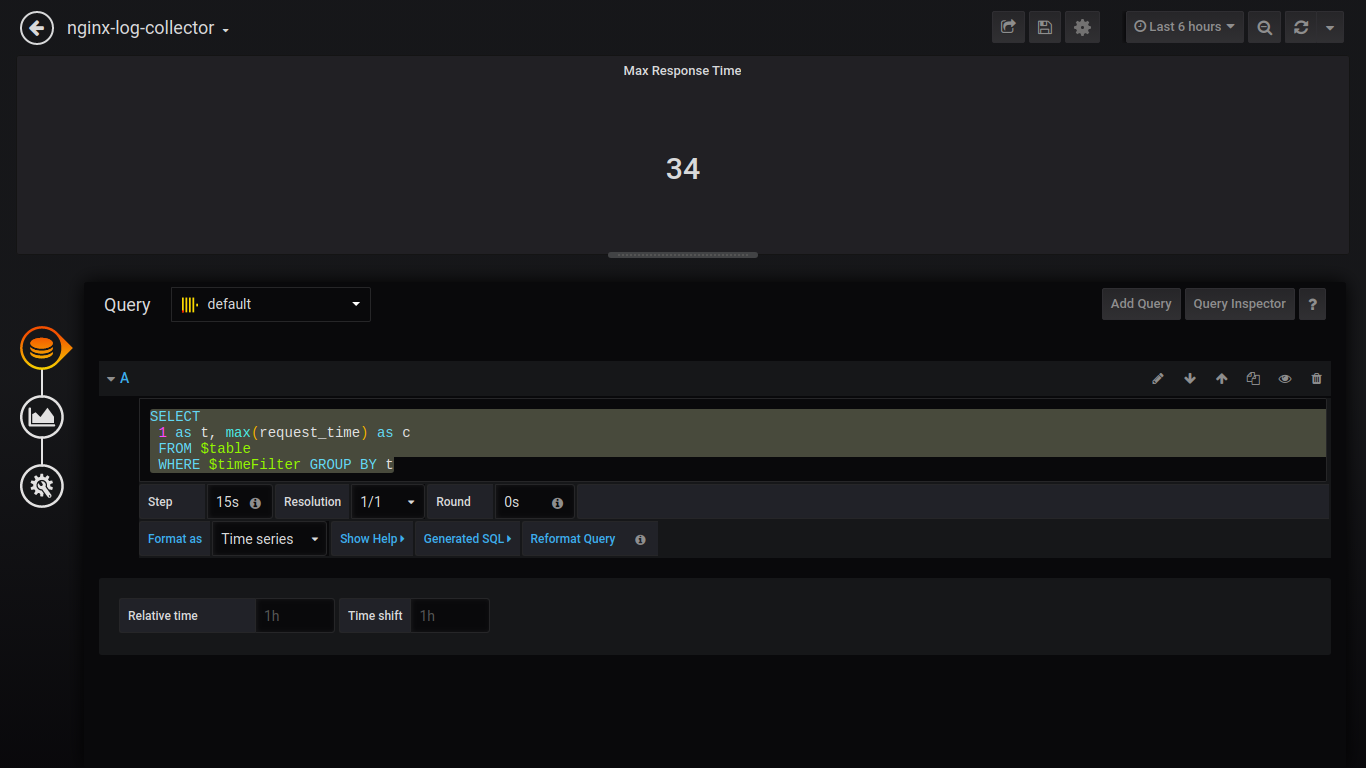
Tiempo de respuesta máximo de Singlestat:
SELECT 1 as t, max(request_time) as c FROM $table WHERE $timeFilter GROUP BY t
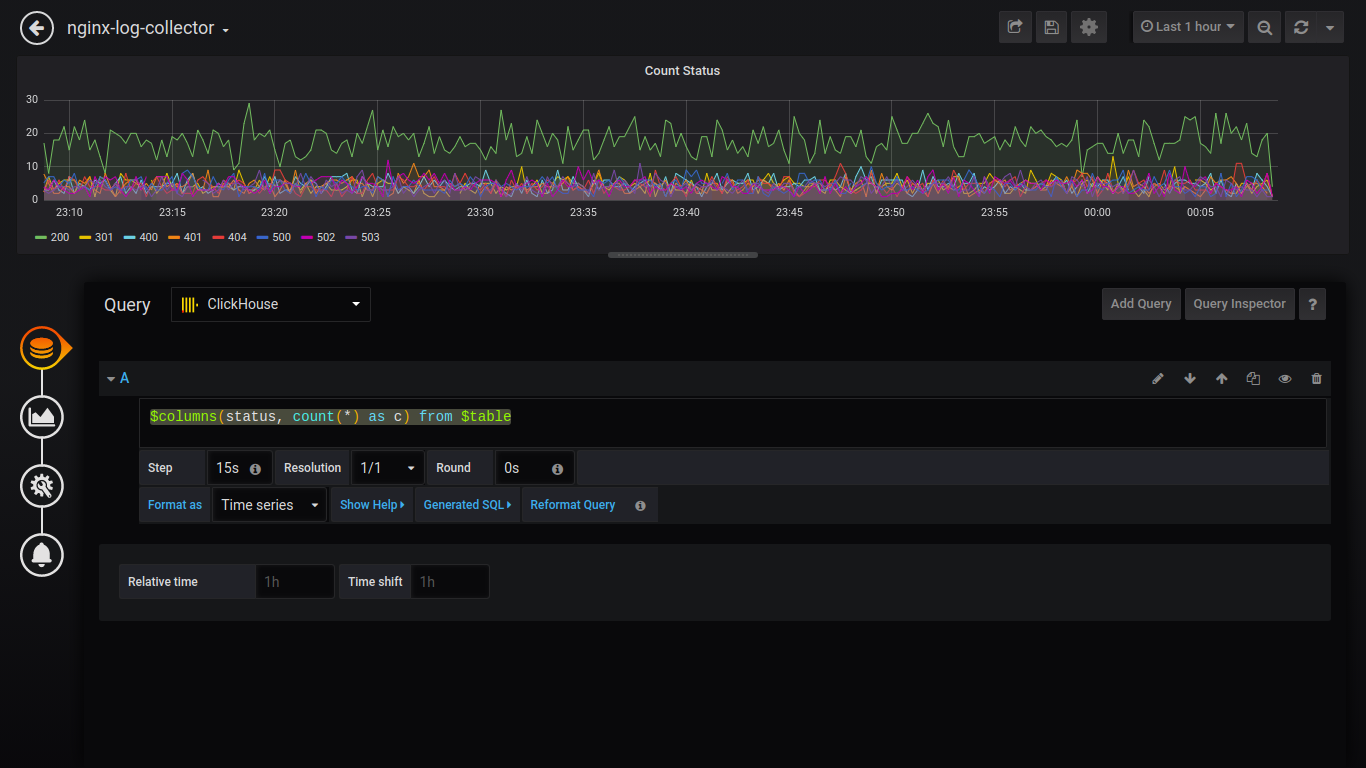
Estado del conteo:
$columns(status, count(*) as c) from $table
Para generar datos como un pastel, debe instalar el complemento y reiniciar grafana.
grafana-cli plugins install grafana-piechart-panel service grafana-server restart
Pie TOP 5 Estado:
SELECT 1, status, sum(status) AS Reqs FROM $table WHERE $timeFilter GROUP BY status ORDER BY Reqs desc LIMIT 5
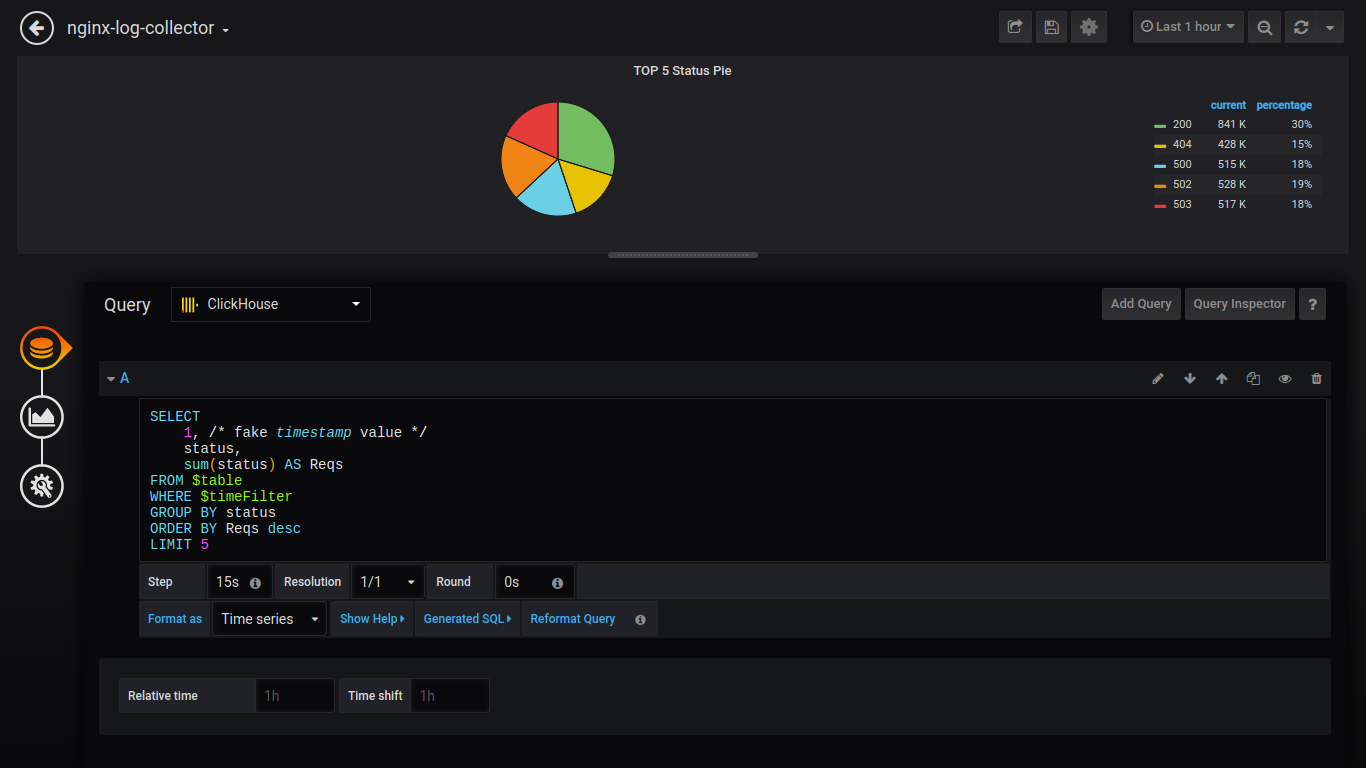
Además, daré solicitudes sin capturas de pantalla:
Cuenta http_user_agent:
$columns(http_user_agent, count(*) c) FROM $table
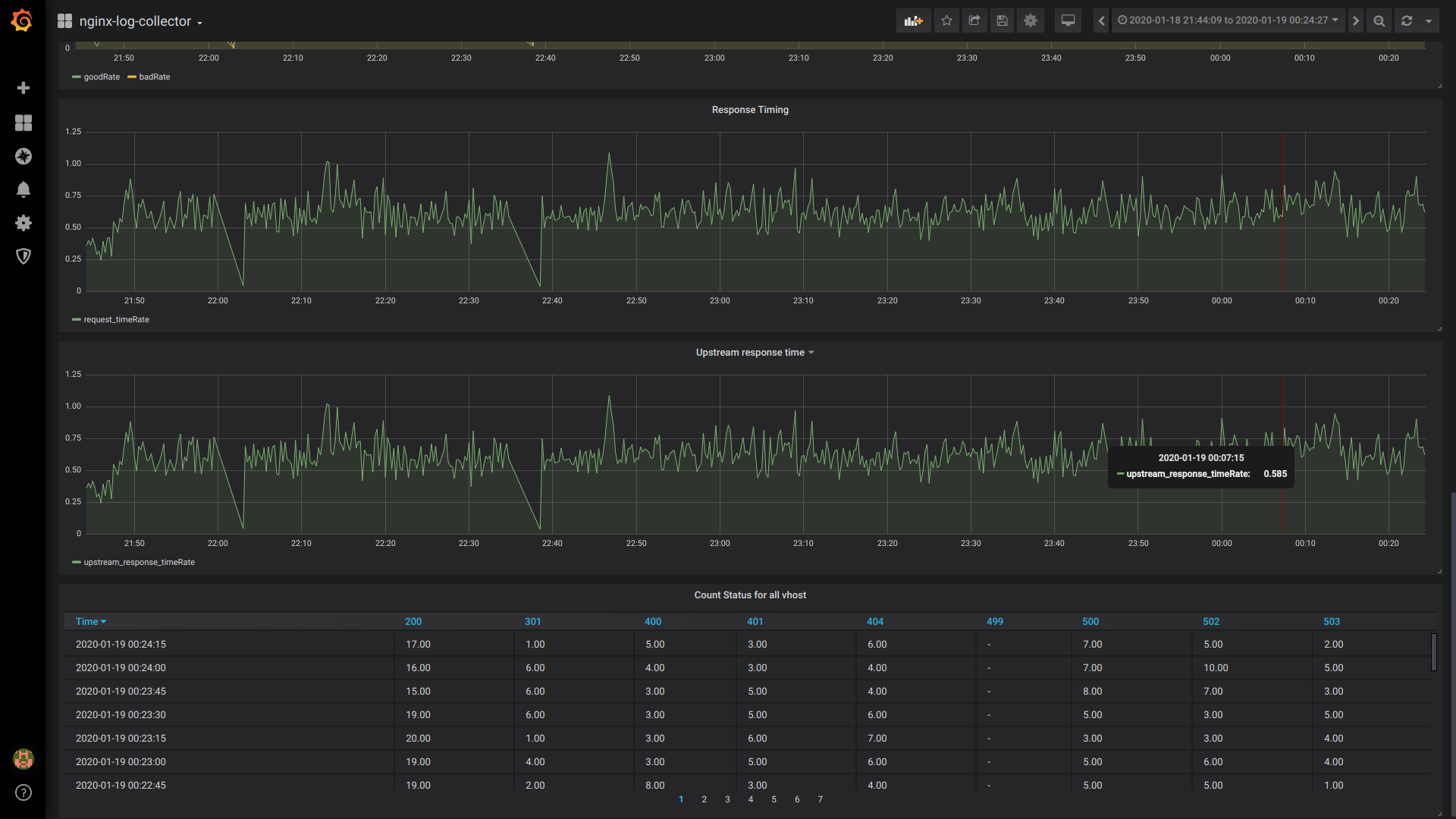
GoodRate / BadRate:
$rate(countIf(status = 200) AS good, countIf(status != 200) AS bad) FROM $table
Tiempo de respuesta:
$rate(avg(request_time) as request_time) FROM $table
Tiempo de respuesta aguas arriba (tiempo de respuesta de la 1ra corriente arriba):
$rate(avg(arrayElement(upstream_response_time,1)) as upstream_response_time) FROM $table
Estado del recuento de tablas para todos los vhost:
$columns(status, count(*) as c) from $table
Vista general del tablero

Comparación de avg () y cuantil ()
avg ()

cuantil ()

Conclusión
Esperemos que la comunidad se involucre en el desarrollo / prueba y uso de nginx-log-collector.
Y alguien, cuando implemente nginx-log-collector, le dirá cuánto ahorró el disco, la RAM y la CPU.
Canales de telegramas:
Milisegundos:
Para quién son importantes los milisegundos, escriba o vote, por favor, en este número .