Hola a todos! Soy un desarrollador de backend, escribiendo microservicios en Java + Spring. Trabajo en uno de los equipos internos de desarrollo de productos de Tinkoff.

Nuestro equipo a menudo plantea la cuestión de la optimización de consultas en el DBMS. Siempre quieres un poco más rápido, pero no siempre puedes sobrevivir con índices bien diseñados; tienes que buscar algunas soluciones. Durante una de estas deambulaciones por la red en busca de optimizaciones razonables al trabajar con la base de datos, encontré el blog infinitamente útil de Marcus Vinand , autor de SQL Performance Explained. Este es el tipo muy raro de blog donde puedes leer todos los artículos seguidos.
Quiero traducirle un breve artículo de Marcus. Se puede llamar, en cierta medida, un manifiesto que busca llamar la atención sobre el tema antiguo pero aún relevante del rendimiento de la operación de compensación de acuerdo con el estándar SQL.
En algunos lugares, complementaré al autor con explicaciones y comentarios. Designaré todos los lugares como "aprox." Para mayor claridad.
Pequeña introducción
Creo que muchas personas saben lo problemático e inhibitorio que es trabajar con selecciones paginales a través de la compensación. ¿Pero sabías que puede ser simplemente reemplazado por un diseño más productivo?
Entonces, la palabra clave offset le dice a la base de datos que omita las primeras n entradas en la solicitud. Sin embargo, la base de datos todavía tiene que leer estos primeros n registros del disco y en el orden especificado (nota: aplique la clasificación si se especifica uno), y solo después de eso será posible devolver registros a partir de n + 1 en adelante. Lo más interesante es que el problema no está en la implementación concreta en el DBMS, sino en la definición inicial de acuerdo con el estándar:
... las filas se ordenan primero de acuerdo con la <orden por cláusula> y luego se limitan al soltar el número de filas especificadas en la <cláusula de compensación de resultado> desde el principio ...
-SQL: 2016, Parte 2, 4.15.3 Tablas derivadas (nota: ahora el estándar más utilizado)
El punto clave aquí es que el desplazamiento toma un solo parámetro: la cantidad de registros que se omiten, y eso es todo. Siguiendo esta definición, un DBMS solo puede obtener todos los registros y luego descartar los innecesarios. Obviamente, tal definición de desplazamiento te obliga a hacer un trabajo extra. Y ni siquiera importa si es SQL o NoSQL.
Un poco mas de dolor
Los problemas de compensación no terminan ahí, y aquí está el por qué. Si otra operación inserta un nuevo registro entre la lectura de dos páginas de datos del disco, ¿qué sucederá en este caso?
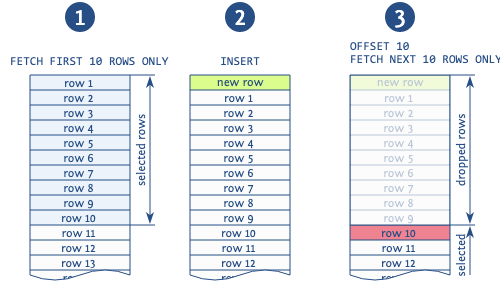
Cuando se usa el desplazamiento para omitir registros de páginas anteriores, en la situación de agregar un nuevo registro entre las operaciones de lectura de diferentes páginas, lo más probable es que obtenga duplicados (nota: esto es posible cuando leemos página por página usando el orden por construcción, luego en el medio de nuestra salida puede obtener un nuevo registro).
La figura representa claramente tal situación. La base lee los primeros 10 registros, después de lo cual se inserta un nuevo registro, que cambia todos los registros de lectura en 1. Luego, la base toma una nueva página de los siguientes 10 registros y comienza no desde el 11 como debería, sino desde el 10, duplicando este registro. Hay otras anomalías asociadas con el uso de esta expresión, pero esta es la más común.
Como ya hemos descubierto, estos no son problemas de un DBMS en particular o su implementación. El problema es la definición de paginación según el estándar SQL. Le decimos al DBMS qué página obtener o cuántos registros omitir. La base simplemente no puede optimizar dicha solicitud, ya que hay muy poca información para esto.
También vale la pena aclarar que este no es un problema específico de palabras clave, sino más bien la semántica de consultas. Hay varias sintaxis que son idénticas en términos de problemática:
- La palabra clave offset, como se mencionó anteriormente.
- La construcción de las dos palabras clave limit [offset] (aunque el límite en sí mismo no es tan malo).
- Filtrado por límites inferiores según la numeración de línea (por ejemplo, row_number (), rownum, etc.).
Todas estas expresiones simplemente dicen cuántas líneas omitir, sin información adicional o contexto.
Más adelante en este artículo, la palabra clave offset se usa como una generalización de todas estas opciones.
La vida sin una compensación
Ahora imagine cómo sería nuestro mundo sin todos estos problemas. Resulta que la vida sin desplazamiento no es tan complicada: puede seleccionar solo aquellas líneas que no hemos visto (nota: es decir, aquellas que no estaban en la última página) usando la condición en dónde.
En este caso, nos basamos en el hecho de que las selecciones se ejecutan en un conjunto ordenado (buen orden anterior). Como tenemos un conjunto ordenado, podemos usar un filtro bastante simple para obtener solo los datos que están detrás del último registro de la página anterior:
SELECT ... FROM ... WHERE ... AND id < ?last_seen_id ORDER BY id DESC FETCH FIRST 10 ROWS ONLY
Ese es todo el principio de este enfoque. Por supuesto, al ordenar por muchas columnas, todo se vuelve más divertido, pero la idea es la misma. Es importante tener en cuenta que esta construcción es aplicable a muchas soluciones N o S Q L.
Este enfoque se denomina método de búsqueda o paginación de conjunto de claves. Resuelve el problema con un resultado flotante (nota: la situación con la escritura entre lecturas de página, descrita anteriormente) y, por supuesto, que todos amamos, funciona más rápido y más estable que el desplazamiento clásico. La estabilidad radica en el hecho de que el tiempo de procesamiento de la consulta no aumenta en proporción al número de la tabla solicitada (nota: si desea obtener más información sobre el trabajo de los diferentes enfoques de paginación, puede consultar la presentación del autor . Allí también puede encontrar puntos de referencia comparativos utilizando diferentes métodos).
Una de las diapositivas dice que la paginación de teclas, por supuesto, no es omnipotente: tiene sus propias limitaciones. Lo más significativo: no tiene la capacidad de leer páginas aleatorias (nota: inconsistentemente). Sin embargo, en la era del desplazamiento sin fin (nota: en el extremo frontal), este no es un problema. En cualquier caso, especificar el número de página para un clic es una mala decisión al desarrollar una interfaz de usuario (nota: opinión del autor del artículo).
¿Qué hay de las herramientas?
La paginación clave a menudo no es adecuada debido a la falta de soporte instrumental para este método. La mayoría de las herramientas de desarrollo, incluidos varios marcos, no dan la opción de cómo se realizará la paginación.
La situación se ve agravada por el hecho de que el método descrito requiere soporte de extremo a extremo en las tecnologías utilizadas, desde el DBMS hasta la ejecución de la solicitud AJAX en el navegador con desplazamiento sin fin. En lugar de especificar solo el número de página, ahora debe especificar el conjunto de claves para todas las páginas a la vez.
Sin embargo, el número de marcos que admiten la paginación clave está creciendo gradualmente. Esto es lo que hay en este momento:
(Nota: algunos enlaces se eliminaron debido al hecho de que en el momento de la traducción algunas bibliotecas no se actualizaron de 2017-2018. Si está interesado, puede consultar la fuente).
Es en este momento que se necesita su ayuda. Si está desarrollando o apoyando un marco que de alguna manera utiliza la paginación, le pido, insto, le ruego que haga un soporte nativo para la paginación clave. Si tiene preguntas o necesita ayuda, con gusto lo ayudaré ( foro , Twitter , formulario de contacto ) (nota: en mi experiencia con Marcus, puedo decir que está realmente entusiasmado con la difusión de este tema).
Si utiliza soluciones preparadas que cree que son dignas de soporte para la paginación de claves, cree una solicitud o incluso ofrezca una solución preparada, si es posible. También puede especificar este artículo en el enlace.
Conclusión
La razón por la cual un enfoque tan simple y útil como la paginación clave no está generalizado no es que sea difícil en la implementación técnica o requiera un gran esfuerzo. La razón principal es que muchos están acostumbrados a ver y trabajar con desplazamiento: este enfoque está dictado por el estándar mismo.
Como resultado, pocas personas piensan en cambiar el enfoque de la paginación, y debido a esto, el soporte instrumental de los marcos y las bibliotecas se está desarrollando deficientemente. Por lo tanto, si está cerca de la idea y el objetivo de la paginación sin complicaciones, ¡ayude a difundirla!
Fuente: https://use-the-index-luke.com/no-offset
Publicado por: Markus Winand