Continuamos lidiando con el trabajo de GraalVM, y esta vez tenemos una traducción del artículo de Aleksandar Prokopec "Bajo el capó de las optimizaciones de GraalVM JIT", publicado originalmente en el blog en Medium . El artículo tiene algunos enlaces interesantes, luego trataremos de traducir estos artículos también.

La última vez en Medium, vimos los problemas de rendimiento de la API de Java Streams en GraalVM en comparación con Java HotSpot VM. GraalVM se caracteriza por un alto rendimiento, y en esos experimentos logramos una aceleración de 1.7 a 5 veces. Por supuesto, los valores específicos de la ganancia de rendimiento siempre dependerán del código que ejecute y de los datos de carga, por lo que antes de sacar conclusiones, debe intentar ejecutar su código en GraalVM usted mismo.
En este artículo, profundizaremos en el interior de GraalVM y veremos cómo ocurre la compilación JIT.
Optimizaciones JIT en GraalVM
Echemos un vistazo a una serie de optimizaciones de alto nivel que utiliza el compilador GraalVM. En este artículo tocaremos solo las optimizaciones más interesantes junto con ejemplos específicos de su trabajo. Si desea profundizar, una buena visión general de las optimizaciones del compilador GraalVM se encuentra en un trabajo titulado "Hacer que las operaciones de recopilación sean óptimas con una compilación JIT agresiva" .
En línea
Si no toca el ensamblaje antes de tiempo, entonces la mayoría de los compiladores JIT en máquinas virtuales modernas hacen análisis internos. Esto significa que en cada momento particular hay un análisis de un método. Por esta razón, el análisis intraprocedural es mucho más rápido que el análisis interprocedural de todo el programa, que generalmente no tiene tiempo para completarse en el tiempo asignado para el trabajo del compilador JIT. En un compilador que utiliza optimizaciones intraprocesales (por ejemplo, optimizando un método a la vez), una de las optimizaciones fundamentales más importantes es la integración. La alineación es importante porque aumenta efectivamente el método, lo que significa que el compilador puede ver más oportunidades para optimizar simultáneamente varios fragmentos de código utilizados en métodos aparentemente no relacionados.
Tomemos, por ejemplo, el método volleyballStars de un artículo anterior:
@Benchmark public double volleyballStars() { return Arrays.stream(people) .map(p -> new Person(p.hair, p.age + 1, p.height)) .filter(p -> p.height > 198) .filter(p -> p.age >= 18 && p.age <= 21) .mapToInt(p -> p.age) .average().getAsDouble(); }
En este diagrama, vemos partes de la representación intermedia (IR) de este método en GraalVM, en el momento inmediatamente posterior al análisis del correspondiente código de bytes de Java.

Puede pensar en este IR como una especie de árbol de sintaxis abstracta con esteroides; gracias a él, algunas optimizaciones son más fáciles de realizar. No importa cómo funciona este IR, pero si desea comprender este tema más profundamente, puede consultar un documento llamado "Graal IR: una representación intermedia declarativa extensible" .
La conclusión principal aquí es que el flujo de control del método indicado por los nodos amarillos del gráfico y las líneas rojas ejecuta secuencialmente los métodos de la interfaz Stream : Stream.filter , Stream.mapToInt , IntStream.average . Al no tener un conocimiento exacto de lo que está en el código de estos métodos, el compilador no puede simplificar el método, ¡y aquí la recuperación viene al rescate!
Una transformación llamada en línea es algo muy comprensible: simplemente busca lugares para llamar métodos y los reemplaza con el cuerpo del método en línea correspondiente, los incrusta dentro. Echemos un vistazo al IR del método volleyballStars después de incluir parte de los métodos. IntStream.average se IntStream.average la parte que sigue a la llamada IntStream.average :

El diagrama muestra que la llamada a getAsDouble (número de nodo 71) ha desaparecido del IR. Tenga en cuenta que el método getAsDouble del objeto getAsDouble devuelto por IntStream.average (la última llamada en el método volleyballStars ) se define en el JDK de la siguiente manera:
public double getAsDouble() { if (!isPresent) { throw new NoSuchElementException("No value present"); } return value; }
Aquí podemos encontrar la carga del campo isPresent (número de nodo 190, LoadField ) y leer el campo de value . Sin embargo, no queda ningún rastro de la excepción NoSuchElementException y no hay más código que la arroje.
Esto se debe a que el compilador GraalVM adivina: el método volleyballStars nunca arrojará una excepción. Este conocimiento generalmente no está disponible durante la compilación getAsDouble : se puede llamar desde muchos lugares diferentes en el programa, y en algún otro caso la excepción seguirá funcionando. Sin embargo, en un método particular de volleyballStars , es poco probable que ocurra una excepción porque el conjunto de estrellas potenciales de voleibol nunca está vacío. Por esta razón, GraalVM elimina la rama e inserta FixedGuard , un nodo que no optimiza el código en caso de violación de nuestra suposición. Este es un ejemplo bastante minimalista, y en la vida real hay casos mucho más complicados de cómo la alineación ayuda a otras optimizaciones.
Sabemos que el árbol de llamadas del programa suele ser muy profundo o tal vez incluso interminable. Por lo tanto, es necesario detener la alineación en algún momento: tiene restricciones muy específicas sobre el tiempo de funcionamiento y el tamaño de la memoria. Sabiendo esto, queda claro: determinar qué y cuándo en línea es muy difícil.
Revestimiento polimórfico
La alineación solo funciona si el compilador puede determinar el método específico al que se dirige la operación de llamada al método. Pero en Java, generalmente hay muchas llamadas indirectas para aquellos métodos cuyas implementaciones son desconocidas en estática, que se buscan en tiempo de ejecución mediante el envío virtual.
Por ejemplo, tome el método IntStream.average . Su implementación típica se ve así:
@Override public final OptionalDouble average() { long[] avg = collect( () -> new long[2], (ll, i) -> { ll[0]++; ll[1] += i; }, (ll, rr) -> { ll[0] += rr[0]; ll[1] += rr[1]; }); return avg[0] > 0 ? OptionalDouble.of((double) avg[1] / avg[0]) : OptionalDouble.empty(); }
¡No dejes que la aparente simplicidad del código te engañe! Este método se define en términos de llamadas por collect , y la magia sucede aquí. El árbol de llamadas de este método (por ejemplo, la jerarquía de llamadas) crece rápidamente a medida que profundizamos en la collect . Solo eche un vistazo a este diagrama:
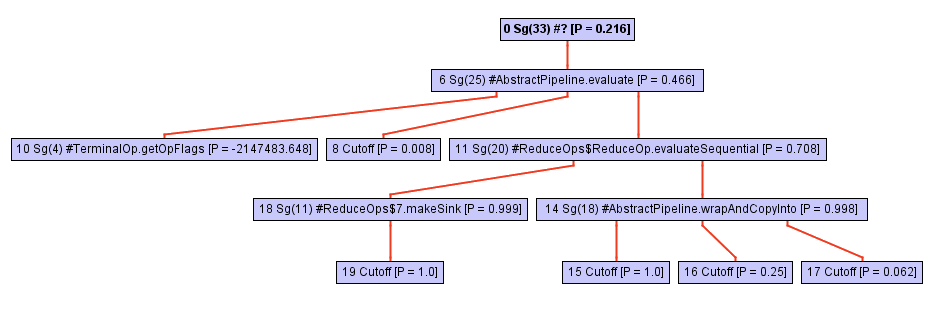
Comenzando desde algún punto en el proceso de atravesar el árbol de llamadas, el inliner descansa contra la llamada opWrapSink del marco de opWrapSink Java, que es un método abstracto:

abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
Por lo general, un inliner no irá más allá, porque es una llamada indirecta. La determinación de un método específico ocurrirá solo durante la ejecución del programa, y ahora el inlayner simplemente no sabe en qué continuará trabajando.
En el caso de GraalVM, sucede algo más: guarda un perfil del tipo del método de destino para cada punto de llamada indirecta. Este perfil es esencialmente solo una tabla que indica con qué frecuencia se wrapSink cada una de las implementaciones de wrapSink . En nuestro caso, el perfil conoce tres implementaciones diferentes en clases anónimas: ReferencePipeline$2 , ReferencePipeline$3 , ReferencePipeline$4 . Estas implementaciones se llaman con una probabilidad del 50%, 25% y 25%, respectivamente.
0.500000: Ljava/util/stream/ReferencePipeline$2; 0.250000: Ljava/util/stream/ReferencePipeline$4; 0.250000: Ljava/util/stream/ReferencePipeline$3; notRecorded: 0.000000
Esta información proporciona una ayuda invaluable al compilador, permitiéndole generar un switch tipo : una breve switch que verifica el tipo del método en tiempo de ejecución, luego llama a un método específico para cada uno de los casos anteriores. La imagen a continuación muestra una parte de la vista intermedia que muestra el interruptor de tipo (tres if nodos) con una verificación para ver si el tipo de destinatario es alguien de ReferencePipeline$2 , ReferencePipeline$3 o ReferencePipeline$4 . Cada llamada directa en la ramificación exitosa de cada una de las comprobaciones de InstanceOf ahora puede estar en línea o conectarle algunas optimizaciones adicionales. Si ninguno de los tipos pasa la prueba, el código se desoptimiza en el nodo Deopt (como alternativa, puede ejecutar el despacho virtual).

Si desea comprender más profundamente la alineación polimórfica, le recomiendo el trabajo clásico sobre este tema, "Incorporación de métodos virtuales" .
Análisis de escape parcial
Volvamos a nuestro ejemplo de voleibol. Observe que ninguno de los objetos Person asignados dentro de la lambda pasada a la función de map escapa del alcance del método volleyballStars . En otras palabras, en el momento en que finaliza el método volleyballStars , no existe tal área de memoria que apunte a objetos de tipo Person . En particular, el registro del valor getHeight se usa además solo para el filtrado de altura.
En algún momento durante la compilación del método volleyballStars , llegamos al IR que se muestra en el diagrama a continuación. El bloque que comienza con el nodo Begin -1621 comienza con la asignación del objeto Person (en el nodo Alloc ), que se inicializa tanto con el valor del campo de age con un incremento de 1 como con el valor anterior del campo de height . El campo de height se lee previamente en el nodo LoadField -1539. El resultado de la asignación se encapsula en AllocatedObject -2137 y se envía a la llamada al método accept -1625. El compilador no puede hacer nada más en este momento: desde su punto de vista, el objeto escapó del método volleyballStars . ( Nota del traductor: "escapar de un objeto" se llama "escape" en inglés, de ahí que el nombre de la optimización sea "análisis de escape" ).

Después de eso, el compilador decide alinear la llamada de accept , esto parece razonable. Como resultado, llegamos al siguiente IR:
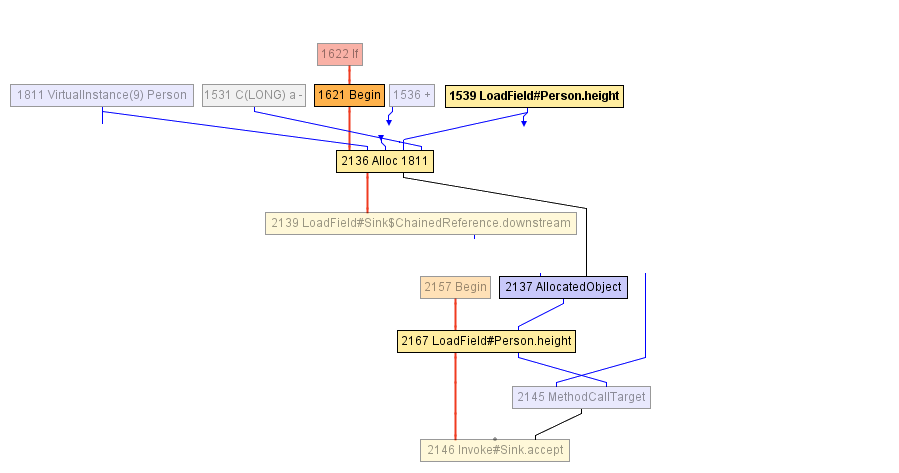
Y aquí el compilador JIT comienza un análisis de escape parcial: se da cuenta de que AllocatedObject usa solo para leer el campo de height (recuperar, la height usa solo en la condición de filtrado, verifique que la altura sea mayor que 198). Por lo tanto, el compilador puede reasignar la lectura del campo de height -2167 para trabajar directamente con el nodo previamente escrito en el objeto Person (nodo Alloc -2136), y este es nuestro LoadField -1539. Además, el nodo Alloc aquí en adelante no va a la entrada de ningún otro nodo, por lo que simplemente puede eliminarlo: ¡este es un código muerto!
Esta optimización es, de hecho, la razón principal por la cual el ejemplo de volleyballStars experimentó una aceleración de cinco veces después de cambiar a GraalVM. Aunque todos los objetos Person no son necesarios y se descartan inmediatamente después de la creación, aún deben asignarse en el montón, su memoria aún debe inicializarse. El análisis de escape parcial le permite eliminar asignaciones o posponerlas moviéndolas a esas ramas de código donde los objetos realmente se escapan y que suceden con mucha menos frecuencia.
Puede obtener una comprensión más profunda del análisis de escape parcial en un documento llamado Análisis de escape parcial y reemplazo escalar para Java .
Resumen
En este artículo, analizamos tres optimizaciones de GraalVM: alineación, alineación polimórfica y análisis de escape parcial. Hay muchas más optimizaciones diferentes: promoción y división de ciclos, duplicación de rutas, numeración de valores globales, convolución de constantes, eliminación de código muerto, ejecución especulativa, etc.
Si desea obtener más información sobre cómo funciona GraalVM, no dude en abrir la página de publicación . Si desea asegurarse de que GraalVM pueda acelerar su código, puede descargar los archivos binarios y probarlo usted mismo.
Del traductor: materiales adicionales
En las conferencias, JPoint y Joker a menudo hablan sobre GraalVM. Por ejemplo, en el último JPoint 2019, Thomas Wuerthinger (Director de Investigación de Oracle Labs, responsable de GraalVM) y Oleg Shelaev, uno de los dos evangelistas tecnológicos oficiales, nos visitaron.
Puedes ver estos y otros videos en nuestro canal de YouTube:
Le recordamos que el próximo JPoint se llevará a cabo del 15 al 16 de mayo de 2020 en Moscú, y que los boletos ya se pueden comprar en el sitio web oficial .