Hay momentos en los que necesita restringir el acceso de los usuarios a algunos datos en el cubo. Parece que no hay nada complicado: instale los filtros de línea en los roles y ya está, pero hay un problema: el filtro recorta los datos en la tabla y resulta que puede ver la velocidad solo por las líneas disponibles, y necesitamos toda la velocidad, pero los detalles solo deberían estar disponibles para algunos de ellos
Por ejemplo, el usuario debería ver la rotación de todos los productos, con la posibilidad de obtener detalles completos sobre ellos, pero al mismo tiempo, los clientes no deberían mostrar todos, sino solo algunos o todos los clientes, pero con datos parcialmente ocultos en algunos atributos (campos).
Para evitar que el usuario vea la facturación de los clientes, puede superar esto a través de las fórmulas en medidas y mostrar un valor vacío si el usuario intenta ver la facturación de un cliente específico,
aquí se describe una de estas opciones. Sin embargo, este no es el caso. Cuando unas pocas docenas de medidas, escriba una fórmula en cada una de ellas ... ¿y si lo olvida? Pero seguramente lo olvidará algún día ... Y si el usuario necesita datos de la tarjeta de un cliente específico, nada le impedirá ver esto sin elegir una medida de filtrado. Que hacer
Necesitábamos lograr esta pantalla:
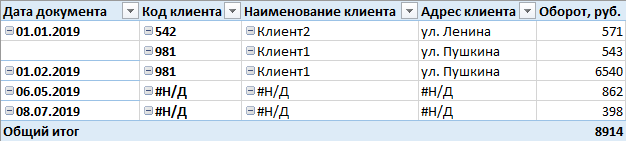
Todo el principio que le permite obtener un resultado similar se basa en un pequeño truco, y consiste en agregar filas sintéticas a la tabla (clientes, en este caso) para que el registro sobre la misma entidad se duplique al menos una vez: el primero contendrá información completa, y el segundo en la mayoría de las columnas se llena con un código auxiliar de tipo
N / A , pero los identificadores son los mismos para ambos registros. Además, con la ayuda de un filtro de roles y una columna especial mediante la cual se realiza el filtrado, dejamos ciertas líneas disponibles para el usuario, ya sea una línea con campos completamente rellenos o con apéndices. Y desde Dado que el cubo tiene la característica de "colapsar" los datos repetidos y ningún otro atributo que proporcione valores únicos es accesible para el usuario, en la tabla resultante todos los clientes con el código
N / A se convertirán en una fila. Creo que en esta etapa todo ya está muy claro, ya no puedes leer. El resultado está en el título del artículo.
Pero si alguien necesita detalles, los tengo.
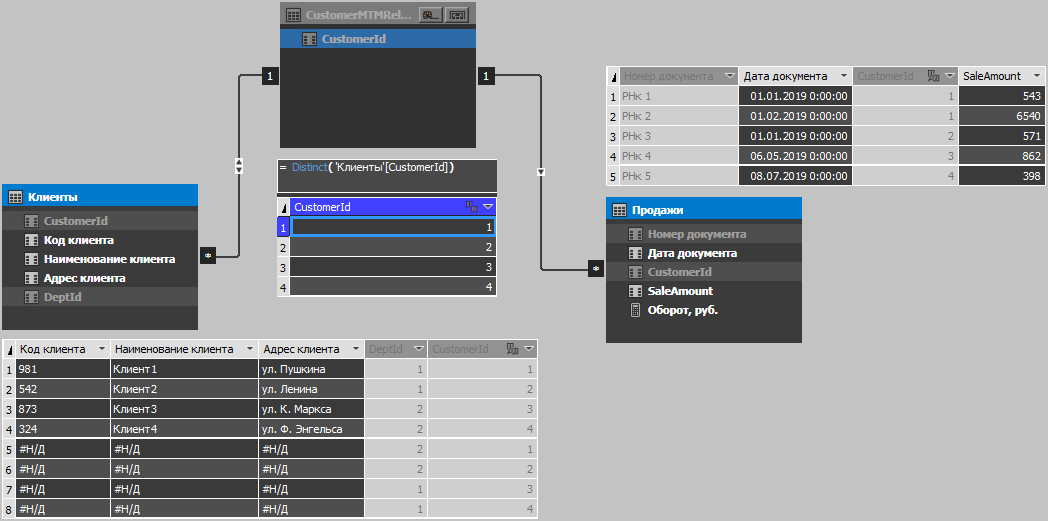
Los modelos tabulares hasta la versión 1400 (SQL 2017 inclusive) no permiten crear relaciones de muchos a muchos, pero en el caso de duplicados, necesitamos dicha relación, por lo que la crearemos a través de una tabla intermedia que contenga solo una columna con identificadores únicos de clientes. La tabla es inicialmente incompresible desde contiene solo valores únicos, por lo que puede hacer que se calcule, porque en este caso no ganaremos nada si lo completamos con t-sql (¿recuerda el principio de procesamiento y el orden de compresión de la tabla?). Solo debido a la capacidad del motor para comprimir datos duplicados, la cantidad de datos en el cubo aumentará ligeramente, y debido al filtrado a través del rol, la sesión del usuario tiene un conjunto reducido de registros, es decir el número final de registros después de filtrar el conjunto permanecerá como estaba sin duplicados. Por lo tanto, no se preocupe, incluso si la tabla es inicialmente lo suficientemente grande, agregar duplicados no afectará el rendimiento y el volumen de manera significativa (por supuesto, los casos son diferentes, pero en la mayoría de ellos todo será solo eso).
La siguiente figura muestra el modelo de cubo y el contenido de la tabla:
Por ejemplo, agregue un filtro simple:

Eso es todo.
Me gustaría advertir sobre una característica del uso de este enfoque. Los usuarios que son administradores en el servidor SSAS, por defecto, entran al cubo sin pasar por todo tipo de roles, incluso si sus nombres están especificados en estos roles. Esto lleva al hecho de que los filtros de roles no funcionan y, bajo el administrador, todos los duplicados son visibles. Pero no se desespere, es suficiente para indicar explícitamente qué rol usar en la cadena de conexión y todo encaja, además, al probar, tendrá que cambiar entre roles más de una vez.
Como comprenderá, puede hacer varias combinaciones del mismo registro con diferentes grados de plenitud de columnas con datos reales. También puede crear una tabla oculta separada en el cubo, que se completará con cuentas a través de ADSI, y distribuirá usuarios a diferentes grupos de dominio, y completará esta tabla dependiendo de las combinaciones de membresía de usuarios en ciertos grupos. Escribimos los enlaces en los filtros de rol línea por línea en esta tabla, lo que nos permitirá controlar las mediciones y también podemos referirnos a ella en medidas, de modo que, si es necesario, algunas medidas muestran el vacío. Con dicha organización, se obtiene un ajuste fino de los derechos de acceso a los datos y todo se almacena en un solo lugar. Pero hay un matiz con las medidas: si un usuario avanzado escribe consultas en el cubo, entonces nada le impide usar su medida, sin marcadores, siempre que sepa los nombres de las columnas base y la fórmula ... Aunque, si lo desea, puede hacerlo aquí restricción, pero ese es otro tema.