
Por tercer año, llevamos a cabo el foro RAIF (Foro de Inteligencia Artificial de Rusia) donde los oradores del mundo de los negocios y la ciencia hablan sobre su trabajo. Decidimos compartir los informes más interesantes. En esta publicación, Andrey Filchenkov, jefe del Laboratorio de aprendizaje automático ITMO, dice toda la verdad sobre AutoML.
En el marco del foro RAIF 2019 celebrado en Skolkovo, organizado por Jet Infosystems, hice una presentación en la que hablé sobre AutoML y las perspectivas para su uso. Como soy científico, no tengo que hablar en tales eventos con mucha frecuencia: generalmente participo en conferencias científicas.
Una de las principales áreas con las que tratamos es AutoML. Además, soy el CTO de dos pequeñas startups. Uno de ellos, las tecnologías Statanly, crea servicios AutoML y se dedica al análisis de datos. De hecho, soy la persona que inventa algoritmos, los implementa y los usa. Creo que soy la única persona que puede hablar sobre AutoML desde las tres posiciones posibles.
¿Qué es AutoML?
En el último año, esta dirección ha sido de gran interés, y ahora se puede comparar con el foco de atención en el aprendizaje profundo popular en su época. El advenimiento del aprendizaje automático se puede remontar a 1976. Había una pequeña comunidad de ML, y en 2017 comenzó a ganar popularidad, después de un año más allá de los límites del aprendizaje automático. Ahora hablan de él en los negocios, la industria y en varios otros campos. Es cierto que en Rusia, desafortunadamente, no todas las personas, incluso de la comunidad de ML, imaginan lo que es el aprendizaje automático. ¿Por qué sucedió esto?
La respuesta es simple: la demanda de científicos de datos crece mucho más rápido de lo que logran graduarse de las universidades y completar cursos. Al mismo tiempo, pasan la mayor parte del tiempo (hasta el 80%) eligiendo un modelo, configurándolo y esperando hasta que todo se calcule. Esto se debe a que no existe un algoritmo ideal; desafortunadamente, ninguno de ellos tiene un alcance limitado, y los especialistas en análisis de datos tienen que seleccionar el algoritmo que sea óptimo para cada tarea específica y luego configurarlo. Aquí, mucho depende de la calificación del analista: cuanto más sepa en el área temática y comprenda los algoritmos, más óptima puede ser la solución por un tiempo determinado. Aquí es donde ayuda AutoML. En realidad, AutoML le permite automatizar y acelerar la selección de soluciones y tareas de aprendizaje automático.
Decidamos de inmediato: hay dos direcciones relacionadas, pero diferentes entre sí.
Primero: los datos se presentan en la tabla, hay etiquetas, y cuando necesitamos clasificarlos, seleccionamos un objeto de una lista grande y configuramos sus hiperparámetros, y al mismo tiempo podemos procesar los datos.
El segundo escenario es más complejo. Por ejemplo, imágenes, secuencias y áreas donde el aprendizaje profundo es ahora el estándar: aquí la tarea se vuelve un poco más interesante, porque puedes crear nuevas arquitecturas: no son tan fáciles de resolver. Entonces, "Buscar arquitecturas neuronales", se dedica al hecho de que selecciona la red óptima y configura hiperparámetros que permiten resolver uno u otro problema. Sin embargo, AutoML no tiene en cuenta la semántica de los datos. También hay métodos que le permiten "extraer" descripciones de datos y usarlas para pronosticar, pero esto solo ayuda a aumentar la aplicabilidad universal de AutoML. Realmente no importa de dónde provienen los datos: si usted es un gasista, un vendedor de helados o cualquier otra persona, los métodos son universales. Al mismo tiempo, AutoML le permite construir las soluciones más efectivas, por un lado, eligiendo soluciones complejas y no las más obvias, incluso para un especialista en el análisis de datos estructurales, y por otro lado, para buscar y optimizar dichas soluciones más rápido. Y una cosa más no obvia: AutoML permite acelerar la escritura de código. Aquí, por ejemplo:

A la derecha, el código está escrito en Keras para el reconocimiento MNIST, y a la izquierda está el código para Auto-Keras en la biblioteca de automatización escrita bajo Keras. La diferencia es visible, mientras se guarda el tiempo de escritura.
Abundancia de soluciones existentes (2019)
En este momento hay una gran cantidad de bibliotecas y plataformas diferentes para el análisis automático de datos, solo he citado algunas de ellas (de hecho, hay muchas más).
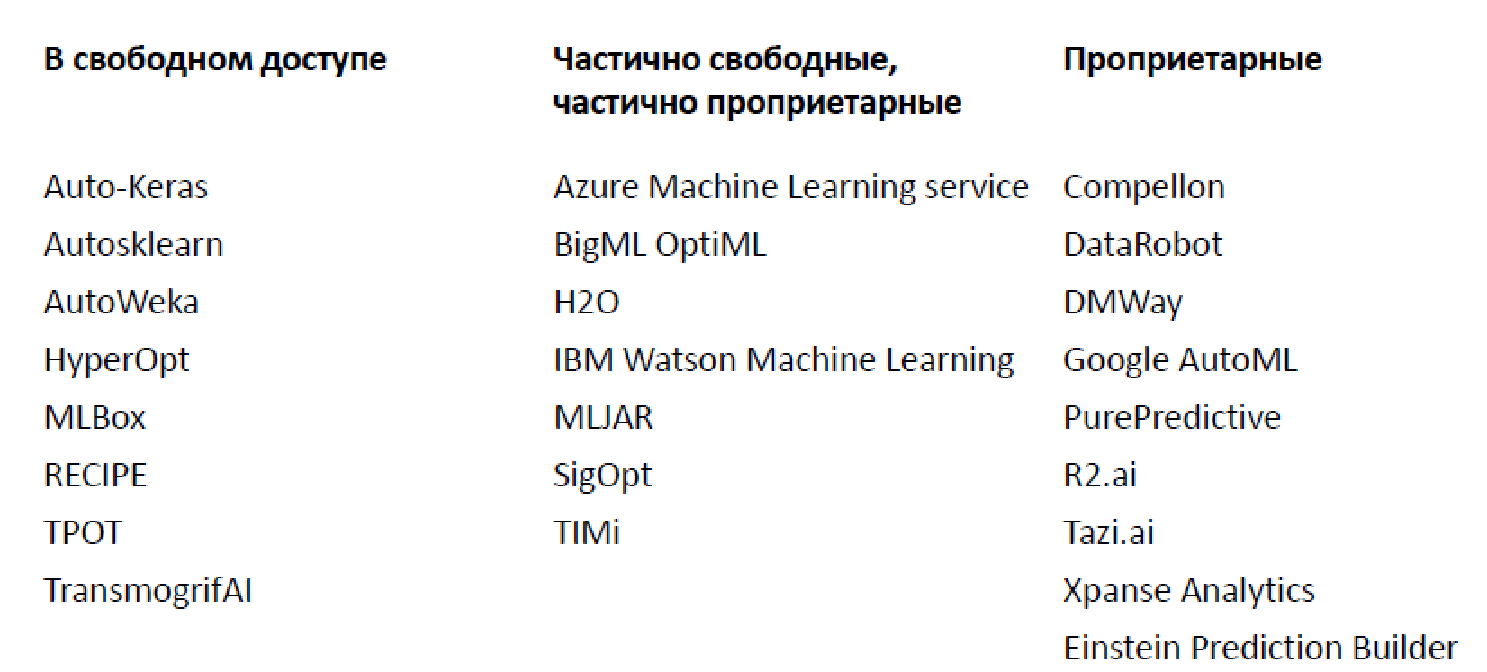
Hay dos abiertos, que implementan una funcionalidad limitada, y opciones propietarias. El más famoso, probablemente, es Google AutoML, que no le da un modelo, pero lo entrena en sus datos, lo que le permite usarlo por $ 20 por hora. Además, hay una gran cantidad de escenarios decentes cuando la funcionalidad básica se ofrece de forma gratuita, pero hay que pagar por componentes más avanzados.
Pronósticos brillantes
La propia comunidad elogia las perspectivas de AutoML. Por ejemplo, Jeff Dean, un científico de inteligencia artificial y un investigador senior de Google, dijo en marzo de 2018 que la experiencia existente en aprendizaje automático podría ser reemplazada por un aumento de cien veces en la potencia informática (casi todo lo que hace un científico de datos) -puedes ser automatizado). Un pronóstico un poco más moderado pero aún aterrador de Gartner dice que para 2020, el 40% de los científicos de datos puede ser reemplazado por AutoML.
Un poco de alquitrán
Así es como se ve la metodología estándar CRISP DM:
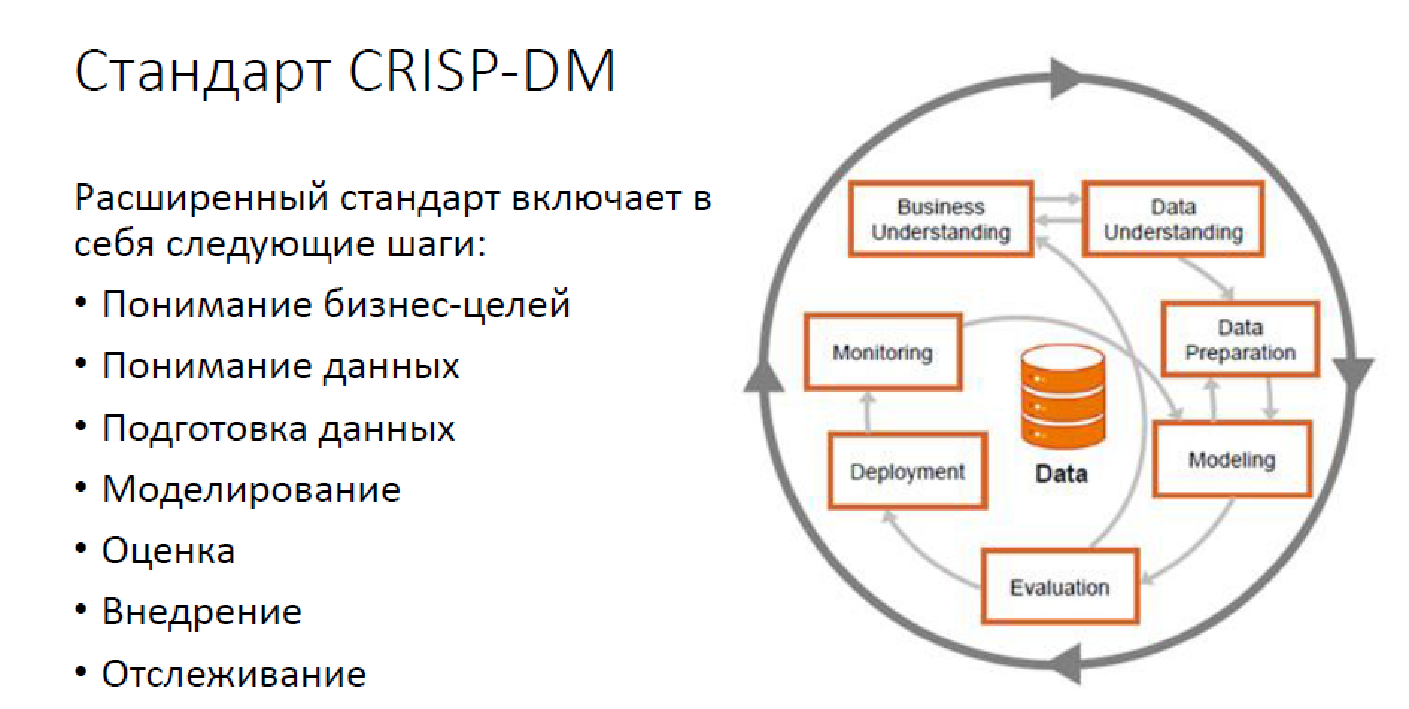
Esta es una opción avanzada, con monitoreo, pero no obstante. Hoy, resolver problemas de análisis de datos no se reduce a construir modelos solamente. Tenemos una gran cantidad de tareas que deben resolverse, y es necesario que las personas las resuelvan con precisión.
Por el momento, en la mayoría de los casos, AutoML tiene solo 2.5 pilares: elegir un modelo, configurarlo y, a veces, cuando resulta, elegir características de síntesis y solo datos.
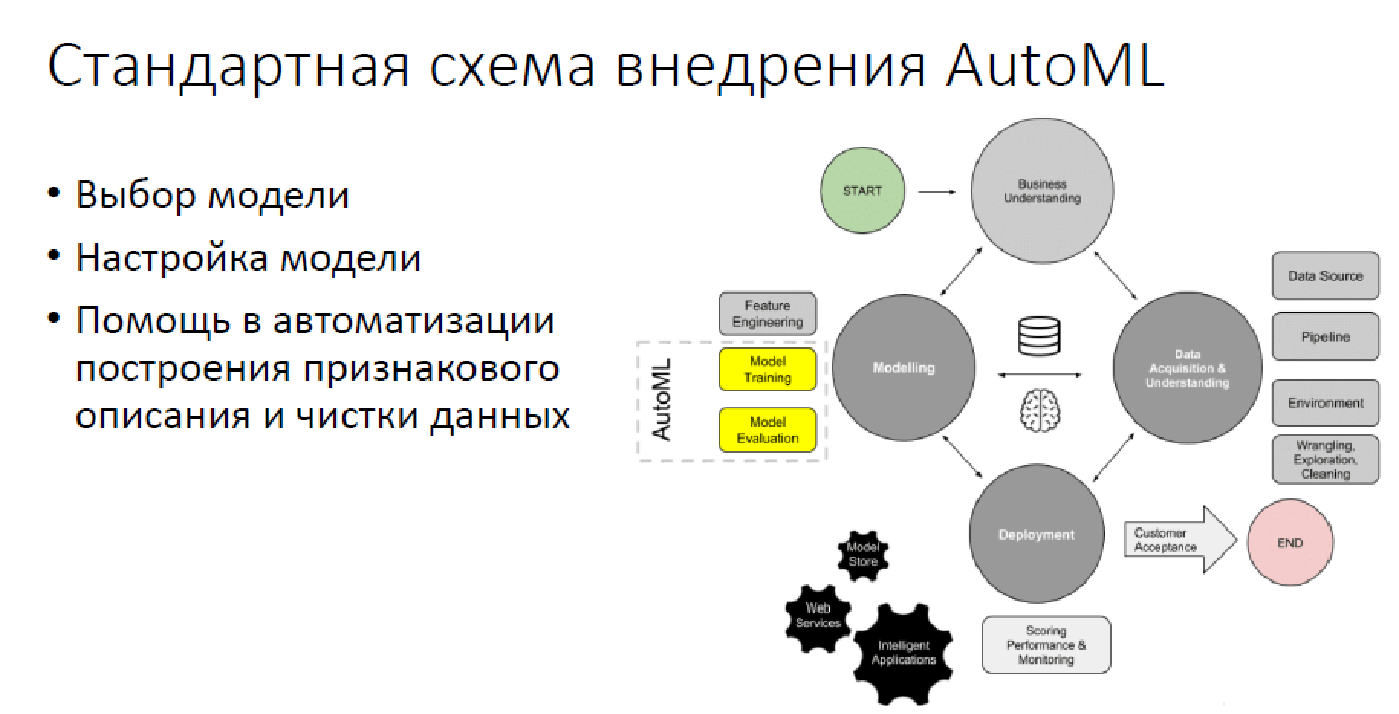
Más allá de AutoML
Desafortunadamente, un número bastante grande de operaciones se deja por la borda, lo que AutoML no puede y no podrá hacer en un futuro razonable. Naturalmente, esto implica la transformación de las tareas del mundo real en el mundo del análisis de datos: "¿Cómo proyectar su problema para que pueda resolverse mediante el análisis de datos?" Estos son todo tipo de seguimiento de modelos, evaluación de calidad, búsqueda de varios momentos desagradables, todo para que la solución no resulte, por ejemplo, demasiado intolerante para nadie, porque esto ya ha sucedido. Naturalmente, ningún AutoML puede admitir soluciones y comunicarse con los clientes. Además, la interpretabilidad en el momento actual está fuera de discusión.
Por lo tanto, esta es una herramienta muy conveniente, pero desafortunadamente para nosotros no resuelve lejos de todos los problemas.

Que estamos haciendo
Así es como se ve el circuito ideal (como lo veo):
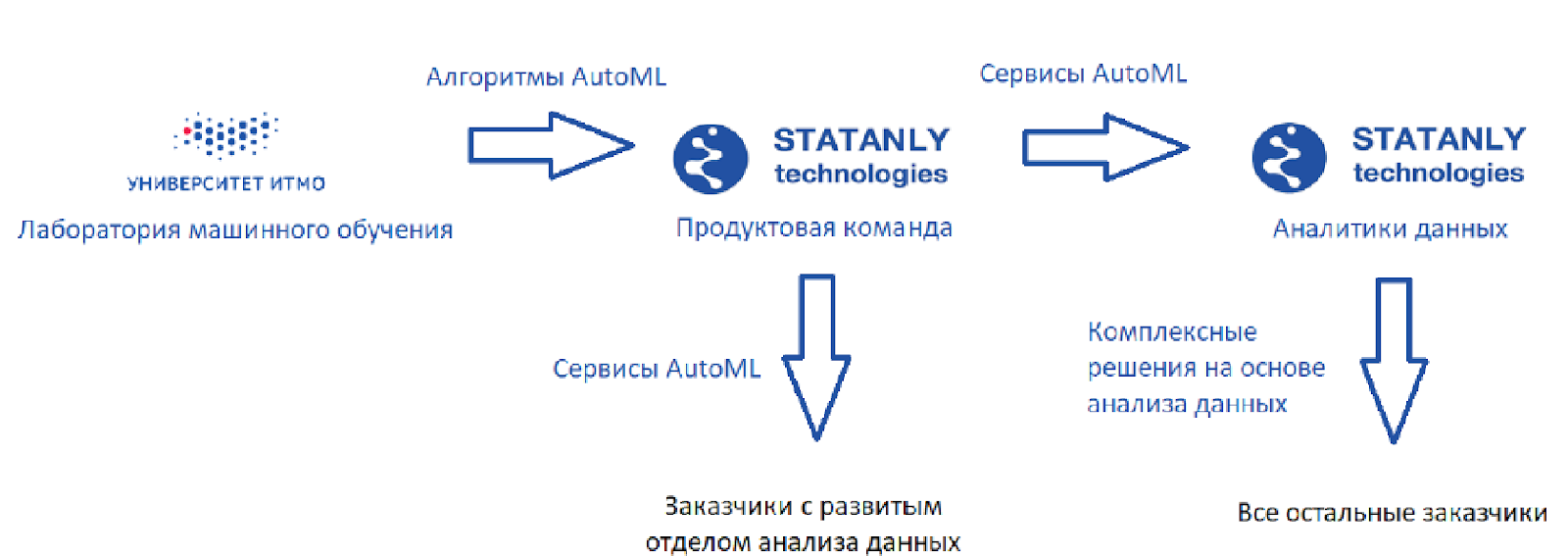
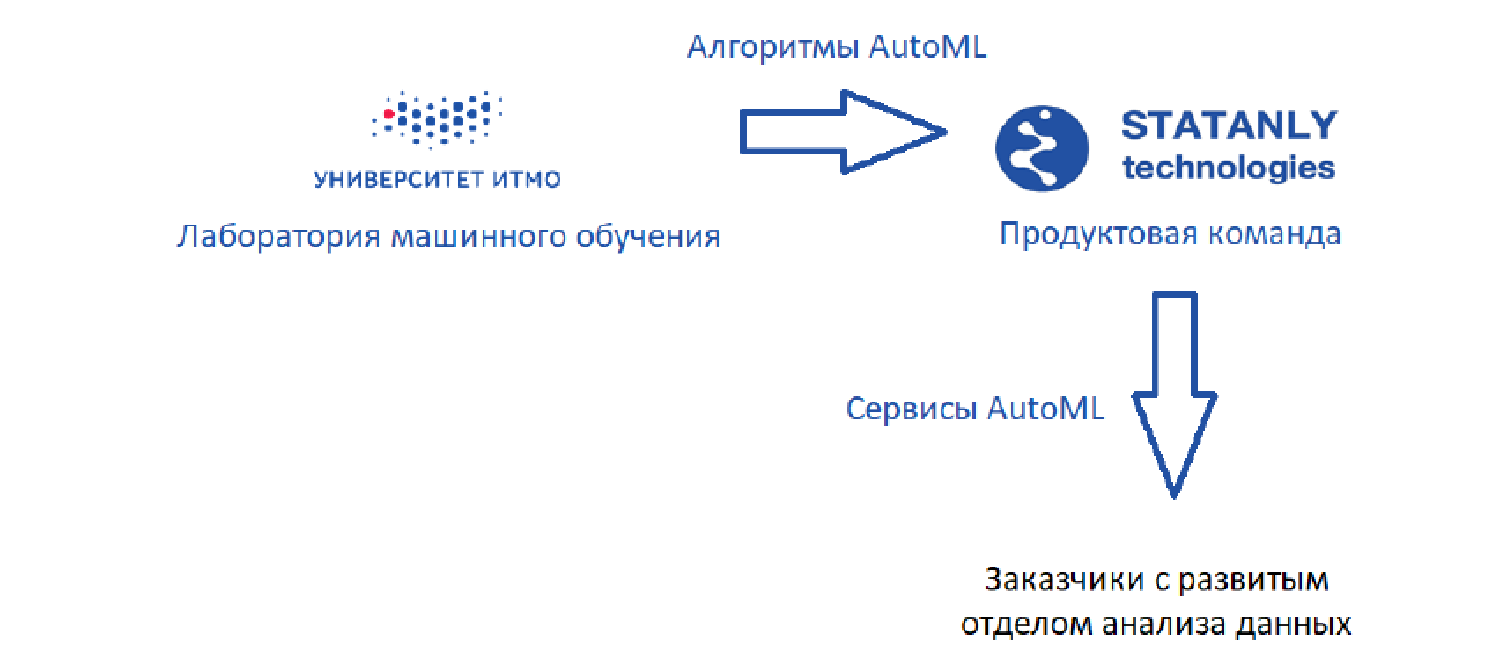
Hay un laboratorio de aprendizaje automático que desarrolla algoritmos, además de
Statanly Technologies , un equipo de producto que implementa servicios AutoML basados en nuestros algoritmos. Trabajan para empresas que tienen un gran departamento de Data Science. Estos mismos productos son utilizados por un equipo de analistas de datos en
Statanly Technologies y resuelven específicamente los problemas de compañías que aún no se han expandido o incluso creado su propio departamento de análisis de datos. El modelo se ve muy bien, pero la realidad, por supuesto, es un poco más prosaica.
Comenzamos en 2017 con el hecho de que no había análisis de datos aquí:
Queríamos lanzar un producto que los analistas de datos usarían, pero en 2017, desafortunadamente, no pudimos encontrar contacto con los inversores: no entendían qué era AutoML, por qué era necesario y quién lo usaría.
Por el momento, no estamos vendiendo nada, como compañía que desarrolla soluciones AutoML, solo hacemos nuestras vidas más fáciles, como un equipo que se dedica al análisis de datos:

Un poco sobre cómo lo hacemos. Naturalmente, configuramos hiperparámetros (sin búsqueda de cuadrícula), pero además de configurarlos, casi siempre tratamos de construir algunas soluciones básicas basadas en AutoML y, a veces, nos ayudamos en los pasos para el preprocesamiento de datos.
Tengo algunos ejemplos inspiradores y variados, prácticamente todo lo que AutoML y yo hicimos, de simple a complejo.
Un ejemplo simple es la tarea en Gazpromneft: hay un pozo, necesita predecir el tiempo potencial de falla. Tenemos a nuestra disposición datos y características tabulares clásicas. Como resultado, creamos un modelo predictivo usando AutoML, aunque ni un solo analista resultó herido, pero ni siquiera participó en el proceso. De hecho, esta resultó ser la mejor solución:

Segunda historia: Tecnologías Sinara. Aquí la tarea fue un poco más complicada, porque de hecho había exactamente dos columnas: tiempo / parámetro + cómo cambió. Era necesario predecir la falla del motor. Aquí usamos AutoML para ayudarnos un poco con el procesamiento de datos: creamos una línea de base, que luego superamos:

El tercer ejemplo: una tarea que a primera vista no tiene nada que ver con AutoML. Hay un sitio web para el canal TVC: una base de datos de artículos en los que buscar, y la búsqueda es semánticamente rica. Nos gustaría encontrar no solo expresiones exactas de palabras, sino también adecuadas en significado. Además de una gran lista de diferentes requisitos que también deben considerarse.
¿Cómo abordamos este problema?
Decidimos indexar todos los documentos basados en grupos flexibles de palabras similares, porque la indexación es más conveniente. Además, hay más de 100 mil documentos en la base de datos, y si esto no se hace, la búsqueda será infinitamente larga. Luego, creamos una representación vectorial (espero que todos hayan oído hablar de ella) y agrupamos sobre representaciones vectoriales para permitirnos ser indexados.
El segundo problema: ¿cómo agrupamos los datos? Aplicamos AutoML para seleccionar medidas para evaluar la calidad de la agrupación, así como para seleccionar algoritmos e hiperparámetros para la agrupación:

Además, la mayoría de las veces no usamos AutoML. Aquí hay dos ejemplos muy reveladores.
En nuestra segunda startup, Special Video Analytics, el producto es un sistema para reconocer los signos de los automóviles para garantizar su acceso centralizado a un territorio cerrado. El principal problema aquí es la pequeña cantidad de datos. En este caso, es bastante difícil ajustar los parámetros del modelo. Y estamos muy limitados, porque a menudo AutoML se usa sin pensar e intenta ajustar los modelos a los mismos datos en los que se prueban. Esto no se puede hacer: de acuerdo con los clásicos del aprendizaje automático, es necesario seleccionar un conjunto de validación: cuanto mayor sea la búsqueda, más máquinas debería haber. Entonces, cuando tenemos pocos datos, nos preocupa más encontrar y marcar estos datos que construir un modelo más complejo.
Otro ejemplo es nuestro desarrollo conjunto con Huawei. Hicimos un proyecto para que reconocieran texto en imágenes. Parece que puede usar AutoML aquí, ya que hay tres métricas que se pueden optimizar: calidad de reconocimiento, tiempo de reconocimiento y parámetro del modelo (ya que se suponía que todo esto se implementaría en dispositivos móviles). Pero ahora nadie tiene la experiencia suficiente para implementar de manera óptima los tres aspectos.
Como resultado, no había suficiente potencia informática: estábamos limitados en el tiempo y no teníamos una cantidad suficiente de servidores. Si lo comenzamos en casa (y debería haber estado en LICE), simplemente no tendríamos tiempo. Como lleva cinco horas procesar, solo nos cuesta nuestras competencias.
Conclusión
En general, AutoML es algo muy útil, pero bastante limitado en la aplicación. Naturalmente, no podrá encontrar soluciones para los conocimientos tradicionales. AutoML actualmente solo es útil para analistas de datos. Tal vez algún día los reemplazará, pero obviamente no en los próximos cinco años.
Publicado por Andrey Filchenkov, jefe del laboratorio de aprendizaje automático, ITMO