Si escribe
consultas SQL sin analizar el algoritmo que deben implementar, esto generalmente no conduce a nada bueno en términos de rendimiento.
A tales solicitudes les
gusta "comer" el tiempo del procesador y leer activamente los datos casi de la nada. Además, esto no es necesariamente un tipo de consultas complejas, por el contrario: cuanto más simple esté escrito, mayores serán las posibilidades de tener problemas. Y si el operador JOIN entra en juego ...
Por sí solo, unir tablas no es dañino ni útil: es solo una herramienta, pero debe poder usarlo.
Agrupación de supervisión
Primero, tome un ejemplo muy simple.
Hay un "diccionario" de 100 entradas (por ejemplo, estas son regiones de la Federación de Rusia):
CREATE TABLE tbl_dict AS SELECT generate_series(0, 100) k; ALTER TABLE tbl_dict ADD PRIMARY KEY(k);
... y adjunto hay una tabla de "hechos" relacionados por cada 100K entradas:
CREATE TABLE tbl_fact AS SELECT (random() * 100)::integer k , (random() * 1000)::integer v FROM generate_series(1, 100000); CREATE INDEX ON tbl_fact(k);
Ahora intentemos calcular la suma de los valores para cada "región".
Como se escucha, está escrito
SELECT dk , sum(fv) FROM tbl_fact f NATURAL JOIN tbl_dict d GROUP BY 1;
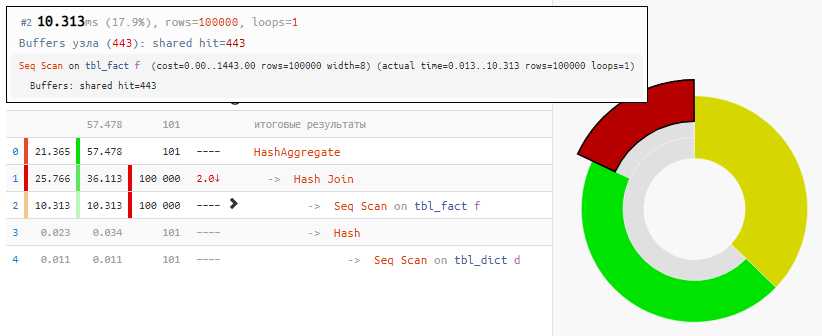
Leer los datos en sí solo tomó el 18% del tiempo, el resto fue procesar:
 [mira explicar.tensor.ru]
[mira explicar.tensor.ru]Y todo porque Hash Join y Hash Aggregate tuvieron que procesar 100K registros cada uno debido a nuestro deseo de
agrupar por el campo de la tabla vinculada .
Usamos ingenio
¡Pero el valor de este campo es igual al valor del campo en la tabla agregada! Es decir, nadie nos molesta en
agrupar primero los "hechos", y solo luego hacer una conexión :
SELECT dk , f.sum FROM ( SELECT k , sum(v) FROM tbl_fact GROUP BY 1 ) f NATURAL JOIN tbl_dict d;
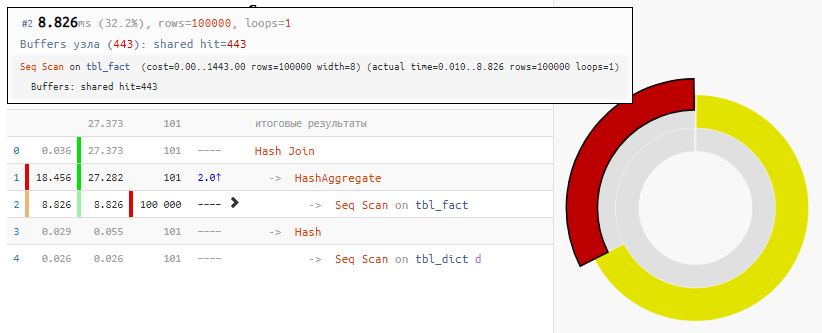 [mira explicar.tensor.ru]
[mira explicar.tensor.ru]Por supuesto, el método no es universal, pero para nuestro caso de la "UNIÓN habitual"
, la ganancia de tiempo es 2 veces con una modificación mínima de la solicitud, simplemente debido a la Hash Join "anulada", que recibió solo 100 entradas en lugar de 100K entradas.
Condiciones desiguales
Ahora vamos a complicar la tarea: tenemos 3 tablas conectadas por un identificador: la tabla principal y las dos tablas auxiliares con algunos datos de aplicación, por los cuales filtraremos.
Una observación pequeña pero muy importante: aunque sobre la base del conocimiento "aplicado" de la tarea objetivo, ya sabemos que las condiciones se cumplirán
en la primera tabla, casi siempre (por definición, 3: 4), y
en la segunda, muy raramente (1: 8 )
Queremos seleccionar de las tablas auxiliares principal y primera los
100 primeros registros por id con valores de identificador pares para los que se
cumplen las
condiciones en todas las tablas . Todos los registros en las tablas, volvamos a estar a 100K.
Generador de guiones CREATE TABLE base( id integer PRIMARY KEY , val integer ); INSERT INTO base SELECT id , (random() * 1000)::integer FROM generate_series(1, 100000) id; CREATE TABLE ext1( id integer PRIMARY KEY , conda boolean ); INSERT INTO ext1 SELECT id , (random() * 4)::integer <> 0
Como se escucha, está escrito
SELECT base.* , ext1.* FROM base NATURAL JOIN ext1 NATURAL JOIN ext2 WHERE id % 2 = 0 AND conda AND condb ORDER BY base.id LIMIT 100;
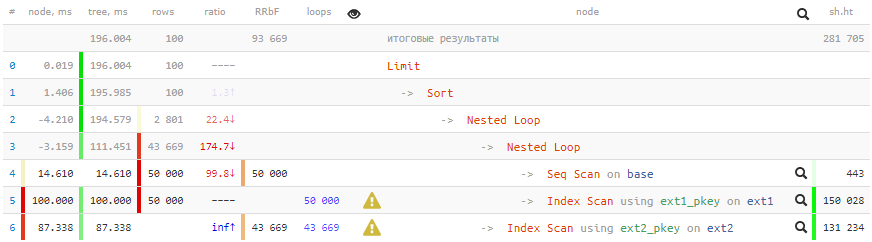 [mira explicar.tensor.ru]
[mira explicar.tensor.ru]Tiempos negativos en términosTantos ciclos han pasado por algunos nodos que los errores de redondeo de algunos incluso se han convertido en menos. Solo sobre artefactos similares en los planes hablaré en
PGConf.Russia .
200ms y más 2GB de datos bombeados - ¡no es muy bueno para 100 registros!
Usamos ingenio
Utilizamos los siguientes enfoques para lograr la aceleración:
- Para empezar, entendemos que tiene sentido que verifiquemos todas las condiciones de las tablas vinculadas solo cuando se cumplen las condiciones de la tabla principal (incluso para la identificación).
- La salida se debe ordenar por base.id, y para esto, ¡la clave principal de esta tabla es perfecta para nosotros!
- No necesitamos datos de ext2, y solo se utilizan para verificar la condición. Esto significa que todo el trabajo con esta tabla se puede eliminar de forma segura de la parte JOIN a WHERE . Y use EXISTS para verificar, de lo contrario, ¿qué pasa si no existe tal registro?
- Necesitamos recuperar al menos algunos datos de ext1 solo si las comprobaciones restantes en base y ext2 se pasan con éxito . Es decir, la conexión con ext1 debe ir después de todas las acciones con base / ext2, lo que se puede lograr usando LATERAL.
- Para que el planificador de consultas no intente convertir la verificación anidada en ext2 en JOIN, la subconsulta "ocultar bajo CASO" .
SELECT base.* , ext1.* FROM base , LATERAL(
 [mira explicar.tensor.ru]
[mira explicar.tensor.ru]La solicitud, por supuesto, se ha vuelto más complicada, ¡pero
ganar 13 veces a tiempo y 350 en "glotonería" vale la pena!
Permítame recordarle nuevamente que no todos los métodos se usan y no siempre, pero saber no será superfluo.También será interesante: