 Aquí hay una lista actualizada de los "productos" Unicode más maravillosos, así como paquetes y recursos
Aquí hay una lista actualizada de los "productos" Unicode más maravillosos, así como paquetes y recursos¡Unicode es asombroso! Antes de su aparición, la comunicación internacional era agotadora: cada uno definía su propio conjunto de caracteres extendidos por separado en la mitad superior de ASCII (las llamadas páginas de códigos). Esto creó conflicto. Solo piense que los alemanes tuvieron que negociar con los coreanos, ¿dónde está la página de códigos? Afortunadamente, apareció Unicode e introdujo un estándar común. Unicode 8.0 cubre más de 120,000 caracteres de más de 129 scripts. Tanto moderno como antiguo, y aún no descifrado. Unicode admite texto de izquierda a derecha y de derecha a izquierda, superpone caracteres e incluye una variedad de símbolos culturales, políticos, religiosos y emojis. Unicode es increíblemente humano, y sus capacidades se subestiman enormemente.
Contenido
Breve introducción
¿Qué caracteres están incluidos en Unicode Standard?
El estándar Unicode define códigos para caracteres en los principales idiomas modernos. Estas son escrituras alfabéticas europeas, escrituras del Medio Oriente de derecha a izquierda y muchas escrituras asiáticas.
El estándar también contiene signos de puntuación, signos diacríticos, símbolos matemáticos, símbolos técnicos, flechas, dingbats, emojis, etc. Proporciona códigos para signos diacríticos que cambian los signos de caracteres, como tildes (~). Se usan en combinación con los básicos para representar caracteres acentuados (por ejemplo, ñ). En general, la versión 9.0 de Unicode proporciona códigos para 128,172 caracteres de alfabetos mundiales, conjuntos de ideogramas y colecciones de caracteres.
Los caracteres más comunes se colocan en los primeros puntos de código de 64K, un área del espacio de código llamado plano multilingüe principal, o BMP para abreviar. Hay otros dieciséis planos adicionales disponibles para codificar otros caracteres, con más de 850,000 puntos de código no utilizados. Pueden ser útiles para agregar nuevos personajes a futuras versiones del estándar.
El estándar Unicode también reserva puntos de código para uso privado. Los proveedores o usuarios finales pueden designarlos en sus propios sistemas para sus personajes o usarlos con fuentes especializadas. El BMP tiene 6400 puntos de código para uso privado y otros 131 068 puntos de código adicionales para uso privado, si 6400 no es suficiente para aplicaciones específicas.
Codificaciones de caracteres Unicode
Los estándares de codificación de caracteres determinan no solo la identidad de cada carácter y su valor numérico o punto de código, sino también cómo se representa este valor en bits.
El estándar Unicode define tres formas de codificación que permiten la transmisión de los mismos datos: un byte, una palabra y una palabra doble (es decir, 8, 16 o 32 bits por unidad de código). Las tres formas codifican el mismo conjunto de caracteres común y pueden convertirse efectivamente entre sí sin pérdida de datos. El Consorcio Unicode respalda completamente el uso de cualquiera de estos formularios de codificación como una forma acordada para implementar el Estándar Unicode.
UTF-8 es popular para HTML y protocolos similares. UTF-8 es una forma de convertir todos los caracteres Unicode a una codificación de longitud de bytes variable. Su ventaja es que los caracteres Unicode que corresponden al conjunto ASCII familiar tienen los mismos valores de bytes que ASCII, y los caracteres Unicode convertidos a UTF-8 se pueden usar con una gran cantidad de software existente sin grandes modificaciones de software.
UTF-16 es popular en muchos entornos donde es necesario equilibrar el acceso eficiente a los personajes con un almacenamiento económico. Es bastante compacto, y todos los caracteres de uso frecuente se colocan en un bloque de código de 16 bits, mientras que todos los demás caracteres están disponibles a través de pares de bloques de código de 16 bits.
UTF-32 es útil cuando la cantidad de memoria no es una preocupación, pero requiere acceso a caracteres en un único código de ancho fijo. Aquí, cada carácter Unicode está codificado en un solo bloque de código de 32 bits.
Las tres formas de codificación requieren no más de 4 bytes (o 32 bits) para cada carácter.
Hablar sobre números
El conjunto de caracteres Unicode se divide en 17 segmentos principales (planos), que se dividen en bloques. En cada plano hay un lugar para 65 536 (2
16 ) puntos de código, lo que crea un total de 1,114,112 puntos de código. Hay dos "aviones de uso privado" (No. 16 y No. 17) que se asignan para su uso a discreción de las empresas / usuarios. Tienen 131.072 puntos de código.
El primer plano se llama plano multilingüe principal o BMP. Contiene puntos de código de U + 0000 a U + FFFF, es decir, los caracteres más utilizados. Los dieciséis planos restantes (U + 010000 → U + 10FFFF) se denominan adicionales o astrales.
Pares sustitutos UTF-16
Los símbolos fuera del plano principal, como un tetragrammaton que significa el centro (U + 1D306), se pueden codificar en UTF-16 con solo dos unidades de código de 16 bits: 0xD834 0xDF06. Esto se llama un par sustituto. Tenga en cuenta que un par sustituto representa solo un personaje.
La primera unidad de código de un par sustituto siempre está en el rango de 0xD800 a 0xDBFF y se llama la parte superior del par.
La segunda unidad de código del par sustituto siempre está en el rango de 0xDC00 a 0xDFFF y se llama la parte inferior del par.
Matthias Binens
Par sustituto: una representación de un símbolo abstracto, que consiste en una secuencia de dos unidades de código de 16 bits, donde el primer valor del par es la unidad de código sustituto superior y el segundo es la unidad de código sustituto inferior. Los pares sustitutos se usan solo en UTF-16.
Unicode 8.0 Capítulo 3.8 - Sustitutos
Cálculo de pares sustitutos
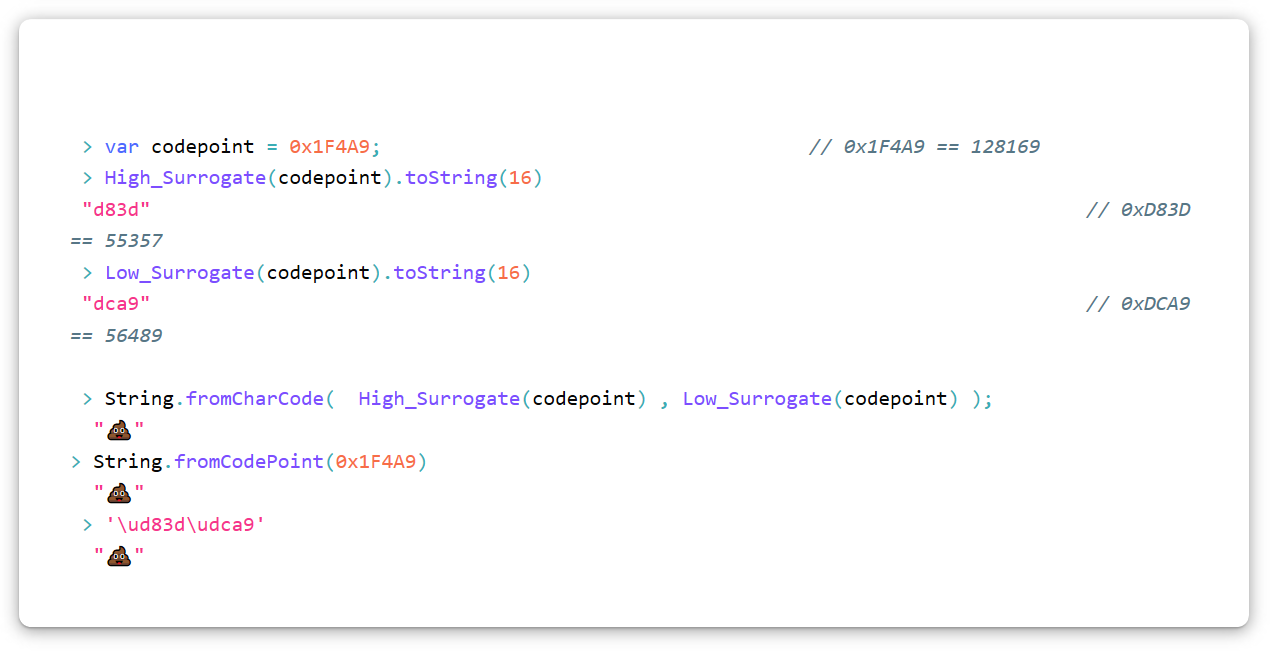
El carácter Unicode "Montón de mierda" (U + 1F4A9) en UTF-16 tendrá que codificarse como un par sustituto, es decir, dos sustitutos. Para convertir cualquier punto de código en un par sustituto, use este algoritmo (en JavaScript). Tenga en cuenta que usamos la notación hexadecimal.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 }; var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
Composición y descomposición.
Unicode incluye un mecanismo para cambiar la forma de un personaje, que amplía enormemente el conjunto de glifos admitidos. Esto se aplica a los diacríticos combinables. Se insertan después del personaje principal. Se pueden aplicar múltiples marcas diacríticas a la misma marca. Unicode también contiene versiones precompiladas de la mayoría de estas combinaciones para uso normal.
Algunas secuencias de caracteres también se pueden representar como un solo carácter llamado carácter precompuesto, también conocido como carácter compuesto. Por ejemplo, el carácter [ü] puede codificarse como el único punto de código U + 00FC o como el carácter base U + 0075 (u), seguido del carácter no autónomo U + 0308 (¨). El estándar Unicode codifica caracteres compuestos para compatibilidad con estándares establecidos, como Latin 1, que incluye muchos caracteres compuestos, como [ü] y [ñ].
Los caracteres compuestos se pueden expandir para lograr consistencia o análisis. Por ejemplo, cuando se ordena alfabéticamente, el símbolo [ü] se puede descomponer en [u] seguido del símbolo no independiente [¨]. Después de tal descomposición, el algoritmo es más fácil de trabajar con una secuencia de caracteres. Esto facilita la clasificación en idiomas donde los modificadores de caracteres no afectan el orden alfabético. El estándar Unicode establece el
orden de descomposición para todos los caracteres compuestos. También define formas de normalización para proporcionar representaciones únicas de personajes.
Mitos Unicode
De las diapositivas de la presentación de Mark Davis "Mitos de Unicode" .- Unicode es solo un código de 16 bits . - Algunas personas creen erróneamente que Unicode es solo un código de 16 bits, en el que cada carácter ocupa 16 bits y, por lo tanto, hay 65.536 caracteres posibles. De hecho, esto no es del todo cierto. Este es el mito más común de Unicode, así que si también lo pensaste antes, no te desanimes.
- Puede tomar cualquier punto de código que no se use para sus necesidades . - No Algún día este lugar será reemplazado por otro símbolo. En su lugar, use planos para uso privado o áreas sin caracteres en cada plano donde no habrá caracteres por estándar.
- Cada punto de código Unicode representa un carácter . - No Hay muchos puntos sin caracteres (FFFE, FFFF, 1FFFE, etc.) Además, puntos de código sustitutos, puntos de código privados y no utilizados, así como "caracteres" de control / formato (RLM, ZWNJ, etc.)
- Unicode se queda sin espacio . - Si se llenara linealmente, habría terminado en 2140. Pero el lugar no se llena linealmente. Planes futuros ver aquí .
- Todos los personajes se corresponden uno a uno . - No Las opciones son:
- Uno a muchos: (β → SS)
- Dado el contexto: (... Σ ← → ... ς y al mismo tiempo ... ΣΤ ... ← → ... στ ...)
- Según la configuración regional: (I ← → ı y al mismo tiempo İ ← → i)
Codificaciones de aplicación Unicode
Código fuente
Lista de personajes increíbles.
Compartir un documento puede convertir rápidamente la edición en una batalla de rap escrita, librada por un acuerdo cada vez más confuso de gerentes de U + 202a a U + 202ePersonajes especiales
El Consorcio Unicode ha publicado
un diagrama de puntuación general donde puede encontrar más información.
Espera ... ¿qué acabo de leer?¡Los identificadores variables pueden incluir espacios!
El marcador de posición Hangul U + 3164 se muestra como un espacio amplio. Si el carácter claramente no se
admite en la representación , se muestra como completamente invisible (y no ocupa espacio, es decir, "ancho cero"). Esto significa que nunca verá un personaje de reemplazo de personaje feo ( ).
Todavía no estoy seguro de por qué U + 3164 tiene instrucciones de comportarse de esta manera. Curiosamente, U + 3164 se agregó a Unicode en la versión 1.1 (1993), por lo que los especialistas del Consorcio tuvieron mucho tiempo para pensarlo. De todos modos, aquí hay algunos ejemplos.
> var ᅟ = 'foo'; undefined > ᅟ 'foo' > var ㅤ= alert; undefined > var foo = 'bar' undefined > if ( foo ===ㅤ`baz` ){}
** Nota: ** Probé el renderizado U + 3164 en Ubuntu y OS X con los siguientes parámetros: `node`,` php`, `ruby`,` python3.5`, `scala`,` vim`, `cat` , `chrome` +` github gist '. Atom es el único sistema que falla al mostrar (incorrectamente) campos vacíos. Todavía tengo que verificar el código en Emacs y Sublime. Según tengo entendido, el Consorcio Unicode no reasignará ni cambiará el nombre de los caracteres o puntos de código, pero puede ser persuadido para cambiar las propiedades de los caracteres como ID_Start e ID_Continue.Modificadores
Zero Width Combiner (ZWJ) es un carácter no imprimible en un conjunto de computadora de algunas fuentes complejas, como el árabe o cualquier fuente india. Cuando se coloca entre dos caracteres que de otro modo no estarían conectados, ZWJ los obliga a imprimir en forma combinada.
El seccionador de ancho cero (ZWNJ) es un carácter no imprimible en conjuntos de escritura basados en computadora con ligaduras. Cuando se coloca entre dos caracteres que de otro modo se unirían en una ligadura, ZWNJ los obliga a imprimir en sus formas final y original, respectivamente. Actúa como un espacio, pero se usa cuando es deseable mantener las palabras cercanas entre sí o combinar una palabra con su morfema.
> 'a' "a" > 'a\u{0308}' "ä" > 'a\u{20DE}\u{0308}' "a⃞̈" > 'a\u{20DE}\u{0308}\u{20DD}' "a⃞̈⃝"
Colisiones de transformación en mayúsculas
Colisiones minúsculas de conversión
Quirks y resolución de problemas
- La longitud de la línea generalmente está determinada por el número de puntos de código . Esto significa que los pares sustitutos se considerarán dos caracteres. Se pueden superponer varios signos diacríticos en un símbolo:
a + ̈ == ̈a . Esto aumenta la longitud de la cadena, produciendo solo un carácter.
- Del mismo modo, la inversión de cadenas a menudo se convierte en una tarea no trivial . Nuevamente, los pares sustitutos y los signos diacríticos deben invertirse juntos. ES Reverser ofrece una solución bastante buena.
- Las comparaciones en mayúsculas y minúsculas no siempre coinciden . Se pueden expresar en tales relaciones:
- Uno a muchos: (ß → SS)
- Dado el contexto: (... Σ ← → ... ς y ... ΣΤ ... ← → ... στ ...)
- Según la configuración regional: (I ← → ı e İ ← → i)
Una a muchas comparaciones
La mayoría de los caracteres a continuación expresan sus asignaciones de uno a muchos en mayúsculas y otros en minúsculas. En principio, la lista se puede dividir en dos partes.
Grandes paquetes y bibliotecas
- PhantomScript -: ghost :: flashlight: ejecutando JavaScript invisible e ingeniería social
- ESReverser : manejo de cadenas JavaScript basado en Unicode .
- mimic - Mal uso de Unicode
- python-ftfy : intenta crear la representación máxima correcta y completa del texto recibido en Unicode.
- vim-troll-stopper : protege tu código de los trolls Unicode.
Emoji
Unicode (diversity), . .
, , . — . :
, .
8.0 ( 2015 ) - . , ( , FitzpatrickSkinType.pdf). .
Unicode
, \u{1F466}\u{1F3FE} .

+

→


JavaScript (ES6)
, ID_START , . , ID_CONTINUE , .
CSS .
<!-- place this within the document head --> <meta charset="UTF-8" /> <div class="ಠ_ಠ">You do not have access to this page.</div> <div class="">Your changes have been saved successfully!</div>
.ಠ_ಠ { border: 1px solid #f00; } . { background: lightgreen; }
HTML
HTML- , , .
, HTML .
:
function testBegin(str){ try{ eval(`document.createElement( '${str}' );`) return true; } catch(e){ return false; } } function testContinue(str){ try{ eval(`document.createElement( 'a${str}' );`) return true; } catch(e){ return false; } }
:
TrueType OpenType UTF-8, 65 535 . 1,1 UTF-8, .
256 .

, () (CJK). , , « ».
. 17- .
:
- — - .
- — , .
- — .
- — , . .
- , — , . , .
- — , . , [Ä] [A] [¨].
- — .
- — , , . .
- — , .
- — .
: c codepoints.net .