Todos hablan sobre los procesos de desarrollo y pruebas, capacitación del personal, aumento de la motivación, pero estos procesos son pocos cuando un minuto de inactividad del servicio cuesta dinero en espacio. ¿Qué hacer cuando realiza transacciones financieras bajo un estricto SLA? ¿Cómo aumentar la confiabilidad y la tolerancia a fallas de sus sistemas, describiendo el desarrollo y las pruebas?

La próxima conferencia HighLoad ++ se llevará a cabo los días 6 y 7 de abril de 2020 en San Petersburgo. Detalles y entradas
aquí . 9 de noviembre, 18:00. HighLoad ++ Moscú 2018, Delhi + Calcutta Hall. Resúmenes y
presentación .
Evgeny Kuzovlev (en lo sucesivo, la CE): - ¡Amigos, hola! Mi nombre es Kuzovlev Evgeny. Soy de EcommPay, una división específica es EcommPay IT, una división de TI de un grupo de empresas. Y hoy hablaremos sobre los tiempos de inactividad: cómo evitarlos, cómo minimizar sus consecuencias, si no puede evitarlos. El tema es: "¿Qué hacer cuando un minuto de tiempo de inactividad cuesta $ 100,000?" Para nosotros, mirando hacia el futuro, los números son comparables.
¿Qué hace EcommPay IT?
Quienes somos ¿Por qué estoy parado frente a ti? ¿Por qué tengo derecho a decirte algo aquí? ¿Y de qué hablaremos con más detalle aquí?

EcommPay Group of Companies es una adquirente internacional. Procesamos pagos en todo el mundo: en Rusia, Europa, en el sudeste asiático (en todo el mundo). Tenemos 9 oficinas, 500 empleados en total y aproximadamente un poco menos de la mitad de ellos son especialistas en TI. Todo lo que hacemos, todo lo que ganamos dinero, lo hicimos nosotros mismos.
Tenemos todos nuestros productos (y tenemos muchos de ellos; en la línea de grandes productos de TI tenemos alrededor de 16 componentes diferentes) los escribimos nosotros mismos; Nos escribimos, nos desarrollamos. Y en este momento estamos realizando alrededor de un millón de transacciones por día (millones, probablemente sea correcto decir eso). Somos una empresa lo suficientemente joven, solo tenemos unos seis años.
Hace 6 años fue una startup cuando los muchachos se unieron al negocio. Estaban unidos por una idea (no había nada más que una idea), y corrimos. Como cualquier startup, corrimos más rápido ... Para nosotros, la velocidad era más importante que la calidad.
En algún momento, nos detuvimos: nos dimos cuenta de que ya no podíamos vivir a esa velocidad y con esa calidad, y teníamos que hacerlo en primer lugar. En este punto, decidimos escribir una nueva plataforma que sea correcta, escalable y confiable. Comenzaron a escribir esta plataforma (comenzaron a invertir, desarrollar el desarrollo, probar), pero en algún momento se dieron cuenta de que el desarrollo y las pruebas no permitían alcanzar un nuevo nivel de calidad de servicio.
Hace un nuevo producto, lo pone en producción, pero aún así, en algún lugar, algo sale mal. Y hoy hablaremos sobre cómo alcanzar un nuevo nivel cualitativo (cómo lo obtuvimos, sobre nuestra experiencia), eliminando el desarrollo y las pruebas; hablaremos sobre lo que está disponible para la explotación: qué puede hacer la explotación por sí solo, qué puede ofrecer pruebas para afectar la calidad.
Tiempos de inactividad. Los mandamientos de la explotación.
Siempre la piedra angular principal, de la que realmente hablaremos hoy es el tiempo de inactividad. Palabra de miedo Si tuvimos un tiempo de inactividad, todo es malo para nosotros. Estamos corriendo para subir, los administradores están reteniendo el servidor - Dios no lo quiera, no se cae, como en esa canción. De esto es de lo que hablaremos hoy.

Cuando comenzamos a cambiar nuestros enfoques, formamos 4 mandamientos. Se presentan en mis diapositivas:
Estos mandamientos son lo suficientemente simples:

- Identifica rápidamente el problema.
- Deshazte de él aún más rápido.
- Ayuda a entender la razón (más tarde, para los desarrolladores).
- Y estandarizar enfoques.
Le llamo la atención sobre el punto número 2. Eliminamos el problema, pero no lo resolvemos. Decidir es la segunda vez. Lo principal para nosotros es que el usuario está protegido de este problema. Existirá en un determinado entorno aislado, pero este entorno no entrará en contacto con él. En realidad, revisaremos estos cuatro grupos de problemas (para algunos con más detalle, para otros con menos detalle), les diré lo que usamos, qué tipo de experiencia tenemos para resolver.
Solución de problemas: ¿cuándo ocurren y qué hacer con ellos?
Pero comenzaremos fuera de orden, comenzamos con el punto número 2: ¿cómo deshacerse rápidamente del problema? Hay un problema: tenemos que solucionarlo. "¿Qué haremos con esto?" Es la pregunta principal. Y cuando comenzamos a pensar en cómo solucionar el problema, desarrollamos algunos requisitos que la resolución de problemas debería seguir.

Para formular estos requisitos, decidimos hacernos la pregunta: "¿Y cuándo tenemos problemas"? Y los problemas, como se vio después, se encuentran en cuatro casos:

- Mal funcionamiento del hardware.
- Fallo de servicios externos.
- Cambio de versión de software (la misma implementación).
- Crecimiento explosivo de la carga.
No hablaremos de los dos primeros. Un mal funcionamiento del hardware se resuelve de manera bastante simple: debe tener todo duplicado. Si se trata de discos, los discos deben ensamblarse en RAID, si es un servidor, el servidor debe estar duplicado, si tiene una infraestructura de red, debe colocar una segunda copia de la infraestructura de red, es decir, tomar y duplicar. Y si algo te falla, cambias a las capacidades de reserva. Es difícil decir más aquí.
El segundo es el fracaso de los servicios externos. Para la mayoría, el sistema no es un problema en absoluto, pero no para nosotros. Como procesamos los pagos, somos un agregador que se interpone entre el usuario (quien ingresa los datos de su tarjeta) y los bancos, los sistemas de pago ("Visa", "MasterCard", "Mundo" de la misma). Nuestros servicios externos (sistemas de pago, bancos) tienden a fallar. Ni nosotros ni usted (si tiene tales servicios) podemos influir en esto.
¿Qué hacer entonces? Hay dos opciones Primero, si puede, debe duplicar este servicio de alguna manera. Por ejemplo, si podemos, transferimos el tráfico de un servicio a otro: procesamos, por ejemplo, tarjetas a través de Sberbank, Sberbank tiene problemas; transferimos el tráfico [condicionalmente] a Raiffeisen. La segunda cosa que podemos hacer es notar rápidamente la falla de los servicios externos y, por lo tanto, hablaremos sobre la velocidad de reacción en la siguiente parte del informe.
De hecho, de estos cuatro, podemos afectar específicamente el cambio de versiones de software, para tomar medidas que conduzcan a una mejora en el contexto de las implementaciones y en el contexto del crecimiento explosivo de la carga. En realidad lo hicimos. Aquí, de nuevo, un pequeño comentario ...
De estos cuatro problemas, varios se resuelven de inmediato si tiene una nube. Si está en las nubes Microsoft Azhur, Ozone, use nuestras nubes, desde Yandex o Mail, entonces al menos un mal funcionamiento del hardware se convierte en su problema y todo se vuelve inmediatamente bueno en el contexto de un mal funcionamiento del hardware.
Somos una pequeña empresa no estándar. Aquí todos hablan de Kubernets, de nubes: no tenemos Kubernets ni nubes. Pero tenemos bastidores con hierro en muchos centros de datos, y nos vemos obligados a vivir con este hierro, nos vemos obligados a responder por todo. Por lo tanto, en este contexto hablaremos. Entonces, sobre los problemas. Los dos primeros están fuera de paréntesis.
Cambiar la versión del software. Bases
Nuestros desarrolladores no tienen acceso a la producción. Por qué Pero simplemente estamos certificados por PCI DSS, y nuestros desarrolladores simplemente no tienen derecho a subir al "producto". Eso es, punto. Absolutamente Por lo tanto, la responsabilidad de desarrollo finaliza exactamente en el momento en que el desarrollo pasó la compilación a la versión.

Nuestra segunda base, que tenemos, que también nos ayuda mucho, es la falta de conocimiento único e indocumentado. Espero que hagas lo mismo. Porque si esto no es así, entonces tendrás problemas. Surgirán problemas cuando este conocimiento único e indocumentado no esté presente en el momento correcto en el lugar correcto. Suponga que tiene una persona que sabe cómo implementar un componente específico: no hay persona, está de vacaciones o se enfermó, eso es todo, tiene problemas.
Y la tercera base a la que hemos llegado. Llegamos a él a través del dolor, la sangre, las lágrimas: llegamos a la conclusión de que cualquiera de nuestros componentes contiene errores, incluso si no tiene errores. Decidimos esto por nosotros mismos: cuando implementamos algo, cuando colocamos algo en el producto, tenemos una compilación con errores. Hemos formado los requisitos que nuestro sistema debe satisfacer.
Requisitos de cambio de versión de software
Hay tres de estos requisitos:

- Debemos revertir rápidamente la implementación.
- Debemos minimizar el impacto de una implementación fallida.
- Y debemos ser capaces de quedarnos atascados rápidamente en paralelo.
En ese orden! Por qué Porque, antes que nada, al implementar la nueva versión, la velocidad no es importante, pero es importante para usted, si algo salió mal, retroceda rápidamente y tenga un impacto mínimo. Pero si tiene un conjunto de versiones en la producción, para lo cual resultó que hay un error (como nieve en su cabeza, no hubo despliegue, pero el error está contenido): la velocidad del despliegue posterior es importante para usted. ¿Qué hemos hecho para cumplir con estos requisitos? Recurrimos a dicha metodología:
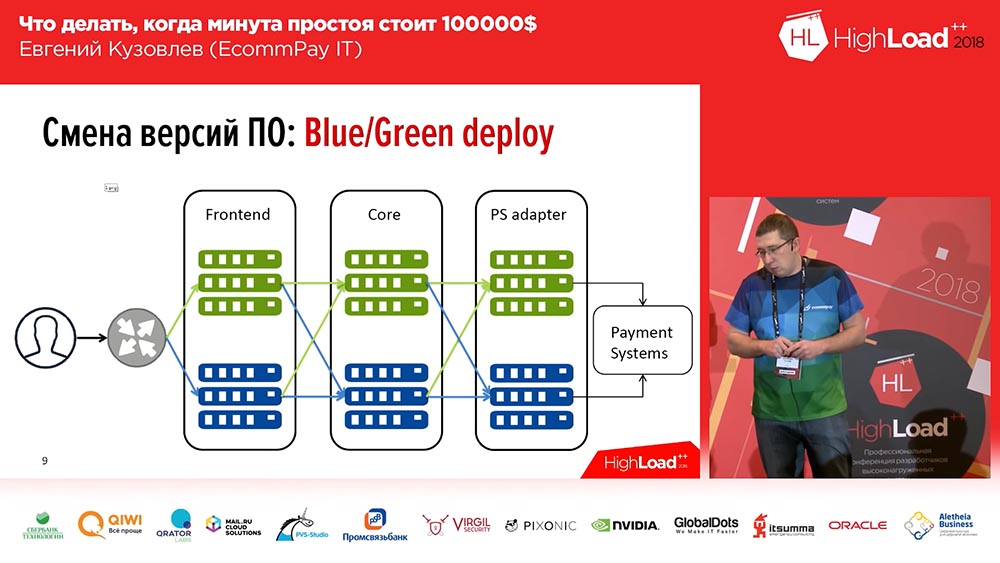
Es bien sabido, no hemos inventado ni una sola vez: esta es una implementación Azul / Verde. Que es esto Debe tener una copia para cada grupo de servidores en el que están instaladas sus aplicaciones. La copia es "cálida": no hay tráfico, pero en cualquier momento este tráfico puede enviarse a esta copia. Esta copia contiene la versión anterior. Y en el momento de la implementación, implementa el código en una copia inactiva. Luego cambie parte del tráfico (o todo) a la nueva versión. Por lo tanto, para cambiar el flujo de tráfico de la versión anterior a la nueva, solo necesita realizar una acción: debe cambiar el equilibrador en el flujo ascendente, cambiar la dirección, de un flujo ascendente a otro. Esto es muy conveniente y resuelve el problema de cambio rápido, retroceso rápido.
Aquí, la solución a la segunda pregunta es la minimización: puede colocar una nueva línea, en una línea con un nuevo código, solo una parte de su tráfico (por ejemplo, 2%). Y estos 2%, ¡no son 100%! Si ha perdido el 100% del tráfico durante una implementación fallida, esto da miedo, si ha perdido el 2% del tráfico, esto es desagradable, pero no da miedo. Además, es muy probable que los usuarios ni siquiera lo noten, porque en algunos casos (no todos) el mismo usuario, al presionar F5, lo llevarán a otra versión que funcione.
Despliegue azul / verde. Enrutamiento
Además, no todo es tan simple "Blue / Green Deploy" ... Todos nuestros componentes se pueden dividir en tres grupos:
- Esta es la interfaz (páginas de pago que ven nuestros clientes);
- núcleo de procesamiento;
- un adaptador para trabajar con sistemas de pago (bancos, MasterCard, Visa ...).
Y hay un matiz: el matiz es la ruta entre las líneas. Si simplemente cambia el 100% del tráfico, no tiene estos problemas. Pero si desea cambiar el 2%, las preguntas comienzan: "¿Cómo hacer esto?" Lo más simple en la frente: puede seleccionar al azar Round Robin en nginx, y le queda un 2%, 98% - a la derecha. Pero esto no siempre es adecuado.
Aquí, por ejemplo, el usuario interactúa con el sistema en más de una solicitud. Esto es normal: 2, 3, 4, 5 consultas: sus sistemas pueden ser los mismos. Y si es importante para usted que todas las solicitudes de los usuarios lleguen a la misma línea a la que llegó la primera solicitud, o (segundo momento) todas las solicitudes de los usuarios llegan a una nueva línea después del cambio (podría comenzar a trabajar antes con el sistema, antes de cambiar), entonces esta distribución aleatoria no te conviene. Luego están las siguientes opciones:

La primera opción, la más fácil, basada en los parámetros básicos del cliente (IP Hash). Tiene una IP y la comparte de derecha a izquierda por IP. Luego, el segundo caso descrito por mí funcionará para usted cuando haya una implementación, el usuario ya podría comenzar a trabajar con su sistema y, desde el momento de la implementación, todas las solicitudes irán a una nueva línea (a la misma, por ejemplo).
Si por alguna razón esto no le conviene y necesita enviar solicitudes a la línea donde llegó la solicitud principal e íntima del usuario, entonces tiene dos opciones ...
La primera opción: puede tomar nginx + pagado. Existe un mecanismo de sesiones permanentes, que, a solicitud inicial del usuario, expone una sesión al usuario y la vincula a un flujo ascendente particular. Todas las solicitudes de usuario posteriores dentro de la vida útil de la sesión irán a la misma cadena ascendente donde se configuró la sesión.
Esto no nos convenía, porque ya teníamos nginx normal. Cambiar nginx + no es que sea costoso, solo fue un poco doloroso para nosotros y no muy correcto. Por ejemplo, "Sticks Sessions" no funcionó para nosotros por la simple razón de que "Sticks Sessions" no brinda la oportunidad de realizar rutas en base a "Eli-or". Allí puede especificar lo que hacemos "Sesiones fijas", por ejemplo, por IP o por IP y por cookie o por parámetro de publicación, pero "Eli-or" ya es más complicado allí.
Por lo tanto, llegamos a la cuarta opción. Tomamos nginx en "esteroides" (esto es openresty), este es el mismo nginx que además admite la inclusión de los últimos scripts. Puede escribir un último script, deslizar este "abrir", y este último script se ejecutará cuando llegue una solicitud del usuario.
Y de hecho, escribimos un guión de este tipo, nos pusimos "abiertos" y en este guión clasificamos 6 parámetros diferentes para la concatenación de "O". Dependiendo de la disponibilidad de este o aquel parámetro, sabemos que el usuario llegó a una página u otra, a una línea u otra.
Despliegue azul / verde. Ventajas y desventajas.
Por supuesto, probablemente podríamos hacerlo un poco más fácil (use las mismas "Sesiones fijas"), pero aún tenemos un matiz tal que no solo el usuario interactúa con nosotros en el marco de un procesamiento de una transacción ... Pero los sistemas de pago también interactúan con nosotros: nosotros, después de procesar la transacción (enviando una solicitud al sistema de pago), recibimos una devolución de llamada.
Y supongamos que si dentro de nuestro circuito podemos omitir la dirección IP del usuario en todas las solicitudes y separar a los usuarios en función de la dirección IP, entonces no diremos la misma "Visa": "Dudes, somos una empresa tan retro, somos un poco internacionales (en el sitio y en De Rusia) ... Y por favor, denos un vistazo a la dirección IP del usuario en un campo adicional, ¡su protocolo está estandarizado! Negocio claro, no estarán de acuerdo.

Por lo tanto, para nosotros no encajaba, hicimos openresty. En consecuencia, con el enrutamiento tenemos así:
El Blue / Green Deploy tiene, respectivamente, las ventajas de las que hablé y las desventajas.
Desventaja dos:
- necesita molestarse con el enrutamiento;
- La segunda desventaja principal es el costo.
Necesita el doble de servidores, necesita el doble de recursos operativos, debe invertir el doble de esfuerzo para mantener todo este zoológico.
Por cierto, entre las ventajas hay otra cosa que no he mencionado antes: tiene una reserva en caso de un aumento en la carga. Si tiene un aumento explosivo en la carga, una gran cantidad de usuarios se han derramado sobre usted, entonces simplemente incluye la segunda línea en la distribución de 50 a 50, e inmediatamente tiene 2 servidores en su clúster hasta que resuelva el problema de tener servidores todavía.
¿Cómo hacer un despliegue rápido?
Hablamos sobre cómo resolver el problema de la minimización y la reversión rápida, pero la pregunta sigue siendo: "¿Cómo implementar rápidamente?"

Aquí es breve y simple.
- Debe tener un sistema de CD (Entrega continua), sin él, en ninguna parte. Si tiene un servidor, puede quedarse atascado con plumas. Tenemos alrededor de mil quinientos servidores y 1.500 manijas, por supuesto, podemos plantar un departamento del tamaño de esta sala, solo para implementar.
- La implementación debe ser paralela. Si tiene una implementación consistente, entonces todo está mal. Un servidor es normal, implementará mil quinientos servidores todo el día.
- Nuevamente, para acelerar, esto ya no es necesario, probablemente. Cuando desploey suelen construir el proyecto. ¿Tiene un proyecto web, hay una parte de front-end (crea un paquete web allí, npm recopila algo así), y este proceso es básicamente de corta duración: 5 minutos, pero estos 5 minutos pueden ser críticos. Por lo tanto, por ejemplo, no hacemos esto: eliminamos estos 5 minutos, desplegamos artefactos.
¿Qué es un artefacto? Un artefacto es una construcción ensamblada en la que toda la parte del ensamblaje ya se ha completado. Almacenamos este artefacto en el almacenamiento de artefactos. Usamos dos de estos almacenamientos al mismo tiempo: era Nexus y ahora jFrog Artifactory). Inicialmente utilizamos el Nexus porque comenzamos a practicar este enfoque en aplicaciones Java (se adaptaba bien). Luego ponen allí la parte de las aplicaciones escritas por PHP; y el Nexus ya no era adecuado, y por lo tanto elegimos jFrog Artefactory, que puede producir casi todo. Incluso llegamos al hecho de que en este almacenamiento de artefactos almacenamos nuestros propios paquetes binarios, que recopilamos para los servidores.
Crecimiento explosivo de la carga
Hablamos sobre cambiar la versión del software. Lo siguiente que tenemos es un crecimiento explosivo de la carga. Aquí probablemente entiendo que el crecimiento explosivo de la carga no es lo correcto ...
Escribimos un nuevo sistema: está orientado al servicio, a la moda hermosa, a todos los trabajadores, a todas las colas, a toda la asincronía. Y en tales sistemas, los datos pueden ir en flujo diferente. Para la primera transacción, el 1 °, 3 °, 10 ° trabajador puede participar, para la segunda transacción: 2 °, 4 °, 5 °. Y hoy, digamos, en la mañana tiene un flujo de datos que usa los primeros tres trabajadores, y en la noche cambia dramáticamente, y todo usa a los otros tres trabajadores.
Y aquí resulta que necesita escalar de alguna manera a los trabajadores, necesita escalar de alguna manera sus servicios, pero al mismo tiempo evitar la inflación de los recursos.

Hemos determinado los requisitos para nosotros mismos. : Service discovery, – , – . , , . «», «», .
? . 70 . «», «» , , . 100 «», 100 . . , – 24/7 , , , 70 , .
«», IP Scale-Nomad – ScaleNo, : . , : « ?» – , .
, , , , , – , . 3-5 – .

Como funciona ! : : , – , – , – .
, . 45 – . 2 , ( – , ). – , 5-10 , .
«», , «» . , , – . . № 2 – « ».
. ?
– « ?» ! . ?

!
, , . . , . « ». :

«» «», . «» . «» «» , , – «» «», – «» «» Telegraf.
New Relic. , . , . 1,5 , , : « ». , , . «-» , 15 «-». .
, – Debugger. «», , , «». Que es esto , 15-30 , « » , .
, ( ) – , . , «» – , «» . – , , , .
?
? ?

- Response time / RPS – . , - .
- .
- .
- .
– «», «» . , - , . – ( ). - 5-10-15 – , ( ).
– :
– 6 , – . – RPS, RTS. – «». «» , - … , .
, – . OpenTracing – , , , ; . OpenTracing- , . , , . , , .

, 3 – . , , 20-30 .
, – .
, , , , . , .

? , : (, «»); , . , , … – -. , : « »?
… -, ( ) , . : – , , ( ). , - . ! . .
, .
, – , , , , , - . , , .

( – ), ELK Stack – . -, , ELK, , ELK. .
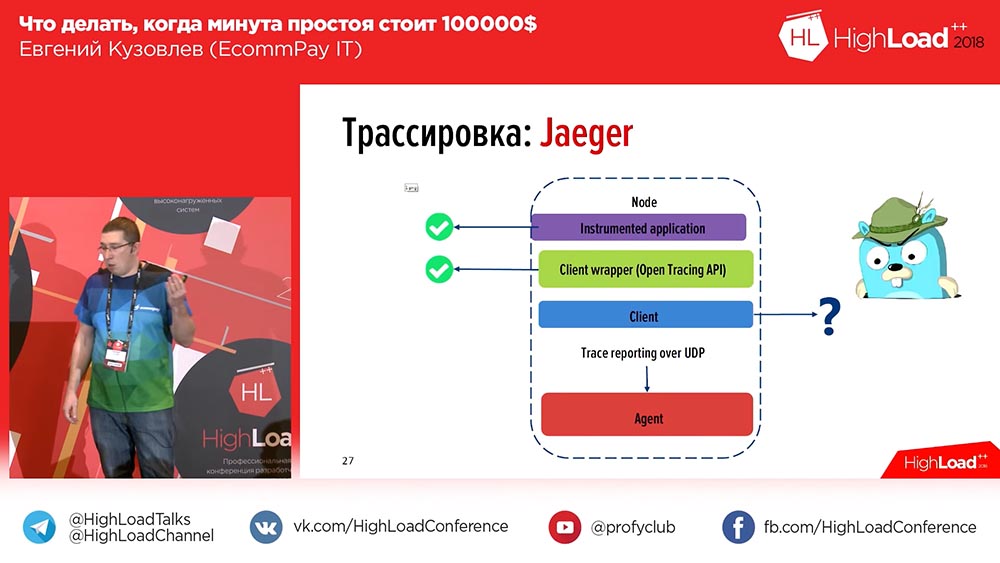
. , , , , «», id- ( ). . Por qué , , . , – OpenTracing, .
, , – «» (Zipkin) «» (Jaeger). «» – , «». «» , , , , . «» .
«»: , Api ( Api PHP , , – , ), . «», – , . ? :
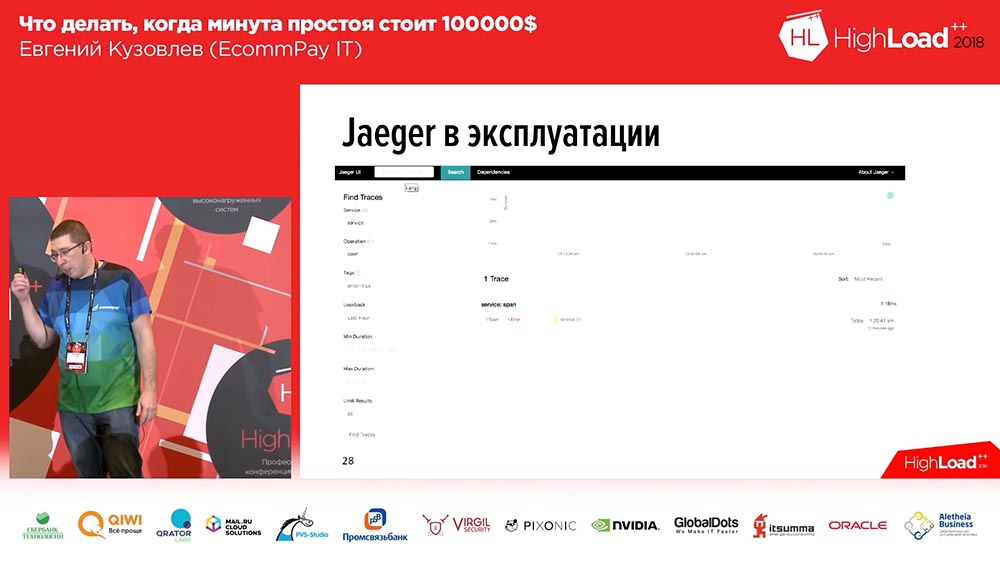
«» span'. , , (1-2-3 – , ). , . , Error. Error , . , span:

. , , . : – , , .
, . , . , «» PHP – , welcome to use, :

– OpenTracing Api, php-extention, . . , . : , extention up to you.
. – . ? :

«»? , ! «» , , , . ?

- . , . 60 , . , , – , .
- . , , RnD-. , (, ) , , .
- , – , . .
- Tenemos tolerancias Por ejemplo, no consideramos el tiempo de inactividad si perdimos el 2% del tráfico en dos minutos. Esto, en principio, no entra en nuestras estadísticas. Si más en porcentaje o tiempo, ya contamos.
- Y siempre escribimos post-mortem. Pase lo que pase con nosotros, cualquier situación en la que se haya comportado de manera inapropiada en el sitio de producción se reflejará en el potsortem. Un post-mortem es un documento en el que escribe lo que le sucedió, el tiempo detallado de lo que hizo para solucionarlo y (¡esto es un bloqueo obligatorio!) Lo que hará para evitar que esto suceda en el futuro. Esto es necesario, necesario para su posterior análisis.
¿Qué considerar el tiempo de inactividad?

¿A qué condujo todo esto?
Esto llevó al hecho de que (tuvimos ciertos problemas de estabilidad, esto no nos convenía ni a los clientes ni a nosotros) en los últimos 6 meses, nuestro indicador de estabilidad ascendió a 99,97. Podemos decir que esto no es mucho. Sí, tenemos algo por lo que luchar. Aproximadamente la mitad de este indicador es la estabilidad, por así decirlo, no la nuestra, sino nuestro firewall de aplicaciones web, que está delante de nosotros y se utiliza como un servicio, pero no es importante para los clientes.
Aprendimos a dormir por la noche. Por fin! Hace seis meses, no sabíamos cómo. Y en esta nota con los resultados, quiero hacer un comentario. Anoche hubo un maravilloso informe sobre el sistema de control de un reactor nuclear. Si las personas que escribieron este sistema me escuchan, olvídate de lo que dije sobre "2% no es tiempo de inactividad". Para usted, el 2% es tiempo de inactividad, ¡aunque sea por dos minutos!
Eso es todo! Sus preguntas

Sobre balanceadores y migración de bases de datos
Pregunta de la audiencia (en adelante - B): - Buenas tardes. ¡Muchas gracias por tal informe de administrador! La pregunta es breve sobre el tema de sus equilibradores. Mencionó que tiene WAF, es decir, según tengo entendido, usa algún tipo de equilibrador externo ...
: - No, utilizamos nuestros servicios como equilibradores. En este caso, WAF es para nosotros únicamente una herramienta de protección DDoS.
P: - ¿Podría decir algunas palabras sobre balanceadores?
EK: - Como dije, este es un grupo de servidores en openresty. Ahora tenemos 5 grupos de redundantes que responden exclusivamente ... es decir, un servidor en el que se encuentra exclusivamente openresty, solo representa el tráfico. En consecuencia, para comprender cuánto tenemos: ahora tenemos un flujo de tráfico regular, esto es varios cientos de megabits. Se las arreglan, se sienten bien, ni siquiera se esfuerzan.
P: - También una pregunta simple. Hay una implementación azul / verde. ¿Y qué haces, por ejemplo, con las migraciones desde la base de datos?
EK: - ¡Buena pregunta! Mire, nosotros en el despliegue Azul / Verde tenemos líneas separadas para cada línea. Es decir, si estamos hablando de las líneas de eventos que se transmiten del trabajador al trabajador, hay líneas separadas para la línea azul y la línea verde. Si hablamos de la base de datos en sí, entonces la redujimos deliberadamente, como pudimos, poniendo todo casi en línea, solo tenemos una pila de transacciones en la base de datos. Y tenemos una sola pila de transacciones para todas las líneas. Con una base de datos en este contexto: no la compartimos con azul y verde, porque ambas versiones del código deben saber qué está pasando con la transacción.
Amigos, todavía tengo un premio tan pequeño para incentivarlos: un libro. Y necesito darle la mejor pregunta.
P: Hola. Gracias por el informe La pregunta es esta. Supervisas los pagos, supervisas los servicios con los que te comunicas ... Pero, ¿cómo supervisas para que una persona de alguna manera acuda a tu página de pagos, realice un pago y el proyecto le acredite dinero? Es decir, ¿cómo monitorea que marchant está disponible y acepta su devolución de llamada?
: - "Comerciante" para nosotros en este caso es exactamente el mismo servicio externo que el sistema de pago. Monitoreamos la velocidad de respuesta del "comerciante".
Sobre el cifrado de la base de datos
P: Hola. Tengo una pequeña pregunta. Tiene datos confidenciales de PCI DSS. ¿Quería saber cómo se almacenan los PAN en las colas en las que deben ingresar? ¿Usas algún cifrado? Y a partir de aquí surge la segunda segunda pregunta: en PCI DSS, es necesario volver a cifrar la base de datos periódicamente en caso de cambios (despido de administradores, etc.): ¿cómo sucede esto con la accesibilidad?

EK: ¡ Maravillosa pregunta! En primer lugar, no almacenamos PAN en las colas. No tenemos derecho a almacenar PAN en ningún lugar claro, en principio, por lo tanto, utilizamos un servicio especial (lo llamamos "Kademon"): este es un servicio que solo hace una cosa: recibe un mensaje y envía un mensaje cifrado. Y almacenamos todo con este mensaje cifrado. En consecuencia, la longitud de la clave para nosotros es inferior a kilobytes, por lo que es directa, seria y confiable.
P: - ¿Necesita 2 kilobytes ahora?
EK: - Parece que ayer fueron 256 ... Bueno, ¿dónde más?
En consecuencia, este es el primero. Y en segundo lugar, la solución que existe, es compatible con el proceso de reencriptación: hay dos pares de "tortas" (claves) que dan "cubiertas" que encriptan (las claves son claves, dek son derivados de claves que encriptan). Y en el caso del inicio del procedimiento (se lleva a cabo regularmente, de 3 meses a ± algunos), cargamos un nuevo par de "pasteles" y tenemos los datos reencriptados. Tenemos servicios separados que eliminan todos los datos, los cifran de una manera nueva; los datos se almacenan al lado del identificador de clave con el que se cifran. En consecuencia, tan pronto como los datos se cifren con nuevas claves, eliminamos la clave anterior.
A veces necesitas hacer pagos manualmente ...
P: - Es decir, si se produce un retorno para alguna operación, ¿descifrarlo con la clave anterior?
CE: Sí.
P: - Entonces una pequeña pregunta más. Cuando hay algún tipo de falla, caída, incidente, es necesario empujar la transacción en modo manual. Existe tal situación.
EK: Sí, lo hace.
P: - ¿De dónde sacas estos datos? ¿O tú mismo vas con bolígrafos a esta tienda?
EK: - No, bueno, por supuesto, tenemos algún tipo de sistema de back-office que contiene una interfaz para nuestro soporte. Si no sabemos en qué estado se encuentra la transacción (por ejemplo, mientras el sistema de pago no respondió con un tiempo de espera), no sabemos a priori, es decir, asignamos el estado final solo con plena confianza. En este caso, volcamos la transacción en un estado especial para el procesamiento manual. Por la mañana, al día siguiente, tan pronto como el soporte recibe información de que tales transacciones permanecen en el sistema de pago, las procesan manualmente en esta interfaz.

P: - Tengo un par de preguntas. Una de ellas es la continuación de la zona PCI DSS: ¿cómo se obtienen sus registros de bucle? Tal pregunta porque el desarrollador podría poner cualquier cosa en los registros. Segunda pregunta: ¿cómo se implementan las revisiones? Los bolígrafos en la base de datos son una opción, pero puede haber correcciones rápidas gratuitas: ¿cuál es el procedimiento allí? Y la tercera pregunta probablemente esté relacionada con RTO, RPO. Su disponibilidad era de 99.97, casi cuatro nueves, pero según tengo entendido, tiene un segundo centro de datos, un tercer centro de datos y un quinto centro de datos ... ¿Cómo maneja su sincronización, replicación, todo lo demás?
EK: - Comencemos por el primero. La primera pregunta sobre los registros fue? Cuando escribimos registros, tenemos una capa que enmascara todos los datos confidenciales. Ella mira la máscara y los campos adicionales. En consecuencia, nuestros registros salen con datos ya enmascarados y un bucle PCI DSS. Esta es una de las tareas regulares asignadas al departamento de pruebas. Están obligados a verificar todas las tareas, incluidos los registros que escriben, y esta es una de las tareas habituales en la revisión del código, para controlar que el desarrollador no haya escrito algo. El departamento de seguridad de la información lleva a cabo una verificación posterior de esto una vez por semana: los registros se toman de forma selectiva para el último día y se ejecutan a través de un escáner-analizador especial desde los servidores de prueba para verificar todo esto.
Sobre arreglos calientes. Esto está incluido en nuestro cronograma de implementación. Tenemos un artículo separado sobre las revisiones. Creemos que implementamos revisiones todo el día cuando lo necesitamos. Tan pronto como se haya ensamblado la versión, tan pronto como se ejecute, tan pronto como tengamos el artefacto, contactaremos al administrador del sistema para que lo llame y lo implementará en el momento que sea necesario.
Sobre los "cuatro nueves". El número que tenemos ahora, realmente se logró, y lo buscamos en otro centro de datos. Ahora tenemos un segundo centro de datos, y estamos comenzando a enrutarlos, y la cuestión del centro de replicación de datos cruzados es realmente una pregunta no trivial. Intentamos resolverlo a su debido tiempo por diferentes medios: tratamos de usar la misma "Tarántula", no funcionó para nosotros, lo digo de inmediato. Por lo tanto, llegamos al hecho de que hacemos el orden de "sensación" manualmente. De hecho, tenemos todas las aplicaciones en el modo asincrónico de las unidades necesarias de sincronización "cambio hecho" entre centros de datos.
P: - Si tienes una segunda, ¿por qué no una tercera? Porque nadie tiene cerebro dividido todavía ...
: - Y no tenemos un cerebro dividido. Debido al hecho de que cada aplicación maneja un multimaestro, no nos importa a qué centro llegó la solicitud. Estamos listos para el hecho de que, en el caso de que un centro de datos se bloquee (estamos recostados) y en medio de la solicitud de un usuario cambiado a un segundo centro de datos, realmente estamos listos para perder a este usuario; pero serán unidades, unidades absolutas.
P: - Buenas tardes. Gracias por el informe Usted habló sobre su depurador, que impulsa algunas transacciones de prueba en producción. ¡Pero cuéntanos sobre las transacciones de prueba! ¿Qué tan profundo va?
EC: - Pasa por el ciclo completo de todo el componente. No hay diferencias entre la transacción de prueba y la de combate para el componente. Y desde el punto de vista de la lógica, este es solo un proyecto separado en el sistema, en el que solo se persiguen las transacciones de prueba.
P: - ¿Y dónde lo cortas? Entonces Core envió ...
: - Estamos detrás de "Kor" en este caso para transacciones de prueba ... Tenemos algo así como enrutamiento: "Kor" sabe a qué sistema de pago enviar - enviamos a un sistema de pago falso, que simplemente da una respuesta http y eso es todo .
P: - Por favor, dígame, ¿tenía la aplicación escrita en un gran monolito o la recortó en algunos servicios o incluso en microservicios?
: - No tenemos un monolito, por supuesto, tenemos una aplicación orientada a servicios. Tenemos una broma de que tenemos un servicio de monolitos: son realmente bastante grandes. Al llamar a microservicios, este lenguaje no se aparta de la palabra, pero estos son los servicios dentro de los cuales trabajan los trabajadores de máquinas distribuidas.
Si el servicio en el servidor se ve comprometido ...
P: - Entonces tengo la siguiente pregunta. Incluso si fuera un monolito, aún dijiste que tienes muchos de estos servidores instantáneos, todos procesan los datos en principio, y la pregunta es: “Si uno de los servidores instantáneos o la aplicación, cualquier enlace en particular está comprometido ¿Tienen algún tipo de control de acceso? ¿Cuál de ellos puede hacer qué? ¿A quién contactar, para qué datos?

EK: Sí, por supuesto. Los requisitos de seguridad son bastante serios. En primer lugar, tenemos tráfico de datos abierto, y los puertos son solo aquellos en los que anticipamos el tráfico por adelantado. Si el componente se comunica con la base de datos (por ejemplo, "Muskul") en 5-4-3-2, solo se abrirán 5-4-3-2 y otros puertos, otras direcciones de tráfico no estarán disponibles. Además, debemos entender que en producción tenemos unos 10 bucles de seguridad diferentes. E incluso si la aplicación se vio comprometida de alguna manera, Dios no lo quiera, un atacante no podrá acceder a la consola de administración del servidor, porque esta es otra zona de seguridad de la red.
P: - Y en este contexto, estoy más interesado en el momento en que tiene algunos contratos con los servicios: qué pueden hacer, a través de qué "acciones" pueden contactarse entre sí ... Y en el flujo normal, algunos servicios específicos preguntan qué una serie, una lista de "acción" en otra. No parecen recurrir a otros en una situación normal, y tienen otras áreas de responsabilidad. Si uno de ellos se ve comprometido, ¿podrá tirar de la "acción" de ese servicio? ..
EK: - Entiendo. Si en una situación normal con otro servidor generalmente se permitía la comunicación, entonces sí. Según el contrato de SLA, no controlamos que solo se le permitan las primeras 3 "acciones", y no se le permiten 4 "acciones". Probablemente esto sea redundante para nosotros, porque tenemos un sistema de protección de 4 niveles, en principio, para circuitos. Preferimos defender con contornos en lugar de a nivel de los interiores.
Cómo funcionan Visa, MasterCard y Sberbank
P: - Quiero aclarar un momento acerca de cambiar a un usuario de un centro de datos a otro. Hasta donde yo sé, "Visa" y "MasterCard" funcionan en el protocolo síncrono binario 8583, hay mezclas. Y quería saber, ahora me refiero a cambiar: ¿es directamente "Visa" y "MasterCard" o a los sistemas de pago, a los procesamientos?
EK: - Depende de las mezclas. Mezclas que tenemos en un centro de datos.
P: - En términos generales, ¿tiene un punto de conexión?
: - "Vise" y "MasterCard" - sí. Solo porque "Visa" y "MasterCard" requieren inversiones bastante serias en infraestructura para celebrar contratos separados para recibir un segundo par de mezclas, por ejemplo. Están reservados dentro del marco de un centro de datos, pero si Dios no lo permite, el centro de datos donde las mezclas para conectarse a "Visa" y "MasterCard" están muertas, entonces tendremos una conexión con "Visa" y "MasterCard" perdido ...
P: - ¿Cómo se pueden reservar? ¡Sé que "Visa" solo permite mantener una conexión en principio!
EK: - Ellos mismos suministran equipos. En cualquier caso, recibimos equipos que son internamente redundantes.
P: - Es decir, ¿el rack de su Connects Orange? ..
CE: Sí.
P: - Pero como en este caso: si su centro de datos desaparece, ¿debería usarlo más? ¿O solo se trata de detener el tráfico?
CE: - No. En este caso, simplemente cambiamos el tráfico a otro canal, que, por supuesto, será más costoso para nosotros, más costoso para los clientes. Pero el tráfico no pasará a través de nuestra conexión directa con la "Visa", "MasterCard", sino a través del "Sberbank" convencional (muy exagerado).
Lamento muchísimo si lastimo a los empleados de Sberbank. Pero según nuestras estadísticas, Sberbank está cayendo con mayor frecuencia de los bancos rusos. En menos de un mes, algo no se ha caído en Sberbank.

Un poco de publicidad :)
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos VPS basado en la nube para desarrolladores desde $ 4.99 , un análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?