Si está interesado en el aprendizaje automático, probablemente escuchó sobre BERT y los transformadores.
BERT es un modelo de lenguaje de Google, que muestra resultados de vanguardia por un amplio margen en una serie de tareas. BERT, y en general los transformadores, se han convertido en un paso completamente nuevo en el desarrollo de algoritmos de procesamiento de lenguaje natural (PNL). El artículo sobre ellos y las "posiciones" para varios puntos de referencia se pueden encontrar en el sitio web de Papers With Code .
Hay un problema con BERT: es problemático de usar en sistemas industriales. BERT-base contiene 110M parámetros, BERT-large - 340M. Debido a la gran cantidad de parámetros, este modelo es difícil de descargar en dispositivos con recursos limitados, como teléfonos móviles. Además, el largo tiempo de inferencia hace que este modelo sea inadecuado cuando la velocidad de respuesta es crítica. Por lo tanto, encontrar formas de acelerar el BERT es un tema muy candente.
En Avito, a menudo tenemos que resolver problemas de clasificación de texto. Esta es una tarea de aprendizaje automático aplicada típica que ha sido bien estudiada. Pero siempre existe la tentación de probar algo nuevo. Este artículo nació de un intento de aplicar BERT en las tareas cotidianas de aprendizaje automático. En él, mostraré cómo puede mejorar significativamente la calidad de un modelo existente usando BERT sin agregar nuevos datos o complicar el modelo.

La destilación del conocimiento como método para acelerar las redes neuronales
Hay varias formas de acelerar / aligerar las redes neuronales. La revisión más detallada que he conocido se publica en el blog de Intento en el Medio .
Los métodos se pueden dividir aproximadamente en tres grupos:
- Cambio de arquitectura de red.
- Modelo de compresión (cuantización, poda).
- Destilación del conocimiento.
Si los dos primeros métodos son relativamente conocidos y comprensibles, entonces el tercero es menos común. Por primera vez, la idea de la destilación fue propuesta por Rich Caruana en el artículo "Modelo de compresión" . Su esencia es simple: puede entrenar un modelo liviano que imitará el comportamiento de un modelo de maestro o incluso un conjunto de modelos. En nuestro caso, el maestro será BERT y el alumno será cualquier modelo ligero.
Desafío
Analicemos la destilación utilizando la clasificación binaria como ejemplo. Tome el conjunto de datos SST-2 abierto del conjunto estándar de tareas que prueban los modelos para PNL.
Este conjunto de datos es una colección de reseñas de películas con IMDb desglosadas por color emocional, positivo o negativo. La métrica en este conjunto de datos es la precisión.
Capacitación de modelos basados en BERT o "maestros"
En primer lugar, debe entrenar el modelo "grande" basado en BERT, que se convertirá en un maestro. La forma más fácil de hacer esto es tomar las incrustaciones de BERT y entrenar el clasificador encima de ellas, agregando una capa a la red.
Gracias a la biblioteca de transformadores, esto es bastante fácil de hacer, porque hay una clase de modelo BertForSequenceClassification ya hecha. En mi opinión, Towards Data Science publicó el tutorial más detallado y comprensible para enseñar este modelo.
Imaginemos que tenemos un modelo entrenado BertForSequenceClassification. En nuestro caso, num_labels = 2, ya que tenemos una clasificación binaria. Utilizaremos este modelo como un "maestro".
Aprendizaje "estudiante"
Puede tomar cualquier arquitectura como estudiante: una red neuronal, un modelo lineal, un árbol de decisión. Intentemos enseñar BiLSTM para una mejor visualización. Para comenzar, enseñaremos BiLSTM sin BERT.
Para enviar texto a la entrada de una red neuronal, debe presentarlo como un vector. Una de las formas más fáciles es asignar cada palabra a su índice en el diccionario. El diccionario constará de las palabras más populares de n en nuestro conjunto de datos más dos palabras de servicio: "pad" - "palabra ficticia" para que todas las secuencias tengan la misma longitud, y "unk" - para palabras fuera del diccionario. Construiremos el diccionario usando el conjunto estándar de herramientas de torchtext. Para simplificar, no utilicé incrustaciones de palabras pre-entrenadas.
import torch from torchtext import data def get_vocab(X): X_split = [t.split() for t in X] text_field = data.Field() text_field.build_vocab(X_split, max_size=10000) return text_field def pad(seq, max_len): if len(seq) < max_len: seq = seq + ['<pad>'] * (max_len - len(seq)) return seq[0:max_len] def to_indexes(vocab, words): return [vocab.stoi[w] for w in words] def to_dataset(x, y, y_real): torch_x = torch.tensor(x, dtype=torch.long) torch_y = torch.tensor(y, dtype=torch.float) torch_real_y = torch.tensor(y_real, dtype=torch.long) return TensorDataset(torch_x, torch_y, torch_real_y)
Modelo BiLSTM
El código para el modelo se verá así:
import torch from torch import nn from torch.autograd import Variable class SimpleLSTM(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, batch_size, device=None): super(SimpleLSTM, self).__init__() self.batch_size = batch_size self.hidden_dim = hidden_dim self.n_layers = n_layers self.embedding = nn.Embedding(input_dim, embedding_dim) self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout) self.fc = nn.Linear(hidden_dim * 2, output_dim) self.dropout = nn.Dropout(dropout) self.device = self.init_device(device) self.hidden = self.init_hidden() @staticmethod def init_device(device): if device is None: return torch.device('cuda') return device def init_hidden(self): return (Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device)), Variable(torch.zeros(2 * self.n_layers, self.batch_size, self.hidden_dim).to(self.device))) def forward(self, text, text_lengths=None): self.hidden = self.init_hidden() x = self.embedding(text) x, self.hidden = self.rnn(x, self.hidden) hidden, cell = self.hidden hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)) x = self.fc(hidden) return x
Entrenamiento
Para este modelo, la dimensión del vector de salida será (batch_size, output_dim). En el entrenamiento, usaremos el logloss habitual. PyTorch tiene una clase BCEWithLogitsLoss que combina entropía sigmoidea y cruzada. Lo que necesitas
def loss(self, output, bert_prob, real_label): criterion = torch.nn.BCEWithLogitsLoss() return criterion(output, real_label.float())
Código para una era de aprendizaje:
def get_optimizer(model): optimizer = torch.optim.Adam(model.parameters()) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma=0.9) return optimizer, scheduler def epoch_train_func(model, dataset, loss_func, batch_size): train_loss = 0 train_sampler = RandomSampler(dataset) data_loader = DataLoader(dataset, sampler=train_sampler, batch_size=batch_size, drop_last=True) model.train() optimizer, scheduler = get_optimizer(model) for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Train')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) model.zero_grad() output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) loss.backward() optimizer.step() train_loss += loss.item() scheduler.step() return train_loss / len(data_loader)
Código de verificación después de la era:
def epoch_evaluate_func(model, eval_dataset, loss_func, batch_size): eval_sampler = SequentialSampler(eval_dataset) data_loader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=batch_size, drop_last=True) eval_loss = 0.0 model.eval() for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc='Val')): text, bert_prob, real_label = to_device(text, bert_prob, real_label) output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) eval_loss += loss.item() return eval_loss / len(data_loader)
Si todo esto se combina, obtenemos el siguiente código para entrenar el modelo:
import os import torch from torch.utils.data import (TensorDataset, random_split, RandomSampler, DataLoader, SequentialSampler) from torchtext import data from tqdm import tqdm def device(): return torch.device("cuda" if torch.cuda.is_available() else "cpu") def to_device(text, bert_prob, real_label): text = text.to(device()) bert_prob = bert_prob.to(device()) real_label = real_label.to(device()) return text, bert_prob, real_label class LSTMBaseline(object): vocab_name = 'text_vocab.pt' weights_name = 'simple_lstm.pt' def __init__(self, settings): self.settings = settings self.criterion = torch.nn.BCEWithLogitsLoss().to(device()) def loss(self, output, bert_prob, real_label): return self.criterion(output, real_label.float()) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=1, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model def train(self, X, y, y_real, output_dir): max_len = self.settings['max_seq_length'] text_field = get_vocab(X) X_split = [t.split() for t in X] X_pad = [pad(s, max_len) for s in tqdm(X_split, desc='pad')] X_index = [to_indexes(text_field.vocab, s) for s in tqdm(X_pad, desc='to index')] dataset = to_dataset(X_index, y, y_real) val_len = int(len(dataset) * 0.1) train_dataset, val_dataset = random_split(dataset, (len(dataset) - val_len, val_len)) model = self.model(text_field) model.to(device()) self.full_train(model, train_dataset, val_dataset, output_dir) torch.save(text_field, os.path.join(output_dir, self.vocab_name)) def full_train(self, model, train_dataset, val_dataset, output_dir): train_settings = self.settings num_train_epochs = train_settings['num_train_epochs'] best_eval_loss = 100000 for epoch in range(num_train_epochs): train_loss = epoch_train_func(model, train_dataset, self.loss, self.settings['train_batch_size']) eval_loss = epoch_evaluate_func(model, val_dataset, self.loss, self.settings['eval_batch_size']) if eval_loss < best_eval_loss: best_eval_loss = eval_loss torch.save(model.state_dict(), os.path.join(output_dir, self.weights_name))
Destilación
La idea de este método de destilación está tomada de un artículo de investigadores de la Universidad de Waterloo . Como dije anteriormente, el "estudiante" debe aprender a imitar el comportamiento del "maestro". ¿Cuál es exactamente el comportamiento? En nuestro caso, estas son las predicciones del modelo del maestro en el conjunto de entrenamiento. Y la idea clave es usar la salida de red antes de aplicar la función de activación. Se supone que de esta manera el modelo podrá aprender mejor la representación interna que en el caso de las probabilidades finales.
El artículo original propone agregar un término a la función de pérdida, que será responsable del error de "imitación" - MSE entre los registros del modelo.

Para estos fines, hacemos dos pequeños cambios: cambiar el número de salidas de red de 1 a 2 y corregir la función de pérdida.
def loss(self, output, bert_prob, real_label): a = 0.5 criterion_mse = torch.nn.MSELoss() criterion_ce = torch.nn.CrossEntropyLoss() return a*criterion_ce(output, real_label) + (1-a)*criterion_mse(output, bert_prob)
Puede reutilizar todo el código que escribimos redefiniendo solo el modelo y la pérdida:
class LSTMDistilled(LSTMBaseline): vocab_name = 'distil_text_vocab.pt' weights_name = 'distil_lstm.pt' def __init__(self, settings): super(LSTMDistilled, self).__init__(settings) self.criterion_mse = torch.nn.MSELoss() self.criterion_ce = torch.nn.CrossEntropyLoss() self.a = 0.5 def loss(self, output, bert_prob, real_label): return self.a * self.criterion_ce(output, real_label) + (1 - self.a) * self.criterion_mse(output, bert_prob) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=2, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings['train_batch_size']) return model
Eso es todo, ahora nuestro modelo está aprendiendo a "imitar".
Comparación de modelo
En el artículo original, los mejores resultados de clasificación para SST-2 se obtienen en a = 0, cuando el modelo aprende solo a imitar, sin tener en cuenta las etiquetas reales. La precisión es aún menor que BERT, pero significativamente mejor que la BiLSTM normal.

Traté de repetir los resultados del artículo, pero en mis experimentos el mejor resultado se obtuvo a = 0.5.
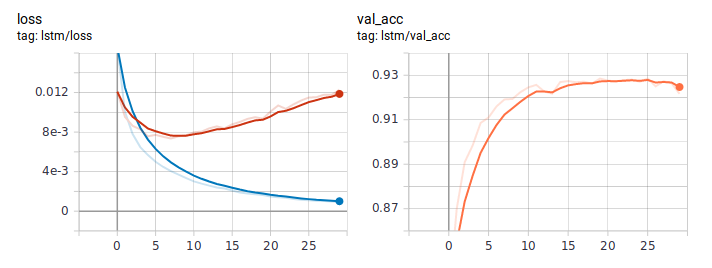
Así es como se ven los gráficos de pérdida y precisión cuando se aprende LSTM de la manera habitual. A juzgar por el comportamiento de la pérdida, el modelo aprendió rápidamente, y en algún lugar después de la sexta era, comenzó el reciclaje.
Gráficos de destilación:
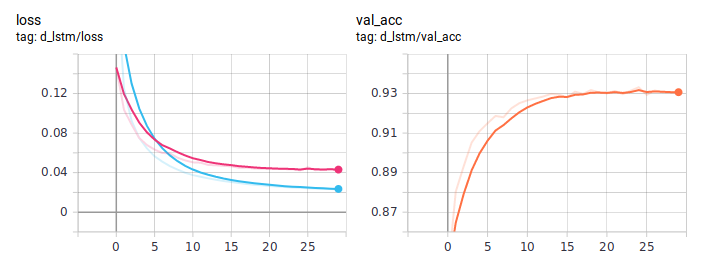
El BiLSTM destilado es consistentemente mejor de lo normal. Es importante que sean absolutamente idénticos en arquitectura, la única diferencia está en la forma de enseñar. Publiqué el código de entrenamiento completo en GitHub .
Conclusión
En esta guía, traté de explicar la idea básica de un enfoque de destilación. La arquitectura específica del alumno dependerá de la tarea en cuestión. Pero en general, este enfoque es aplicable en cualquier tarea práctica. Debido a la complejidad en la etapa de entrenamiento del modelo, puede obtener un aumento significativo en su calidad, manteniendo la simplicidad original de la arquitectura.