Este artículo es una traducción de mi artículo sobre el medio:
Introducción a Data Lake , que resultó ser bastante popular, probablemente debido a su simplicidad. Por lo tanto, decidí escribirlo en ruso y complementarlo un poco para que una persona simple que no sea especialista en datos pueda comprender qué es un almacén de datos (DW) y qué es un Data Lake y cómo se llevan. .
¿Por qué quería escribir sobre un lago de datos? He trabajado con datos y análisis durante más de 10 años, y ahora definitivamente trabajo con Big Data en Amazon Alexa AI en Cambridge, que está en Boston, aunque yo mismo vivo en Victoria en la isla de Vancouver y a menudo visito Boston, Seattle y Vancouver, y a veces incluso en Moscú, hablo en conferencias. Además, de vez en cuando escribo, pero escribo principalmente en inglés, y ya he escrito
varios libros , también tengo la necesidad de compartir tendencias analíticas de América del Norte, y a veces escribo en
telegramas .
Siempre trabajé con almacenes de datos, y desde 2015 comencé a trabajar estrechamente con Amazon Web Services y, en general, cambié a la analítica en la nube (AWS, Azure, GCP). Observé la evolución de las soluciones analíticas desde 2007, e incluso trabajé en el proveedor del almacén de datos de Teradat y lo implementé en Sberbank, luego apareció Big Data con Hadoop. Todos comenzaron a decir que la era de los almacenes había pasado y ahora todo estaba en Hadoop, y luego comenzaron a hablar sobre Data Lake, nuevamente, ahora que el depósito de datos seguramente había terminado. Pero afortunadamente (tal vez para alguien y desafortunadamente, que ganó mucho dinero al configurar Hadoop), el almacén de datos no desapareció.
En este artículo, consideraremos qué es un lago de datos. Este artículo está destinado a personas que tienen poca o ninguna experiencia con el almacenamiento de datos.

En la imagen, el lago Bled es uno de mis lagos favoritos, aunque estuve allí solo una vez, pero lo recuerdo de por vida. Pero hablaremos de otro tipo de lago: el lago de datos. Quizás muchos de ustedes ya hayan escuchado sobre este término más de una vez, pero otra definición no le hará daño a nadie.
En primer lugar, estas son las definiciones más populares de un lago de datos:
"Almacenamiento de archivos de todo tipo de datos en bruto que están disponibles para el análisis de cualquier persona en la organización" - Martin Fowler.
“Si cree que una pantalla de datos es una botella de agua, purificada, empacada y empacada para un uso conveniente, entonces el lago de datos es un enorme depósito de agua en su forma natural. Usuarios, puedo sacar agua para mí, sumergirme en las profundidades, explorar "- James Dixon.
Ahora sabemos con certeza que el lago de datos se trata de análisis, nos permite almacenar grandes cantidades de datos en su forma original y tenemos el acceso necesario y conveniente a los datos.
A menudo me gusta simplificar las cosas, si puedo decir un término complejo en palabras simples, entonces por mí mismo entendí cómo funciona y para qué sirve. De alguna manera, estaba eligiendo mi iPhone en la galería de fotos, y me di cuenta, así que este es un verdadero lago de datos, incluso hice una diapositiva para conferencias:

Todo es muy sencillo. Tomamos una foto en el teléfono, la foto se guarda en el teléfono y se puede guardar en iCloud (almacenamiento de archivos en la nube). El teléfono también recopila metadatos de la foto: lo que se muestra, geoetiqueta, hora. Como resultado, podemos usar la conveniente interfaz de iPhone para encontrar nuestra foto y, al mismo tiempo, incluso vemos indicadores, por ejemplo, cuando busco fotos con la palabra fuego, encuentro 3 fotos con la imagen de un incendio. Para mí, es como una herramienta de Business Intelligence que funciona de manera muy rápida y clara.
Y, por supuesto, no debemos olvidarnos de la seguridad (autorización y autenticación), de lo contrario, nuestros datos pueden entrar fácilmente en acceso abierto. Hay muchas noticias sobre grandes corporaciones y nuevas empresas, en las que los datos ingresaron al dominio público debido a la negligencia de los desarrolladores y al incumplimiento de reglas simples.
Incluso una imagen tan simple nos ayuda a imaginar qué es un lago de datos, sus diferencias con respecto a un almacén de datos tradicional y sus elementos principales:
- La carga de datos (ingestión) es un componente clave de un lago de datos. Los datos pueden ingresar al almacén de datos de dos maneras: lote (descarga a intervalos) y transmisión (flujo de datos).
- El almacenamiento de archivos es el componente principal del lago de datos. Necesitamos que el almacenamiento sea fácilmente escalable, extremadamente confiable y de bajo costo. Por ejemplo, en AWS, este es S3.
- Catálogo y búsqueda : para evitar el Pantano de datos (esto es cuando volcamos todos los datos en una pila, y luego es imposible trabajar con ellos), necesitamos crear una capa de metadatos para clasificar los datos para que los usuarios puedan fácilmente encontrar los datos que necesitan para el análisis. Además, puede usar soluciones de búsqueda adicionales, como ElasticSearch. La búsqueda ayuda al usuario a buscar los datos deseados a través de una interfaz conveniente.
- Procesamiento (Proceso): este paso es responsable del procesamiento y la transformación de los datos. Podemos transformar datos, cambiar sus estructuras, borrar y mucho más.
- Seguridad : es importante pasar tiempo diseñando una solución de seguridad. Por ejemplo, encriptación de datos durante el almacenamiento, procesamiento y carga. Es importante utilizar métodos de autenticación y autorización. En conclusión, se necesita una herramienta de auditoría.
Desde un punto de vista práctico, podemos caracterizar un lago de datos con tres atributos:
- Recopile y almacene lo que desee : el lago de datos contiene todos los datos, tanto los datos brutos sin procesar para cualquier período de tiempo como los datos procesados / borrados.
- Análisis profundo : un lago de datos permite a los usuarios explorar y analizar datos.
- Acceso flexible : un lago de datos proporciona acceso flexible para diversos datos y diversos escenarios.
Ahora podemos hablar sobre la diferencia entre un almacén de datos y un lago de datos. La gente suele preguntar:
- ¿Pero qué pasa con el almacén de datos?
- ¿Estamos reemplazando el almacén de datos con un lago de datos o lo estamos expandiendo?
- ¿Es posible prescindir de un lago de datos?
En resumen, no hay una respuesta clara. Todo depende de la situación específica, las habilidades del equipo y el presupuesto. Por ejemplo, migrar un almacén de datos a Oracle en AWS y crear un lago de datos por la subsidiaria de Amazon - Woot -
Nuestra historia del lago de datos: cómo Woot.com construyó un lago de datos sin servidor en AWS .
Por otro lado, el proveedor de Snowflake afirma que ya no necesita pensar en un lago de datos, ya que su plataforma de datos (hasta 2020 era un almacén de datos) le permite combinar un lago de datos y un almacén de datos. No he trabajado mucho con Snowflake, y es un producto verdaderamente único que puede hacer esto. El precio de la pregunta es otra pregunta.
En conclusión, mi opinión personal es que todavía necesitamos un almacén de datos como la fuente principal de datos para nuestros informes, y almacenamos todo lo que no cabe en el lago de datos. Todo el papel de la analítica es proporcionar un acceso conveniente a las empresas para la toma de decisiones. De todos modos, los usuarios comerciales trabajan de manera más eficiente con un almacén de datos que con un lago de datos, por ejemplo, en Amazon: hay Redshift (almacén de datos analíticos) y Redshift Spectrum / Athena (interfaz SQL para el lago de datos en S3 basado en Hive / Presto). Lo mismo se aplica a otros almacenes de datos analíticos modernos.
Veamos una arquitectura típica de almacén de datos:
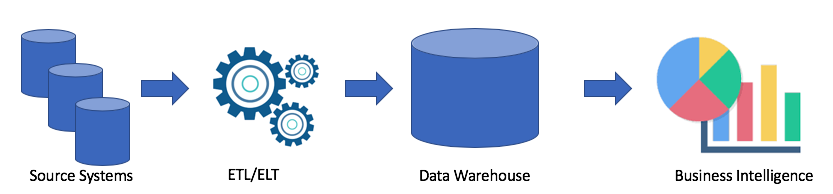
Esta es una solución clásica. Tenemos sistemas de origen, utilizando ETL / ELT copiamos datos al almacén de datos analíticos y conectamos la solución a mi solución de Business Intelligence (¿mi Tableau favorito y el suyo?).
Esta solución tiene las siguientes desventajas:
- Las operaciones ETL / ELT requieren tiempo y recursos.
- Como regla general, la memoria para almacenar datos en un almacén de datos analíticos no es barata (por ejemplo, Redshift, BigQuery, Teradata), ya que necesitamos comprar un clúster completo.
- Los usuarios comerciales tienen acceso a datos limpios y a menudo agregados y no tienen la capacidad de obtener datos sin procesar.
Por supuesto, todo depende de tu caso. Si no tiene problemas con su almacén de datos, no necesita un lago de datos. Pero cuando surgen problemas con la falta de espacio, la capacidad o el precio del problema tiene un papel clave, entonces puede considerar la opción de un lago de datos. Por eso, el lago de datos es muy popular. Aquí hay un ejemplo de una arquitectura de lago de datos:

Usando el enfoque del lago de datos, cargamos datos sin procesar en nuestro lago de datos (lote o transmisión), luego procesamos los datos según sea necesario. El lago de datos permite a los usuarios empresariales crear sus propias transformaciones de datos (ETL / ELT) o analizar datos en soluciones de Business Intelligence (si tiene el controlador adecuado).
El objetivo de cualquier solución analítica es servir a los usuarios empresariales. Por lo tanto, siempre debemos trabajar en los requisitos del negocio. (En Amazon, este es uno de los principios: trabajar al revés).
Trabajando con el almacén de datos y el lago de datos, podemos comparar ambas soluciones:
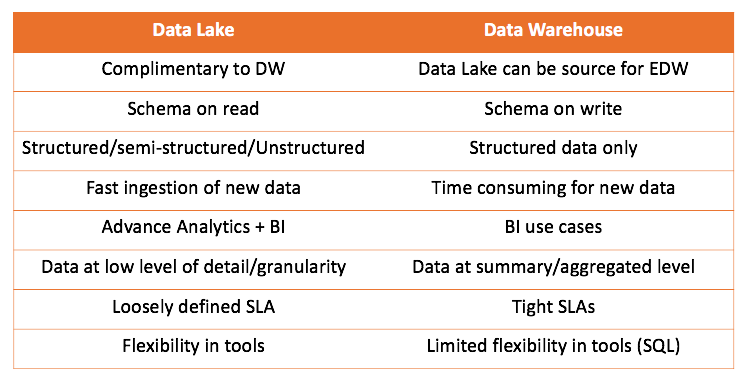
La principal conclusión que se puede extraer es que el almacén de datos no compite con el lago de datos, sino que lo complementa más. Pero depende de usted lo que es correcto para su caso. Siempre es interesante probarlo usted mismo y sacar las conclusiones correctas.
También me gustaría hablar sobre uno de los casos en que comencé a usar el enfoque del lago de datos. Todo es bastante común, intenté usar la herramienta ELT (teníamos Matillion ETL) y Amazon Redshift, mi solución funcionó, pero no se ajustaba a los requisitos.
Necesitaba tomar registros web, transformarlos y agregarlos para proporcionar datos para 2 casos:
- El equipo de marketing quería analizar la actividad de los bots para SEO
- TI quería ver las métricas del sitio
Muy simple, registros muy simples. Aquí hay un ejemplo:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188 192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57 "GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012" 1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"
Un archivo pesaba 1-4 megabytes.
Pero había una dificultad. Teníamos 7 dominios en todo el mundo, y en un día se crearon 7,000 mil archivos. Este no es un volumen muy grande, solo 50 gigabytes. Pero el tamaño de nuestro clúster Redshift también era pequeño (4 nodos). La descarga de un solo archivo de la manera tradicional tomó aproximadamente un minuto. Es decir, la tarea no se resolvió en la frente. Y este fue el caso cuando decidí usar el enfoque del lago de datos. La solución se parecía a esto:
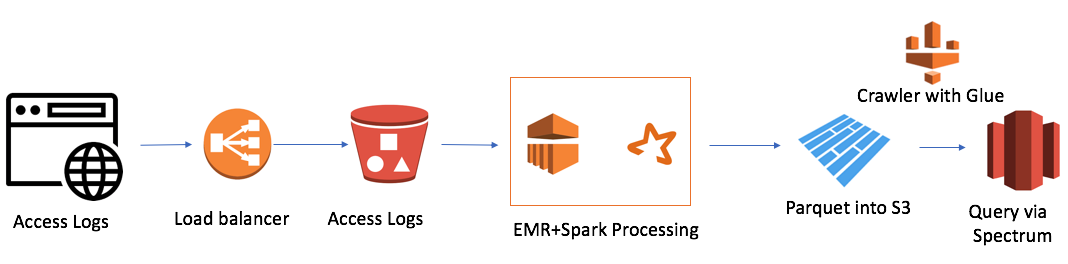
Es bastante simple (quiero señalar que la ventaja de trabajar en la nube es la simplicidad). Yo usé:
- AWS Elastic Map Reduce (Hadoop) como potencia informática
- AWS S3 como almacenamiento de archivos con la capacidad de cifrar datos y restringir el acceso
- Spark como InMemory Computing Power y PySpark para la lógica y la transformación de datos
- Parquet como resultado de Spark
- AWS Glue Crawler como recopilador de metadatos sobre nuevos datos y particiones
- Redshift Spectrum como interfaz SQL para el lago de datos para usuarios existentes de Redshift
El clúster EMR + Spark más pequeño procesó una gran cantidad de archivos en 30 minutos. Hay otros casos para AWS, especialmente muchos relacionados con Alexa, donde hay muchos datos.
Más recientemente, descubrí que uno de los inconvenientes del lago de datos es el GDPR. El problema es cuando el cliente le pide que elimine, y los datos están en uno de los archivos, no podemos usar el lenguaje de manipulación de datos y la operación DELETE como en la base de datos.
Esperemos que el artículo aclare la diferencia entre un almacén de datos y un lago de datos. Si fue interesante, todavía puedo traducir mis artículos o el artículo de profesionales que leí. Y también hablar sobre las soluciones con las que trabajo, y su arquitectura.