Hola Habr! Mi nombre es Denis Kopyrin, y hoy quiero hablar sobre cómo resolvimos el problema de la copia de seguridad a pedido en macOS. De hecho, una tarea interesante que encontré en el instituto eventualmente se convirtió en un gran proyecto de investigación sobre el trabajo con el sistema de archivos. Todos los detalles están debajo del corte.

No comenzaré desde lejos, solo puedo decir que todo comenzó con un proyecto en el Instituto de Física y Tecnología de Moscú, que desarrollé con mi supervisor en el departamento de base de Acronis. Nos enfrentamos a la tarea de organizar el almacenamiento remoto de archivos, o más bien, mantener el estado actual de sus copias de seguridad.
Para garantizar la seguridad de los datos, utilizamos la extensión del núcleo macOS, que recopila información sobre eventos en el sistema. KPI para desarrolladores tiene una API KAUTH, que le permite recibir notificaciones sobre cómo abrir y cerrar un archivo, eso es todo. Si usa KAUTH, debe guardar completamente el archivo al abrirlo para escribir, porque los eventos de escritura en el archivo no están disponibles para los desarrolladores. Dicha información no fue suficiente para nuestras tareas. De hecho, para complementar de forma permanente una copia de seguridad de los datos, debe comprender exactamente dónde el usuario (o malware :) escribió los nuevos datos en el archivo.
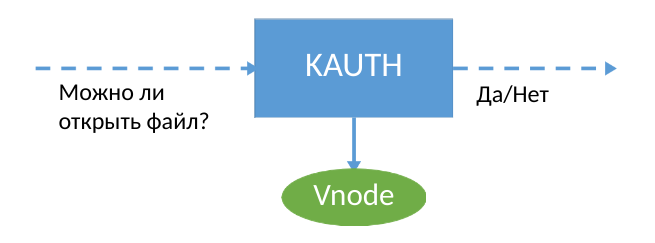
¿Pero cuál de los desarrolladores estaba asustado por las restricciones del sistema operativo? Si la API del kernel no le permite obtener información sobre las operaciones de escritura, entonces debe idear su propia forma de interceptar a través de otras herramientas del kernel.
Al principio, no queríamos parchear el núcleo y sus estructuras. En su lugar, intentaron crear un volumen virtual completo que nos permitiera interceptar todas las solicitudes de lectura y escritura que lo atraviesen. Pero al mismo tiempo, resultó una característica desagradable de macOS: el sistema operativo cree que no tiene 1, sino 2 unidades flash USB, dos discos, etc. Y por el hecho de que el segundo volumen cambia cuando se trabaja con el primero, macOS comienza a funcionar incorrectamente con las unidades. Había tantos problemas con este método que tuve que abandonarlo.
Busca otra solución
A pesar de las limitaciones de KAUTH, este KPI le permite recibir notificaciones sobre el uso de un archivo para grabar antes de todas las operaciones. Los desarrolladores tienen acceso a la abstracción del archivo BSD en el kernel - vnode. Por extraño que parezca, resultó que parchear vnode es más fácil que usar el filtrado de volumen. La estructura vnode tiene una tabla de funciones que proporcionan trabajo con archivos reales. Por lo tanto, tuvimos la idea de reemplazar esta tabla.
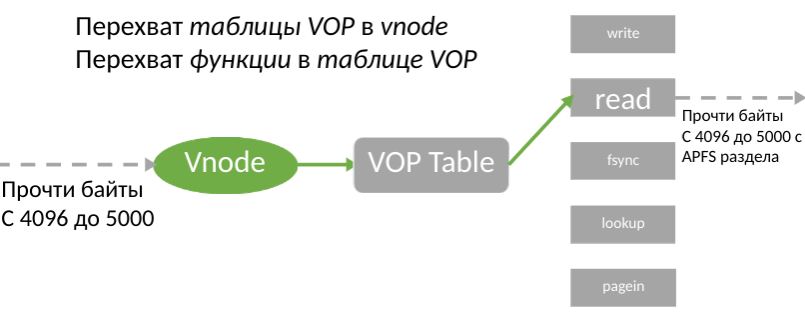
La idea fue considerada inmediatamente como una buena idea, pero para su implementación fue necesario encontrar la tabla en la estructura vnode, ya que Apple no documenta su ubicación en ningún lado. Para hacer esto, era necesario estudiar el código de máquina del kernel, y también determinar si es posible escribir en esta dirección para que el sistema no muera después de eso.
Si se encuentra la tabla, simplemente la copiamos en la memoria, reemplazamos el puntero y pegamos el enlace a la nueva tabla en el vnode existente. Gracias a esto, todas las operaciones con archivos pasarán por nuestro controlador, y podremos registrar todas las solicitudes de los usuarios, incluidas la lectura y la escritura. Por lo tanto, la búsqueda de la mesa atesorada se ha convertido en nuestro principal objetivo.
Dado que Apple realmente no quiere esto, para resolver el problema debe intentar "adivinar" la ubicación de la tabla utilizando la heurística para la ubicación relativa de los campos, o tomar una función ya conocida, desarmarla y buscar un desplazamiento de esta información.
Cómo buscar un desplazamiento: una manera fácilLa forma más sencilla de encontrar compensaciones de tabla en vnode es una heurística basada en la ubicación de los campos en una estructura (
enlace a Github ).
struct vnode { ... int (**v_op)(void *); mount_t v_mount; ... }
Supondremos que el campo v_op que necesitamos está exactamente eliminado de 8 bytes de v_mount. El valor de este último se puede obtener utilizando KPI público (
enlace a Github ):
mount_t vnode_mount(vnode_t vp);
Conociendo el valor de v_mount, comenzaremos a buscar una "aguja en el pajar" - percibiremos el valor del puntero para vnode 'vp' como uintptr_t *, el valor de vnode_mount (vp) como uintptr_t. Esto es seguido por iteraciones al valor "razonable" de i, hasta que se cumpla la condición 'haystack [i] == aguja'. Y si la suposición sobre la ubicación de los campos es correcta, el desplazamiento v_op es i-1.
void* getVOPPtr(vnode_t vp) { auto haystack = (uintptr_t*) vp; auto needle = (uintptr_t) vnode_mount(vp); for (int i = 0; i < ATTEMPTCOUNT; i++) { if (haystack[i] == needle) { return haystack + (i - 1); } } return nullptr; }
Cómo buscar un desplazamiento: desmontajeA pesar de su simplicidad, el primer método tiene un inconveniente significativo. Si Apple cambia el orden de los campos en la estructura vnode, el método simple se romperá. Un método más universal pero menos trivial es desmontar dinámicamente el núcleo.
Por ejemplo, considere la función de kernel desmontada VNOP_CREATE (
enlace a Github ) en macOS 10.14.6. Las instrucciones que nos interesan están marcadas con una flecha ->.
_VNOP_CREATE:
1 push rbp
2 mov rbp, rsp
3 push r15
4 push r14
5 push r13
6 push r12
7 push rbx
8 sub rsp, 0x48
9 mov r15, r8
10 mov r12, rdx
11 mov r13, rsi
-> 12 mov rbx, rdi
13 lea rax, qword [___stack_chk_guard]
14 mov rax, qword [rax]
15 mov qword [rbp+-48], rax
-> 16 lea rax, qword [_vnop_create_desc] ; _vnop_create_desc
17 mov qword [rbp+-112], rax
18 mov qword [rbp+-104], rdi
19 mov qword [rbp+-96], rsi
20 mov qword [rbp+-88], rdx
21 mov qword [rbp+-80], rcx
22 mov qword [rbp+-72], r8
-> 23 mov rax, qword [rdi+0xd0]
-> 24 movsxd rcx, dword [_vnop_create_desc]
25 lea rdi, qword [rbp+-112]
-> 26 call qword [rax+rcx*8]
27 mov r14d, eax
28 test eax, eax
…. errno_t VNOP_CREATE(vnode_t dvp, vnode_t * vpp, struct componentname * cnp, struct vnode_attr * vap, vfs_context_t ctx) { int _err; struct vnop_create_args a; a.a_desc = &vnop;_create_desc; a.a_dvp = dvp; a.a_vpp = vpp; a.a_cnp = cnp; a.a_vap = vap; a.a_context = ctx; _err = (*dvp->v_op[vnop_create_desc.vdesc_offset])(&a;); …
Escanearemos las instrucciones del ensamblador para encontrar el cambio en el vnode dvp. El "propósito" del código ensamblador es llamar a una función desde la tabla v_op. Para hacer esto, el procesador debe seguir estos pasos:
- Sube dvp para registrarte
- Desreferenciarlo para obtener v_op (línea 23)
- Obtenga vnop_create_desc.vdesc_offset (línea 24)
- Llamar a una función (línea 26)
Si todo está claro con los pasos 2-4, entonces surgen dificultades con el primer paso. ¿Cómo entender en qué registro se cargó dvp? Para hacer esto, utilizamos un método para emular una función que monitorea los movimientos del puntero deseado. De acuerdo con la convención de llamadas System V x86_64, el primer argumento se pasa en el registro rdi. Por lo tanto, decidimos hacer un seguimiento de todos los registros que contienen rdi. En mi ejemplo, estos son los registros rbx y rdi. Además, se puede guardar una copia del registro en la pila, que se encuentra en la versión de depuración del núcleo.
Sabiendo que los registros rbx y rdi almacenan dvp, descubrimos que la línea 23 anula la referencia de vnode para obtener v_op. Entonces asumimos que el desplazamiento en la estructura es 0xd0. Para confirmar la decisión correcta, continuamos escaneando y nos aseguramos de que la función se llame correctamente (líneas 24 y 26).
Este método es más seguro, pero, desafortunadamente, también tiene desventajas. Tenemos que confiar en el hecho de que el patrón de la función (es decir, los 4 pasos que mencionamos anteriormente) será el mismo. Sin embargo, la probabilidad de cambiar el patrón de la función es un orden de magnitud menor que la probabilidad de cambiar el orden de los campos. Entonces decidimos detenernos en el segundo método.
Vuelva a colocar los punteros en la tabla.
Después de encontrar v_op, surge la pregunta, ¿cómo usar este puntero? Hay dos formas diferentes: sobrescribir la función en la tabla (tercera flecha en la imagen) o sobrescribir la tabla en vnode (segunda flecha en la imagen).
Al principio parece que la primera opción es más rentable, porque solo necesitamos reemplazar un puntero. Sin embargo, este enfoque tiene 2 inconvenientes significativos. En primer lugar, la tabla v_op es la misma para todos los vnode de un sistema de archivos determinado (v_op para HFS +, v_op para APFS, ...), por lo que es necesario filtrar por vnode, lo que puede ser muy costoso; tendrá que filtrar vnode adicional en cada operación de escritura. En segundo lugar, la tabla está escrita en la página de solo lectura. Esta limitación se puede eludir si usa la grabación a través de IOMappedWrite64, evitando las verificaciones del sistema. Además, si se envía kext con el controlador del sistema de archivos, será difícil descubrir cómo eliminar el parche.
La segunda opción resulta ser más específica y segura: se llamará al interceptor solo para el vnode necesario, y la memoria de vnode inicialmente permite operaciones de lectura-escritura. Como se está reemplazando toda la tabla, es necesario asignar un poco más de memoria (80 funciones en lugar de una). Y dado que el número de tablas suele ser igual al número de sistemas de archivos, el límite de memoria es completamente insignificante.
Es por eso que kext usa el segundo método, aunque, repito, a primera vista parece que esta opción es peor.
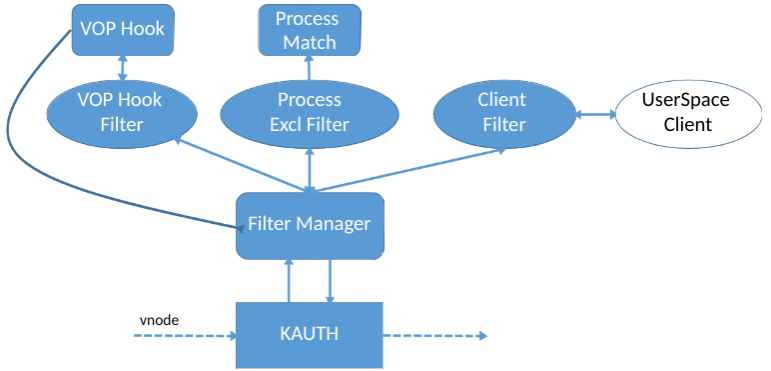
Como resultado, nuestro controlador funciona de la siguiente manera:
- La API de KAUTH proporciona vnode
- Estamos reemplazando la tabla vnode. Si es necesario, interceptamos operaciones solo para vnode "interesante", por ejemplo, documentos de usuario
- Al interceptar, verificamos qué proceso está grabando, filtramos "nuestro"
- Enviamos una solicitud de UserSpace sincrónica al cliente, quien decide qué es exactamente lo que se debe guardar.
Que paso
Hoy tenemos un módulo experimental, que es una extensión del núcleo macOS y tiene en cuenta cualquier cambio en el sistema de archivos a nivel granular. Vale la pena señalar que en macOS 10.15 Apple introdujo un nuevo marco (
enlace a EndpointSecurity ) para recibir notificaciones de cambios en el sistema de archivos, que está planeado para su uso en Active Protection, por lo tanto, la solución descrita en el artículo fue declarada obsoleta.