Los usuarios de ClickHouse ya saben que su mayor ventaja es su procesamiento de alta velocidad de consultas analíticas. Pero afirmaciones como esta deben confirmarse con pruebas de rendimiento confiables. De eso es de lo que queremos hablar hoy.
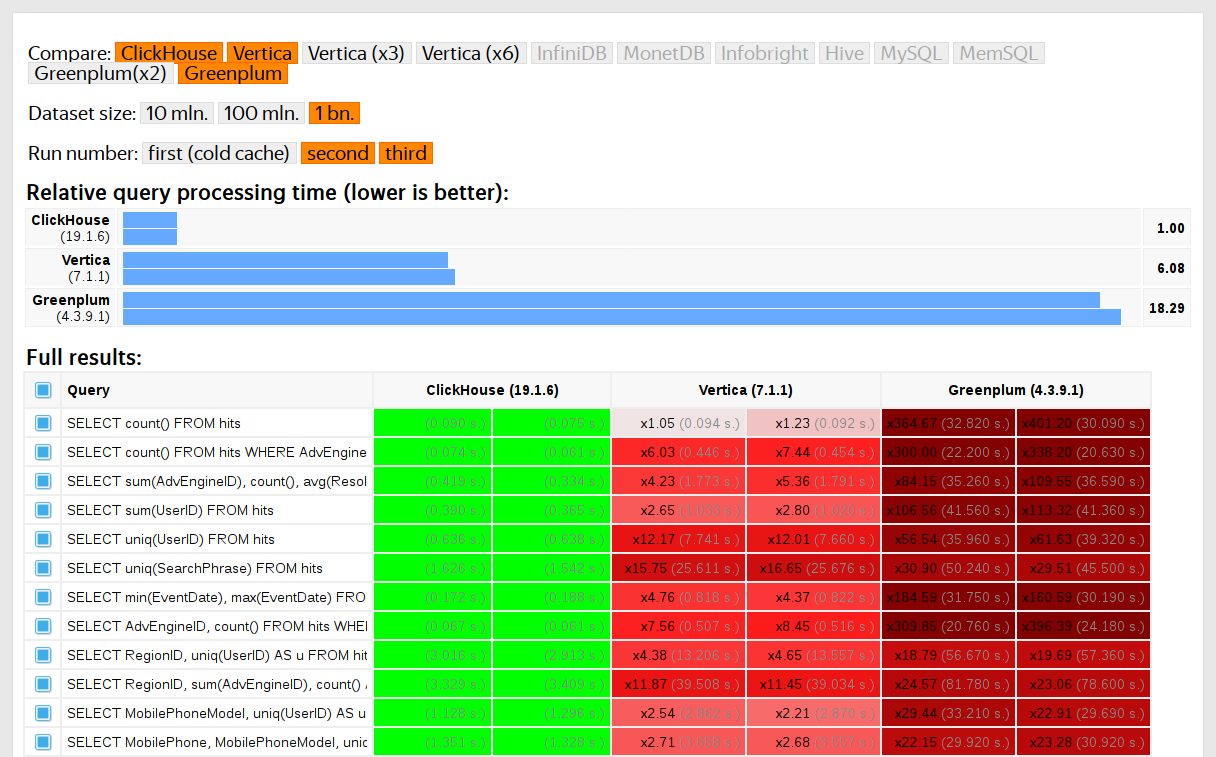
Comenzamos a realizar pruebas en 2013, mucho antes de que el producto estuviera disponible como código abierto. En aquel entonces, al igual que ahora, nuestra principal preocupación era la velocidad de procesamiento de datos en Yandex.Metrica. Habíamos estado almacenando esos datos en ClickHouse desde enero de 2009. Parte de los datos se habían escrito en una base de datos a partir de 2012, y parte se convirtió de
OLAPServer y Metrage (estructuras de datos utilizadas anteriormente por Yandex.Metrica). Para las pruebas, tomamos el primer subconjunto al azar de los datos para mil millones de páginas vistas. Yandex.Metrica no tenía ninguna consulta en ese momento, por lo que se nos ocurrieron consultas que nos interesaron, utilizando todas las formas posibles para filtrar, agregar y clasificar los datos.
El rendimiento de ClickHouse se comparó con sistemas similares como Vertica y MonetDB. Para evitar sesgos, las pruebas fueron realizadas por un empleado que no había participado en el desarrollo de ClickHouse, y los casos especiales en el código no se optimizaron hasta que se obtuvieron todos los resultados. Utilizamos el mismo enfoque para obtener un conjunto de datos para pruebas funcionales.
Después de que ClickHouse se lanzó como código abierto en 2016, la gente comenzó a cuestionar estas pruebas.
Deficiencias de las pruebas en datos privados
Nuestras pruebas de rendimiento:
- No se pueden reproducir de forma independiente porque usan datos privados que no se pueden publicar. Algunas de las pruebas funcionales no están disponibles para usuarios externos por la misma razón.
- Necesita más desarrollo. El conjunto de pruebas debe ampliarse sustancialmente para aislar los cambios de rendimiento en partes individuales del sistema.
- No se ejecute por compromiso o para solicitudes de extracción individuales. Los desarrolladores externos no pueden verificar su código en busca de regresiones de rendimiento.
Podríamos resolver estos problemas descartando los viejos exámenes y escribiendo nuevos basados en datos abiertos, como
los datos de vuelo de los EE. UU. Y
los viajes en taxi en Nueva York . O podríamos usar puntos de referencia como TPC-H, TPC-DS y
Star Schema Benchmark . La desventaja es que estos datos son muy diferentes de los datos de Yandex.Metrica, y preferimos mantener las consultas de prueba.
Por qué es importante usar datos reales
El rendimiento solo debe probarse en datos reales de un entorno de producción. Veamos algunos ejemplos.
Ejemplo 1Supongamos que llena una base de datos con números pseudoaleatorios distribuidos uniformemente. La compresión de datos no funcionará en este caso, aunque la compresión de datos es esencial para las bases de datos analíticas. No existe una solución de plata para el desafío de elegir el algoritmo de compresión correcto y la forma correcta de integrarlo en el sistema, ya que la compresión de datos requiere un compromiso entre la velocidad de compresión y descompresión y la potencial eficiencia de compresión. Pero los sistemas que no pueden comprimir datos son perdedores garantizados. Si sus pruebas usan números pseudoaleatorios distribuidos uniformemente, este factor se ignora y los resultados se distorsionarán.
En pocas palabras: los datos de prueba deben tener una relación de compresión realista.
Cubrí la optimización de los algoritmos de compresión de datos ClickHouse en
una publicación anterior .
Ejemplo 2Digamos que estamos interesados en la velocidad de ejecución de esta consulta SQL:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Esta es una consulta típica para Yandex.Metrica. ¿Qué afecta la velocidad de procesamiento?
- Cómo se ejecuta GROUP BY.
- Qué estructura de datos se utiliza para calcular la función agregada uniq.
- Cuántos RegionID diferentes hay y cuánta RAM requiere cada estado de la función uniq.
Pero otro factor importante es que la cantidad de datos se distribuye de manera desigual entre las regiones. (Probablemente sigue una ley de potencia. Pongo la distribución en un gráfico log-log, pero no puedo decir con certeza). Si este es el caso, es importante que los estados de la función agregada uniq con menos valores utilicen Muy poca memoria. Cuando hay muchas claves de agregación diferentes, cada byte cuenta. ¿Cómo podemos obtener datos generados que tengan todas estas propiedades? La solución obvia es usar datos reales.
Muchos DBMS implementan la estructura de datos HyperLogLog para una aproximación de COUNT (DISTINCT), pero ninguno de ellos funciona muy bien porque esta estructura de datos utiliza una cantidad fija de memoria. ClickHouse tiene una función que utiliza
una combinación de tres estructuras de datos diferentes , según el tamaño del conjunto de datos.
En pocas palabras: los datos de prueba deben representar las propiedades de distribución de los datos reales lo suficientemente bien, lo que significa cardinalidad (número de valores distintos por columna) y cardinalidad entre columnas (número de valores diferentes contados en varias columnas diferentes).
Ejemplo 3En lugar de probar el rendimiento del DBMS ClickHouse, tomemos algo más simple, como las tablas hash. Para las tablas hash, es esencial elegir la función hash correcta. Esto no es tan importante para std :: unordered_map, porque es una tabla hash basada en el encadenamiento y se usa un número primo como tamaño de matriz. La implementación estándar de la biblioteca en GCC y Clang usa una función hash trivial como la función hash predeterminada para los tipos numéricos. Sin embargo, std :: unordered_map no es la mejor opción cuando buscamos la velocidad máxima. Con una tabla hash de direccionamiento abierto, no podemos usar una función hash estándar. Elegir la función hash correcta se convierte en el factor decisivo.
Es fácil encontrar pruebas de rendimiento de la tabla hash utilizando datos aleatorios que no tienen en cuenta las funciones hash utilizadas. También hay muchas pruebas de función hash que se centran en la velocidad de cálculo y ciertos criterios de calidad, a pesar de que ignoran las estructuras de datos utilizadas. Pero el hecho es que las tablas hash y HyperLogLog requieren diferentes criterios de calidad de función hash.
Puede obtener más información sobre esto en
"Cómo funcionan las tablas hash en ClickHouse" (presentación en ruso). La información está un poco desactualizada, ya que no cubre las
tablas suizas .
Desafío
Nuestro objetivo es obtener datos para probar el rendimiento que tiene la misma estructura que Yandex.Metrica con todas las propiedades que son importantes para los puntos de referencia, pero de tal manera que no haya rastros de usuarios reales del sitio web en estos datos. En otras palabras, los datos deben ser anónimos y aún preservar:
- Relación de compresión
- Cardinalidad (el número de valores distintos).
- Cardinalidad mutua entre varias columnas diferentes.
- Propiedades de las distribuciones de probabilidad que se pueden usar para el modelado de datos (por ejemplo, si creemos que las regiones se distribuyen de acuerdo con una ley de potencia, entonces el exponente, el parámetro de distribución, debería ser aproximadamente el mismo para los datos artificiales y los reales).
¿Cómo podemos obtener una relación de compresión similar para los datos? Si se usa LZ4, las subcadenas en datos binarios deben repetirse aproximadamente a la misma distancia y las repeticiones deben tener aproximadamente la misma longitud. Para ZSTD, la entropía por byte también debe coincidir.
El objetivo final es crear una herramienta disponible públicamente que cualquiera pueda usar para anonimizar sus conjuntos de datos para su publicación. Esto nos permitiría depurar y probar el rendimiento en los datos de otras personas similares a nuestros datos de producción. También nos gustaría que los datos generados sean interesantes.
Sin embargo, estos son requisitos muy poco definidos y no estamos planeando redactar una declaración o especificación formal del problema para esta tarea.
Posibles soluciones
No quiero que parezca que este problema es particularmente importante. Nunca se incluyó realmente en la planificación y nadie tenía intenciones de trabajar en ello. Solo esperaba que surgiera una idea algún día, y de repente estaría de buen humor y podría posponer todo lo demás hasta más tarde.
Modelos probabilísticos explícitos
La primera idea es tomar cada columna de la tabla y encontrar una familia de distribuciones de probabilidad que la modele, luego ajustar los parámetros en función de las estadísticas de datos (ajuste del modelo) y usar la distribución resultante para generar nuevos datos. Se podría utilizar un generador de números pseudoaleatorio con una semilla predefinida para obtener un resultado reproducible.
Las cadenas de Markov podrían usarse para campos de texto. Este es un modelo familiar que podría implementarse de manera efectiva.
Sin embargo, requeriría algunos trucos:
- Queremos preservar la continuidad de las series de tiempo. Esto significa que para algunos tipos de datos, necesitamos modelar la diferencia entre los valores vecinos, en lugar del valor en sí.
- Para modelar la "cardinalidad conjunta" de columnas también tendremos que reflejar explícitamente las dependencias entre columnas. Por ejemplo, generalmente hay muy pocas direcciones IP por ID de usuario, por lo que para generar una dirección IP usaríamos un valor hash de la ID de usuario como semilla y también agregaríamos una pequeña cantidad de otros datos pseudoaleatorios.
- No estamos seguros de cómo expresar la dependencia de que el mismo usuario visita con frecuencia las URL con dominios coincidentes aproximadamente al mismo tiempo.
Todo esto se puede escribir en un "script" de C ++ con las distribuciones y dependencias codificadas. Sin embargo, los modelos de Markov se obtienen de una combinación de estadísticas con suavizado y adición de ruido. Comencé a escribir un guión como este, pero después de escribir modelos explícitos para diez columnas, se volvió insoportablemente aburrido, y la tabla de "hits" en Yandex. Métrica tenía más de 100 columnas en 2012.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Este enfoque fue un fracaso. Si me hubiera esforzado más, tal vez el guión ya estaría listo.
Ventajas:
Desventajas
- Gran cantidad de trabajo requerido.
- La solución solo se aplica a un tipo de datos.
Y preferiría una solución más general que se pueda utilizar para los datos de Yandex.Metrica, así como para ofuscar cualquier otro dato.
En cualquier caso, esta solución podría mejorarse. En lugar de seleccionar modelos manualmente, podríamos implementar un catálogo de modelos y elegir el mejor entre ellos (mejor ajuste más alguna forma de regularización). O tal vez podríamos usar modelos de Markov para todo tipo de campos, no solo para texto. Las dependencias entre los datos también podrían extraerse automáticamente. Esto requeriría calcular la
entropía relativa (cantidad relativa de información) entre columnas. Una alternativa más simple es calcular las cardinalidades relativas para cada par de columnas (algo así como "cuántos valores diferentes de A hay en promedio para un valor fijo B"). Por ejemplo, esto dejará en claro que URLDomain depende completamente de la URL, y no al revés.
Pero también rechacé esta idea, porque hay muchos factores a considerar y tomaría demasiado tiempo escribirlos.
Redes neuronales
Como ya he mencionado, esta tarea no ocupaba un lugar destacado en la lista de prioridades: nadie pensaba siquiera en tratar de resolverla. Pero por suerte, nuestro colega Ivan Puzirevsky enseñaba en la Escuela Superior de Economía. Me preguntó si tenía algún problema interesante que funcionara como temas de tesis adecuados para sus alumnos. Cuando le ofrecí este, me aseguró que tenía potencial. Así que le entregué este desafío a un buen tipo "fuera de la calle" Sharif (aunque sí tuvo que firmar un NDA para acceder a los datos).
Compartí todas mis ideas con él, pero hice hincapié en que no había restricciones sobre cómo se podría resolver el problema, y una buena opción sería probar enfoques de los que no sé nada, como usar LSTM para generar un volcado de datos de texto. Esto parecía prometedor después de encontrar el artículo
La efectividad irracional de las redes neuronales recurrentes .
El primer desafío es que necesitamos generar datos estructurados, no solo texto. Pero no estaba claro si una red neuronal recurrente podría generar datos con la estructura deseada. Hay dos formas de resolver esto. La primera solución es usar modelos separados para generar la estructura y el "relleno" y solo usar la red neuronal para generar valores. Pero este enfoque fue pospuesto y luego nunca se completó. La segunda solución es simplemente generar un volcado de TSV como texto. La experiencia ha demostrado que algunas de las filas del texto no coincidirán con la estructura, pero estas filas se pueden desechar al cargar los datos.
El segundo desafío es que la red neuronal recurrente genera una secuencia de datos y, por lo tanto, las dependencias en los datos deben seguir en el orden de la secuencia. Pero en nuestros datos, el orden de las columnas puede ser potencialmente inverso a las dependencias entre ellas.
No hicimos nada para resolver este problema.
A medida que se acercaba el verano, tuvimos el primer script de Python en funcionamiento que generó datos. La calidad de los datos parecía decente a primera vista:

Sin embargo, nos encontramos con algunas dificultades:
- El tamaño del modelo es de aproximadamente un gigabyte. Intentamos crear un modelo para datos que tenía un tamaño de varios gigabytes (para empezar). El hecho de que el modelo resultante sea tan grande suscita preocupaciones. ¿Sería posible extraer los datos reales sobre los que se entrenó? Poco probable Pero no sé mucho sobre aprendizaje automático y redes neuronales, y no he leído el código Python de este desarrollador, entonces, ¿cómo puedo estar seguro? Hubo varios artículos publicados en ese momento sobre cómo comprimir las redes neuronales sin pérdida de calidad, pero no se implementó. Por un lado, esto no parece ser un problema grave, ya que podemos optar por no publicar el modelo y simplemente publicar los datos generados. Por otro lado, si se produce un sobreajuste, los datos generados pueden contener alguna parte de los datos de origen.
- En una máquina con una sola CPU, la velocidad de generación de datos es de aproximadamente 100 filas por segundo. Nuestro objetivo era generar al menos mil millones de filas. Los cálculos mostraron que esto no se completaría antes de la fecha de la defensa de la tesis. No tenía sentido usar hardware adicional, porque el objetivo era crear una herramienta de generación de datos que pudiera ser utilizada por cualquier persona.
Sharif trató de analizar la calidad de los datos mediante la comparación de estadísticas. Entre otras cosas, calculó la frecuencia de diferentes caracteres que ocurren en los datos de origen y en los datos generados. El resultado fue sorprendente: los personajes más frecuentes fueron Ð y Ñ.
Sin embargo, no te preocupes por Sharif. Él defendió con éxito su tesis y luego felizmente nos olvidamos de todo.
Mutación de datos comprimidos.
Supongamos que la declaración del problema se ha reducido a un solo punto: necesitamos generar datos que tengan la misma relación de compresión que los datos de origen, y los datos deben descomprimirse a la misma velocidad. ¿Cómo podemos lograr esto? ¡Necesitamos editar bytes de datos comprimidos directamente! Esto nos permite cambiar los datos sin cambiar el tamaño de los datos comprimidos, además, todo funcionará rápido. Quería probar esta idea de inmediato, a pesar de que el problema que resuelve no es el mismo con el que comenzamos. Pero así es siempre.
Entonces, ¿cómo editamos un archivo comprimido? Digamos que solo estamos interesados en LZ4. Los datos comprimidos de LZ4 se componen de secuencias, que a su vez son cadenas de bytes no comprimidos (literales), seguidas de una copia de coincidencia:
- Literales (copie los siguientes N bytes tal como están).
- Coincide con una longitud mínima de repetición de 4 (repita N bytes que estaban en el archivo a una distancia de M).
Datos de origen:
Hello world HelloDatos comprimidos (ejemplo arbitrario):
literals 12 "Hello world " match 5 12 .
En el archivo comprimido, dejamos "coincidir" tal cual y cambiamos los valores de bytes en "literales". Como resultado, después de descomprimir, obtenemos un archivo en el que todas las secuencias repetidas de al menos 4 bytes de longitud también se repiten a la misma distancia, pero consisten en un conjunto diferente de bytes (básicamente, el archivo modificado no contiene un solo byte que fue tomado del archivo fuente).
¿Pero cómo cambiamos los bytes? La respuesta no es obvia, porque además de los tipos de columna, los datos también tienen su propia estructura interna implícita que nos gustaría preservar. Por ejemplo, el texto a menudo se almacena en codificación UTF-8, y queremos que los datos generados también sean válidos UTF-8. Desarrollé una heurística simple que implica cumplir varios criterios:
- Los bytes nulos y los caracteres de control ASCII se mantienen tal cual.
- Algunos caracteres de puntuación permanecen tal cual.
- ASCII se convierte a ASCII y para todo lo demás se conserva el bit más significativo (o se escribe un conjunto explícito de sentencias "if" para diferentes longitudes UTF-8). En una clase de byte, un nuevo valor se elige de manera uniforme al azar.
- Se conservan fragmentos como
https:// , de lo contrario, parece un poco tonto.
La única advertencia de este enfoque es que el modelo de datos son los datos de origen en sí, lo que significa que no se pueden publicar. El modelo solo es apto para generar cantidades de datos no mayores que la fuente. Por el contrario, los enfoques anteriores proporcionan modelos que permiten generar datos de tamaño arbitrario.
Ejemplo para una URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
Los resultados fueron positivos y los datos fueron interesantes, pero algo no estaba del todo bien. Las URL mantenían la misma estructura, pero en algunas de ellas era demasiado fácil reconocer "yandex" o "avito" (un mercado popular en Rusia), así que creé una heurística que intercambia algunos de los bytes.
También hubo otras preocupaciones. Por ejemplo, la información confidencial posiblemente podría residir en una columna FixedString en representación binaria y potencialmente consta de caracteres de control ASCII y puntuación, que decidí preservar. Sin embargo, no tomé en cuenta los tipos de datos.
Otro problema es que si una columna almacena datos en el formato "longitud, valor" (así es como se almacenan las columnas de cadena), ¿cómo me aseguro de que la longitud siga siendo correcta después de la mutación? Cuando traté de arreglar esto, inmediatamente perdí el interés.
Permutaciones aleatorias
Lamentablemente, el problema no se resolvió. Realizamos algunos experimentos, y empeoró. Lo único que quedaba era sentarse sin hacer nada y navegar por la web al azar, ya que la magia había desaparecido. Afortunadamente, me encontré con una página que
explicaba el algoritmo para representar la muerte del personaje principal en el juego Wolfenstein 3D.

La animación está muy bien hecha: la pantalla se llena de sangre. El artículo explica que esto es en realidad una permutación pseudoaleatoria. Una permutación aleatoria de un conjunto de elementos es una transformación biyectiva (uno a uno) escogida al azar del conjunto, o un mapeo donde cada elemento derivado corresponde exactamente a un elemento original (y viceversa). En otras palabras, es una forma de iterar aleatoriamente a través de todos los elementos de un conjunto de datos. Y ese es exactamente el proceso que se muestra en la imagen: cada píxel se llena en orden aleatorio, sin ninguna repetición. Si solo tuviéramos que elegir un píxel aleatorio en cada paso, llevaría mucho tiempo llegar al último.
El juego utiliza un algoritmo muy simple para la permutación pseudoaleatoria llamado registro de desplazamiento de retroalimentación lineal (
LFSR ). Al igual que los generadores de números pseudoaleatorios, las permutaciones aleatorias, o más bien sus familias, pueden ser criptográficamente fuertes cuando se parametrizan mediante una clave. Esto es exactamente lo que necesitamos para la transformación de datos. Sin embargo, los detalles pueden ser más complicados. Por ejemplo, el cifrado criptográficamente fuerte de N bytes a N bytes con una clave predeterminada y un vector de inicialización parece funcionar para una permutación pseudoaleatoria de un conjunto de cadenas de N bytes. De hecho, esta es una transformación uno a uno y parece ser aleatoria. Pero si usamos la misma transformación para todos nuestros datos, el resultado puede ser susceptible al criptoanálisis porque el mismo vector de inicialización y el valor clave se usan varias veces. Esto es similar al modo de operación del
Libro de
códigos electrónico para un cifrado de bloque.
¿Cuáles son las formas posibles de obtener una permutación pseudoaleatoria? Podemos tomar transformaciones simples uno a uno y construir una función compleja que parezca aleatoria. Estas son algunas de mis transformaciones individuales favoritas:
- Multiplicación por un número impar (como un número primo grande) en la aritmética del complemento a dos.
- Xorshift:
x ^= x >> N - CRC-N, donde N es el número de bits en el argumento.
Por ejemplo, tres multiplicaciones y dos operaciones xorshift se utilizan para el finalizador
murmurhash . Esta operación es una permutación pseudoaleatoria. Sin embargo, debo señalar que las funciones hash no tienen que ser uno a uno (incluso hashes de N bits a N bits).
O aquí hay otro
ejemplo interesante
de la teoría de
los números elementales del sitio web de Jeff Preshing.
¿Cómo podemos usar permutaciones pseudoaleatorias para resolver nuestro problema? Podemos usarlos para transformar todos los campos numéricos para poder preservar las cardinalidades y las cardinalidades mutuas de todas las combinaciones de campos. En otras palabras, COUNT (DISTINCT) devolverá el mismo valor que antes de la transformación y, además, con cualquier GROUP BY.
Vale la pena señalar que preservar todas las cardinalidades contradice de alguna manera nuestro objetivo de anonimización de datos. Digamos que alguien sabe que los datos de origen para las sesiones del sitio contienen un usuario que visitó sitios de 10 países diferentes, y quieren encontrar a ese usuario en los datos transformados. Los datos transformados también muestran que el usuario visitó sitios de 10 países diferentes, lo que facilita la búsqueda. Incluso si descubren en qué se transformó el usuario, no será muy útil, porque todos los demás datos también se han transformado, por lo que no podrán averiguar qué sitios visitó el usuario ni nada más. Pero estas reglas pueden aplicarse en una cadena. Por ejemplo, si alguien sabe que el sitio web que aparece con mayor frecuencia en nuestros datos es Yandex, con Google en segundo lugar, puede usar la clasificación para determinar qué identificadores de sitios transformados realmente significan Yandex y Google. No hay nada sorprendente en esto, ya que estamos trabajando con un enunciado informal del problema y solo estamos tratando de encontrar un equilibrio entre el anonimato de datos (ocultar información) y preservar las propiedades de los datos (divulgación de información). Para obtener información sobre cómo abordar el problema de anonimato de datos de manera más confiable, lea este
artículo .
Además de mantener la cardinalidad original de los valores, también quiero mantener el orden de magnitud de los valores. Lo que quiero decir es que si los datos de origen contenían números menores a 10, entonces quiero que los números transformados también sean pequeños. ¿Cómo podemos lograr esto?
Por ejemplo, podemos dividir un conjunto de valores posibles en clases de tamaño y realizar permutaciones dentro de cada clase por separado (manteniendo las clases de tamaño). La forma más fácil de hacer esto es tomar la potencia más cercana de dos o la posición del bit más significativo en el número como la clase de tamaño (son la misma cosa). Los números 0 y 1 siempre permanecerán como están. Los números 2 y 3 a veces permanecerán como están (con una probabilidad de 1/2) y a veces se intercambiarán (con una probabilidad de 1/2). ¡El conjunto de números 1024. 2047 se asignará a uno de 1024! variantes (factoriales), etc. Para números con signo, conservaremos el signo.
También es dudoso si necesitamos una función uno a uno. Probablemente podamos usar una función hash criptográficamente fuerte. La transformación no será uno a uno, pero la cardinalidad será cercana a la misma.
Sin embargo, necesitamos una permutación aleatoria criptográficamente fuerte para que cuando definamos una clave y derivemos una permutación con esa clave, sería difícil restaurar los datos originales de los datos reorganizados sin conocer la clave.
Hay un problema: además de no saber nada sobre redes neuronales y aprendizaje automático, también soy bastante ignorante cuando se trata de criptografía. Eso deja solo mi coraje. Todavía estaba leyendo páginas web al azar, y encontré un enlace en
Hackers News a una discusión en la página de Fabien Sanglard. Tenía un enlace a una
publicación de blog del desarrollador de Redis Salvatore Sanfilippo que hablaba sobre el uso de una maravillosa forma genérica de obtener permutaciones aleatorias, conocida como una
red Feistel .
La red Feistel es iterativa y consiste en rondas. Cada ronda es una transformación notable que le permite obtener una función uno a uno de cualquier función. Veamos cómo funciona.
- Los bits del argumento se dividen en dos mitades:
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - La mitad derecha reemplaza a la izquierda. En su lugar, colocamos el resultado de XOR en el valor inicial de la mitad izquierda y el resultado de la función aplicada al valor inicial de la mitad derecha, así:
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
También se afirma que si usamos una función pseudoaleatoria criptográficamente fuerte para F y aplicamos una ronda Feistel al menos 4 veces, obtendremos una permutación pseudoaleatoria criptográficamente fuerte.
Esto es como un milagro: tomamos una función que produce basura aleatoria basada en datos, la insertamos en la red Feistel, y ahora tenemos una función que produce basura aleatoria basada en datos, ¡pero aún así es invertible!
La red Feistel está en el corazón de varios algoritmos de encriptación de datos. Lo que vamos a hacer es algo como el cifrado, solo que es realmente malo. Hay dos razones para esto:
- Estamos encriptando valores individuales de forma independiente y de la misma manera, de manera similar al modo de operación del Libro de códigos electrónicos.
- Estamos almacenando información sobre el orden de magnitud (la potencia más cercana de dos) y el signo del valor, lo que significa que algunos valores no cambian en absoluto.
De esta manera, podemos ofuscar los campos numéricos mientras conservamos las propiedades que necesitamos. Por ejemplo, después de usar LZ4, la relación de compresión debería permanecer aproximadamente igual, porque los valores duplicados en los datos de origen se repetirán en los datos convertidos, y a las mismas distancias entre sí.
Modelos de Markov
Los modelos de texto se utilizan para la compresión de datos, entrada predictiva, reconocimiento de voz y generación de cadenas aleatorias. Un modelo de texto es una distribución de probabilidad de todas las cadenas posibles. Digamos que tenemos una distribución de probabilidad imaginaria de los textos de todos los libros que la humanidad podría escribir. Para generar una cadena, simplemente tomamos un valor aleatorio con esta distribución y devolvemos la cadena resultante (un libro aleatorio que la humanidad podría escribir). Pero, ¿cómo descubrimos la distribución de probabilidad de todas las cadenas posibles?
Primero, esto requeriría demasiada información. Hay 256 ^ 10 cadenas posibles que tienen una longitud de 10 bytes, y se necesitaría bastante memoria para escribir explícitamente una tabla con la probabilidad de cada cadena. En segundo lugar, no tenemos suficientes estadísticas para evaluar con precisión la distribución.
Es por eso que usamos una distribución de probabilidad obtenida de estadísticas aproximadas como modelo de texto. Por ejemplo, podríamos calcular la probabilidad de que cada letra ocurra en el texto y luego generar cadenas seleccionando cada letra siguiente con la misma probabilidad. Este modelo primitivo funciona, pero las cadenas siguen siendo muy poco naturales.
Para mejorar ligeramente el modelo, también podríamos hacer uso de la probabilidad condicional de la aparición de la letra si está precedida por N letras específicas. N es una constante preestablecida. Digamos N = 5 y estamos calculando la probabilidad de que la letra "e" ocurra después de las letras "compr". Este modelo de texto se llama modelo Order-N Markov.
P(cat a | cat) = 0.8
P(cat b | cat) = 0.05
P(cat c | cat) = 0.1
...Veamos cómo funcionan los modelos de Markov en el sitio web
de Hay Kranen . A diferencia de las redes neuronales LSTM, los modelos solo tienen memoria suficiente para un pequeño contexto de N de longitud fija, por lo que generan textos divertidos y sin sentido. Los modelos de Markov también se utilizan en métodos primitivos para generar spam, y los textos generados se pueden distinguir fácilmente de los reales contando estadísticas que no se ajustan al modelo. Hay una ventaja: los modelos de Markov funcionan mucho más rápido que las redes neuronales, que es exactamente lo que necesitamos.
Ejemplo de título (nuestros ejemplos están en turco debido a los datos utilizados):
Hyunday Butter'dan anket shluha - Politika cabeza manşetleri | STALKER BOXER Çiftede book - Yanudistkarışmanlı Mı Kanal | League el Digitalika Haberler Haberleri - Haberlerisi - Hoteles con Centry'ler Neden babah.com
Podemos calcular estadísticas a partir de los datos de origen, crear un modelo de Markov y generar nuevos datos con él. Tenga en cuenta que el modelo necesita suavizarse para evitar revelar información sobre combinaciones raras en los datos de origen, pero esto no es un problema. Utilizo una combinación de modelos de 0 a N. Si las estadísticas son insuficientes para el modelo de orden N, se utiliza el modelo N - 1.
Pero aún queremos preservar la cardinalidad de los datos. En otras palabras, si los datos de origen tenían 123456 valores de URL únicos, el resultado debería tener aproximadamente el mismo número de valores únicos. Podemos usar un generador de números aleatorios inicializado determinísticamente para lograr esto. La forma más fácil de hacer esto es usar una función hash y aplicarla al valor original. En otras palabras, obtenemos un resultado pseudoaleatorio que está explícitamente determinado por el valor original.
Otro requisito es que los datos de origen pueden tener muchas URL diferentes que comienzan con el mismo prefijo pero no son idénticos. Por ejemplo:
https://www.yandex.ru/images/cats/?id=xxxxxx . Queremos que el resultado también tenga URL que comiencen con el mismo prefijo, pero diferente. Por ejemplo:
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . Como generador de números aleatorios para generar el siguiente carácter usando un modelo de Markov, tomaremos una función hash de una ventana móvil de 8 bytes en la posición especificada (en lugar de tomarla de toda la cadena).
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ...Resulta ser exactamente lo que necesitamos. Aquí está el ejemplo de los títulos de las páginas:
PhotoFunia - Haber7 - Hava mükemment.net Oynamak içinde şaşıracak haber, Oyunu Oynanılmaz • apród.hu kínálatában - RT Árabe
PhotoFunia - Kinobar.Net - apród: Ingyenes | Posti
PhotoFunia - Peg Perfeo - Castika, Sıradışı Deniz Lokoning Your Code, sire Eminema.tv/
PhotoFunia - TUT.BY - Tu Ayakkanın ve Son Dakika Spor,
PhotoFunia - película grande izle, Del Meireles offilim, Samsung DealeXtreme Değerler NEWSru.com.tv, Smotri.com Mobile yapmak Okey
PhotoFunia 5 | Galaxy, gt, după ce anal bilgi yarak Ceza RE050A V-Stranç
PhotoFunia :: Miami olacaksını yerel Haberler Oyun Young video
PhotoFunia Monstelli'nin En İyi kisa.com.tr –Star Thunder Ekranı
PhotoFunia Seks - Politika, Ekonomi, Spor GTA SANAYİ VE
PhotoFunia Taker-Rating Star TV Resmi Söylenen Yatağa każdy dzież wierzchnie
PhotoFunia TourIndex.Marketime oyunu Oyna Geldolları Mynet Spor, Magazin, Haberler yerel Haberleri ve Solvia, korkusuz Ev SahneTv
PhotoFunia todo en el Fotograma Gratis Perky Parti'nin yapıyı bu
PhotoFunian Dünyasın takımız halles en kulları - TEZ
Resultados
Después de probar cuatro métodos, me cansé tanto de este problema que llegó el momento de elegir algo, convertirlo en una herramienta utilizable y anunciar la solución. Elegí la solución que usa permutaciones aleatorias y modelos de Markov parametrizados por una clave. Se implementa como el programa
clickhouse-ofuscador , que es muy fácil de usar. La entrada es un volcado de tabla en
cualquier formato compatible (como CSV o JSONEachRow), y los parámetros de la línea de comando especifican la estructura de la tabla (nombres y tipos de columna) y la clave secreta (cualquier cadena, que puede olvidar inmediatamente después de usar). El resultado es el mismo número de filas de datos ofuscados.
El programa se instala con clickhouse-client, no tiene dependencias y funciona en casi cualquier versión de Linux. Puede aplicarlo a cualquier volcado de la base de datos, no solo a ClickHouse. Por ejemplo, puede generar datos de prueba de bases de datos MySQL o PostgreSQL o crear bases de datos de desarrollo que sean similares a las bases de datos de producción.
clickhouse-obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse-obfuscator --help
Por supuesto, todo no está tan cortado y seco, porque los datos transformados por este programa son casi completamente reversibles. La pregunta es si es posible realizar la transformación inversa sin conocer la clave. Si la transformación utilizara un algoritmo criptográfico, esta operación sería tan difícil como una búsqueda de fuerza bruta. Aunque la transformación usa algunas primitivas criptográficas, no se usan de la manera correcta y los datos son susceptibles a ciertos métodos de análisis. Para evitar problemas, estos problemas están cubiertos en la documentación del programa (acceda usando
--help ).
Al final, transformamos el conjunto de datos que necesitamos
para las pruebas funcionales y de rendimiento y la publicación aprobada de VP de Yandex de seguridad de datos.
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzLos desarrolladores que no son de Yandex usan estos datos para realizar pruebas de rendimiento real al optimizar algoritmos dentro de ClickHouse. Los usuarios de terceros pueden proporcionarnos sus datos ofuscados para que podamos hacer que ClickHouse sea aún más rápido para ellos. También lanzamos un punto de referencia abierto independiente para proveedores de hardware y nube además de estos datos:
clickhouse.yandex/benchmark_hardware.html