Para obtener suficientes datos de entrenamiento para robomobiles, no es necesario utilizar multitudes de personas que marcan videos manualmente

Después de leer un libro sobre un tema específico, no se convertirá en un experto en él. ¿Cómo no puedes convertirte en él leyendo muchos de los mismos libros? Para convertirse en un verdadero profesional en cualquier campo de conocimiento, es necesario recopilar una gran cantidad de información de varias fuentes.
Lo mismo será cierto para los robomobiles y otras tecnologías basadas en IA.
Las redes neuronales profundas responsables del funcionamiento del robot robótico requieren una formación integral. Necesitan estudiar tanto las situaciones que pueden enfrentar en las condiciones cotidianas como los casos inusuales que nunca tendrán que enfrentar si tienen suerte. La clave del éxito es asegurarse de que estén capacitados en los datos correctos.
Pero, ¿qué son los datos adecuados? Estas son situaciones nuevas o inciertas, y no una repetición constante de las mismas.
El aprendizaje activo es un método de selección de datos de aprendizaje para el aprendizaje automático que encuentra automáticamente estos datos diversos. Además, recopila conjuntos de datos durante una pequeña fracción del tiempo que llevaría a las personas completar esta tarea.
Funciona con la ayuda de un modelo entrenado, que itera sobre los datos recopilados y marca esos marcos, con el reconocimiento de que tuvo dificultades. Entonces estos marcos están marcados por personas. Luego se agregan a los datos de entrenamiento. Esto aumenta la precisión del modelo en situaciones como el reconocimiento de objetos en condiciones difíciles.
Cómo buscar una aguja en una pila de datos
La cantidad de datos necesarios para entrenar un robot robótico es monstruosa. Los expertos de
la Corporación RAND creen que el automóvil necesita recorrer 17 mil millones de kilómetros para superar a la persona en precisión en un 20%. Para hacer esto, una flota de 100 autos en el mundo real tendría que conducir continuamente durante 500 años.
Además, no todos los datos obtenidos al conducir en la carretera son adecuados para esta tarea. Los datos de entrenamiento efectivos deben contener condiciones diversas y complejas para garantizar un viaje seguro.
Si las personas se dedicaban a buscar y marcar estos datos, procesar los datos recibidos por una flota de 100 automóviles que viajaban 8 horas al día requeriría el trabajo de más de un millón de marcadores, lo que necesitaba marcar los datos de todas las cámaras de todos los automóviles, claramente una tarea imposible. Además del costo del trabajo humano, no sería práctico asignar recursos para el almacenamiento de datos y la computación de redes neuronales.
La combinación de marcado y aprobación de datos plantea un serio desafío para el desarrollo de robomobiles. Al aplicar la IA a este proceso, puede ahorrar tiempo y dinero en el entrenamiento, al tiempo que aumenta la precisión de las redes neuronales.
¿Por qué el aprendizaje activo?
Hay tres métodos comunes para seleccionar datos para entrenar redes neuronales de robomobiles. El muestreo aleatorio selecciona marcos de la base de datos a intervalos regulares, que describe los escenarios más comunes, pero es probable que omita casos raros.
El muestreo basado en metadatos utiliza etiquetas básicas (por ejemplo, "lluvia", "noche") para muestrear datos, lo que facilita encontrar situaciones difíciles comunes, pero también faltan cuadros únicos que no se pueden clasificar fácilmente, como un remolque con un tractor o una persona con puentes. cruzando la calle
 Comparación de la escena habitual en la carretera (arriba a la izquierda) con escenarios inusuales: un ciclista nocturno en la rueda trasera, una camioneta con un remolque con un remolque, un peatón en puentes.
Comparación de la escena habitual en la carretera (arriba a la izquierda) con escenarios inusuales: un ciclista nocturno en la rueda trasera, una camioneta con un remolque con un remolque, un peatón en puentes.Finalmente, el muestreo manual utiliza etiquetas de metadatos junto con los marcos de visualización de las personas; esta tarea lleva mucho tiempo, es propensa a errores y no se escala bien.
El aprendizaje activo hace posible automatizar el proceso de selección de marcos, al tiempo que selecciona puntos de referencia valiosos en los datos. Comienza con el entrenamiento de una red neuronal especial en datos ya etiquetados. Después de eso, la red procesa los datos no asignados, seleccionando marcos que no puede reconocer, por lo tanto, busca datos que serán difíciles para el algoritmo robomobile. Luego, estos datos son estudiados y marcados por personas, y se agregan a la base de datos de capacitación.
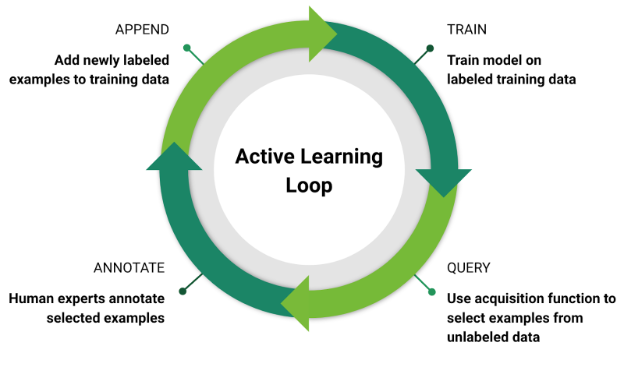 Bucle de aprendizaje activo: para entrenar un modelo en datos etiquetados, hacer una selección de datos no asignados, marcar datos seleccionados utilizando mano de obra humana, agregar nuevos datos etiquetados a la base de datos; repetir
Bucle de aprendizaje activo: para entrenar un modelo en datos etiquetados, hacer una selección de datos no asignados, marcar datos seleccionados utilizando mano de obra humana, agregar nuevos datos etiquetados a la base de datos; repetirEl entrenamiento activo ya ha demostrado su capacidad para aumentar la precisión del funcionamiento de las redes neuronales de robomobiles en comparación con la adición manual de datos. En nuestro
estudio, encontramos que el aumento en la precisión cuando se usa el entrenamiento activo excede el aumento en la precisión con el muestreo manual de datos hasta 3 veces para el reconocimiento de peatones, y hasta 4.4 veces para los ciclistas.
Al mismo tiempo, los métodos de entrenamiento avanzados para redes neuronales, por ejemplo, aprendizaje activo, aprendizaje de
transferencia y
aprendizaje colaborativo, funcionan de manera más eficiente en una infraestructura confiable y escalable que le permite procesar simultáneamente cantidades masivas de datos, acortando el ciclo de desarrollo. El acceso a dichas capacidades es proporcionado por el proyecto
NVIDIA GPU Cloud , donde se encuentran las herramientas de capacitación mencionadas y una gran biblioteca de redes neuronales profundas para robomobiles.